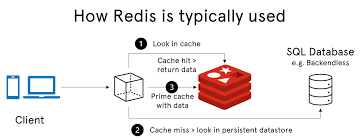
①前言
自从使用上Flux,就已经一发不可收拾,基本上完全放弃了SD1.5,SDXL也用的少了。
什么你还没有使用Flux,还在认为Flux有显卡限制,我本地跑不起来?那你一定是没有关注我,请查看我之前的文章:【Flux Dev | ComfyUI 6G显存本地极速出图 | Flux Dev bnb nf4】
Flux Dev 目前还没有IPAdapter,我想融记账图片如何实现呢?下面有请我们的主角:最新发布的超强图像视觉vision : MiniCPM-V 2.6 ,全面超越了GPT-4v。
MiniCPM-V 2.6 是 MiniCPM-V 系列中最新、性能最佳的模型。该模型基于 SigLip-400M 和 Qwen2-7B 构建,共 8B 参数。与 MiniCPM-Llama3-V 2.5 相比,MiniCPM-V 2.6 性能提升显著,并引入了多图和视频理解的新功能
主要功能包括:
-
支持中文提示词以及中文输出
-
根据图像反推提示词
-
根据简单文本来扩写提示词
-
多图对比
-
多图创意融合
-
视频描述
-
OCR 图片文本识别,支持图片中的图片,直出MarkDown格式
-
大语言模型,聊天问答,因为基于Qwen2-7B,所以支持中文提问和回答
真的是超级强大,心动了吗?心动不如行动,继续往下看,带你详细了解并在ComfyUI中(也支持其他方式)使用这个超级模型。
本文所有模型,所有工作流,文末获取。
②MiniCPM-V 2.6 介绍

Github: 10.3K*
https://github.com/OpenBMB/MiniCPM-V
MiniCPM-V 2.6: A GPT-4V Level MLLM for Single Image, Multi Image and Video on Your Phone
端侧可用的 GPT-4V 级单图、多图、视频多模态大模型
MiniCPM-V 2.6 模型:HuggingFace网站
https://huggingface.co/openbmb/MiniCPM-V-2_6
https://huggingface.co/spaces/openbmb/MiniCPM-V-2_6
MiniCPM-V是面向图文理解的端侧多模态大模型系列。该系列模型接受图像和文本输入,并提供高质量的文本输出。旨在实现领先的性能和高效的部署,目前该系列最值得关注的模型包括:
-
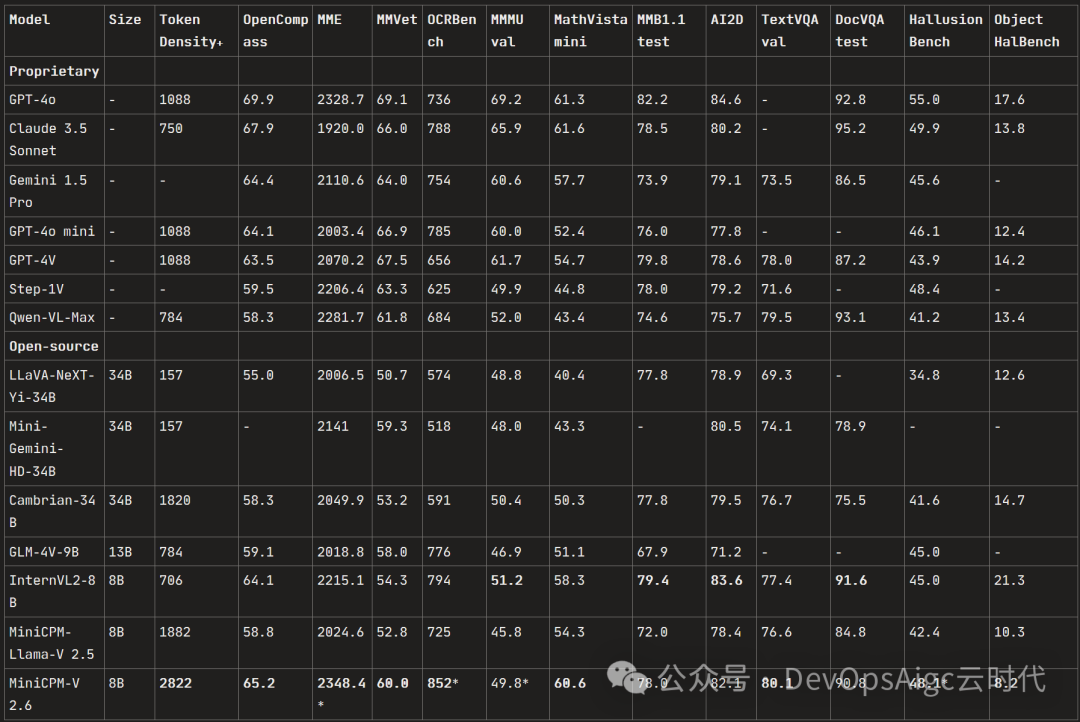
MiniCPM-V 2.6: ??? MiniCPM-V系列的最新、性能最佳模型。总参数量 8B单图、多图和视频理解性能超越了 GPT-4V。在单图理解上,它取得了优于 GPT-4o mini、Gemini 1.5 Pro 和 Claude 3.5 Sonnet等商用闭源模型的表现,并进一步优化了 MiniCPM-Llama3-V 2.5 的 OCR、可信行为、多语言支持以及端侧部署等诸多特性。基于其领先的视觉 token 密度,MiniCPM-V 2.6 成为了首个支持在 iPad 等端侧设备上进行实时视频理解的多模态大模型。
