CUDA编程中内存分为主机内存(内存条)与设备内存(显存),为提高计算效率,需要设计程序降低内存的数据搬运,或使用快速的内存寄存数据。
共享内存 {#共享内存}
CPU和GPU组成异构计算架构,如果想从内存上优化程序,我们必须尽量减少主机与GPU设备间的数据拷贝,并将更多计算从主机端转移到GPU设备端,我们要尽量在设备端初始化数据,并计算中间数据,并尽量不做无意义的数据回写。
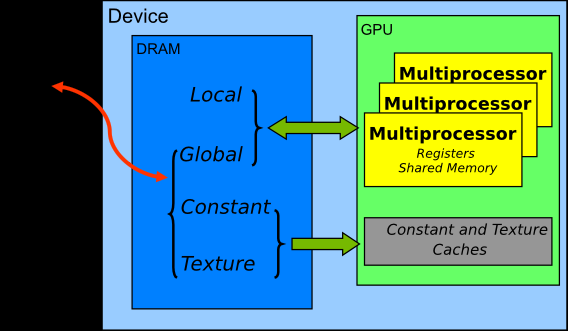
GPU的内存结构如图所示:GPU的计算核心都在Streaming Multiprocessor(SM)上,SM里有计算核心可直接访问的寄存器(Register)和共享内存(Shared Memory) ;多个SM可以读取显卡上的显存,包括全局内存(Global Memory)。
每个SM上的Shared Memory相当于该SM上的一个缓存,一般都很小,Telsa V100的Shared Memory也只有96KB。注意,Shared Memory和Global Memory的字面上都有共享的意思,但是不要将两者的概念混淆,Shared Memory离计算核心更近,延迟很低;Global Memory是整个显卡上的全局内存,延迟高。
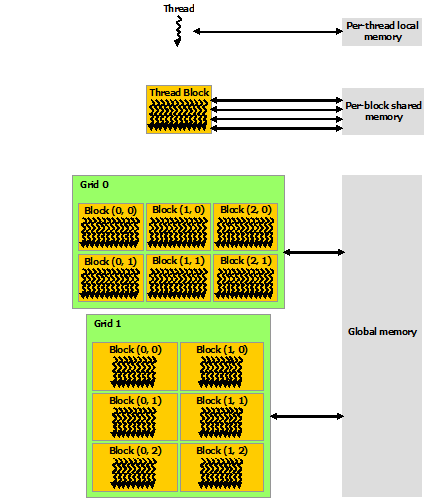
从软件角度来看,CUDA的线程可以访问不同级别的存储,每个Thread有独立的私有内存;每个Block中多个Thread都可以在该Block的Shared Memory中读写数据;整个Grid中所有Thread都可以读写Global Memory。Shared Memory的读写访问速度会远高于Global Memory。内存优化一般主要利用Shared Memory技术。下文将以矩阵乘法为例,展示如何使用Shared Memory来优化程序。
普通矩阵乘法 {#普通矩阵乘法}
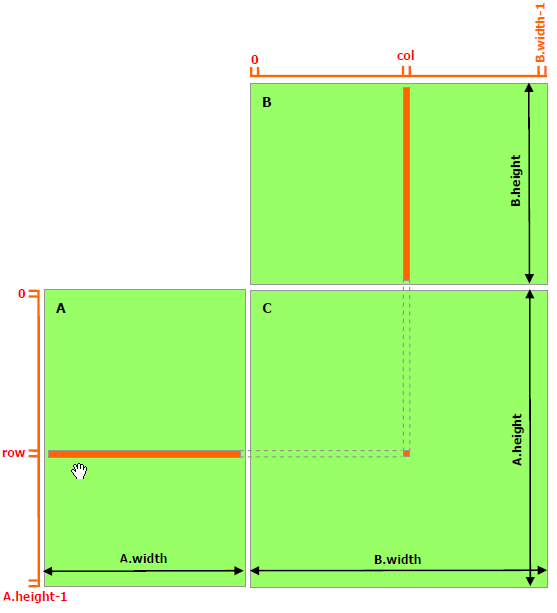
一个
C = AB的矩阵乘法运算,需要我们把A的某一行与B的某一列的所有元素一一相乘,求和后,将结果存储到结果矩阵C的(row, col)上。在这种实现中,每个线程都要读取A的一整行和B的一整列,共计算M行*P列。以计算第row行为例,计算C[row, 0]、C[row, 1]...C[row, p-1]这些点时都需要从显存的Global Memory中把整个第row行读取一遍。可以算到,A矩阵中的每个点需要被读 B.width 次,B矩阵中的每个点需要被读 A.height 次。这样比较浪费时间。因此,可以将多次访问的数据放到Shared Memory中,减少重复读取的次数,并充分利用Shared Memory的延迟低的优势。
