2024-03-12
分类:网赚思路
阅读(696) 评论(0)
*** ** * ** ***
ControlNet作者又出新工作,这次的工作LayerDiffusion它使得大规模预训练的Stable Diffusion能够生成透明图像。该方法允许生成单个透明图像或多个透明图层,效果堪比商业产品Adobe Stock。而且LayerDiffusion和ControlNet一样支持基于SD微调的模型。
"LayerDiffusion绝不是简单的抠图,重点在于生成。" 给一句prompt,用Stable Diffusion可以直接生成单个或多个透明图层(PNG)!例如来一句: "头发凌乱的女性,在卧室里。" "在乡下,在桌子上烧柴。" 
可以看到,AI不仅生成了符合prompt的完整图像,就连背景和人物也能分开。可以生成具有透明度的多个图层。这些层可以混合产生与提示相对应的图像。放大可以看到细节,包括凌乱的头发和半透明的火。
**相关链接** 论文链接: https://arxiv.org/abs/2402.17113 Github链接: https://github.com/layerdiffusion/LayerDiffusion 原理解读:https://zhuanlan.zhihu.com/p/685029401  **摘要**
我们提出了LayerDiffusion,一种能够使大规模预训练的潜在扩散模型生成透明图像的方法。该方法可以生成单个透明图像或多个透明层。该方法学习了一个"潜在透明度",将Alpha通道透明度编码到预训练潜在扩散模型的潜在流形中。通过将添加的透明度作为潜在偏移量进行调节,并对预训练模型的原始潜在分布进行最小改变,它保持了大规模扩散模型的生产就绪质量。通过使用人机协同收集方案收集1M个透明图像层对来训练模型。我们展示了潜在透明性可以应用于不同的开源图像生成器,或者被调整为各种条件控制系统以实现前景/背景条件下的层生成、联合层生成、层内容结构控制等应用。用户研究发现,在大多数情况下(97%),用户更喜欢我们本地生成的透明内容,而不是之前的临时解决方案,如先生成再抠图。用户还报告说我们所生成的透明图片质量与Adobe Stock等真实商业可见资产相当好。**方法**