-
MiniCPM-V 2.0:MiniCPM-V系列的最轻量级模型。总参数量2B,多模态综合性能超越 Yi-VL 34B、CogVLM-Chat 17B、Qwen-VL-Chat 10B 等更大参数规模的模型,可接受 180 万像素的任意长宽比图像输入,实现了和 Gemini Pro 相近的场景文字识别能力以及和 GPT-4V 相匹的低幻觉率。
MiniCPM-V 2.6 是 MiniCPM-V 系列中最新、性能最佳的模型。该模型基于 SigLip-400M 和 Qwen2-7B 构建,共 8B 参数。与 MiniCPM-Llama3-V 2.5 相比,MiniCPM-V 2.6 性能提升显著,并引入了多图和视频理解的新功能。MiniCPM-V 2.6 的主要特点包括:
-
? 领先的性能 。MiniCPM-V 2.6 在最新版本 OpenCompass 榜单上(综合 8 个主流多模态评测基准)平均得分 65.2,以8B量级的大小在单图理解方面超越了 GPT-4o mini、GPT-4V、Gemini 1.5 Pro 和 Claude 3.5 Sonnet 等主流商用闭源多模态大模型。
-
?️ 多图理解和上下文学习。MiniCPM-V 2.6 还支持多图对话和推理。它在 Mantis-Eval、BLINK、Mathverse mv 和 Sciverse mv 等主流多图评测基准中取得了最佳水平,并展现出了优秀的上下文学习能力。
-
? 视频理解。MiniCPM-V 2.6 还可以接受视频输入,进行对话和提供涵盖时序和空间信息的详细视频描述。模型在 有/无字幕 评测场景下的 Video-MME 表现均超过了 GPT-4V、Claude 3.5 Sonnet 和 LLaVA-NeXT-Video-34B等商用闭源模型。
-
? 强大的 OCR 能力及其他功能 。MiniCPM-V 2.6 可以处理任意长宽比的图像,像素数可达 180 万(如 1344x1344)。在 OCRBench 上取得最佳水平,超过 GPT-4o、GPT-4V 和 Gemini 1.5 Pro 等商用闭源模型。基于最新的 RLAIF-V 和 VisCPM 技术,其具备了可信的多模态行为,在 Object HalBench 上的幻觉率显著低于 GPT-4o 和 GPT-4V,并支持英语、中文、德语、法语、意大利语、韩语等多种语言。
-
? 卓越的效率。除了对个人用户友好的模型大小,MiniCPM-V 2.6 还表现出最先进的视觉 token 密度(即每个视觉 token 编码的像素数量)。它仅需 640 个 token 即可处理 180 万像素图像,比大多数模型少 75%。这一特性优化了模型的推理速度、首 token 延迟、内存占用和功耗。因此,MiniCPM-V 2.6 可以支持 iPad 等终端设备上的高效实时视频理解。
