当核心数量不够或想限制当前任务使用的GPU核心数时可以使用网格跨步的思路编写CUDA程序。
背景 {#背景}
CUDA的执行配置:
[gridDim, blockDim]中的blockDim最大只能是1024,但是并没提到gridDim的最大限制。英伟达给出的官方回复是gridDim最大为一个32位整数的最大值,也就是2,147,483,648,大约二十亿。这个数字已经非常大了,足以应付绝大多数的计算,但是如果对并行计算的维度有更高需求呢?答案是网格跨步,它能提供更优的并行计算效率。
网格跨步 {#网格跨步}
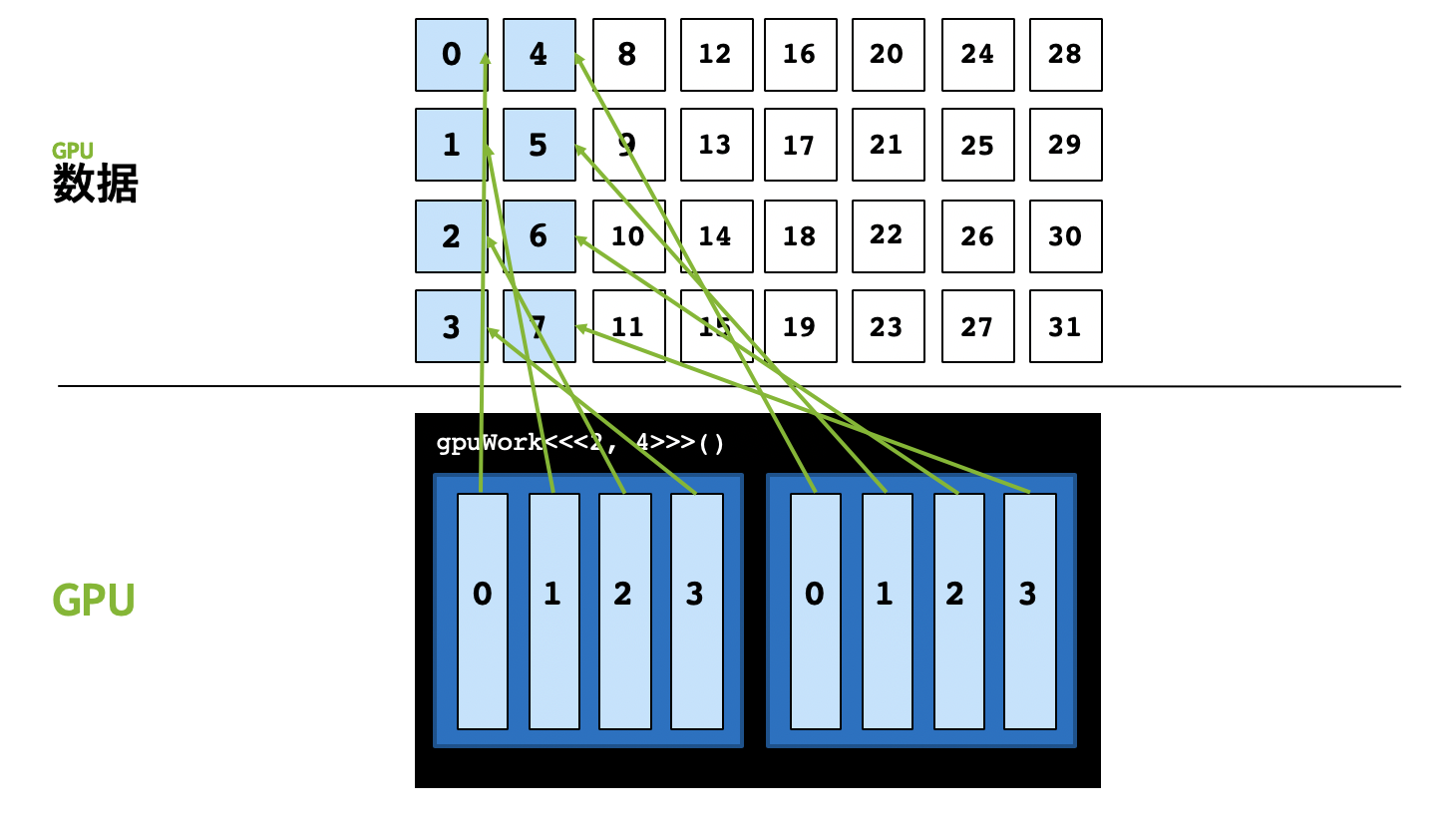
- 这里仍然以
[2, 4]的执行配置为例,该执行配置中整个grid只能并行启动8个线程,假如我们要并行计算的数据是32,会发现后面8号至31号数据共计24个数据无法被计算。
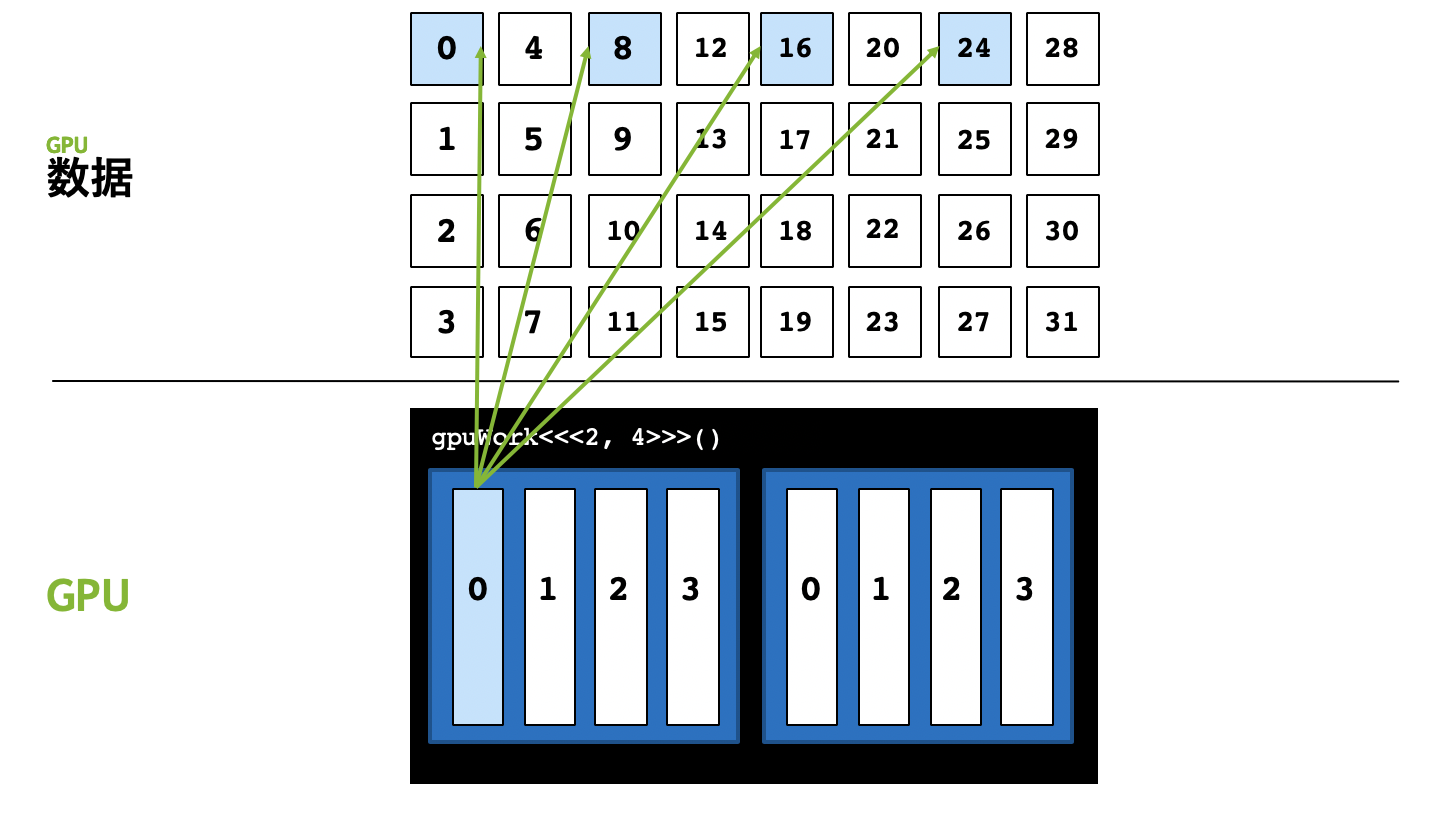
- 我们可以在0号线程中,处理第0、8、16、24号数据,这样就能解决数据远大于执行配置中的线程总数的问题,用程序表示,就是在核函数里再写个for循环。
优势 {#优势}
- 扩展性:可以解决数据量比线程数大的问题
- 线程复用:CUDA线程启动和销毁都有开销,主要是线程内存空间初始化的开销;不使用网格跨步,CUDA需要启动大于计算数的线程,每个线程内只做一件事情,做完就要被销毁;使用网格跨步,线程内有
for循环,每个线程可以干更多事情,所有线程的启动销毁开销更少。 - 方便调试:我们可以把核函数的执行配置写为
[1, 1],如下所示,那么核函数的跨步大小就成为了1,核函数里的for循环与CPU函数中顺序执行的for循环的逻辑一样,非常方便验证CUDA并行计算与原来的CPU函数计算逻辑是否一致。
参考资料 {#参考资料}
文章链接:
https://www.zywvvd.com/notes/study/deep-learning/speed-up/cuda-grid-step/cuda-grid-step/



![渗透测试|[hvv利器]cs4.4修改去特征狗狗版(美化ui,去除特征,自带bypass核晶截图等)](https://img1.51tbox.com/static/2024-11-07/HxPubgSSCmux.jfif)