2024-06-04
分类:开源工具
阅读(505) 评论(0)
Redis 持久化
---------
#### RDB
RDB 的全称为 Redis Database Backup(Redis 数据备份),也被叫做 Redis 数据快照,该功能默认开启。简单来说就是把内存中的所有数据记录到磁盘中。当 Redis 故障重启后,从磁盘读取快照文件,恢复数据。RDB 默认开启,会在主动停机时自动保存数据,也可以通过`save`命令主动保存数据,但会阻塞所有命令。因此更推荐使用`bgsave`命令来进行主动保存数据。
当然,Redis 内部也有 RDB 自动触发机制,相关配置项可以在 redis.conf 文件中配置
```
# 表示禁止用 RDB 功能,禁用后仍然可以使用命令手动生成 RDB 文件
# save ""
# 900 秒内,如果至少有一个 key 被修改,则自动执行 bgsave
save 900 1
# 300 秒内,如果至少有十个 key 被修改,则自动执行 bgsave
save 300 10
# 是否压缩 RDB 文件,默认开启,CPU 资源紧张时建议关闭,压缩虽然节省了磁盘,但会消耗 CPU 资源
rdbcompression yes
# RDB 文件名称
dbfilename dump.rdb
# 指定持久化文件的保存目录,目录必须提前创建好,系统不会自动创建
dir /data/redis/file
# 后台保存出错时是否停止写入数据,默认 yes
stop-writes-on-bgsave-error yes
# RDB 文件合法性校验,默认 yes,在存储快照后,让 Redis 使用 CRC64 算法来进行数据校验,但这样会增加 10% 的性能消耗,如果希望得到最大的性能提升,可以关闭此功能
rdbchecksum yes
```
该持久化方案间隔时间长,两次 RDB 之间写入数据有丢失风险,且比较耗时。而且 RDB 依赖于主进程的 fork,fork 的时候内存中的数据被克隆了一份,当数据量很大时会使内存迅速膨胀,这可能会导致服务请求的瞬间延迟。
#### AOF
AOF 全称为 Append Only File。Redis 处理的每一个**写命令**都会记录在 AOF 文件,可以看做是命令日志文件。
AOF 功能默认关闭,需要手动开启,相关配置项可以在 redis.conf 文件中配置
```
# 是否开启 AOF,默认 no
appendonly yes
# 指定 AOF 文件名
appendfilename "appendonly.aof"
# 指定 AOF 刷盘策略(always-每执行一次写命令立即记录到 AOF 文件、everysec-写命令执行完后先放入 AOF 缓冲区,每隔一秒写到 AOF 文件,默认值、no-写命令执行完后先放入 AOF 缓冲区,由系统决定何时写到 AOF 文件)
appendfsync everysec
# AOF 目录名(Redis 7.0 之后,AOF 会在 dir 配置的目录下创建一个文件夹,文件夹名称就是次配置项配置的名称,并将生成的 AOF 文件存放在该目录下) 例如:dir 配置内容为 /data/redis/file,则 AOF 文件的保存目录为 /data/redis/file/appendonlydir
appenddirname appendonlydir