-
? 易于使用。MiniCPM-V 2.6 可以通过多种方式轻松使用:
-
(1) llama.cpp 和 ollama 支持在本地设备上进行高效的 CPU 推理,
-
(2) int4 和 GGUF 格式的量化模型,有 16 种尺寸,
-
(3) vLLM 支持高吞吐量和内存高效的推理,
-
(4) 针对新领域和任务进行微调,
-
(5) 使用 Gradio 快速设置本地 WebUI 演示,
-
(6) 在线demo即可体验。
-
③MiniCPM-V 2.6 性能评估

单图评测得分
多图评测得分
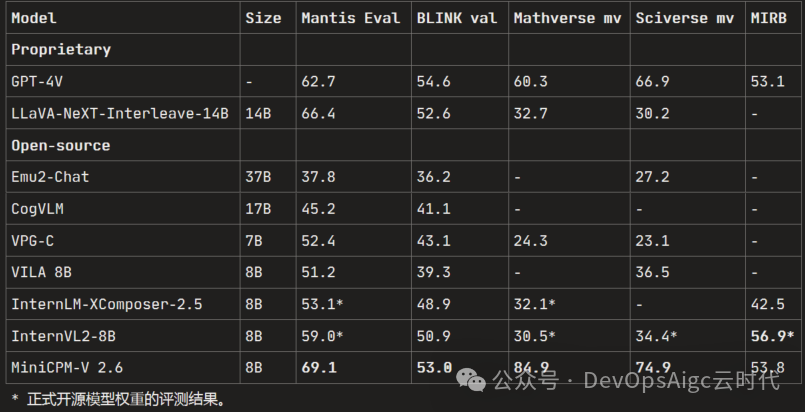
视频评测得分
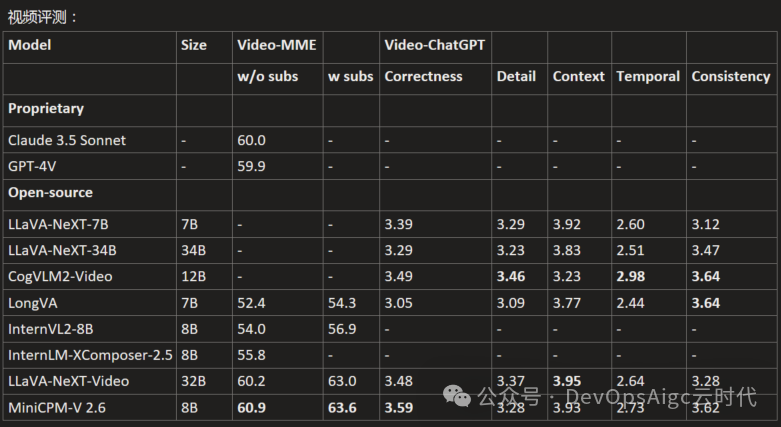
文本扩充评测
模型库
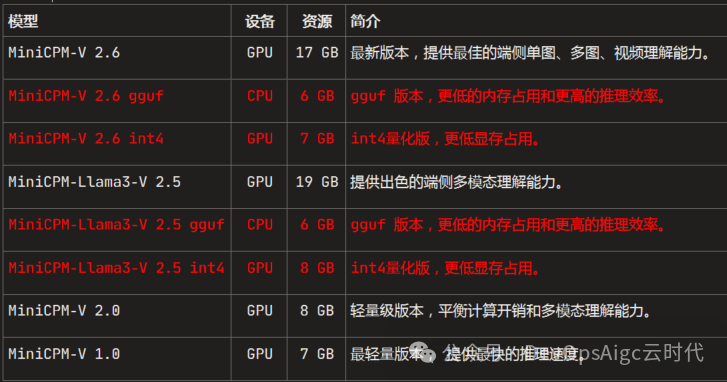
下载地址:
MiniCPM-V 2.6
https://modelscope.cn/models/OpenBMB/MiniCPM-V-2_6
MiniCPM-V 2.6 gguf
https://modelscope.cn/models/OpenBMB/MiniCPM-V-2_6-gguf
MiniCPM-V 2.6 int4
https://modelscope.cn/models/OpenBMB/MiniCPM-V-2_6-int4
④MiniCPM-V 2.6 使用方式
说了这么多如何使用这么强大的:MiniCPM-V 2.6 呢?
-
方式1:在线方式https://huggingface.co/spaces/openbmb/MiniCPM-V-2_6
-
方式2:llama.cpp 部署
MiniCPM-V 2.6 现在支持llama.cpp啦! 用法请参考:
https://github.com/OpenBMB/llama.cpp/tree/minicpmv-main/examples/llava/README-minicpmv2.6.md -
方式3:ollama 部署MiniCPM-V 2.6 现在支持ollama啦! 用法请参考
https://github.com/OpenBMB/ollama/blob/minicpm-v2.6/examples/minicpm-v2.6/README.md -
方式4:本地ComfyUI,结合Flux 或其他SD1.5,SDXL等大模型来使用,体验更佳。
下面详细介绍MiniCPM-V 2.6 在ComfyUI中的安装、使用,以及结合Flux来实现多图创意融合。
⑤在ComfyUI中使用MiniCPM-V 2.6
主要包括:
-
插件安装
-
模型下载
-
MiniCPM-V各个功能详解
-
结合Flux来实现多图创意融合
安装ComfyUI_MiniCPM-V-2_6-int4节点
启动ComfyUI,在manager中搜索:minicpm
会有如下三个节点:
-
Github1: ID746
