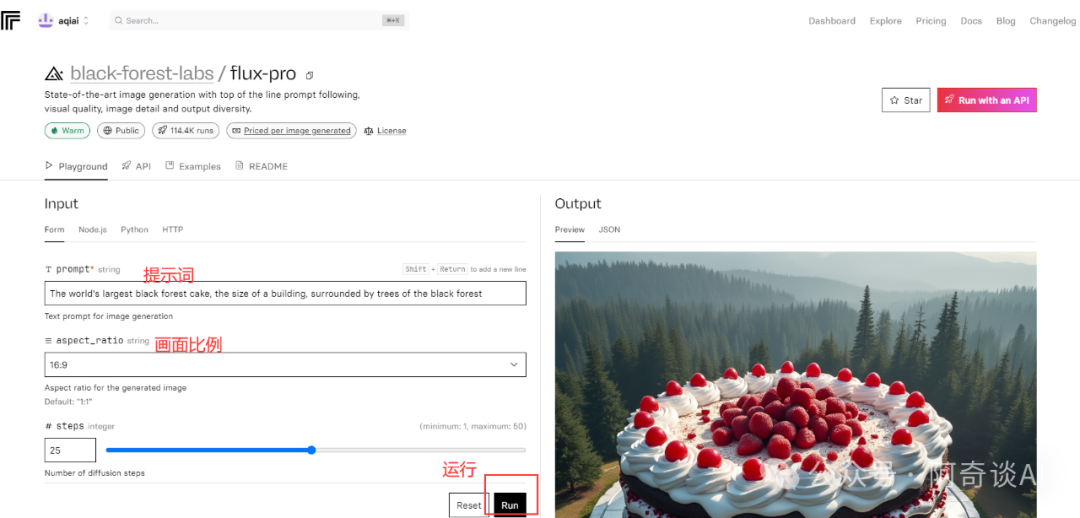
2024,AI 视频元年,也是 AI 视频工具爆发的一年。
前有快手可灵,后有 Luma 的 Dream Machine,随后沉寂许久的Runway,突然又爆出 Gen-3。
就这样,一下子,AI 视频领域热闹起来了。
大家玩得不亦乐乎。
不过这几款工具,虽强悍,但是视频人物主体的动作行为,因为依赖于提示词及系统的随机抽卡,不那么可控。
而在前几天的世界人工智能大会上,商汤推出的全球首个可控人物视频生成模型,Vimi,成了一个焦点。
嗯...不是国内首个,是全球首个!
在文末我会附上申请链接,小伙伴可以趁着内测阶段申请,早便是优势,就是当时可灵一样。
是个啥呢?
我们先来看一下官方的介绍视频:
视频来源:Vimi 官网
Vimi,全球首个可控人物视频生成AIGC产品。
可以通过动作视频、动画、声音、文字等等,然后来驱动人物图片,生成和目标动作一致的人物类视频。
当下阶段,其它的 AI 视频大模型,在人物稳定性上面,都处理的不是那么的好。
并且单次生成的时长,基本都是几秒钟。
而 Vimi,不但在人物的稳定性上有了很大的突破,而且还可以生成分钟级的单镜头人物视频。
在控制这一块,以往的 AI 视频更多的是控制头部表情动作。
Vimi,则不但可以控制人物表情,还能控制肢体动作,并在这个基础上,生成合理的头发、服饰、背景。
还支持光影变化...
我们一个一个特色来看。
可控人物
简单来说,就是可以生成高度一致性的人物表情和肢体动作。
看示例效果:
多种控制方式
Vimi,可以通过动作视频、动画、声音和文字等,来驱动图片生成视频。
能达到这样的视频效果:
分钟级单镜头
可以支持生成长度达到分钟级的单镜头人物视频。
视频来源:Vimi官网
生成合理的视频场景
Vimi 在人物的头发、服饰和背景生成这一块,会处理的更加合理,并且支持光影的变化。
就像这个样子,看细节:
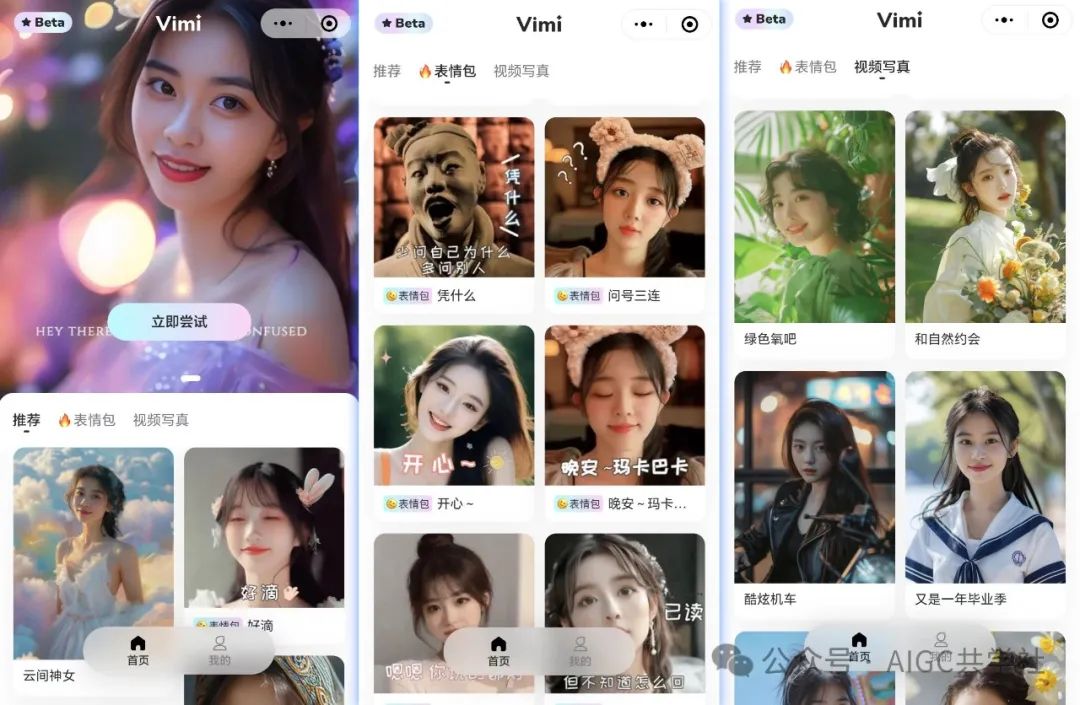
目前阶段提供的是小程序,小程序里支持 AI 生成表情包和质量超高的写真。
这个样子:
当前是内测时期,需要填写申请链接:https://vme-int.softsugar.com/questionnaire**/。**
冲,就完事了...
好了,到此结束。
如果这期内容你觉得不错,随手点个赞和"在看"吧,创作不易~感谢喜欢!