```
因为是记录命令,所以 AOF 文件会比 RDB 文件大得多,且 AOF 会记录对同一个 key 的多次写操作,但只有最后一次写操作才有意义。因此可以通过`bgrewriteaof`命令让 AOF 文件执行重写功能,只保留可以恢复数据的最小指令集,达到用最少命令起到相同效果。当然,该功能同样有自动触发机制,我们可以根据需要在配置文件中进行相关配置
```
# 根据上次重写 AOF 文件的大小,文件大小增长了 100% 且文件大小到达 64mb 就会自动触发 bgrewriteaof
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
# AOF 重写期间是否同步,默认 no
no-appendfsync-on-rewrite no
```
#### 如何抉择
RDB 和 AOF 各有优劣,如果对数据安全不是很高,我们只需要开启 RDB 即可,如果对数据安全性要求较高,建议开启 AOF。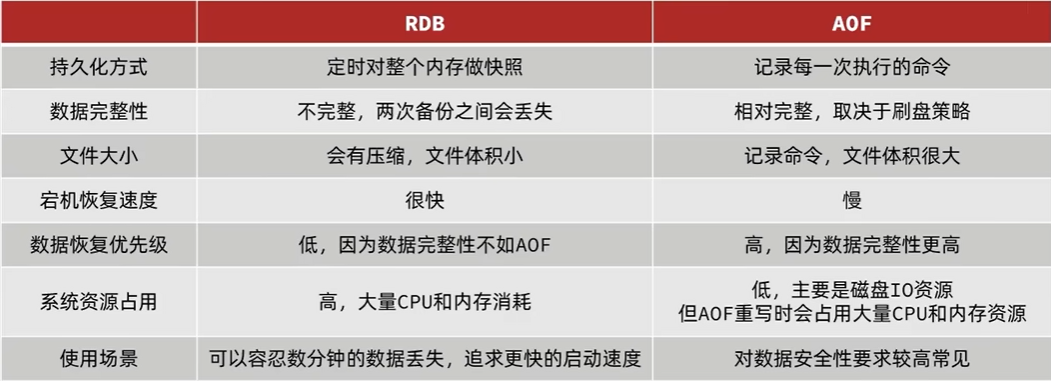在实际开发中往往会结合两者来使用,我们可以同时开启 RDB 和 AOF,当两者同时开启时,AOF 的优先级较高。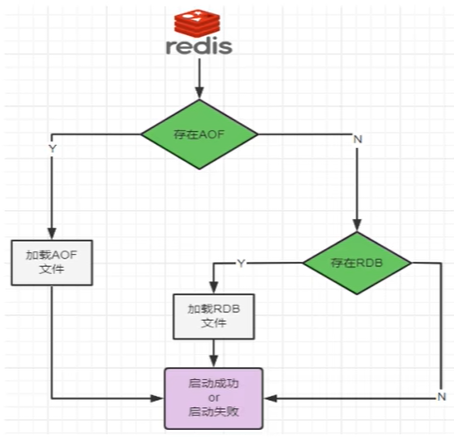那可能有同学会说,既然 AOF 的优先级较高,且保存数据较为完整,那是否只需要开启 AOF 就可以了呢?
Redis 的作者建议不要这样做,因为 RDB 更适合用于备份数据库(AOF 在不断变化不好备份),我们可以在配置文件中开启混合模式
```
# 是否开启 RDB + AOF 混合模式,默认 yes
aof-use-rdb-preamble yes
```
当开启混合模式后,会先使用 RDB 进行快照存储,然后使用 AOF 持久化记录所有写操作,当重写策略满足或手动触发重写的时候,系统会将最新的数据存储为新的 RDB 记录。这样的话,重启服务的时候会从 RDB 和 AOF 两部分恢复数据,既保证了数据的完整性,又提高了恢复数据的性能。简单来说就是 RDB 做全量,AOF 做增量。
Redis 主从架构集群搭建
--------------
单节点的 Redis 的并发能力是有上限的,要进一步提高 Redis 的并发能力,就需要搭建 Redis 集群,来提高 Redis 的可用性和并发能力。
主从架构是最简单的 Redis 集群架构,其中主节点既可以读也可以写,而从节点只能读不能写。因此我们可以使用主从架构进行读写分离,从而缓解主节点的压力。
要搭建主从架构首先要确保所有节点的 RDB 功能开启,其次在从节点的配置文件中写入主节点的相关信息:
```
# 开启 RDB 功能
save 3600 1
save 300 10
save 60 100
# 配置主节点的 IP 和端口
replicaof 192.168.111.185 6379
# 如果主节点有访问密码,则必须配置主节点的访问密码
masterauth "123456"
```