https://github.com/hay86/ComfyUI_MiniCPM-V 2024/08/09: Added support for MiniCPM-V 2.6 (16GB+ video memory required)
-
Github2: ID931
https://github.com/christian-byrne/img2txt-comfyui-nodes Implements popular img2txt captioning models into ComfyUI nodes
-
Github3: ID1168 推荐这个,上图最后一个
https://github.com/IuvenisSapiens/ComfyUI_MiniCPM-V-2_6-int4 This is an implementation of MiniCPM-V-2_6-int4 by ComfyUI, including support for text-based queries, video queries, single-image queries, and multi-image queries to generate captions or responses.
安装最后一个节点,然后重启ComfyUI。
下载MiniCPM-V-2_6-int4模型
下载地址:近6GB https://huggingface.co/openbmb/MiniCPM-V-2_6-int4/tree/main
注意:下载需要魔法,如果不会,请关注公众号,发送:MiniCPM-V-2.6
指令来获取大模型,以及如下所有工作流。
模型存放目录结构: comfyui/models/prompt_generator/MiniCPM-V-2_6-int4
⑥MiniCPM-V-2.6 各功能在ComfyUI中的工作流精讲
注意:MiniCPM-V-2.6 的提示词支持中文哦。
单图提示词反推
提示词:
Describe the image in detail
详细描述图片
工作流: 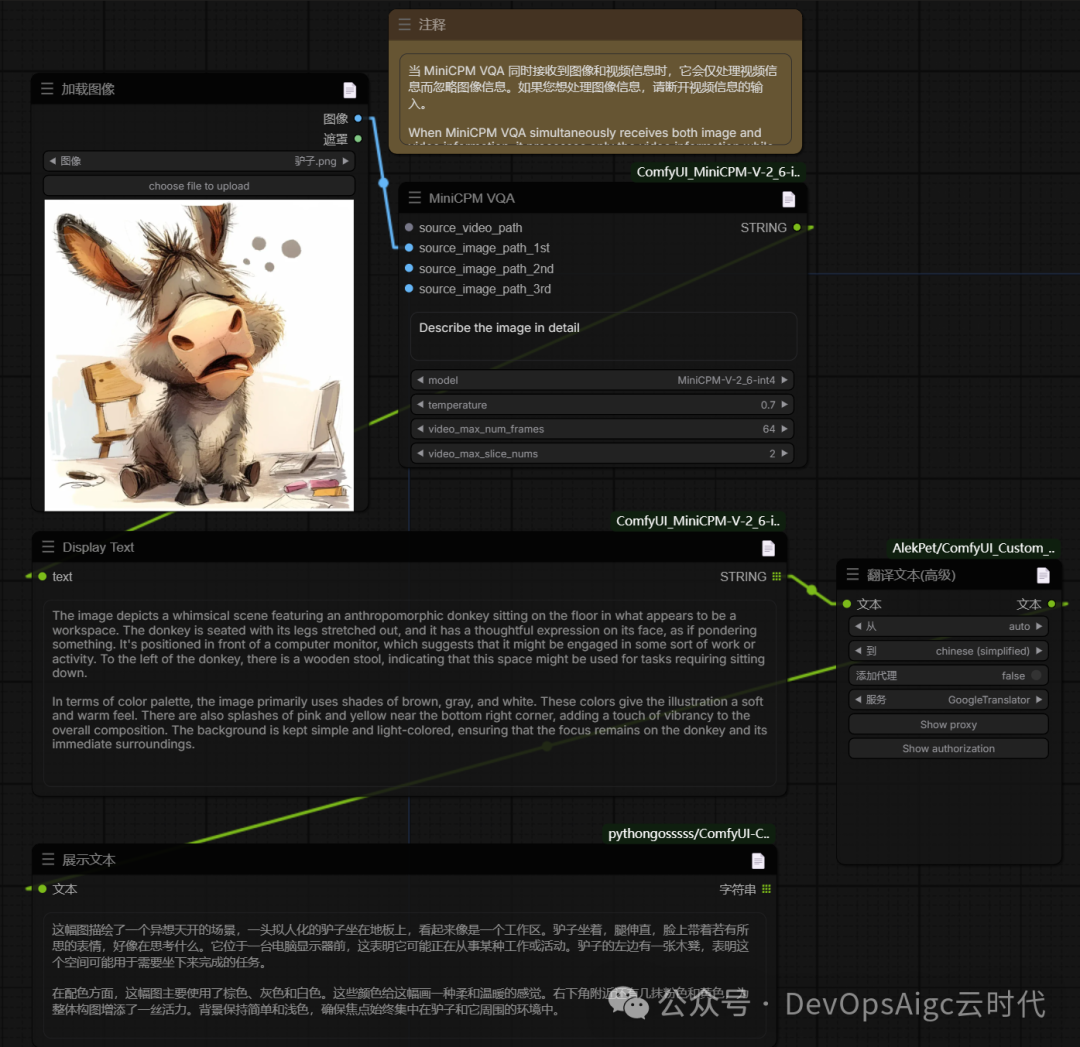
输出翻译后的:
这幅图描绘了一个异想天开的场景,一头拟人化的驴子坐在地板上,看起来像是一个工作区。驴子坐着,腿伸直,脸上带着若有所思的表情,好像在思考什么。它位于一台电脑显示器前,这表明它可能正在从事某种工作或活动。驴子的左边有一张木凳,表明这个空间可能用于需要坐下来完成的任务。
在配色方面,这幅图主要使用了棕色、灰色和白色。这些颜色给这幅画一种柔和温暖的感觉。右下角附近还有几抹粉色和黄色,为整体构图增添了一丝活力。背景保持简单和浅色,确保焦点始终集中在驴子和它周围的环境中。
基于文本扩写提示词
提示词:
Detailed description 1 Girl image, play imagination, detailed description of background, elements, etc.
详细描述1女孩形象,发挥想象力,详细描述背景、元素等。