LayerDiffusion的核心,是一种叫做潜在透明度(latent transparency)的方法。简单来说,它可以允许在不破坏预训练潜在扩散模型(如Stable Diffusion)的潜在分布的前提下,为模型添加透明度。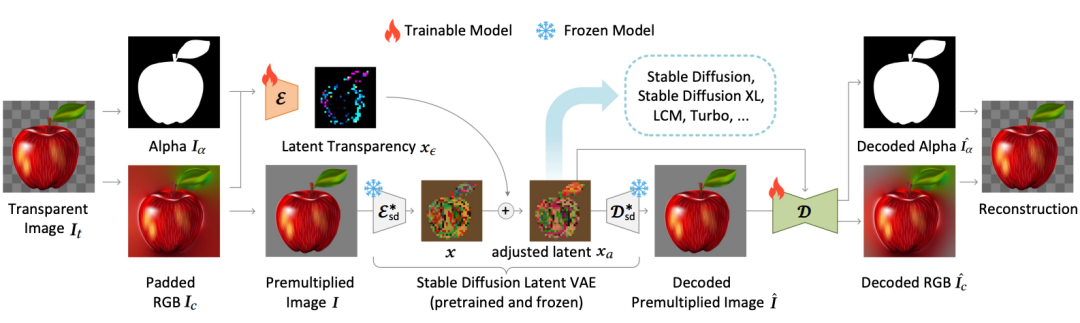
在具体实现上,可以理解为在潜在图像上添加一个精心设计过的小扰动(offset),这种扰动被编码为一个额外的通道,与RGB通道一起构成完整的潜在图像。
为了实现透明度的编码和解码,作者训练了两个独立的神经网络模型:一个是潜在透明度编码器(latent transparency encoder),另一个是潜在透明度解码器(latent transparency decoder)。
编码器接收原始图像的RGB通道和alpha通道作为输入,将透明度信息转换为潜在空间中的一个偏移量。
而解码器则接收调整后的潜在图像和重建的RGB图像,从潜在空间中提取出透明度信息,以重建原始的透明图像。
为了确保添加的潜在透明度不会破坏预训练模型的潜在分布,作者提出了一种"无害性"(harmlessness)度量。
这个度量通过比较原始预训练模型的解码器对调整后潜在图像的解码结果与原始图像的差异,来评估潜在透明度的影响。 在训练过程中,作者还使用了一种联合损失函数(joint loss function),它结合了重建损失(reconstruction loss)、身份损失(identity loss)和判别器损失(discriminator loss)。 它们的作用分别是:
* 重建损失:用于确保解码后的图像与原始图像尽可能相似;
* 身份损失:用于确保调整后的潜在图像能够被预训练解码器正确解码;
* 判别器损失:则是用于提高生成图像的真实感。
通过这种方法,任何潜在扩散模型都可以被转换为透明图像生成器,只需对其进行微调以适应调整后的潜在空间。 **效果展示** 
上图展示了模型生成的各种透明图像示例。每个组提示都在示例的顶部。
多层定性结果。使用不同的提示符来呈现模型生成的定性结果的话题。对于每个示例显示混合图像和两个输出层。 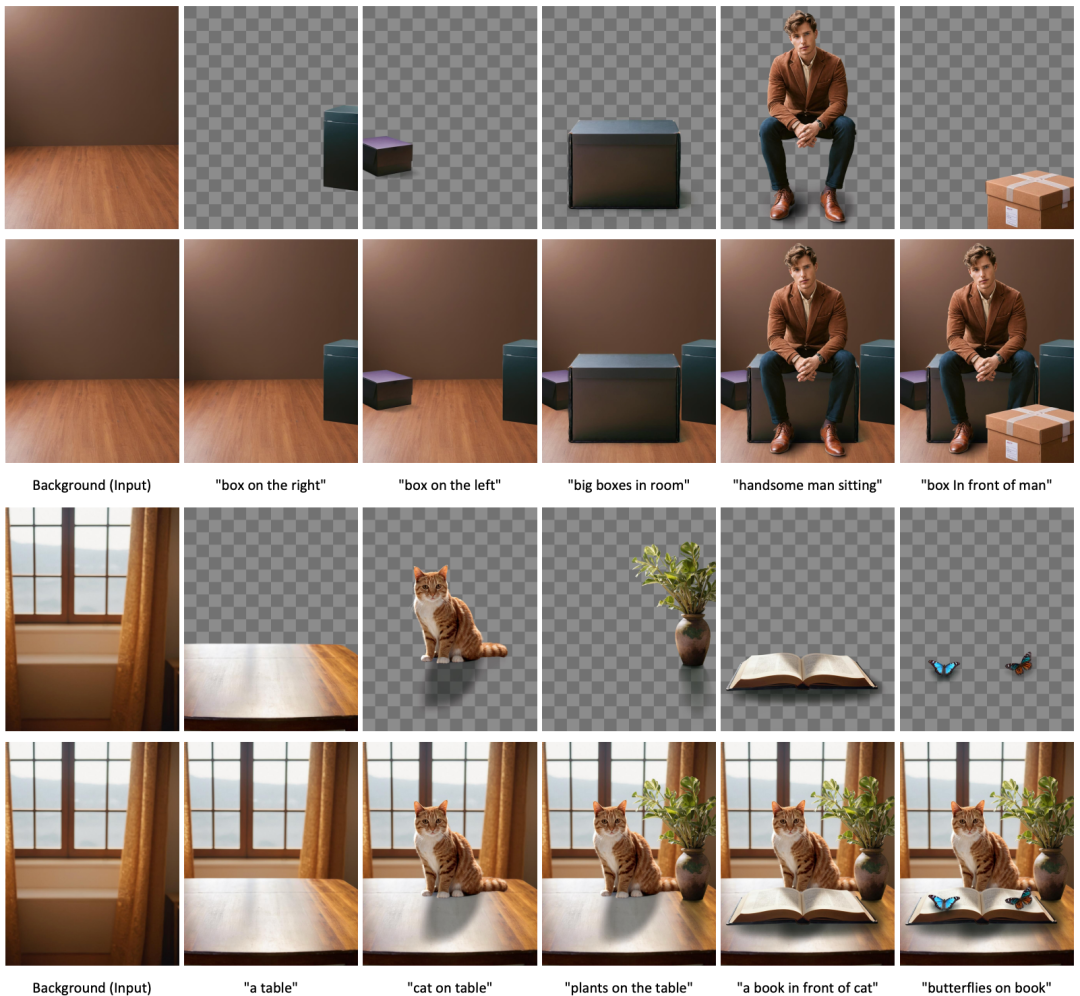   
![]()
众生皆苦,唯有自渡!
 51工具盒子
51工具盒子