接着我们只需要一次启动主节点和从节点我们的 Redis 主从架构就搭建完毕了。接着我们可以使用命令`info replication`查看是否搭建成功。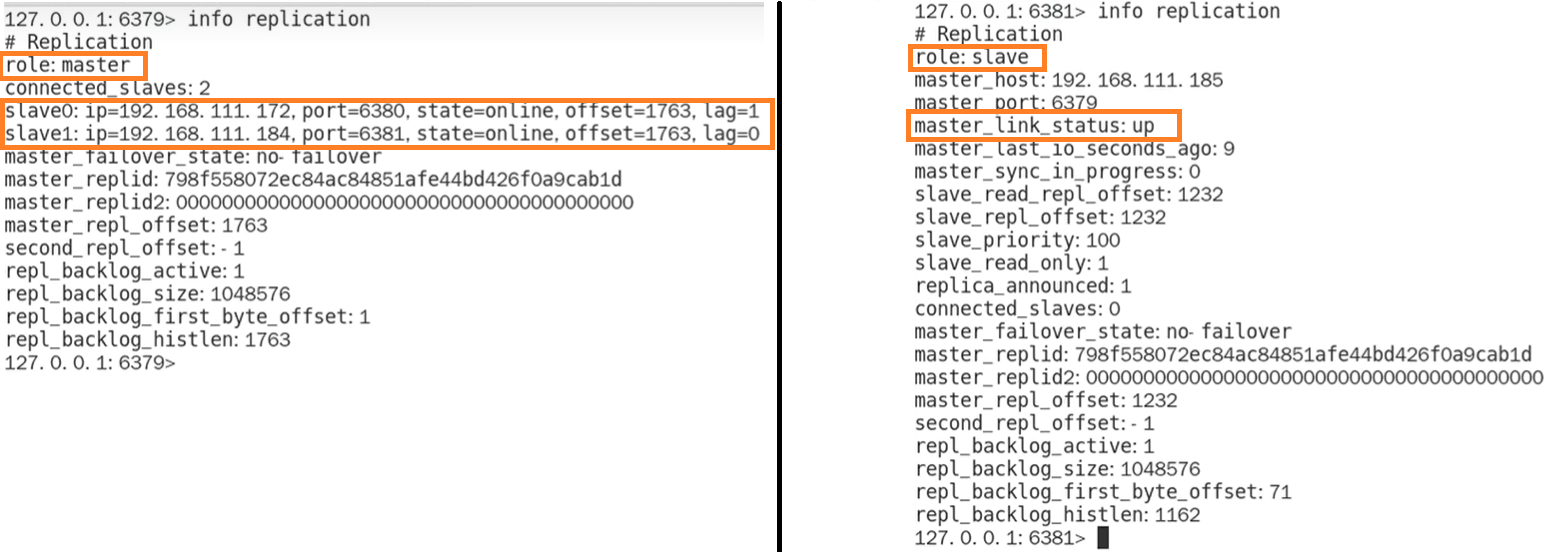可以看到已经搭建成功了。
当然除了使用配置文件之外,我们还可以通过命令行的方式来临时搭建临时的(重启服务后失效)主从架构,相关命令如下:
```
# 临时成为 192.168.111.185 的从节点
slaveof 192.168.111.185 6379
# 使当前节点停止与主节点同步数据,独立为 master 节点
slaveof no one
```
#### 工作原理
* slave 启动成功连接到 master 后会发送一个同步数据请求,并携带自己的 replicationId 和 offset
* master 接受到数据同步请求后会判断 replicationId 是否和自己一致,不一致则为首次连接,如果是首次连接,master 会发送自己的 replicationId 和 offset
* slave 收到 master 的 replicationId 和 offset 后会将这些信息保存保存,接着 master 执行 bgsave 命令生成 RDB 信息并发送给 slave,并将发送数据期间的命令记录到 repl_baklog
* slave 收到 RDB 信息后首先清除本地数据,之后加载 RDB 数据
* master 接着将 repl_baklog 命令发送给 slave
* slave 收到 repl_baklog 后执行里面的命令,首次连接全量同步数据完成
* 之后 slave 保持与 master 连接,之后通过 replicationId 和 offset 与 master 做增量同步
Redis 哨兵集群
----------
虽然主从架构搭建起来非常简单,但默认情况下,slave 不会在 master 宕机后重新选举 master。因此在 master 宕机期间以及数据恢复期间整个集群是没办法写入数据的,为了解决这个问题,我们就需要使用 Redis 的哨兵机制。
Redis 提供了哨兵(Sentinel)机制来实现主从集群的故障恢复,哨兵集群至少有 3 个节点,不存放数据。哨兵有如下作用:
* 监控:哨兵会不断检查 master 和 slave 是否按预期工作
* 自动故障恢复:如果 master 故障,哨兵会将一个 slave 提升为 master,当故障节点恢复后也以新的 master 为主
* 通知:哨兵充当 Redis 客户端的服务发现来源,当集群发生故障转移时,会将新信息推送给 Redis 的客户端
要搭建哨兵集群其实也非常简单,只需要在哨兵的配置文件 sentinel.conf 中进行配置即可:
```
# 开启守护进程模式
daemonize yes
# 指定日志输出目录
logfile "/data/redis/log/sentinel.log"
# 指定要监控主从集群的 master 的名称、IP、端口以及客观下线故障迁移的票数
sentinel monitor mymaster 192.168.111.185 6379 2