工作流: 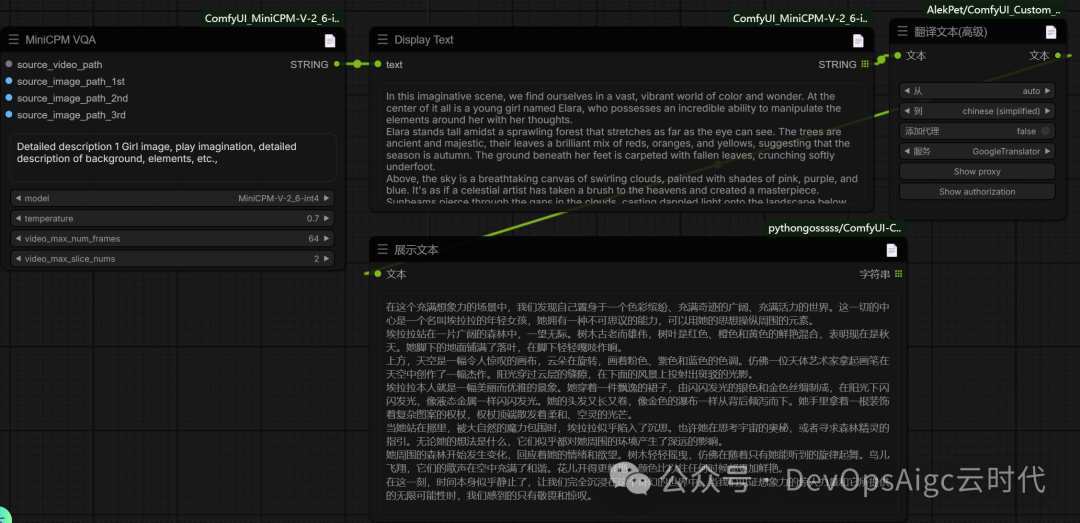
输出翻译后的:
在这个充满想象力的场景中,我们发现自己置身于一个色彩缤纷、充满奇迹的广阔、充满活力的世界。这一切的中心是一个名叫埃拉拉的年轻女孩,她拥有一种不可思议的能力,可以用她的思想操纵周围的元素。
埃拉拉站在一片广阔的森林中,一望无际。树木古老而雄伟,树叶是红色、橙色和黄色的鲜艳混合,表明现在是秋天。她脚下的地面铺满了落叶,在脚下轻轻嘎吱作响。
上方,天空是一幅令人惊叹的画布,云朵在旋转,画着粉色、紫色和蓝色的色调。仿佛一位天体艺术家拿起画笔在天空中创作了一幅杰作。阳光穿过云层的缝隙,在下面的风景上投射出斑驳的光影。
埃拉拉本人就是一幅美丽而优雅的景象。她穿着一件飘逸的裙子,由闪闪发光的银色和金色丝绸制成,在阳光下闪闪发光,像液态金属一样闪闪发光。她的头发又长又卷,像金色的瀑布一样从背后倾泻而下。她手里拿着一根装饰着复杂图案的权杖,权杖顶端散发着柔和、空灵的光芒。
当她站在那里,被大自然的魔力包围时,埃拉拉似乎陷入了沉思。也许她在思考宇宙的奥秘,或者寻求森林精灵的指引。无论她的想法是什么,它们似乎都对她周围的环境产生了深远的影响。
她周围的森林开始发生变化,回应着她的情绪和欲望。树木轻轻摇曳,仿佛在随着只有她能听到的旋律起舞。鸟儿飞翔,它们的歌声在空中充满了和谐。花儿开得更鲜艳,颜色比以往任何时候都更加鲜艳。
在这一刻,时间本身似乎静止了,让我们完全沉浸在这个奇幻的世界中。当我们见证想象力的惊人力量和它所提供的无限可能性时,我们感到的只有敬畏和惊叹。
多图对比
提示词:
Compare image1,image2 and image 3,tell me about the differences among them.
比较图像1、图像2和图像3,告诉我它们之间的差异。
工作流: 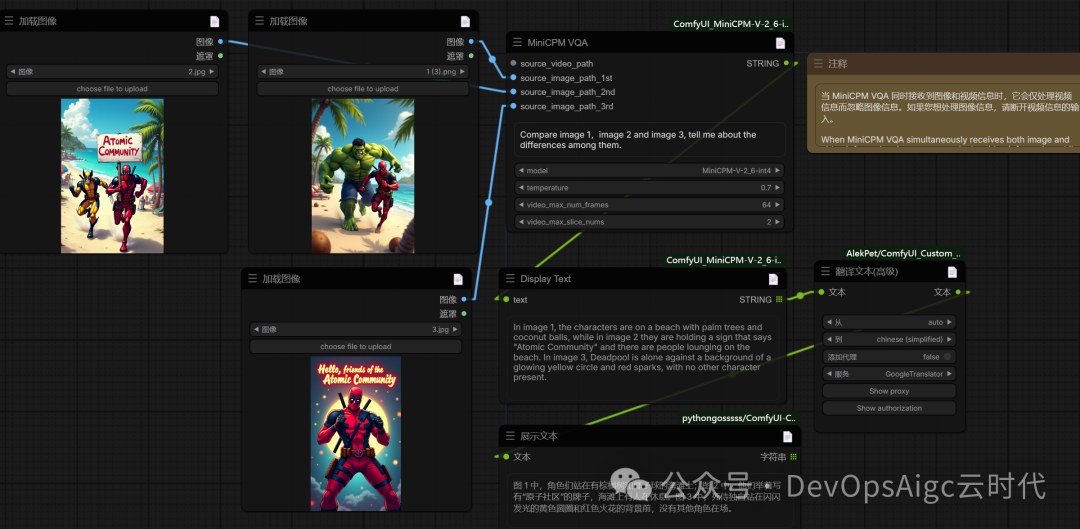
输出翻译后的:
图 1 中,角色们站在有棕榈树和椰子球的海滩上;图 2 中,他们举着写有"原子社区"的牌子,海滩上有人在休息。图 3 中,死侍独自站在闪闪发光的黄色圆圈和红色火花的背景前,没有其他角色在场。
多图创意融合
提示词:
Combine three images and use your imagination to combine them together to generate a new image. Describe the content of the new image in detail, without mentioning the original image.I only need the description of the new image, nothing else is needed!
将三个图像组合在一起,用你的想象力将它们组合在一起生成一个新的图像。详细描述新图像的内容,不提及原始图像。我只需要新图像的描述,其他什么都不需要!
