Python的requests库是一个简洁而强大的HTTP库,用于发送HTTP请求和处理响应。它使得与Web服务进行交互变得非常简单,可以轻松地实现数据的抓取、网页的爬取等功能。比起urllib、urllib2库来说,更简单方便,所以也是许多爬虫爱好者的必选库之一。
1、爬虫的基本操作流程
1)确定目标网站的url地址;
2)通过网络请求向目标网站发送请求;
3)获取网站返回的响应数据;
4)将获取到的数据进行持久化存储,以便后续分析和处理。
2、实际案例
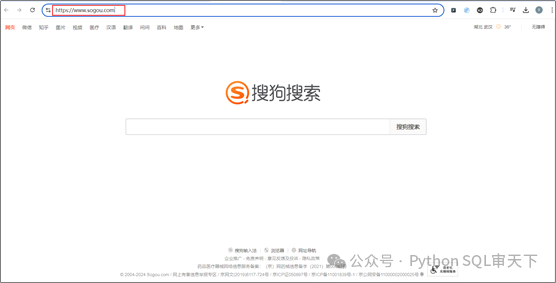
案例1:爬取搜狗首页的页面源码数据
搜狗首页如下图所示:
测试代码: * * * * * * * *
import requestsimport os os.chdir(r'E:\TestData')url = 'https://www.sogou.com/'response = requests.get(url = url)page_text = response.textwith open('sogou.html','w',encoding = 'utf-8') as fp:fp.write(page_text)
测试结果如下:
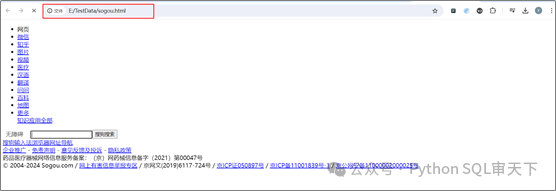
我们发现爬取的页面与浏览器访问的页面有很大的出入,这是因为我们只是对搜狗首页发送了请求,并没有请求网页的样式,所以爬取的只是网页的基础数据,而浏览器会请求到多个数据,比如说CSS样式表等。再说,样式对我们来说并不重要,我们关心的只是数据。
案例2:实现一个简易的搜狗页面采集器
我们通过在sogou页面输入关键字,来获取具体的页面信息。这样我们想看到什么样的信息,就可以通过输入什么样的关键字来搞定。
测试代码: * * * * * * * * * * * * * * * * * *
import requestsimport os os.chdir(r'E:\TestData')keyword = input('请输入一个关键字:')headers = { 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36'}params = { 'query':keyword}url = 'https://www.sogou.com/web'response = requests.get(url = url,headers = headers,params = params)response.encoding = 'utf-8'fileName = keyword + '.html'page_text = response.textwith open(fileName,'w',encoding = 'utf-8') as fp: fp.write(page_text)print(fileName,'爬取完毕!!!')

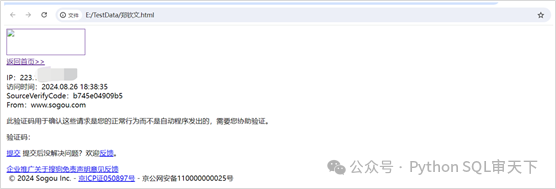
测试结果:
注意:这里我们添加了User-Agent来进行伪装浏览器操作。如果不进行伪装,则结果是下面显示的那样,获取不到任何数据,当然也不是我们所期望的。
User-Agent是HTTP协议中的一个头部字段,用于标识发送请求的客户端信息,包括客户端的软件、操作系统、版本号等信息。通过User-Agent字段,服务器可以识别客户端的类型,从而根据不同的客户端类型返回不同的页面或数据,以提供更好的用户体验。
在爬虫中,设置合适的User-Agent是非常重要的。因为有些网站会根据User-Agent来判断请求是否来自于爬虫,如果发现是爬虫请求,可能会拒绝服务或者返回错误的数据。因此,爬虫程序通常会设置一个合理的User-Agent,模拟真实的浏览器请求,以避免被识别为爬虫而被封禁或限制访问。
说白了,网页源代码也是人写的。人家开发的网站,突然有一天发现访问很慢,甚至宕机了。通过后台日志一看,居然有那么多流量访问网站,还有大量的下载操作,所以人家会在服务器中添加反爬机制,说白了还是人与人之间的较量。你能爬,我有反爬;你有反爬,我有反反爬......