标准库里的所有映射类型都是利用 dict 来实现的,因此它们有个共同的限制,即只有可散列的数据类型才能用作这些映射里的键,本文记录Python 中 hash 相关内容。
hash {#hash}
Hash,一般翻译做散列、杂凑,或音译为哈希,是把任意长度的输入(又叫做预映射pre-image)通过散列算法变换成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,所以不可能从散列值来确定唯一的输入值。简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。
- Hash算法可以将一个数据转换为一个标志,这个标志和源数据的每一个字节都有十分紧密的关系。Hash算法还具有一个特点,就是很难找到逆向规律。
- Hash算法是一个广义的算法,也可以认为是一种思想,使用Hash算法可以提高存储空间的利用率,可以提高数据的查询效率,也可以做数字签名来保障数据传递的安全性。所以Hash算法被广泛地应用在互联网应用中。
- Hash算法也被称为散列算法,Hash算法虽然被称为算法,但实际上它更像是一种思想。Hash算法没有一个固定的公式,只要符合散列思想的算法都可以被称为是Hash算法。
Python 中可散列的数据类型 {#Python-中可散列的数据类型}
-
翻译过来就是:
如果一个对象的哈希值在其生命周期中从不变化(它需要一个
__hash__()方法) ,并且可以与其他对象进行比较(它需要一个 _ eq _ ()方法) ,那么该对象就是可变的。比较相等的 hasable 对象必须具有相同的散列值。Hashability 使对象可用作字典键和集合成员,因为这些数据结构在内部使用哈希值。
Python 中大多数不可变的内置对象都是 hasable; 可变的容器(如列表或字典)则不是; 不可变的容器(如元组和 frozenset)只有在其元素是 hasable 的情况下才是 hasable 的。默认情况下,作为用户定义类实例的对象是可以 hasable 的。它们都比较 unequal (除了它们自己) ,它们的 hash 值是从它们的 id ()派生出来的。
-
也就是说,一个对象可散列,需要以下条件:
- 在这个对象的生命周期中,它 的散列值是不变的
- 实现
__hash__()方 法 - 实现
__qe__()方法
-
可散列的数据类型
| 类型 | 描述 | |-----------------|----------------------------------------------------------------------------------------------------------------------------------------------------| | str、bytes 和数值类型 | 原子不可变数据类型 | | frozenset | 因为根据其定义,frozenset 里 只能容纳可散列类型 | | 元组 | 只有当一个元组包含的所有元素都是可散列类型的情况下,它才是可散列的。 | | 户自定义的类型 | 一般来讲用户自定义的类型的对象都是可散列的,散列值就是它们 的
id()函数的返回值,所以所有这些对象在比较的时候都是不相等的。如果一个对象实现了__eq__方法,并且在方法中用到了这 个对象的内部状态的话,那么只有当所有这些内部状态都是不可变 的情况下,这个对象才是可散列的。 | -
示例代码:
dict 和set的背后 {#dict和set的背后}
-