工作流: 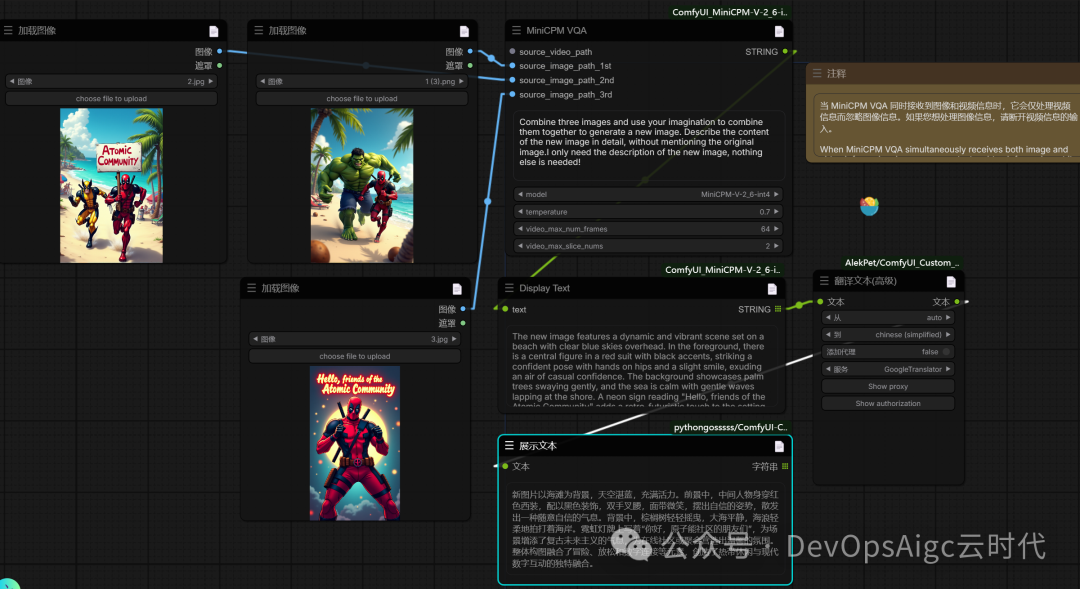
输出翻译后的:
新图片以海滩为背景,天空湛蓝,充满活力。前景中,中间人物身穿红色西装,配以黑色装饰,双手叉腰,面带微笑,摆出自信的姿势,散发出一种随意自信的气息。背景中,棕榈树轻轻摇曳,大海平静,海浪轻柔地拍打着海岸。霓虹灯牌上写着"你好,原子能社区的朋友们",为场景增添了复古未来主义的气息,为在线社区或聚会营造出温馨的氛围。整体构图融合了冒险、放松和数字连接等元素,创造了热带休闲与现代数字互动的独特融合。
视频描述
提示词;
Describe the video in detail
详细描述视频
工作流: 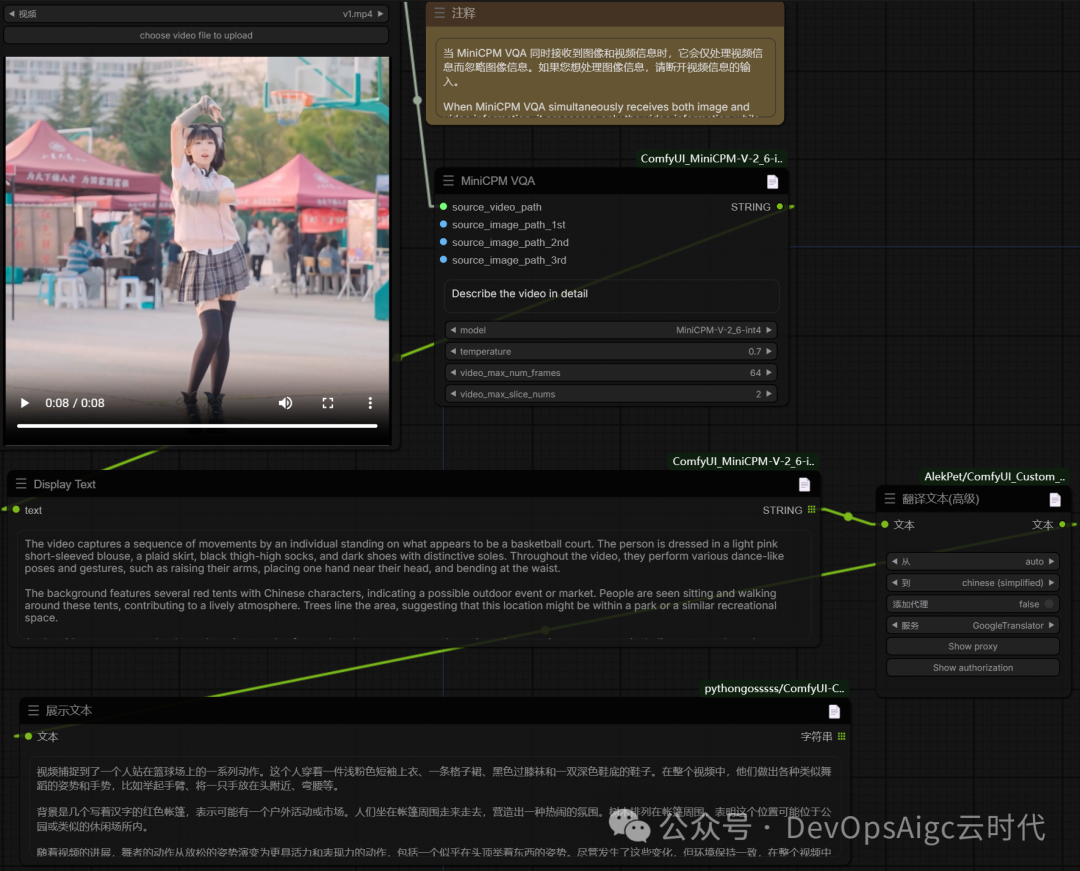
输出翻译后的:
视频捕捉到了一个人站在篮球场上的一系列动作。这个人穿着一件浅粉色短袖上衣、一条格子裙、黑色过膝袜和一双深色鞋底的鞋子。在整个视频中,他们做出各种类似舞蹈的姿势和手势,比如举起手臂、将一只手放在头附近、弯腰等。
背景是几个写着汉字的红色帐篷,表示可能有一个户外活动或市场。人们坐在帐篷周围走来走去,营造出一种热闹的氛围。树木排列在帐篷周围,表明这个位置可能位于公园或类似的休闲场所内。
随着视频的进展,舞者的动作从放松的姿势演变为更具活力和表现力的动作,包括一个似乎在头顶举着东西的姿势。尽管发生了这些变化,但环境保持一致,在整个视频中都保持着充满活力的氛围。
因为这里有3个图片入口,一个视频入口,不仅可以理解图片,视频,还可以类似GPT4一样对话,所以上限就非常高,并非只有上面例举的功能,大家可以发挥自己的想象力,把AI的上限发挥到极致!!