基于Shared Memory的矩阵乘法 {#基于Shared-Memory的矩阵乘法}
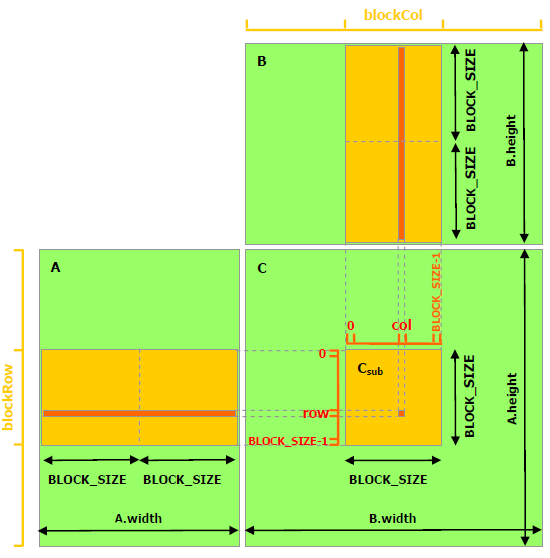
接下来的程序利用了Shared Memory来做矩阵乘法。这个实现中,跟未做优化的版本相同的是,每个Thread计算结果矩阵中的一个元素,不同的是,每个CUDA Block会以一个 BLOCK_SIZE * BLOCK_SIZE 子矩阵为基本的计算单元。具体而言,需要声明Shared Memory区域,数据第一次会从Global Memory拷贝到Shared Memory上,接下来可多次重复利用Shared Memory上的数据。
进行Shared Memory优化后,计算部分的耗时减少了近一半:
补充说明 {#补充说明}
- 声明Shared Memory。这里使用了
cuda.shared.array(shape,type),shape为这块数据的向量维度大小,type为Numba数据类型,例如是int32还是float32。这个函数只能在设备端使用。定义好后,这块数据可被同一个Block的所有Thread共享。需要注意的是,这块数据虽然在核函数中定义,但它不是单个Thread的私有数据,它可被同Block中的所有Thread读写。 - 数据加载。每个Thread会将A中的一个元素加载到sA中,一个Block的 BLOCK_SIZE x BLOCK_SIZE 个Thread可以把sA填充满。
cuda.syncthreads()会等待Block中所有Thread执行完之后才执行下一步。所以,当执行完这个函数的时候,sA和sB的数据已经拷贝好了。 - 数据复用。A中的某个点,只会被读取 B.width / BLOCK_SIZE 次;B中的某个点,只会被读 A.height / BLOCK_SIZE 次。
for n in range(BLOCK_SIZE)这个循环做子矩阵向量乘法时,可多次复用sA和sB的数据。 - 子矩阵的数据汇总。我们以一个 BLOCK_SIZE x BLOCK_SIZE 的子矩阵为单位分别对A从左到右,对B从上到下平移并计算,共循环 A.width / BLOCK_SIZE 次。在某一步平移,会得到子矩阵的点积。
for m in range(math.ceil(A.shape[1] / BLOCK_SIZE))这个循环起到了计算A从左到右与B从上到下点积的过程。
参考资料 {#参考资料}
文章链接:
https://www.zywvvd.com/notes/study/deep-learning/speed-up/cuda-shared-memory/cuda-shared-memory/