mysql 数据库服务自主优化能力(4种)
- 自主优化功能一:AHI(索引的索引)
- 自主优化功能二:CHANGE BUFFER
- 自主优化功能三:ICP (索引下推)
- 自主优化功能四:MRR
下边我们来一一介绍
1 自主优化功能一:AHI(索引的索引)
AHI全称(中文名称)为自适应的hash索引/散列索引,用于在内存中建立索引,快速锁定内存中的热点数据索引页位置;
正常情况下,所有数据都是存储在磁盘中的,如果想访问读取相应磁盘的数据信息,都是会将磁盘数据调取存放在内存中,即消耗IO;
对于数据库服务而言,想要读取数据信息,也是会从磁盘中读取存储页,在放入内存中被数据库服务进行访问,索引访问也是一样的;
但是当数据页大量的被存放在内存中后,从大量内存中的数据页找到想要的,也是比较困难的事情;
因此,可以对内存中经常被访问数据索引页建立一个hash索引,从而可以帮助数据库服务快速定位内存中想要找的索引数据页;
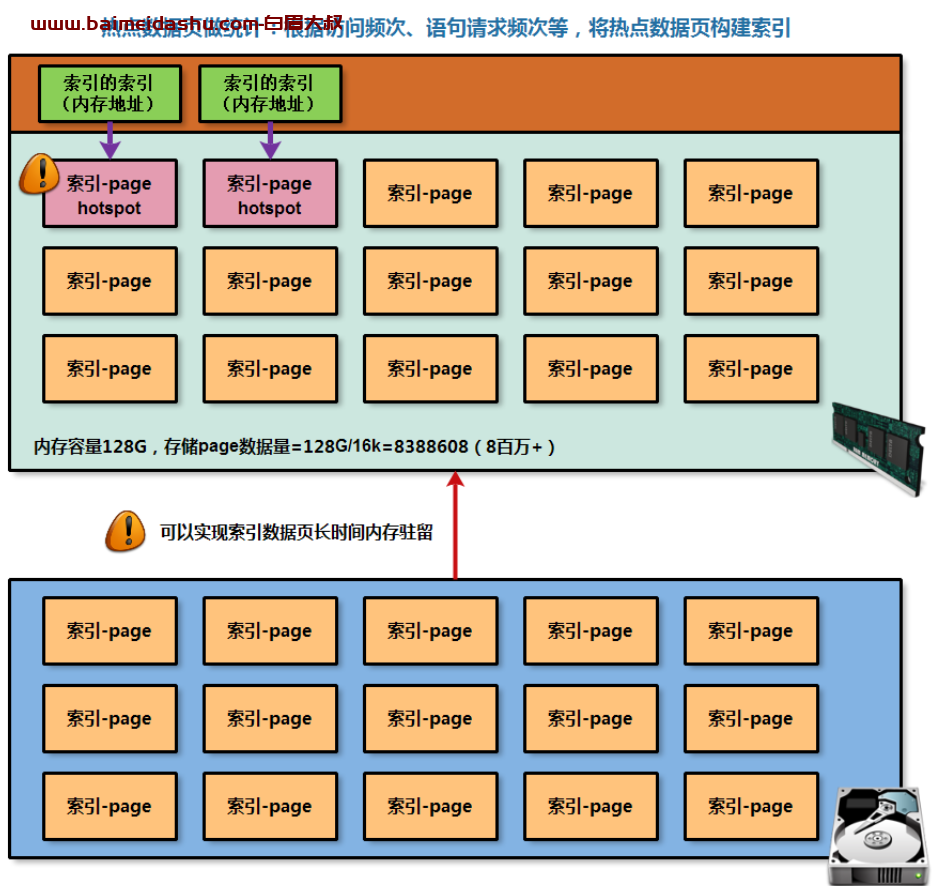
AHI功能配置信息:
mysql> show variables like 'innodb_adaptive_hash_index';
+--------------------------------------+-------+
| Variable_name | Value |
+--------------------------------------+-------+
| innodb_adaptive_hash_index | ON |
+--------------------------------------+-------+
1 row in set (0.00 sec)
2-自主优化功能二:CHANGE BUFFER
早期版本称为 insert buffer,只是对插入操作有作用,版本更新后(5.6),可以对插入 修改 删除操作都有作用效果;
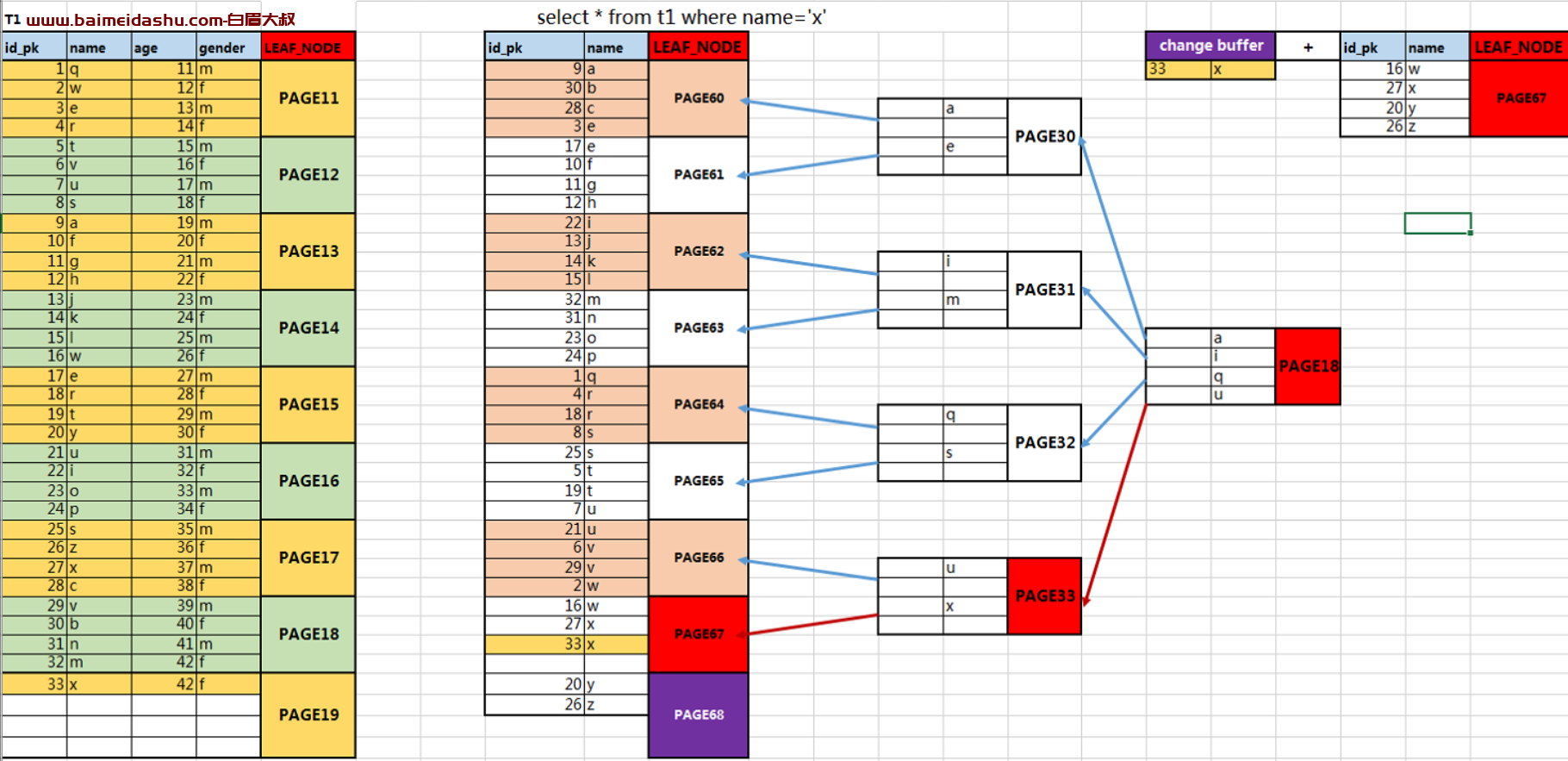
change buffer主要是针对辅助索引的缓冲区,属于内存结构上的应用;
changerbuffer应用原理:假设现在需要插入一行数据信息
① 插入一行数据信息到表中,将会实时立即更新聚簇索引信息,因为利用聚簇索引是用来获取数据页上详细原表数据信息的;
② 插入一行数据信息到表中,不会实时立即更新辅助索引信息,因为利用辅助索引是用来获取索引页上聚簇索引数据信息的;
