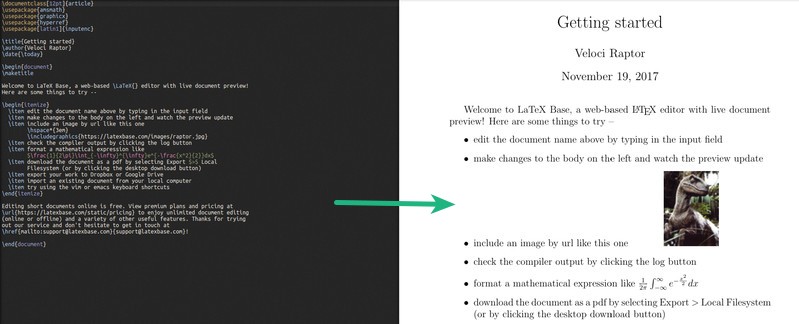
在 20 世纪 50 年代,弗兰克·罗森布莱特(Frank Rosenblatt)提出了感知机算法,其最初的目的是教会计算机识别图像。感知机的基本思路是简单模型神经元细胞的的运行原理。
- 感知机原理 {#title-0} ===================

- f(x) > 0 时,输出 1 类别
- f(x) < 0 时,输出 -1 类别
感知机的损失函数为:

- 如果样本的真实类别是 1,当该样本分类错误时,则 w^T^x + b 小于 0
- 如果样本的真实类别是 -1,当该样本分类错误时,则 w^T^x + b 大于 0
- M 表示分类错误的样本
- 由于样本分类错误时,模型的输出和真实标签符号相反,故而添加符号转正
对 w、b 求导,使用梯度下降算法来优化模型参数。

w、b 的更新公式如下:

当碰到分类错误样本时,就对模型的参数进行更新,如何判断样本分类错误,可以使用下面的公式来判断:

- 感知机示例 {#title-1} ===================
下面代码的基本思路:
- 遍历样本
- 如果发现样本分类错误,则使用该样本的梯度更新模型参数
- 直到模型能够把所有的样本都能正确分类
from sklearn.datasets import make_classification
import matplotlib.pyplot as plt
import numpy as np
import random
import math
from sklearn.linear_model import Perceptron
初始化模型参数
np.random.seed(5)
w = np.random.randn(2, 1)
b = np.zeros(1)
假设函数
def percetron(x):
return x @ w + b
def plot_boundary(model, x, y):
# 绘制分类边界
x1, x2 = np.meshgrid(
np.linspace(x[:, 0].min() - 1, x[:, 0].max() + 1, 1000),
np.linspace(x[:, 1].min() - 1, x[:, 1].max() + 1, 1000))
data = np.c_[x1.ravel(), x2.ravel()]
y_pred = np.where(percetron(data) >= 0, 1, -1).reshape(1, -1)
plt.contourf(x1, x2, y_pred.reshape(1000, 1000), cmap=plt.cm.Blues)
绘制原始数据散点图
plt.scatter(x[:, 0], x[:, 1], c=y)
plt.show()
构建分类数据集
def create_dataset(sample_number=100, random_state=None):
x, y = make_classification(n_samples=sample_number,
n_features=2,
n_redundant=0,
n_clusters_per_class=1, random_state=random_state)
# 将0类别使用-1表示
y = np.where(y == 0, -1, y)
return x, y
数据加载器
def data_loader(x, y):
# 生成样本索引
sample_index = list(range(len(y)))
# 打乱数据索引
random.shuffle(sample_index)
# 每次返回一个样本
for idx in sample_index:
yield x[idx], y[idx]
优化方法
def optimizer(x, y, lr=0.1):
global w, b
计算样本梯度
w_g = (-y * x).reshape(2, 1)
b_g = -y
更新模型参数
w -= lr * w_g
b -= lr * b_g
def perceptron_loss(y_pred, y_true):
return -y_pred * y_true
1. 手动实现简单的感知机训练过程
def test01():
# 1. 构建分类样本
data_x, data_y = create_dataset(sample_number=20, random_state=1)
2. 感知机训练
tol = 1e-3
for idx in range(1000):
total_loss = 0.0
error_number = 0
for x, y in data_loader(data_x, data_y):
# 训练样本送入模型
output = percetron(x)
# 如果样本预测错误, 则使用该样本更新参数
loss = perceptron_loss(output.squeeze(), y)
if loss &amp;gt; 0:
# 更新模型参数
optimizer(x, y, lr=0.0001)
# 统计损失信息
total_loss += loss
error_number += 1
print('epoch %d loss: %.2f' % (idx + 1, total_loss))
4. 绘制分类边界
plot_boundary(percetron, data_x, data_y)
2. 使用 sklearn 的 Perceptron API
def test02():
# 1. 构建分类样本
data_x, data_y = create_dataset(sample_number=20, random_state=1)
2. 模型训练
estimator = Perceptron(random_state=0)
estimator.fit(data_x, data_y)
3. 绘制分类边界
x1, x2 = np.meshgrid(
np.linspace(data_x[:, 0].min() - 1, data_x[:, 0].max() + 1, 1000),
np.linspace(data_x[:, 1].min() - 1, data_x[:, 1].max() + 1, 1000))
data = np.c_[x1.ravel(), x2.ravel()]
y_pred = estimator.predict(data)
plt.contourf(x1, x2, y_pred.reshape(1000, 1000), cmap=plt.cm.Blues)
plt.scatter(data_x[:, 0], data_x[:, 1], c=data_y)
plt.show()
if name == 'main':
test01()
test02()
程序多次运行之后,我们发现感知机模型并不是唯一的。