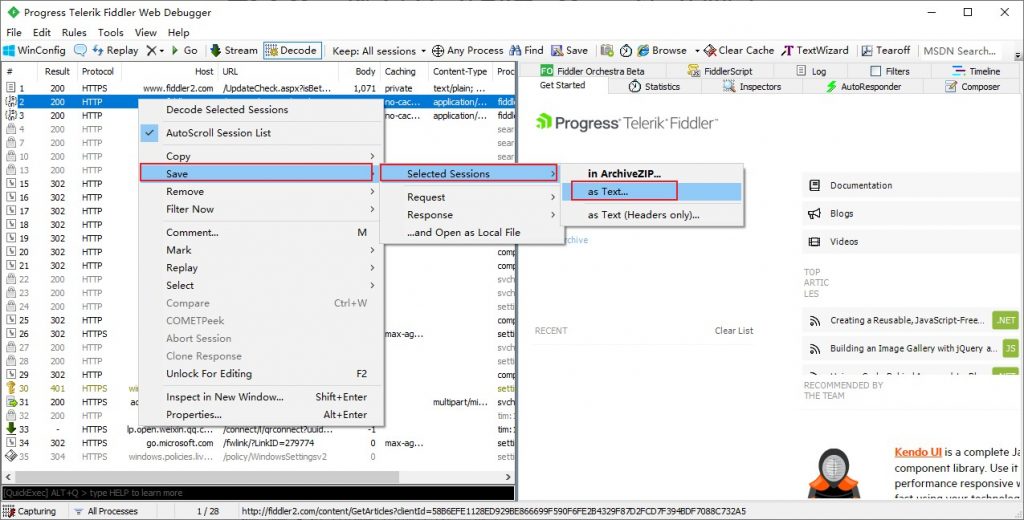
Fiddler开始抓包获得请求后右键 Save -> Selected Sessions -> as Text 另存为文件
 修改str_filename变量值为另存的文件全称(包括扩展名)
修改str_filename变量值为另存的文件全称(包括扩展名)
#!/usr/bin/python
#指定内容
# -*- coding: UTF-8 -*-
str_filename = "15_full.txt"
#指定文件
save_name = "re_test.py"
#修改后缀为py结尾
save_name = str_filename.replace("txt", "py")
class FidToPy():
def init(self, str_name, sa_name):
self.str_filename = str_name
self.save_name = sa_name
self.text = ""
self.url_list = []
self.headers = {}
self.cookies = {}
self.data = {}
def get_url(self):
infos = self.text.split("\n")[0]
self.url_list = [infos.split(" ")[0], infos.split(" ")[1]]
def get_headers(self):
infos = self.text.split("\n")[1:]
info = ""
for i in infos:
if "Cookie: " in i:
break
info += i + "\n"
headers = info.split("\n")
while "" in headers:
headers.remove("")
for i in headers:
if ": " not in i:
break
self.headers[i.split(": ")[0]] = i.split(": ")[1]
def get_cookies(self):
infos = self.text.split("\n")[1:]
cookies_flag = 0
for i in infos:
if "Cookie: " in i:
self.cookies = i.replace("Cookie: ", "")
print(self.cookies)
cookies_flag = 1
break
if cookies_flag == 1:
self.cookies = {i.split("=")[0]: i.split("=")[1] for i in self.cookies.split("; ")}
def get_data(self):
try:
infos = self.text.split("\n")
for i in range(2, len(infos)):
if infos[i - 1] == "" and "HTTP" in infos[i + 1]:
self.data = infos[i]
break
self.data = {i.split("=")[0]: i.split("=")[1] for i in self.data.split("&")}
except:
pass
def get_req(self):
info_beg = "#!/usr/bin/python\n# -- coding: UTF-8 --\nimport requests\n\n"
info_url = "url = '{}'\n".format(self.url_list[1])
info_headers = "headers = {}\n".format(self.headers)
info_cookies = "cookies = {}\n".format(self.cookies)
info_data = "data = {}\n\n".format(self.data)
if "GET" in self.url_list[0]:
info_req = "html = requests.get(url, headers=headers, verify=False, cookies=cookies)\n"
else:
info_req = "html = requests.post(url, headers=headers, verify=False, cookies=cookies, data=data)\n"
info_end = "print(len(html.text))\nprint(html.text)\n"
text = info_beg + info_url + info_headers + info_cookies + info_data + info_req + info_end
with open(save_name, "w+", encoding="utf8") as p:
p.write(text)
print("转化成功!!")
print(save_name, "文件保存!")
def read_infos(self):
with open(self.str_filename, "r+", encoding="utf-8") as p:
old_line = ""
for line in p:
if old_line == b"\n" and line.encode() == b"\n":
break
old_line = line.encode()
self.text += old_line.decode()
# print("self.text:", self.text)
def start(self):
self.read_infos()
self.get_url()
self.get_headers()
self.get_cookies()
self.get_data()
print("self.url_list:", self.url_list)
print("self.headers:", self.headers)
print("self.cookies:", self.cookies)
print("self.data:", self.data)
self.get_req()
ifname== 'main': f = FidToPy(str_filename, save_name) f.start()
脚本执行成功后会在当前目录下生成py文件