如果此时实时更新了辅助索引的信息,有可能会导致出现数据页分裂,造成辅助索引树结构变化,形成索引树访问阻塞(锁机制);
③ 为了避免辅助索引树结构变更,对数据库服务并发访问的影响,可以将插入的数据信息,暂时存储在缓冲区中;
当利用辅助索引检索数据时,可以将检索到数据页范围信息调取到内存中,与缓存区数据进行合并,自然可以检索到插入的数据
说明:在数据表中插入 修改 删除数据时,聚簇索引树会进行同步实时更新,辅助索引树会进行异步延时更新。
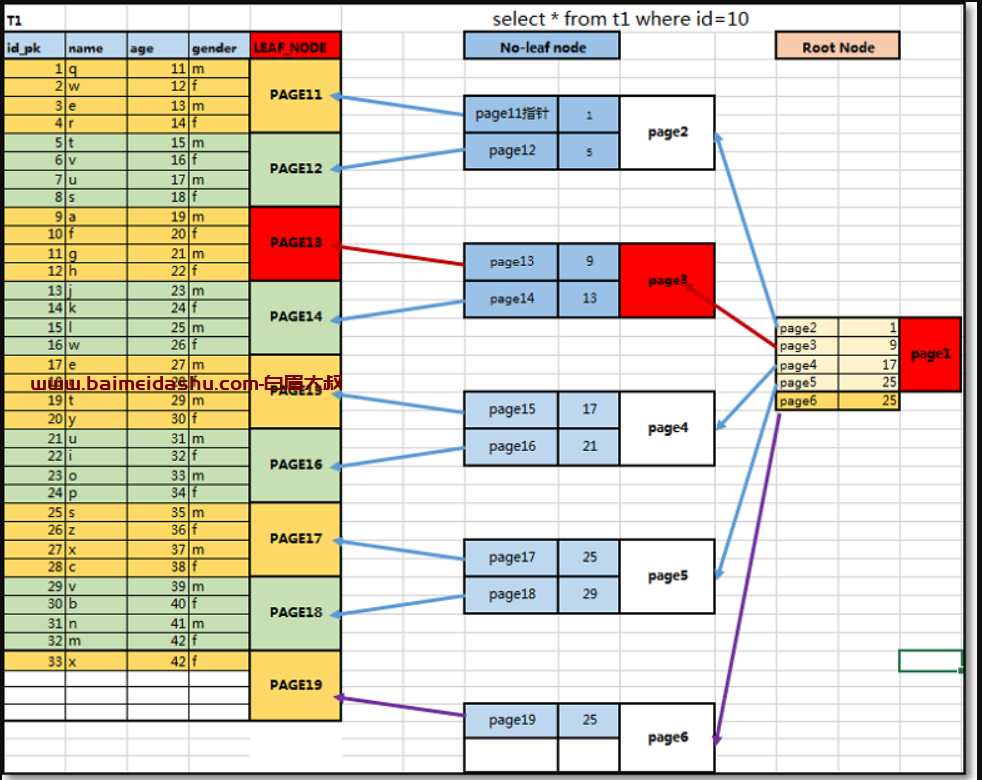
change_buffer功能配置信息:
mysql> show variables like '%change_buffer%';
+-----------------------------------------+-------+
| Variable_name | Value |
+-----------------------------------------+-------+
| innodb_change_buffer_max_size | 25 |
| innodb_change_buffering | all |
+-----------------------------------------+-------+
2 rows in set (0.00 sec)
--all: 默认值。开启buffer inserts、delete-marking operations、purges
--none: 不开启change buffer
自主优化功能三:ICP (索引下推)
属于5.6之后引用的数据库服务新特性,称之为索引下推功能,主要是针对联合索引功能起作用;
ICP应用原理:假设创建联合索引进行数据检索
idx(a,b,c)
where a=10 and b like '%x%' and c=z
在没有ICP优化机制情况:
基于联合索引的特性,查找检索数据只会依据a进行检索,可能检索到的数据页是100个数据块,会将数据放入内存中;
数据信息到达内存中后,在根据b和c的条件信息进行定位最终的聚簇索引信息,进行回表查询;
说明:基于数据库优化器的特性,遵循联合索引引用原则,SQL层面只能检索到联合索引中的A;
在应用ICP优化机制情况:
基于联合索引的特性,查找检索数据只会依据a进行检索,但是b和c也属于联合索引中的索引部分,在SQL层不能再进行索引情况下;