dict 和 set 可以快速检索得益于散列的应用,理论上在散列中查找数据的时间复杂度为 O(1)
-
散列表其实是一个稀疏数组(总是有空白元素的数组称为稀疏数组)。 在一般的数据结构教材中,散列表里的单元通常叫作表元(bucket)。 在 dict 的散列表当中,每个键值对都占用一个表元,每个表元都有两 个部分,一个是对键的引用,另一个是对值的引用。因为所有表元的大 小一致,所以可以通过偏移量来读取某个表元。
-
因为 Python 会设法保证大概还有三分之一的表元是空的,所以在快要达 到这个阈值的时候,原有的散列表会被复制到一个更大的空间里面。
-
如果要把一个对象放入散列表,那么首先要计算这个元素键的散列值。 Python 中可以用 hash() 方法来做这件事情:
- 内置的 hash() 方法可以用于所有的内置类型对象。如果是自定义 对象调用 hash() 的话,实际上运行的是自定义的
__hash__。如 果两个对象在比较的时候是相等的,那它们的散列值必须相等,否 则散列表就不能正常运行了。 - 为了让散列值能够胜任散列表索引这一角色,它们必须在索引空间 中尽量分散开来。这意味着在最理想的状况下,越是相似但不相等 的对象,它们散列值的差别应该越大。
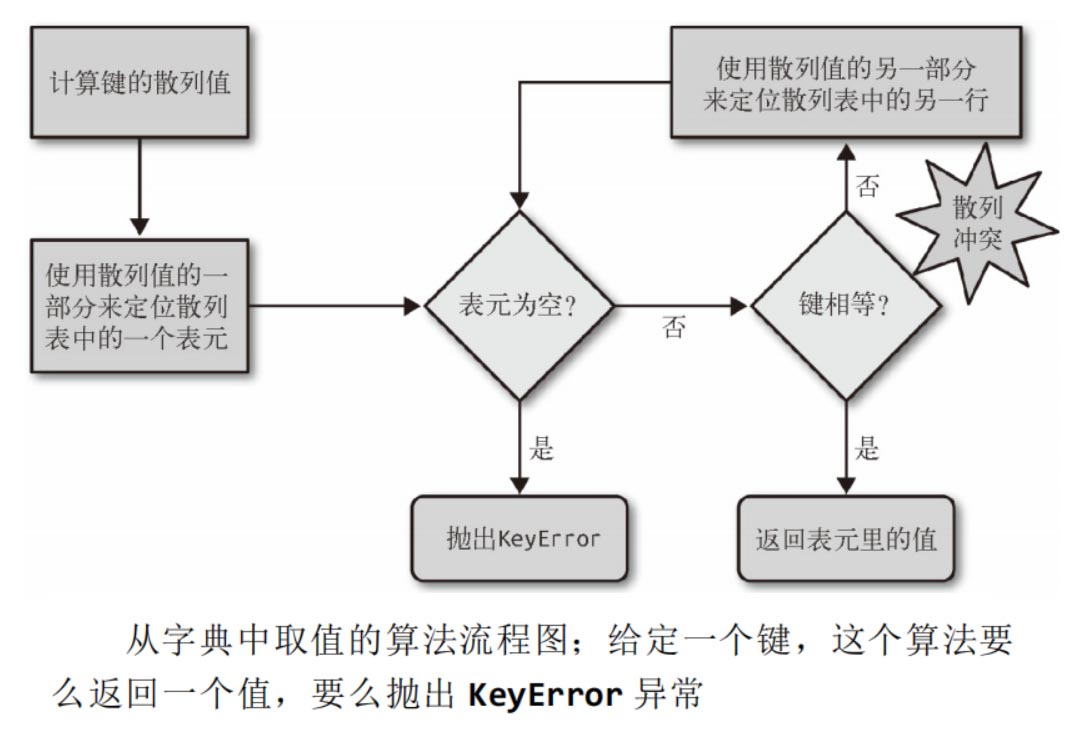
- 为了获取 my_dict[search_key] 背后的值,Python 首先会调用 hash(search_key) 来计算 search_key 的散列值,把这个值最低 的几位数字当作偏移量,在散列表里查找表元(具体取几位,得看 当前散列表的大小)。若找到的表元是空的,则抛出 KeyError 异 常。若不是空的,则表元里会有一对 found_key:found_value。 这时候 Python 会检验 search_key == found_key 是否为真,如 果它们相等的话,就会返回 found_value。
- 如果 search_key 和 found_key 不匹配的话,这种情况称为散列 冲突。发生这种情况是因为,散列表所做的其实是把随机的元素映 射到只有几位的数字上,而散列表本身的索引又只依赖于这个数字 的一部分。为了解决散列冲突,算法会在散列值中另外再取几位, 然后用特殊的方法处理一下,把新得到的数字再当作索引来寻找表 元。10 若这次找到的表元是空的,则同样抛出 KeyError;若非 空,或者键匹配,则返回这个值;或者又发现了散列冲突,则重复 以上的步骤。
- 内置的 hash() 方法可以用于所有的内置类型对象。如果是自定义 对象调用 hash() 的话,实际上运行的是自定义的
dict的实现及其导致的结果 {#dict的实现及其导致的结果}
键必须是可散列的 {#键必须是可散列的}
- 一个可散列的对象必须满足以下要求。:
- 支持 hash() 函数,并且通过
__hash__()方法所得到的散列 值是不变的。 - 支持通过
__eq__()方法来检测相等性。 - 若
a == b为真,则hash(a) == hash(b)也为真。
- 支持 hash() 函数,并且通过
如果你实现了一个类的
__eq__方法,并且希望它是可 散列的,那么它一定要有个恰当的__hash__方法,保证在 a == b 为真的情况下 hash(a) == hash(b) 也必定为真。否则 就会破坏恒定的散列表算法,导致由这些对象所组成的字典和 集合完全失去可靠性,这个后果是非常可怕的。另一方面,如 果一个含有自定义的__eq__依赖的类处于可变的状态,那就 不要在这个类中实现__hash__方法,因为它的实例是不可散 列的。
字典在内存上的开销巨大 {#字典在内存上的开销巨大}
