hadoop集群YARN作业资源不足排查实战
1.现象
目前 CC 集群出现大量任务积压,运行缓慢的情况,怀疑是集群的资源分配出现了问题。
CC 集群总共有 569 个 NodeManager,总共 VCore 数是 27704 ,内存171T,资源比较丰富。理论上,应该足够任务的执行。
经过现场的分析,发现如下现象。
集群总体的资源使用高,少量剩余
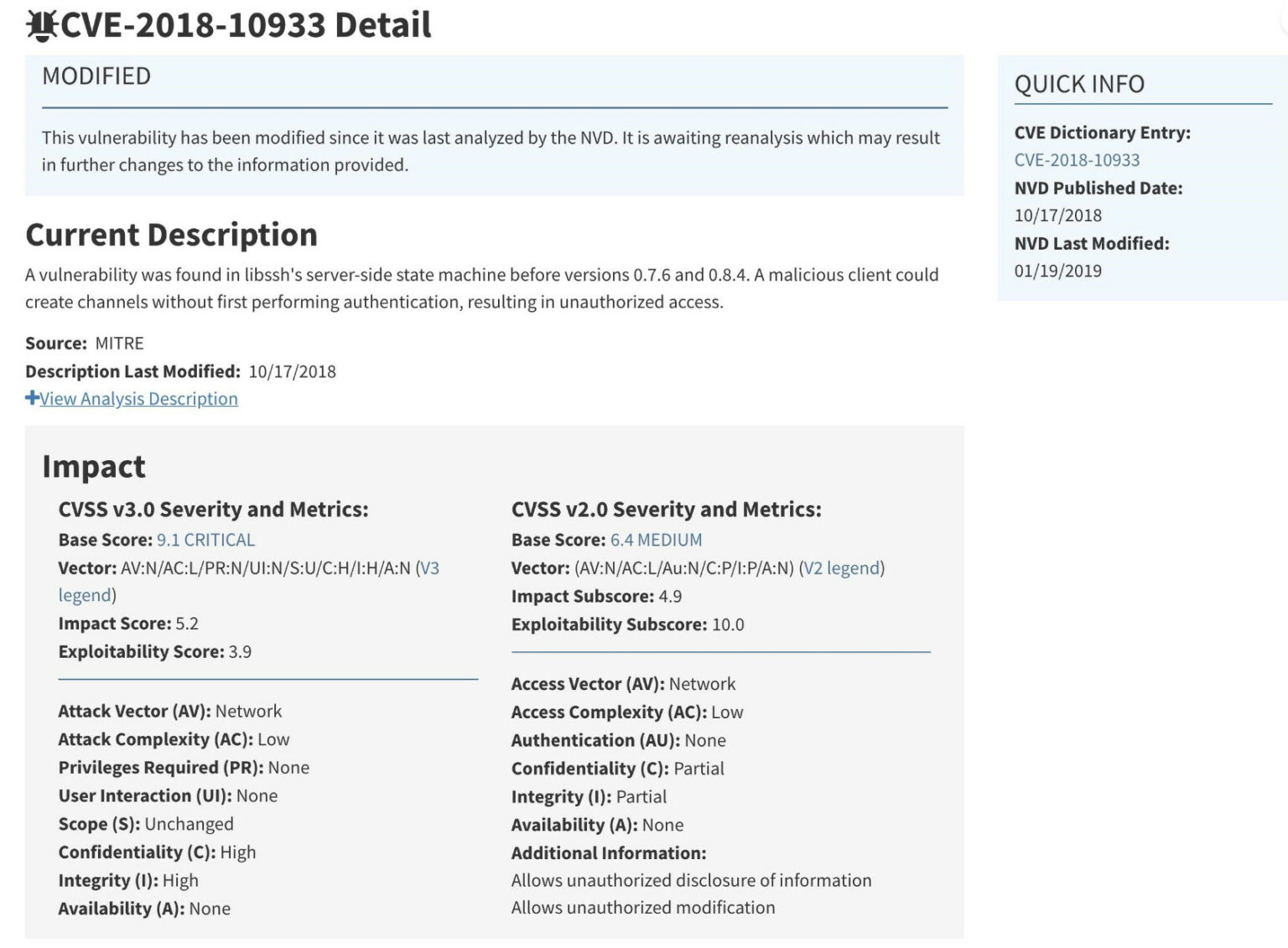
如下图所示,集群总体的资源使用已经非常高,但是仍有少量剩余。其中 CPU Vcore,总共 27704 个,使用了 26842 个。内存总共 171T,使用了153T。即集群 CPU 使用了 95%以上,但是仍然有少量的剩余。
队列最小资源没有得到满足
从上图可以看出,目前配置的队列最小资源都设置的比较大,即使集群资源使用非常高,仍然没有满足最小资源的需求。队列最小资源,是集群有资源的情况下,必须要满足的资源。并且集群中,绝大部分队列都没有达到最小资源。出现大量 Map Pening
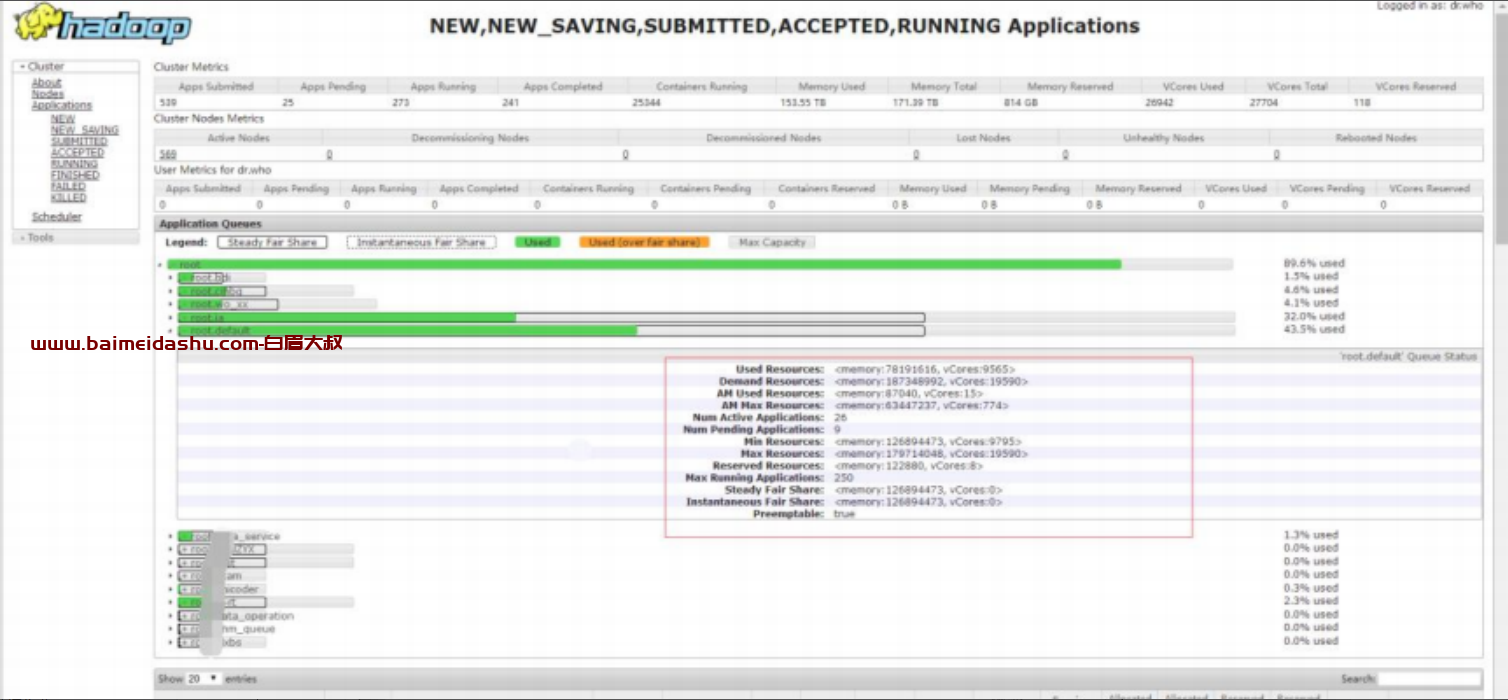
如下图所示,集群中出现大量的任务都有如下的现象。Reduce 已经启动,在等待 Map 阶段完成,然后向前执行,但是 Map 阶段还有部分任务没有完成,
