1、parquet 介绍
> 略....
2、本地测试环境
- doris版本 1.2.4-1
创建doris表
#创建表 并且添加模拟数据
drop table if exists load_parquet_file_test;
CREATE TABLE IF NOT EXISTS load_parquet_file_test
(
id INT,
name VARCHAR(50),
age TINYINT
)
unique key(id)
DISTRIBUTED BY HASH(id) BUCKETS 3
PROPERTIES
(
"replication_num" = "1"
);
INSERT INTO load_parquet_file_test VALUES("1","A1",21);
INSERT INTO load_parquet_file_test VALUES("2","A2",22);
INSERT INTO load_parquet_file_test VALUES("3","A3",23);
INSERT INTO load_parquet_file_test VALUES("4","A4",24);
INSERT INTO load_parquet_file_test VALUES("5","A5",25);
INSERT INTO load_parquet_file_test VALUES("6","A6",26);
INSERT INTO load_parquet_file_test VALUES("7","A7",27);
INSERT INTO load_parquet_file_test VALUES("8","A8",28);
INSERT INTO load_parquet_file_test VALUES("9","A9",29);
3、ParQuet数据格式导入
1、本地文件导入 Steam Load 导入
# 语法示例
curl \
-u user:passwd \ # 账号密码
-H "label:load_2023" \ # 本次任务的唯一标识
-H "column_separator:," \ # 分隔符,
-H "columns:name,age,id" \
-H "format:parquet" \ -- 指定导入的类型为parquet
-T 文件地址 \
http://主机名:端口号/api/库名/表名/_stream_load
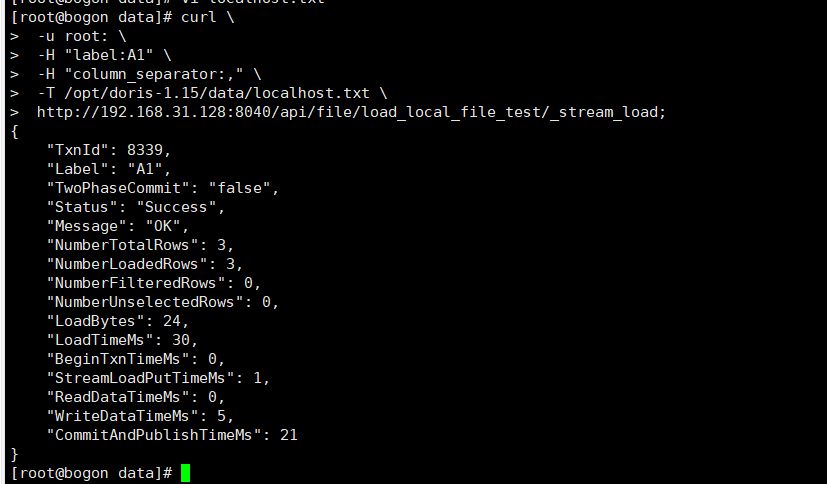
