V-Express
论文:https://arxiv.org/abs/2406.02511
开源地址:https://github.com/tencent-ailab/V-Express/
在以往的说话人生成项目中,音频信号条件较弱,通常会被面部姿势和参考图像等更强的型号所掩盖,然而,弱信号直接训练会导致收敛困难。
V-Express方法通过渐进式训练和条件退出操作来平衡不同的控制信号,逐渐实现弱条件的有效控制,从而实现同时考虑面部姿态、参考图像和音频的生成能力。
框架如下
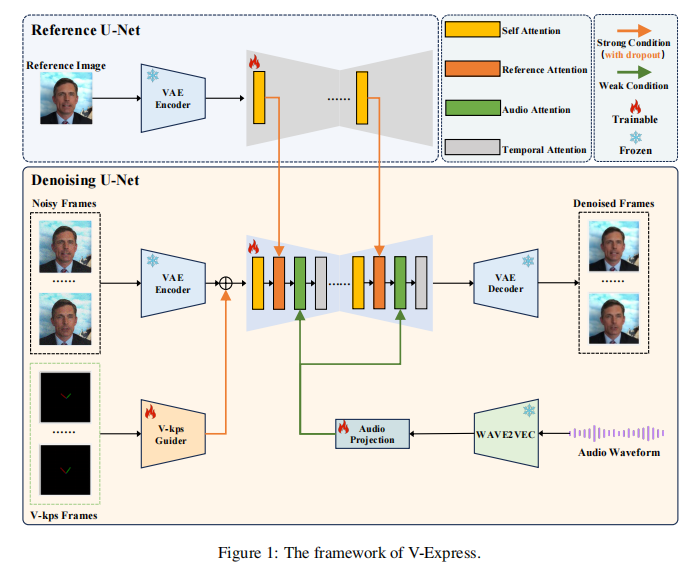
V-Express的主干是一个去噪的U-Net,在此条件下对输入的多帧噪声潜进行去噪。去噪U-Net的架构与SDv1.5非常相似,关键的区别在于每个U-Net都有四个注意层transformer块,而不是两个。
第一个注意层是自我注意力层,就像在SDv1.5中一样。第二和第三个注意层是交叉注意层。其中第二个注意层,称为参考注意层,编码与参考图像的关系,第三个注意层称为音频注意层,负责编码与音频的关系。这三个注意层都是空间注意层。第四个注意层,称为运动注意层,是一个时间智能的自注意层,它负责捕获视频帧之间的时间关系。此外,V-Express还集成了三个关键模块:ReferenceNet、V-Kps Guider和Audio Projection,分别用于对参考图像、V-Kps图像和音频进行编码。
Reference U-Net
负责对参考图像进行编码以便实现外观的一致性。架构与SD1.5保持一致,在ReferenceNet的每个Transformer块中,参考特征由自注意力层提取,然后作为去噪U-Net中相应Transformer块的第二注意层中的key和value。ReferenceNet在参考图像中不加入噪声,仅用于对参考图像进行编码,在扩散过程中只进行一次前向传递。此外,为了不引入其他额外信息,将空文本输入ReferenceNet的交叉注意层。
V-Kps Guider
V-Kps引导器负责对V-Kps图像进行编码,其是一种轻量级的卷积模型,它将每个V-Kps图像编码成一个V-Kps特征,该特征与latent形状相匹配。随后,在输入去噪U-Net之前,直接将多帧latents与编码后的V-Kps特征相加。
Audio Projection
负责对音频特征进行预处理,使其与每个视频帧对齐,是的输出视频中的嘴唇与响应的音频同步。音频输入以16 kHz的采样率对音频进行重采样,然后使用预训练的音频编码器Wav2Vec2,将重采样的音频转换为嵌入序列送到Audio Projection。
Motion Attention Layers
负责捕获连续帧之间的时间依赖关系,确保生成的帧表现出平滑和连贯的过度,保持整个视频序列的时间一致性。具体来说,给定一个隐藏状态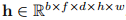 ,其中b、f、d、h和w分别表示批大小、帧数、特征维度、高度和宽度,运动注意层通过重塑隐藏状态