这部分任务也拿不到资源执行,running 的 map 为 0。从而出现了死锁的情况。即 Reduce 启动了占用了资源,但是在等待 Map,而 Map 拿不到资源无法执行。
2.分析
原因1
根据上面的现象,可以分析得出,导致任务出现积压的情况,直接原因是因为,出现了资源分配的死锁。即 Reduce 阶段占用了资源,但是需要等待Map 阶段执行完成,而 Map 阶段在等待资源,但是资源已经被 Reduce 都占用了,无法申请到资源,因此无法执行。大量的任务都出现了这种情况,集群中绝大部分的资源都被 Reduce 的 Container 占用了,而 Map 阶段分到的资源很少。
Mapreduce 任务在执行任务时,分为 Map,Reduce 两个阶段,这两个阶段都需要申请 yarn 的 Container,进行运行。并且 Yarn 并不区分 Map,Reduce 的 Container 类型,只要是申请资源,会一视同仁。Reduce 阶段,需要获取 Map 阶段的输出,从而继续往下执行。Yarn 通过参数
mapreduce.job.reduce.slowstart.completedmaps,设定比例,例如设置为0.8(目前集群设置为 0.8),则 Map 阶段完成 80%后,Reduce 阶段就会开始申请 Container,占用资源。提前启动 Reduce 的好处是,可以尽早的申请到资源,然后 Reduce 首先从已经完成的 Map 任务中拷贝数据,Map 同时执行。从而,加快整体任务的执行。
然而,这个设定,在极端情况下,会出现问题:
1.集群中存在大量任务同时运行
2.其中不少的任务都需要启动大量的 Map 任务和 reduce 任务
3.集群总体的资源使用率已经非常高,没有很多的剩余资源
在上述的情况下,就有可能出现资源死锁的情况。由于大量的任务同时运行,并且其中不少的任务都有大量的 Map 任务和 Reduce 任务,当 Map任务完成到一定比例之和,就开始启动 Reduce 任务,Reduce 任务启动之后,占用了资源,但是 Map 还没有结束。集群总体的资源使用率已经非常高,没有很多的剩余资源,Map 阶段分配不到足够的资源,只能非常缓慢的运行,或者甚至分不到资源,直接不运行了
整个任务就停滞了,但是也不超时
(2)原因2
另外一个加剧该现象的原因是,因为目前集群队列的资源设定中,每个资源池的最小资源占比设置的比较大,总和已经超过了集群资源的总和 。