执行 curl 命令导入本地文件(这个命令不是在mysql端执行的哦):
-
user:passwd 为在 Doris 中创建的用户。初始用户为 admin / root,密码初始状态下为空。
-
host:port 为 BE 的 HTTP 协议端口,默认是 8040,可以在 Doris 集群 WEB UI页面查看。
-
label: 导入任务的标签,相同标签的数据无法多次导入。(标签默认保留30分钟)
-
column_separator:用于指定导入文件中的列分隔符,默认为\t。
-
line_delimiter:用于指定导入文件中的换行符,默认为\n。
-
columns:用于指定文件中的列和table中列的对应关系,默认一一对应
-
format: 指定导入数据格式,默认是csv,支持json格式 parquet。
-
read_json_by_line: 布尔类型,为true表示支持每行读取一个json对象,默认值为false。
1、导入成功
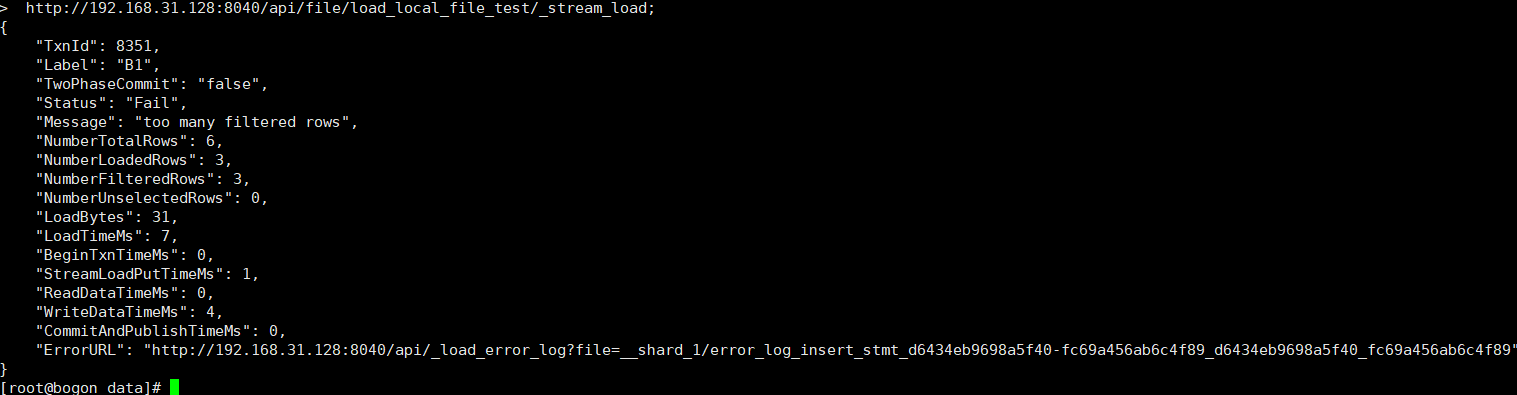
2、导入失败
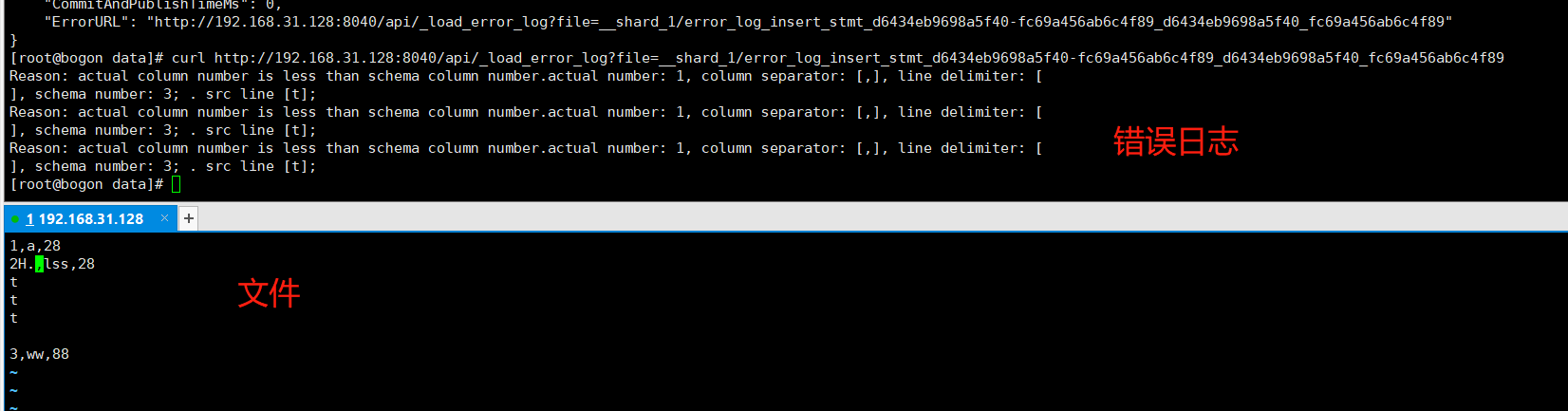
3、失败查看日志
导入失败可以curl ErrorURL 查看日志
2、Broker Load 导入
详情参考官方文档 Broker Load官网
语法参数(参数顺序不对,可能有问题)
-
LOAD LABEL
test.label_202204 -
每个导入需要指定一个唯一的 Label。后续可以通过这个 label 来查看作业进度。
-
MERGE|APPEND|DELETE
-
不写就是
append -
DATA INFILE
-
指定需要导入的文件路径。可以是多个。可以使用通配符。路径最终必须匹配到文件,如果只匹配到目录则导入会失败。。
-
INTO TABLE
table_name -
导入的表名字
-
PARTITION (p1, p2, ...)
-
导入到哪些分区,不符合这些分区的就会被过滤掉
-
COLUMNS TERMINATED BY ","
-
指定分隔符 仅在 CSV 格式下有效。仅能指定单字节分隔符。
-
FORMAT AS "file_type"
- 指定文件类型,支持 CSV、PARQUET 和 ORC 格式。默认为 CSV。
-
(column_list)
-
指定导入哪些列
-
COLUMNS FROM PATH AS (c1, c2, ...)
