0X00前言 {#0X00%E5%89%8D%E8%A8%809546}
这份作业是我们学校的爬虫作业,今天就顺带发送到博客里
该爬虫仅供学习使用,切勿违法操作
0X01正文 {#0X01%E6%AD%A3%E6%96%876669}
该爬虫程序所须库有
requests,lxml,time
首先我们查看一下网页的源代码(右键查看,并保存到本地)

在这里,我们可以发现,每条评论的格式都为
<p class=" comment-content">
<span class="short">所爬的内容</span>
</p>
所以说接下来我们用lxml的xpath来爬取,我是这么定位的:
tiqu=soup.xpath('//p[@class=" comment-content"]/span[@class="short"]/text()')
这就是第一阶段,我用来初步调试能否正常爬取。
以下附上第一阶段的代码截图
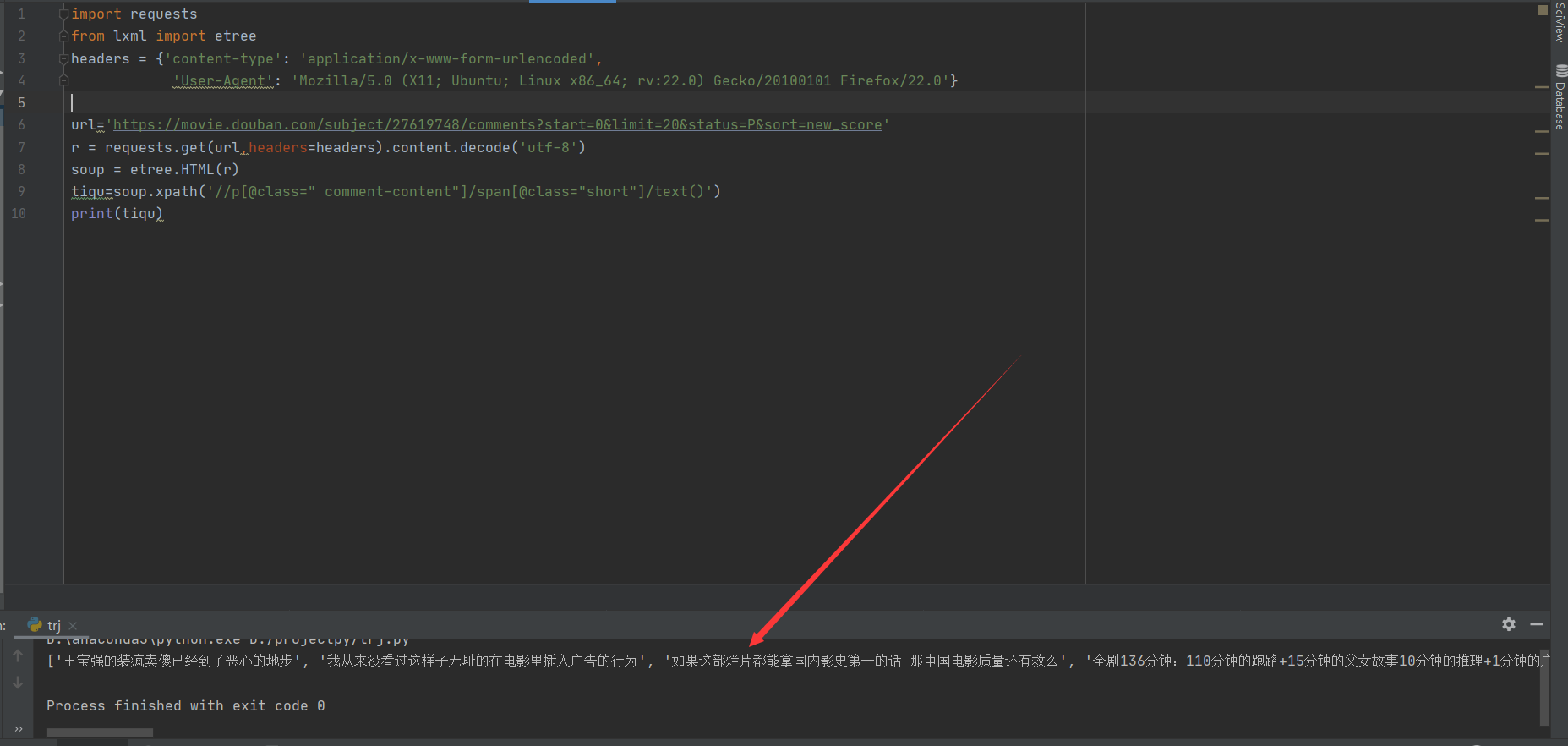
okk,已经正常爬取评论了。
然后我们进入下一阶段,开始爬取所有的连接。
首先我们先打开豆瓣网站

点击下一页的时候连接变为
https://movie.douban.com/subject/27619748/comments?start=20&limit=20&status=P&sort=new_score
我们可以发现多了一个start参数。所以说,我们可以通过修改start参数来进行页数的切换。
经过查询目前最多到200为止。
for page in range(0,220,20):
接下来我们需要把爬取的数据保存到一个文本里
with open(r'trj1.txt', 'a+',encoding='UTF-8') as f:
f.write(tiqu + '\n')
f.close()
噢,一定要记得加点延迟访问。否则可能会被网站拦截!!!而且降低访问速度,对对方网站的资源占用也不会太高。最后就如下图所示。

如果想要方便调用的话,我们还可以利用def函数来封装。如图

接下来就到了生成词云了。
(这里我直接用了系主任给的博客文章进行微调)。
不知道为什么,我文本格式是utf-8可,返回信息却是gbk.

不过问题不大,只需要对这个地方调整即可

然后通过调整以下代码来令图片更好看
wc = WordCloud(
background_color="white", # 背景颜色
max_words=500, # 显示最大词数
font_path="C:\Windows\WinSxS\amd64_microsoft-windows-font-truetype-simsun_31bf3856ad364e35_10.0.18362.1_none_cd668f05ece74044\simsun.ttc", # 使用字体,每个人的文件路径可能不同
min_font_size=10,
max_font_size=60,
width=400,
height=860,
mask=color_mask) # 图幅宽度
附上成品图

0X02文末 {#0X02%E6%96%87%E6%9C%AB1063}
这篇文章还是蛮有趣的,下一篇过几天发。感兴趣的xd麻烦github点点star
地址https://github.com/byyanxia/WinterVacationHomework