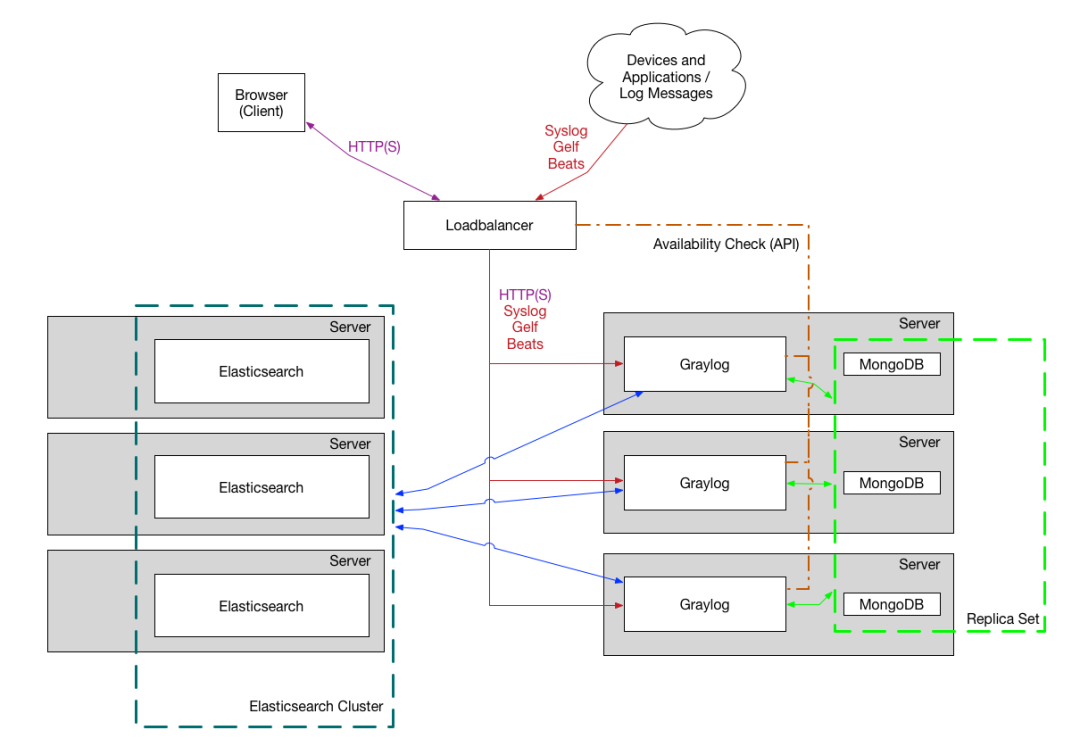
SentencePiece 是一种用于文本处理的工具,特别适用于基于神经网络的文本生成系统。它的主要功能是将文本分割成更小的单位(称为子词单元),这些子词单元可以是完整的单词、部分单词,甚至是单个字符。
- 灵活的词汇表: SentencePiece 允许我们在训练神经网络之前预先确定词汇表的大小。这对于控制模型的复杂度非常有用。
- 处理未知词: 它可以处理训练数据中未出现过的词,通过将它们分解成子词单元来表示。
- 语言无关性: SentencePiece 不依赖于特定的语言,可以用于多种语言的文本处理。
- 端到端系统: 它可以直接从原始文本进行训练,不需要额外的预处理或后处理步骤。
SentencePiece 主要使用了两种技术:
- BPE : 通过迭代合并频繁出现的子序列来构建词汇表。
- UnigGram: 基于词频的语言模型,用于对生成的子词序列进行评分,从而选择最佳的分割方式。
pip install sentencepiece
GitHub:https://github.com/google/sentencepiece
使用示例代码:
from sentencepiece import SentencePieceTrainer
from sentencepiece import SentencePieceProcessor
1. 训练
def test01():
SentencePieceTrainer.train(input='corpus.txt',
# 指定输出模型的前缀名称。模型文件包含两个文件:model_prefix.model 和 model_prefix.vocab
model_prefix='model/tokenizer',
# 指定输入文件的格式。可以是 'text'(默认,按行分隔的句子)或者 'tsv'(Tab 分隔的文件,第一列为句子,其他列可选)
input_format='text',
# 指定模型涵盖的字符的百分比
character_coverage=0.99,
# 词汇表的大小,即模型最终生成的分词单位数量。包括特殊符号(如 <unk>)在内
vocab_size=163,
# 指定模型类型。支持四种模型:unigram、bpe、char、word
model_type='bpe',
# 是否在训练前对输入的句子进行随机打乱
shuffle_input_sentence=True,
# 指定 <pad> 等特殊标记 ID。设置为 -1 时,表示该符号不在词汇表中
pad_id=0,
bos_id=1,
eos_id=2,
# 指定 <unk>(未知标记)的 ID
unk_id=3,
# 定义用户自定义的特殊符号。这些符号将被包含在词汇表中,且不会被进一步分词处理
user_defined_symbols=['<user>', '<system>', '<asistant>'],
# 指定控制符号(如 <cls> 等)。这些符号用于控制模型的行为
control_symbols=['|CLS|', '|SEP|'],
# 当模型遇到未登录词时,它将使用 |unk| 来表示这些词
unk_surface='|unk|',
# 指定文本标准化规则。支持:'nmt_nfkc':标准 NFKC 正规化,用于去除不必要的符号。'identity':不进行任何标准化。
normalization_rule_name='nmt_nfkc')
2. 加载
def test02():
# 加载方法一
tokenizer = SentencePieceProcessor()
tokenizer.load('model/tokenizer.model')
# 加载方法二
tokenizer = SentencePieceProcessor(model_file='model/tokenizer.model')
print('词表大小:', tokenizer.vocab_size())
3. 编码
def test03():
tokenizer = SentencePieceProcessor(model_file='model/tokenizer.model')
inputs = tokenizer.Encode(input=['郑钦文仍然创造僻'],
# 指定输出的类型。可以输出 piece 的索引(int)或文本(str)。
out_type=str,
# 是否在输出序列的开头添加 <bos>(句子开始标记)
add_bos=True,
# 是否在输出序列的末尾添加 <eos>(句子结束标记)
add_eos=True,
# 是否对输出的子词序列进行反转
reverse=False,
# 设置为 True,遇到未登录词时则使用 unk_surface 代替,否则返回 unk_id 对应的 ID。
emit_unk_piece=True)
print(inputs)
4. 解码
def test04():
tokenizer = SentencePieceProcessor(model_file='model/tokenizer.model')
outputs = tokenizer.Decode([[13, 87, 43, 56, 12]],
# str 字符串类型
# bytes 字节类型
# 'serialized_proto' 一种高效的二进制格式,通常用于数据存储和网络传输。
# 'immutable_proto' 解码后得到的输出内容为不可变的协议缓冲区对象
out_type='serialized_proto')
print(outputs)
# print(outputs[0].text)
# print(outputs[0].score)
# for piece in outputs[0].pieces:
# print(piece)
if name == 'main':
test04()