2024-03-12
分类:开源工具
阅读(945) 评论(0)
上周作者实现了一个功能超强的本地ChatGPT,收到了很多朋友的点赞和好评,今天我们在此基础上继续完善,给它加上RAG文档对话功能。
[247.2k star! 超强大的私有化ChatGPT,支持图像识别/文生图/语音输入/文本朗读,个人电脑可运行!](http://mp.weixin.qq.com/s?__biz=MzU0MzI3MzU1Ng==&mid=2247484774&idx=1&sn=4aff4a1ddf920561905947cc488cde7f&chksm=fb0ca25dcc7b2b4b14101988865f49752d5a9075c7398a4b8a37235d063802d194ee241a41af&scene=21#wechat_redirect)
我上传了一个阿里巴巴Java代码规范的pdf,以下是问答效果: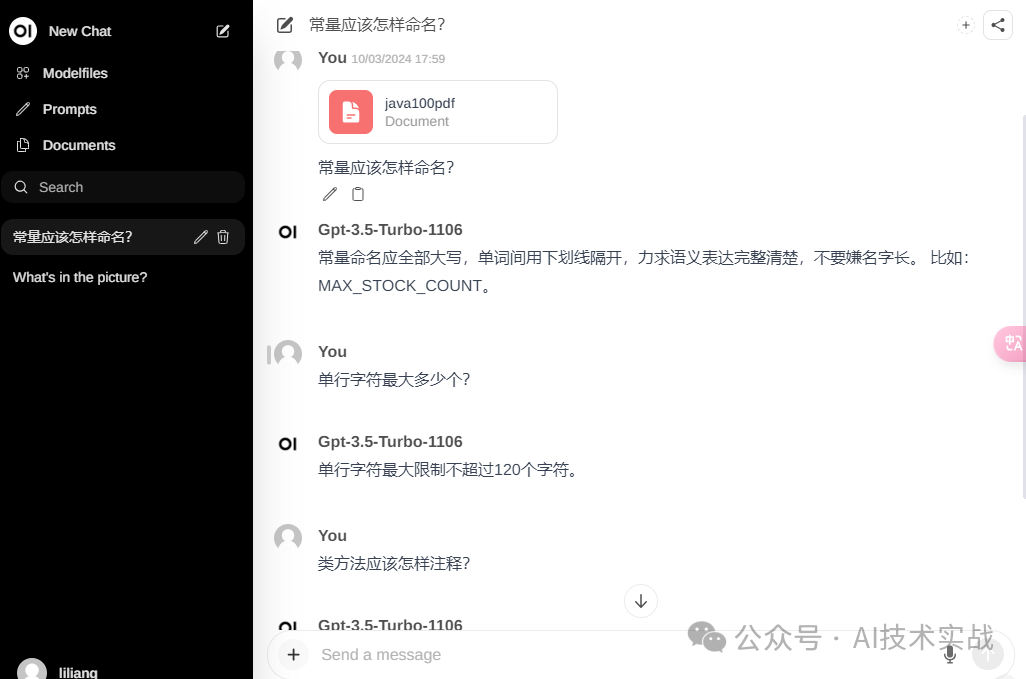 下文分为实战步骤、原理解析两部分。
**1.设置embedding模型**
重点:open-webui默认的embedding模型all-MiniLM-L6-v2只支持英文并且效果不好,我们将其改为更为强大的多语言模型intfloat/multilingual-e5-large模型,使用以下命令启动容器,与之前命令相比增加了RAG_EMBEDDING_MODEL参数。
\*
```
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui -e RAG_EMBEDDING_MODEL=intfloat/multilingual-e5-large --restart always ghcr.io/open-webui/open-webui:main
```
```
更多embedding模型可从文末链接获取2.添加文档
```
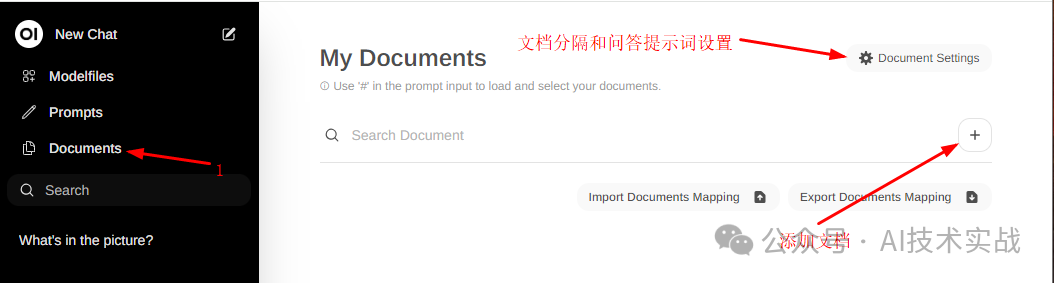
点击+添加一个文档,支持pdf、docx、txt、md等多种格式,如果文档较大需要稍等一会,等下面列表中显示出来自己添加的文档即可。
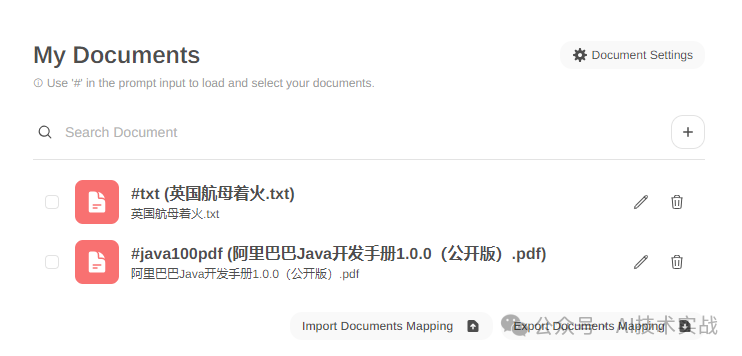
**3.开始问答**
==========
按下图操作即可开始对文档进行问答:
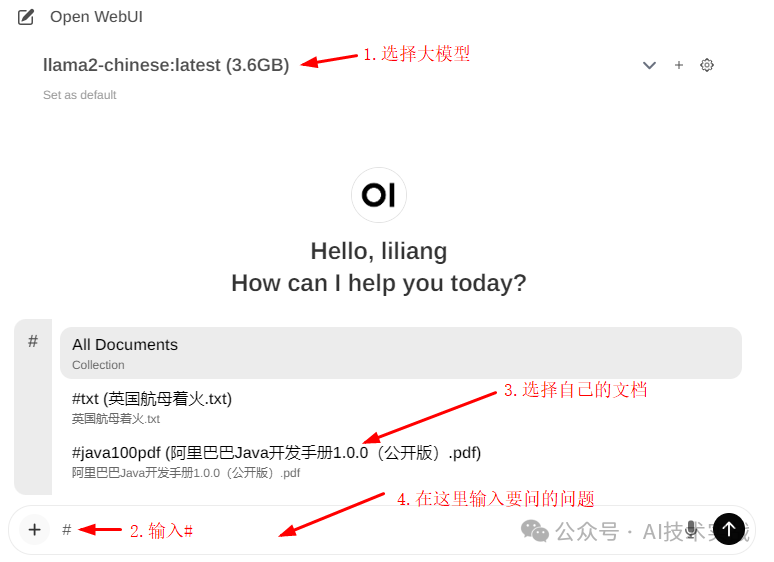