# 如果要监视的主从集群(所有需要访问密码的节点的密码必须一致)需要密码则需要添加该配置
sentinel auth-pass mymaster 123456
```
接着使用命令`redis-sentinel /data/redis/sentinel.conf` 或`redis-server /data/redis/sentinel.conf --sentinel`分别启动哨兵集群中的机器即可。
#### 运行原理
* 当哨兵集群中的其中一个节点检测到 master 下线之后,即超过 daon-after-milliseconds 设置的超时时间内没有收到 master 的 ping 回复,则会判定 master 主观下线。
* 当哨兵集群中有超过 monitor 设置的客观下线票数数量的节点将 master 判定为主观下线时,则判定 master 为客观下线
* 当 master 被判定为客观下线以后,哨兵集群会采用 Raft 算法从集群中选出一位哨兵 leader 并由该节点进行故障迁移
* leader 首先根据主从集群中所有 slave 的 replica-priority 数值进行比较,数字越小则优先级越高,优先级最高的节点为新的 master。
* 如果 replica-priority 数值都一样,则比较所有 slave 的复制偏移量 offset,偏移量最大的优先称谓 master
* 如果偏移量也一样,则选择 Run ID 最小的节点为 master
* leader 会对新的 master 执行 slaveof no one 命令,使其成为 master
* 接着 leader 会对主从集群中的其他节点执行 slaveof 命令,使其成为新 master 节点的从节点
* 最后 leader 会强制修改故障的旧 master 节点的配置文件,将其降级为 slave,当故障恢复重启后,会成为新 master 的从节点
分片集群
----
虽然哨兵集群可以解决主从集群 master 宕机之后无法重新选举的问题,但仍然存在问题。首先就是在新 master 选举期间仍然有无法写入的问题,其次就是哨兵集群仅仅只用来监控并不能存储数据使得成本稍高。
因此为了解决这个问题,就需要对多个复制集进行集群,形成水平扩展,每个复制集只负责存储整个数据集的一部分,这就是 Redis 的分片集群,其作用就是提供在多个 Redis 节点间共享数据的程序集,不仅方便对集群扩缩容而且容易对数据分派查找。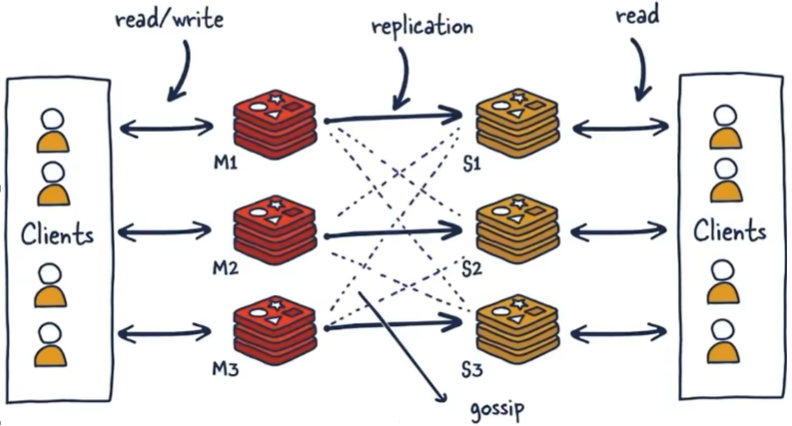要学习分片集群,需要先了解两个概念:
* slot:也叫槽位,Redis 分片集群没有使用一致性哈希,而是引入了哈希槽的概念。每个分片集群有 16384 个哈希槽位,每个 key 通过 CRC16 校验后对 16384 取模来决定放置哪个槽位,分片集群每个节点负责一部分哈希槽位。
* 分片:使用分片集群时,集群会将存储的数据分散到多台 Redis 集群上,这称之为分片。简言之,集群中每个节点都被认为是整个数据的一个分片。
\> 大厂高频面试题:为什么 Redis 分片集群的最大 slot 数量是 16384 个?