可以将b和c的检索工作下推交给引擎层完成,可以让引擎再调取数据到内存之前,再根据b和c的条件进行一次过滤;
可以将过滤后的数据信息再放入到内存中,然后结合获取到的聚簇索引信息,进行回表查询;
说明:基于数据库优化器的特性,可以将SQL层完成不了的检索工作,下推给引擎层完成,从而减少磁盘IO消耗,以及回表策略
ICP功能配置信息:
mysql> show variables like '%switch%';
mysql> set global optimizer_switch='index_condition_pushdown=off';
-- 实现测试练习完,需要恢复开启(操作可以省略)
# 测试练习
mysql> select * from t100w where k1='qj' and k2 like '%v%';
mysql> desc select * from t100w where k1='qj' and k2 like '%v%';
-- extra列显示using index condition信息,表示应用了索引下推
# 进行压测
mysqlslap --defaults-file=/etc/my.cnf --concurrency=100 --iterations=1 --create-schema='baimei' --query="select * from t100w where k1='qj' and k2 like '%v%" engine=innodb --number-of-queries=20000 -uroot -p123456 -h192.168.30.101 -verbose
自主优化功能四:MRR
MRR,全称(Multi-Range Read Optimization 多范围读取操作);
简单来说:MRR 通过把「随机磁盘读」,转化为「顺序磁盘读」,从而提高了索引查询的性能。
描述说明中涉及到的问题:
① 为什么要把随机读转换为顺序读? 减少磁盘压力
② 为什么顺序读就能提升读取性能?
③ 如何将随机读去转换为顺序读取? MRR
MRR功能配置信息:
mysql > set optimizer_switch='mrr=on';
mysql > set global optimizer_switch='mrr_cost_based=off';
Query OK, 0 rows affected (0.06 sec)

优化器算法扩展:BNL/BKA(自行了解)