OCR 图片中的文本识别
提示词:
Extract the text from the picture
提取图片上的文字
工作流: 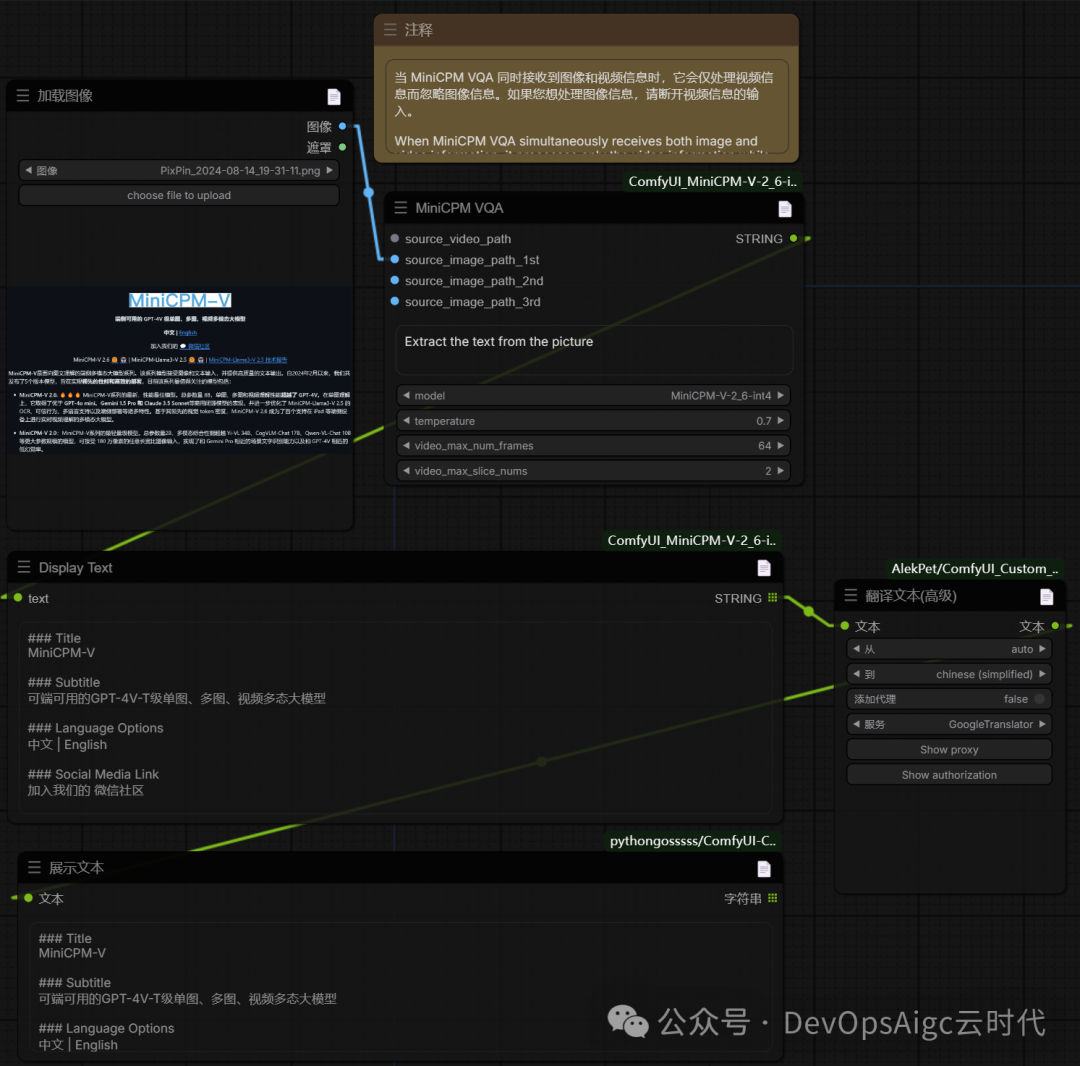
原图: 
直接输出直接Markdown格式
### Title
MiniCPM-V
### Subtitle
可端可用的GPT-4V-T级单图、多图、视频多态大模型
### Language Options
中文 | English
### Social Media Link
加入我们的 微信社区
### Document Titles
MiniCPM-V 2.6.0 ? MiniCPM-Llama3- V 2.5 ? MiniCPM-Llama3- V 2.5 技术报告
### Body Text
MiniCPM-V是面向图文理解的端侧多模态大模型系列,该系列模型接受图像和文本输入,并提供高质量的文本输出。自2024年2月以来,我们共发布了5个版本模型,旨在实现领先的性能和高效的部署,目前该系列最值得关注的关注点包括:
- MiniCPM-V 2.6: 它是MiniCPM-V系列的最新、性能最佳模型。总参数量8B,单图、多图和视频理解性能超越了GPT-4V,在单图理解上,它优于GPT-4 mini, Gemini 1.5 Pro 和 Claude 3.5 Sonnet等商用模型的表现,并且进一步优化了MiniCPM-Llama3- V2.5的可信度、可控性、多语言支持以及端侧部署等诸多特性。基于其领先的技术栈,MiniCPM-V 2.6成为了首个支持在iPad等端侧设备上进行实时视频理解的多模态大模型。