\> 针对于这个问题,Redis 的作者也给出了答案:https://github.com/redis/redis/issues/2576
\> 可以简单概括为以下三点:
\> - 如果槽位为 65535,发送心跳的信息头大小就达到 8k,使心跳包过于庞大。
\> - 其次 Redis 分片集群的主节点数量基本不可能超过一千个(集群节点越多,心跳包的消息体内携带的数据就越多,超过一千个会导致网络拥堵),因此 16384 个槽位也够用了,没必要扩展到 65535 个。
\> - 最后就是槽位越少,在节点少的情况下压缩比越高,容易传输。
搭建过程也非常简单,先在 redis.conf 配置文件中配置上以下内容:
```
# 开启集群模式
cluster-enabled yes
# 指定生成的集群配置文件名
cluster-config-file cluster-node.conf
# 集群节点的超时时间(单位:毫秒)
cluster-node-timeoout 5000
```
接着分别在每个节点执行以下命令启动 Redis(根据自己的配置文件所在位置调整):
```
redis-server /data/redis/redis.conf
```
最后在任意一台节点上执行以下命令(根据自己节点的 IP 和端口调整):
```
# --cluster-replicas 1 表示为每个 master 节点创建一个 slave 节点
redis-cli --cluster create --cluster-replicas 1 192.168.111.185:6381 192.168.111.185:6382 192.168.111.172:6383 192.168.111.172:6384 192.168.111.184:6385 192.168.111.184:6386
```
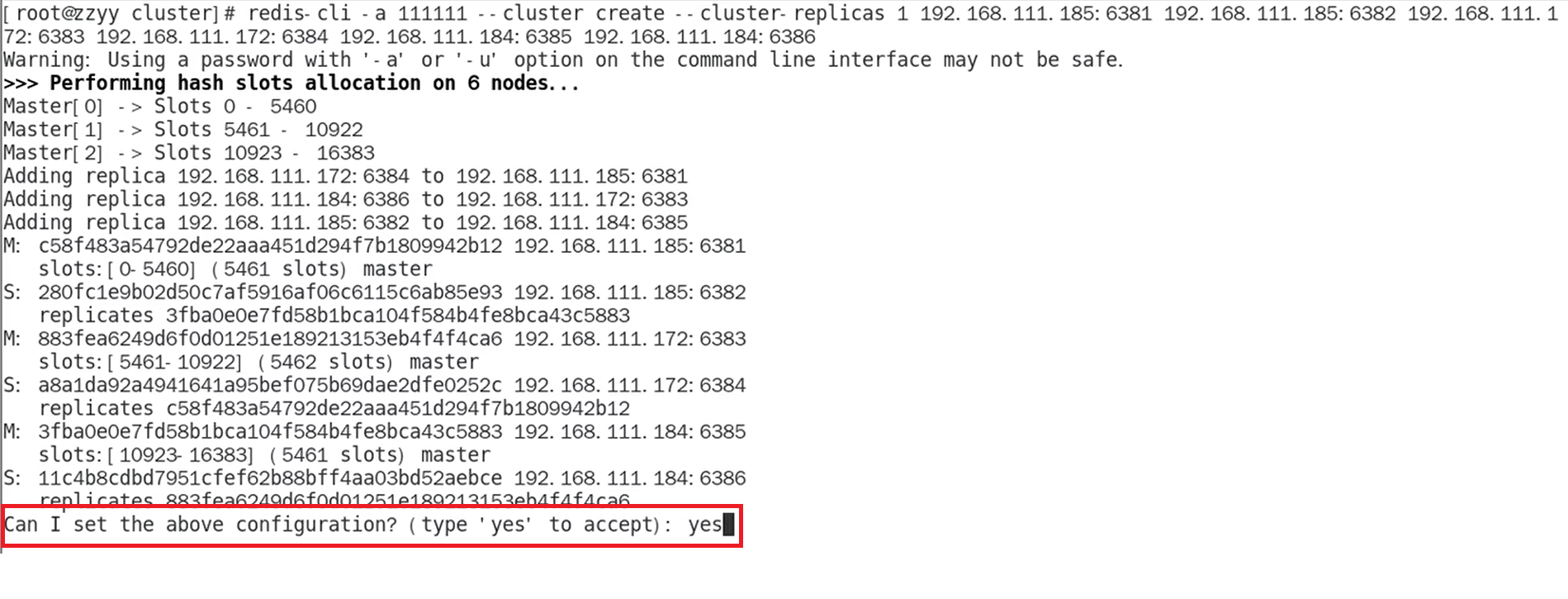可以看到执行上面这条命令之后,系统询问我们是否执行上面的配置,我们输入 yes,系统就会把我们配置的节点加入集群。
如果可以看到下面的信息,则说明集群搭建完成除此之外,我们还可以使用`cluster nodes`命令来查看节点之间的关系可以看到 192.168.111.185:6381 成为了 192.168.111.172:6384 的 master、192.168.111.172:6383 成为了 192.168.111.184:6386 的 master、192.168.111.184:6385 成为了 192.168.111.185:6382 的 master,说明 Redis 分片集群已经搭建成功。
此外,在访问Redis集群时,需要多加一个`-c`参数,否则当存取非该节点的 key 时不会进行重定向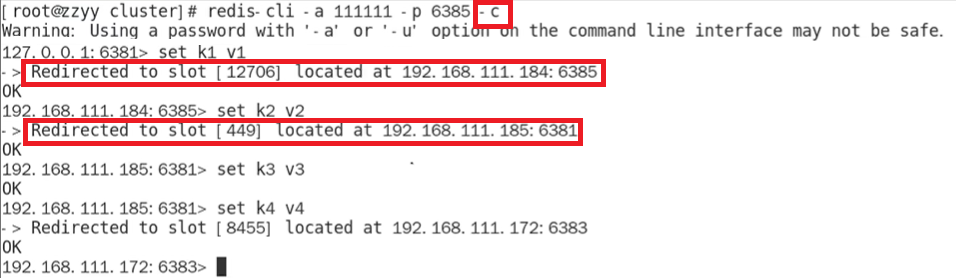可以看到,加入 -c 参数后 Redis 分片集群会将不属于该节点的请求进行重定向。
#### 集群扩容
当需要对集群进行扩容时,只需要按照上面的方法启动新的节点,并执行以下命令将新节点以 master 身份加入集群:
```
# 命令中的 192.168.111.184:6387 为新节点的IP和端口,192.168.111.185:6381 相当于介绍人身份(集群中已存在的节点),将 192.168.111.184:6387 拉入集群
redis-cli --cluster add-node 192.168.111.184:6387 192.168.111.185:6381
```
接着使用命令`redis-cli --cluster check 192.168.111.185:6381`查看新节点是否成功加入集群可以看到,新节点已经成功加入到集群中,但是却没有分配任何的槽位。
所以接下来就要使用下面的命令来为新节点分配槽位
```
redis-cli --cluster reshard 192.168.111.185:6381
```
执行命令后,系统会问我们需要移动多少槽位到新节点,这里我们填入 4096。之后需要我们指定新节点的 id,我们填入 192.168.111.184:6387 的节点 id。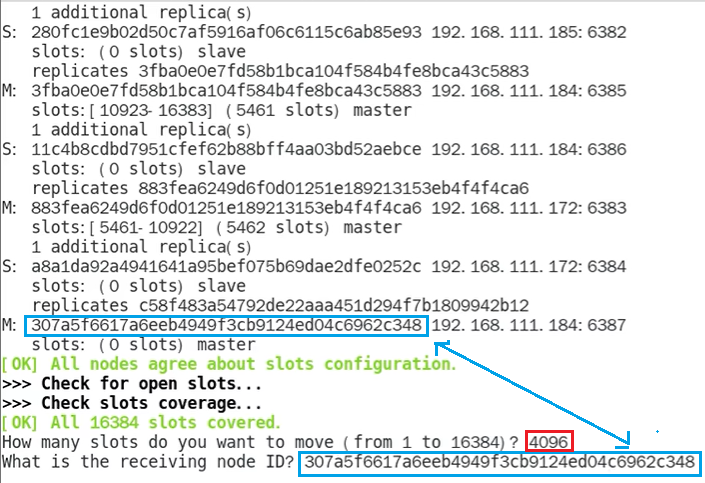之后我们根据提示输入 all 即可开始重新分配槽位等待槽位分为完毕后,我们再次检查集群情况可以看到,新节点已经被分配了 4096 个槽位
最后使用以下命令将 192.168.111.184:6388 以 slave 身份加入集群,并指定其 master 为 192.168.111.184:6387
```
# 命令中的 192.168.111.184:6388 为新节点的IP和端口,192.168.111.184:6387 相当于介绍人身份
# --cluster-slave 表示以 slave 身份加入集群
# --cluster-master-id 表示指定新节点的 master 的 id 为 307a5f6617a6eeb4949f3cb9124ed04c6962c348 即 192.168.111.184:6387 的 id
redis-cli --cluster add-node 192.168.111.184:6388 192.168.111.184:6387 --cluster-slave --cluster-master-id 307a5f6617a6eeb4949f3cb9124ed04c6962c348
```
接着,我们查看集群情况可以看到,新节点成功以 slave 身份加入集群并成为 192.168.111.184:6387 的从节点。至此 Redis 分片集群扩容完毕。
#### 集群缩容
这里我们以上面刚加入集群的 192.168.111.184:6387、192.168.111.184:6388 为例,再次把它们从集群中剔除。
要对集群进行缩容,需要先执行以下命令删除缩容节点的从节点:
```