-
指定从导入文件路径中抽取的列。
案例
LOAD LABEL label_2023_06_24_
(
DATA INFILE("hdfs://192.168.31.128:9820/d515c997c8494470-9b65c5e6af6c92d9_0.parquet/")
INTO TABLE `load_parquet_file_test`
FORMAT AS PARQUET -- 指定类型
(id,name,age)
)
with HDFS (
"fs.defaultFS"="hdfs://192.168.31.128:9820",
"hadoop.username"="root"
)
PROPERTIES
(
"timeout"="1200",
"max_filter_ratio"="0.1"
);
查看导入状态
#可视乎工具
show load order by createtime desc limit 1;
#mysql 客户端可以加上\G
show load order by createtime desc limit 1\G;
mysql> show load order by createtime desc limit 1\G;
*************************** 1. row ***************************
JobId: 41326624
Label: broker_load_2022_03_23
State: FINISHED
Progress: ETL:100%; LOAD:100%
Type: BROKER
EtlInfo: unselected.rows=0; dpp.abnorm.ALL=0; dpp.norm.ALL=27
TaskInfo: cluster:N/A; timeout(s):1200; max_filter_ratio:0.1
ErrorMsg: NULL
CreateTime: 2022-04-01 18:59:06
EtlStartTime: 2022-04-01 18:59:11
EtlFinishTime: 2022-04-01 18:59:11
LoadStartTime: 2022-04-01 18:59:11
LoadFinishTime: 2022-04-01 18:59:11
URL: NULL
JobDetails: {"Unfinished backends":{"5072bde59b74b65-8d2c0ee5b029adc0":[]},"ScannedRows":27,"TaskNumber":1,"All backends":{"5072bde59b74b65-8d2c0ee5b029adc0":[36728051]},"FileNumber":1,"FileSize":5540}
1 row in set (0.01 sec)
取消导入
-
当 Broker load 作业状态不为 CANCELLED 或 FINISHED 时,可以被用户手动取消。
-
取消时需要指定待取消导入任务的 Label 。取消导入命令语法可执行 CANCEL LOAD 查看。
例如:撤销数据库 demo 上, label 为 broker_load_2023_06_25 的导入作业
CANCEL LOAD FROM demo WHERE LABEL = "broker_load_2023_06_25";
4、导出语法
>官网 https://doris.apache.org/docs/dev/sql-manual/sql-reference/Data-Manipulation-Statements/OUTFILE?_highlight=outfile
1、 查询结果导出
select * from load_parquet_file_test
INTO OUTFILE "hdfs://192.168.31.128:9820/my_file_"
FORMAT AS PARQUET
PROPERTIES
(
"broker.name" = "broker_128",
"max_file_size" = "100MB"
);
PROPERTIES ("key"="value", ...)
支持如下属性:
文件相关的属性
column_separator: 列分隔符。<version since="1.2.0">支持多字节分隔符,如:"\x01", "abc"</version>
line_delimiter: 行分隔符。<version since="1.2.0">支持多字节分隔符,如:"\x01", "abc"</version>
max_file_size: 单个文件大小限制,如果结果超过这个值,将切割成多个文件。
delete_existing_files: 默认为false,若指定为true,则会先删除file_path指定的目录下的所有文件,然后导出数据到该目录下。
例如:"file_path" = "/user/tmp", 则会删除"/user/"下所有文件及目录;"file_path" = "/user/tmp/", 则会删除"/user/tmp/"下所有文件及目录
Broker 相关属性需加前缀 broker.:
broker.name: broker名称
broker.hadoop.security.authentication: 指定认证方式为 kerberos
broker.kerberos_principal: 指定 kerberos 的 principal
broker.kerberos_keytab: 指定 kerberos 的 keytab 文件路径。该文件必须为 Broker 进程所在服务器上的文件的绝对路径。并且可以被 Broker 进程访问
2、Export 导出到线上存储地址
>官网 https://doris.apache.org/docs/dev/sql-manual/sql-reference/Data-Manipulation-Statements/Manipulation/EXPORT?_highlight=export
-
Export 这是一个异步操作,任务提交成功则返回。执行后可使用 SHOW EXPORT 命令查看进度。
-
properties可以指定如下参数:
-
label: 可选参数,指定此次 Export任务的label,当不指定时系统会随机给一个label。
-
column_separator:指定导出的列分隔符,默认为\t。仅支持单字节。
-
line_delimiter:指定导出的行分隔符,默认为\n。仅支持单字节。
-
columns:指定导出作业表的某些列。
-
timeout:导出作业的超时时间,默认为2小时,单位是秒。
-
format:导出作业的文件格式,支持:parquet, orc, csv, csv_with_names、csv_with_names_and_types。 默认为csv格式。
-
max_file_size:导出作业单个文件大小限制,如果结果超过这个值,将切割成多个文件。
EXPORT TABLE D_6_13.load_parquet_file_test -- 库名.表名 to "hdfs://192.168.31.128:9820/parquet/" -- 导出到那里去 PROPERTIES (
"label" = "2023-6-25",
"timeout" = "3600", "format"="parquet" -- 指定导出类型 ) WITH BROKER "broker_128" (
"username" = "root",
"password" = "" );
-
3、Export 导出到本地
> export数据到本地文件系统,需要在fe.conf中添加enable_outfile_to_local=true并且重启FE。
// parquet格式
EXPORT TABLE load_parquet_file_test TO "file://opt/app/python/parquet/"
PROPERTIES (
"format" = "parquet"
);