设定队列的最小资源,是为了保证队列能够至少能够拿到最小资源,不至于被饿死。并且集群有一定的剩余资源,可以供资源池之间竞争,作为补充。但是目前的设定,导致即使集群所有的资源也无法满足每个队列的最小资源。这样的情况,就导致了,集群的所有资源基本会被使用完,并且关键的是,所有的队列都认为是自己的最小资源。即使某个队列出现了资源饥饿的情况,也无法从集群或者其他队列抢占部分资源来补充。
3.解决方案
步骤1:
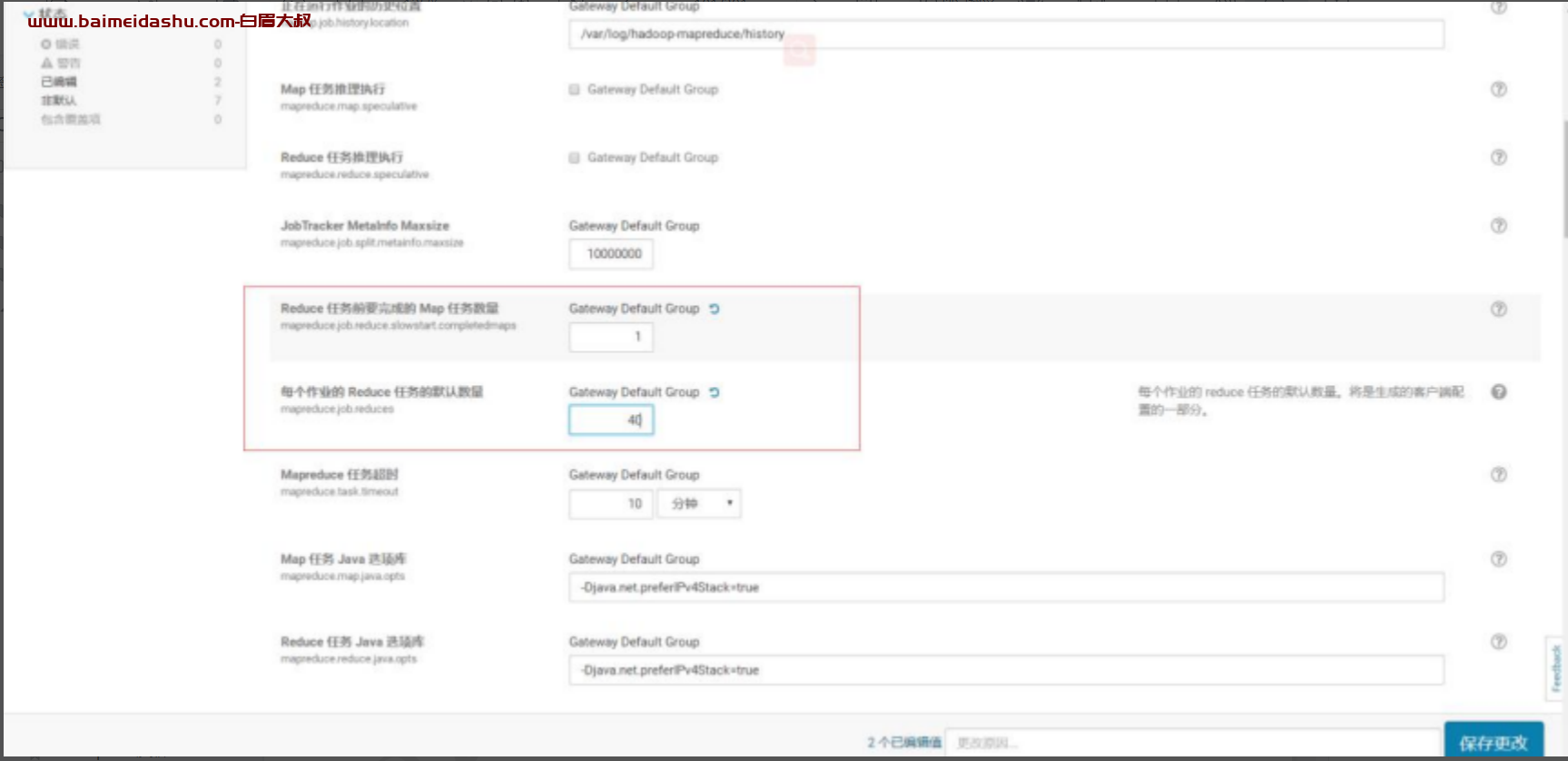
设置 mapreduce.job.reduce.slowstart.completedmaps 为 1
设置为 1 之后,Reduce 需要等待 Map 阶段都完成之后,才会申请资源并启动,这样的话,就不会出现 Reduce 占用资源而 Map 分配不到的情况了
如下图所示,通过 CM,设置mapreduce.job.reduce.slowstart.completedmaps 为 1。同时,原来设定默
认 reduce 个数为 600, 这个值偏大,修改为 40
步骤2:重新调整资源池的设定
重新调整各资源池,最小资源,最大资源,以及并发任务数。
建议调整所有资源池的最小资源为集群资源的 60%。最大资源为集群资源的 100%
4.整体修改
其他调整
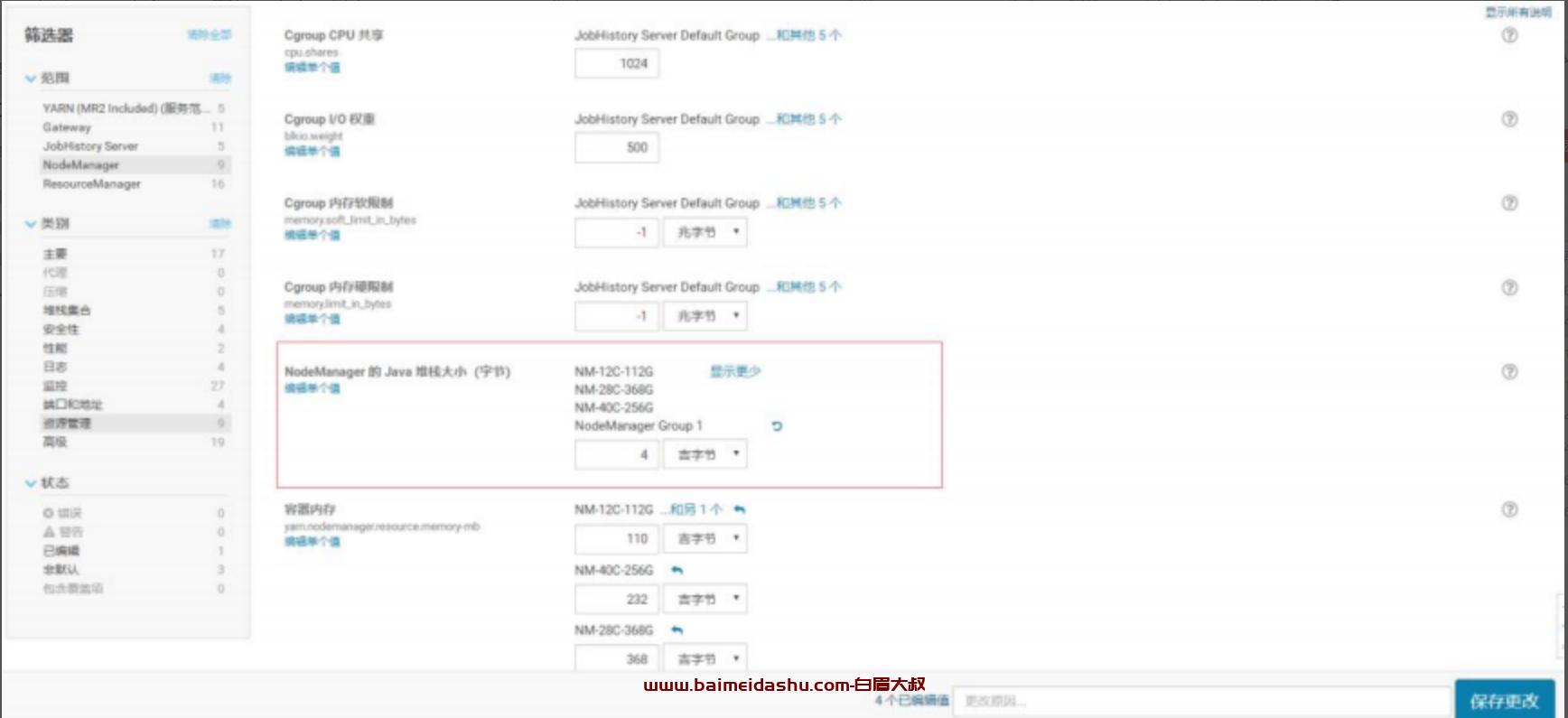
1-NodeManager 内存调整
如下图所示,目前集群 NodeManager 内存为 2G,对于一个比较繁忙,并且规模很大的集群,NodeManager 内存建议可以设置的稍微大一点,下图修改成 4G。
2-控制 Map 数
可以通过设置 mapreduce.input.fileinputformat.split.minsize 参数来控制任务的 Map 数,该参数控制每个 map 的最小处理数据量。
组合参数优化:减少 map 数
是否支持可切分的 CombineInputFormat 合并输入小文件此参数必须加否则不生效
set hive.hadoop.supports.splittable.combineinputformat=true;
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
一个节点上 split 的最大的大小
set mapred.max.split.size=1073741824;
一个交换机下 split 最小的大小
set mapred.min.split.size.per.node=1073741824;
一个机架下 split 至少的大小
set mapred.min.split.size.per.rack=1073741824;