# 其中 2a845089dfcf2c399444e5ff6823158eb04b884f 是 192.168.111.184:6388 的节点 id
redis-cli --cluster del-node 192.168.111.184:6388 2a845089dfcf2c399444e5ff6823158eb04b884f
```
接着执行下面的命令重新进行槽位分配
```
redis-cli --cluster reshard 192.168.111.185:6381
```
这里我们为了方便将 192.168.111.184:6387 的槽位全部分给 192.168.111.185:6381这时我们使用命令`redis-cli --cluster check 192.168.111.185:6381`检查集群情况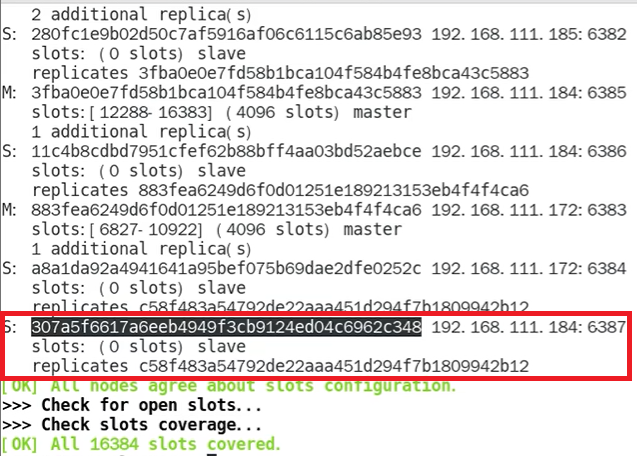可以看到 192.168.111.184:6387 已经变为了 192.168.111.185:6381 的从节点
因此,我们只需要使用命令将它从集群中剔除即可
```
# 其中 307a5f6617a6eeb4949f3cb9124ed04c6962c348 是 192.168.111.184:6387 的节点 id
redis-cli --cluster del-node 192.168.111.184:6387 307a5f6617a6eeb4949f3cb9124ed04c6962c348
```
最后我们再次检查集群情况可以看到,集群已经成功从四主四从恢复到了三主三从,只不过 192.168.111.185:6381 的槽位是其他两个主节点的二倍。至此分片集群缩容完毕。
![]()
众生皆苦,唯有自渡!
 JQuery.validationEngine表单验证插件(推荐)2024-11-24
JQuery.validationEngine表单验证插件(推荐)2024-11-24
 npm run build 在windows 和mac 没问题 在linux 上报错2024-09-03
npm run build 在windows 和mac 没问题 在linux 上报错2024-09-03
 nginx报错socket() failed (24: Too many open files) while connecting to upstream2024-09-06
nginx报错socket() failed (24: Too many open files) while connecting to upstream2024-09-06
 9.6K Star超越AirDrop!!!无需服务器,P2P文件传输神器2024-08-17
9.6K Star超越AirDrop!!!无需服务器,P2P文件传输神器2024-08-17
 (解决方案)size 0 of data subvolume is too small, minimum 100 blocks2024-08-29
(解决方案)size 0 of data subvolume is too small, minimum 100 blocks2024-08-29