-
由于字典使用了散列表,而散列表又必须是稀疏的,这导致它在空 间上的效率低下。
-
如果你需要存放数量巨大的记录,那么放在由元组或是具名元组构成的列表中会是比较好的选择;最好不要根据 JSON 的风格,用由字典组成的列表来存放这些记录。
-
用元组取代字典就能节省空间的原因有两个:
- 避免了散列表所耗费的空间
- 无需把记录中字段的名字在每个元素里都存一遍。
记住我们现在讨论的是空间优化。如果你手头有几百万个对象,而你的机器有几个 GB 的内存,那么空间的优化工作可以等到真正需 要的时候再开始计划,因为优化往往是可维护性的对立面。
键查询很快 {#键查询很快}
- dict 的实现是典型的空间换时间:字典类型有着巨大的内存开 销,但它们提供了无视数据量大小的快速访问------只要字典能被装 在内存里。
- 如果把字典的大小从 1000 个元素增 加到 10 000 000 个,查询时间也不过是原来的 2.8 倍,从 0.000163 秒增加到了 0.00456 秒。这意味着在一个有 1000 万个元素的字典 里,每秒能进行 200 万个键查询。
键的次序取决于添加顺序 {#键的次序取决于添加顺序}
- 当往 dict 里添加新键而又发生散列冲突的时候,新键可能会被安排存放到另一个位置。于是下面这种情况就会发生:由
dict([key1, value1), (key2, value2)]和dict([key2, value2], [key1, value1])得到的两个字典,在进行比较的时候,它们是相等的;但是如果在 key1 和 key2 被添加到字典里的过程中有冲突发生的话,这两个键出现在字典里的顺序是不一样 的。
往字典里添加新键可能会改变已有键的顺序 {#往字典里添加新键可能会改变已有键的顺序}
- 无论何时往字典里添加新的键,Python 解释器都可能做出为字典扩容的决定。扩容导致的结果就是要新建一个更大的散列表,并把字典里已有的元素添加到新表里。这个过程中可能会发生新的散列冲突,导致新散列表中键的次序变化。要注意的是,上面提到的这些变化是否会发生以及如何发生,都依赖于字典背后的具体实现,因此你不能很自信地说自己知道背后发生了什么。如果你在迭代一个字典的所有键的过程中同时对字典进行修改,那么这个循环很有可能会跳过一些键------甚至是跳过那些字典中已经有的键。
set的实现以及导致的结果 {#set的实现以及导致的结果}
- set 和 frozenset 的实现也依赖散列表,但在它们的散列表里存放的只有元素的引用(就像在字典里只存放键而没有相应的值)。
- 字典和散列表的几个特点,对集合来说几乎都是适用的。
- 集合里的元素必须是可散列的。
- 集合很消耗内存。
- 可以很高效地判断元素是否存在于某个集合。
- 元素的次序取决于被添加到集合里的次序。
- 往集合里添加元素,可能会改变集合里已有元素的次序。
参考资料 {#参考资料}
- 流畅的Python(2017年人民邮电出版社出版)
- https://docs.python.org/3/glossary.html#term-hashable
- https://baike.baidu.com/item/Hash/390310?fr=aladdin
文章链接:
https://www.zywvvd.com/notes/coding/python/fluent-python/chapter-3/python-hashable/pytho-hashable/