,其中b、f、d、h和w分别表示批大小、帧数、特征维度、高度和宽度,运动注意层通过重塑隐藏状态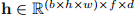 并沿着帧序列执行自关注来实现有效捕获帧间依赖关系。
并沿着帧序列执行自关注来实现有效捕获帧间依赖关系。
训练分为三阶段
-
第一阶段的重点是单帧生成,V-Express接收一帧输入并计算相应的去噪损失。在此阶段,只训练ReferenceNet、V-Kps Guider和去噪U-Net。注意,在四个注意层中,音频注意层和运动注意层的权重没有更新。这两个注意层由于零初始化的"to-out"线性层会被跳过
-
第二阶段侧重于多帧生成,其中V-Express接收多帧输入并预测添加的多帧噪声。在此阶段,只训练音频投影层、音频注意层和运动注意层,而其他模块的参数保持不变。
-
第三阶段同样侧重于多帧生成。然而,这个阶段涉及全局微调,其中更新了所有参数。
效果示例炸裂
下面的视频中展示了不同参数产生的不同效果。可以根据自己的需要相应地调整参数。
同时有Comfyui版本
https://github.com/tiankuan93/ComfyUI-V-Express
感兴趣的可以去玩玩。
MusePose
开源地址:https://github.com/TMElyralab/MusePose
MusePose是TME开源Muse系列的最后一个模块,专注于基于姿态等控制信号下虚拟人图像到视频的AI驱动生成。当前发布的模型是通过优化Moore-AnimateAnyone实现的AnimateAnyone。
所以,其框架是大体遵循AnimatedAnyone的,
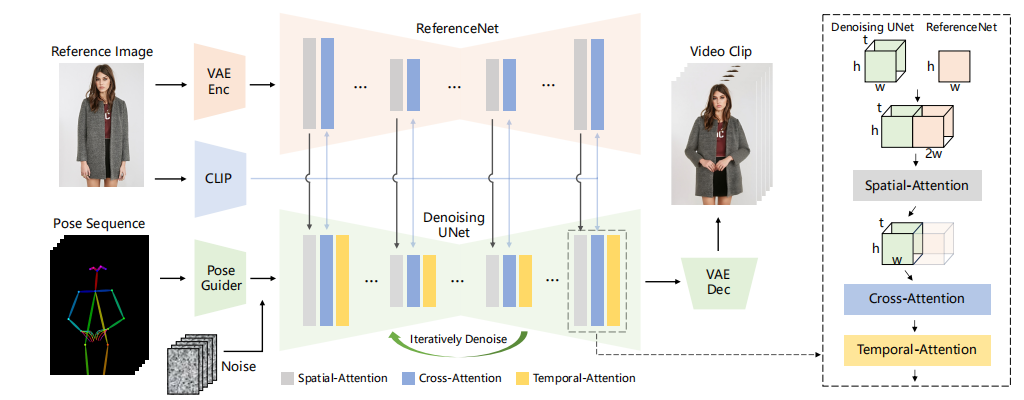
AnimatedAnyone框架
MusePose主要有下贡献:
-
发布的模型可以在给定的姿势序列下生成参考图像中人物角色的舞蹈视频,结果质量超过了同一主题中几乎所有当前的开源模型。
-
发布了姿态对齐算法,用户可以将任意舞蹈视频对齐到任意参考图像,这大大提高了推理性能,确保生成的视频中的人物动作与输入姿态序列一致,增强了模型的可用性。
-
修复了Moore-AnimateAnyone的几个重要的错误,优化部分代码。
发布的效果示例依然是炸裂。
同时也开源了Comfyui版本,
https://github.com/tiankuan93/ComfyUI-V-Express
自己部署用自己的数据体验了下,针对普通场景效果还行,对于非常规虚拟人场景真的是。。。还有较大的进步空间~~
效果
-
一致性较好
-
运动对齐较好
-
姿态对齐算法有bug,针对一些检测不到或者检测错误的关键点对齐后效果就有点诡异了,MusePose采用的是硬对齐,不知道配合模型回归,训练一个关键点对齐模型会怎样?
点击下方 卡片 ,关注"AICV与前沿 "********