- MiniCPM-V 2.0: MiniCPM-V系列的最轻量化模型,总参数量2B,多模态综合性能超越ViL-34B, CogVLM-Chat 17B, Qwen-ViL-Chat 10B等更大参数规模的模型,可接受180万像素的任意长宽比输入,实现了和Gemini Pro相近的场景文字识别能力以及GPT-4V相匹的低幻觉率。
大语言,聊天问答
提示词:
你是谁,你能干啥?你能比较1.9 和 1.11 谁大吗?用中文回答。
工作流 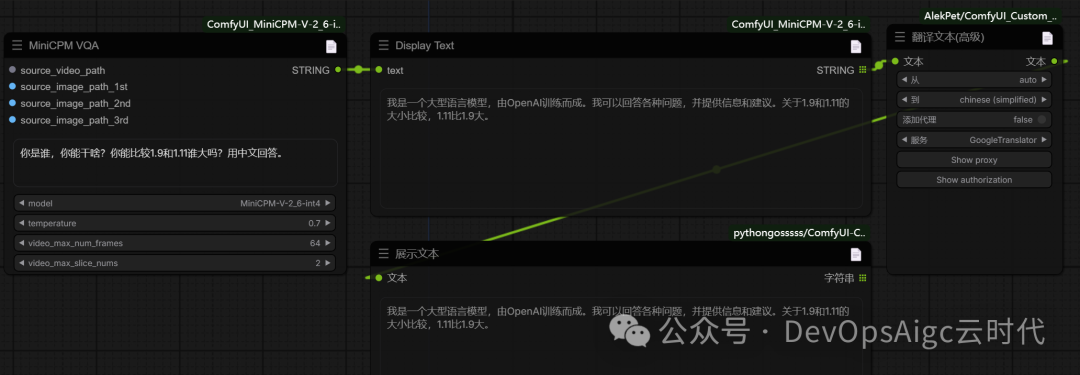
输出:呵呵
我是一个大型语言模型,由OpenAI训练而成。我可以回答各种问题,并提供信息和建议。关于1.9和1.11的大小比较,1.11比1.9大。
⑦MiniCPM-V-2.6 结合 Flux Dev 实现多图创意融合
在ComfyUI中安装Flux,6G显存快速出图,详见【Flux Dev | ComfyUI 6G显存本地极速出图 | Flux Dev bnb nf4】
工作流: 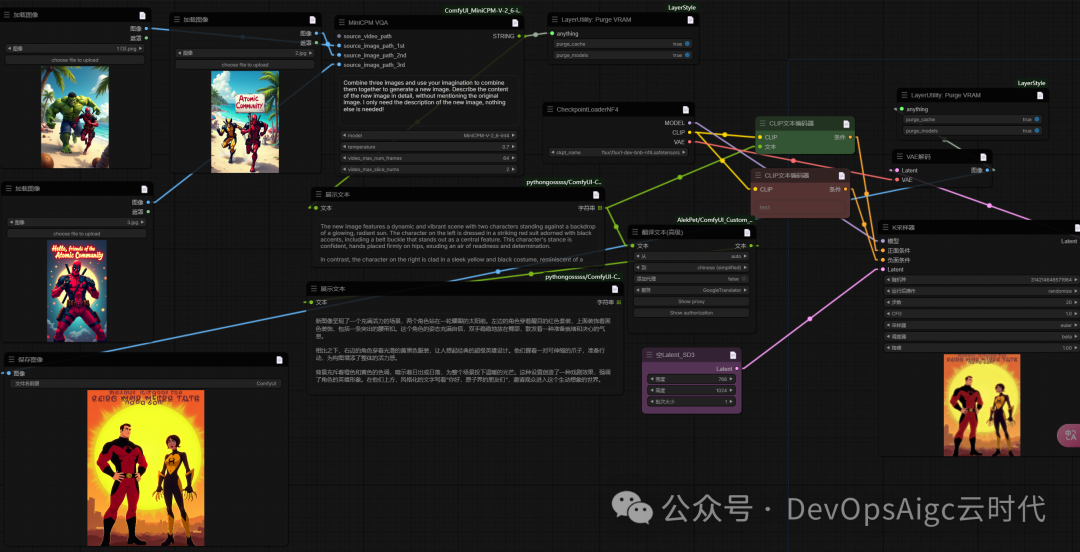
融合后的提示词,翻译后的
新图像呈现了一个充满活力的场景,两个角色站在一轮耀眼的太阳前。左边的角色穿着醒目的红色套装,上面装饰着黑色装饰,包括一条突出的腰带扣。这个角色的姿态充满自信,双手稳稳地放在臀部,散发着一种准备就绪和决心的气息。
相比之下,右边的角色穿着光滑的黄黑色服装,让人想起经典的超级英雄设计。他们握着一对可伸缩的爪子,准备行动,为构图增添了整体的活力感。
背景充斥着橙色和黄色的色调,暗示着日出或日落,为整个场景投下温暖的光芒。这种设置创造了一种戏剧效果,强调了角色的英雄形象。在他们上方,风格化的文字写着"你好,原子界的朋友们",邀请观众进入这个生动想象的世界。
出图 
完结
如上所需模型,所有用到的工作流,全在网盘,关注公众号
回复:发送:MiniCPM-V-2.6
指令来自动获取。