**4.原理解析**
==========
Open-webui项目中文档问答的源码在backend/apps/rag/main.py中,我们结合上面的操作步骤、源码和langchain-chatchat项目中的一张图,简单描述一下实现原理。
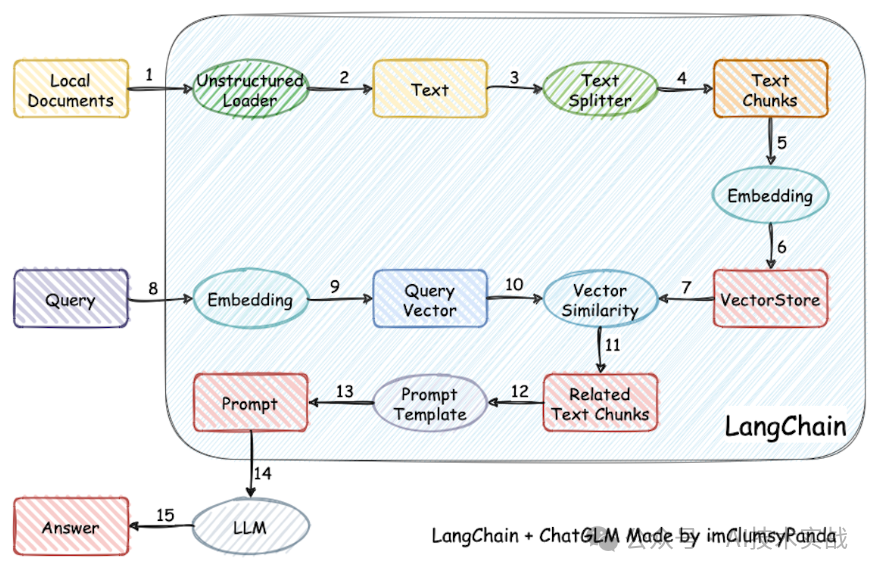
4.1 当我们添加pdf文档时,open-webui前端调用服务端的/doc接口,对应上图的1、2、3、4、5、6步。
\*
\*
\*
\*
\*
\*
\*
\*
```
// main.py@app.post("/doc")// 根据文件类型获取加载器,不同的文件类型对应不同的加载器loader, known_type = get_loader(file.filename, file.content_type, file_path)// 将pdf等文件解析为文本data = loader.load()// 文本切割、向量化、存储result = store_data_in_vector_db(data, collection_name)
```
4.2 当我们针对文档提问时,主要分两次请求完成:
* 前端请求/query/doc接口,服务端根据问题从向量数据库中查出相关内容原文,对应上图的8、9、10、11步。
*
*
*
*
*
*
```
@app.post("/query/doc")result = collection.query( query_texts=[form_data.query], n_results=form_data.k if form_data.k else app.state.TOP_K,)return result
```
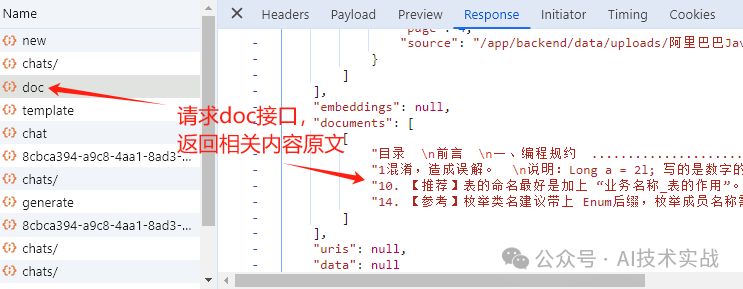
* 把问题与向量数据库查询结果一起作为prompt提交给大模型,大模型返回最终结果,对应上图的12、13、14、15步。

prompt大概意思就是:
\*
```
请根据我提供的上下文回答问题,我的问题是:{query},上下文是:{向量数据库查询结果}
```
**5.更多embedding模型**
===================
如果embedding模型效果不好,可访问以下链接使用更多模型: https://huggingface.co/models?library=sentence-transformers
![]()
众生皆苦,唯有自渡!