2024-03-12
分类:开源工具
阅读(427) 评论(0)
> 
> ?**这是一个或许对你有用的开源项目**
>
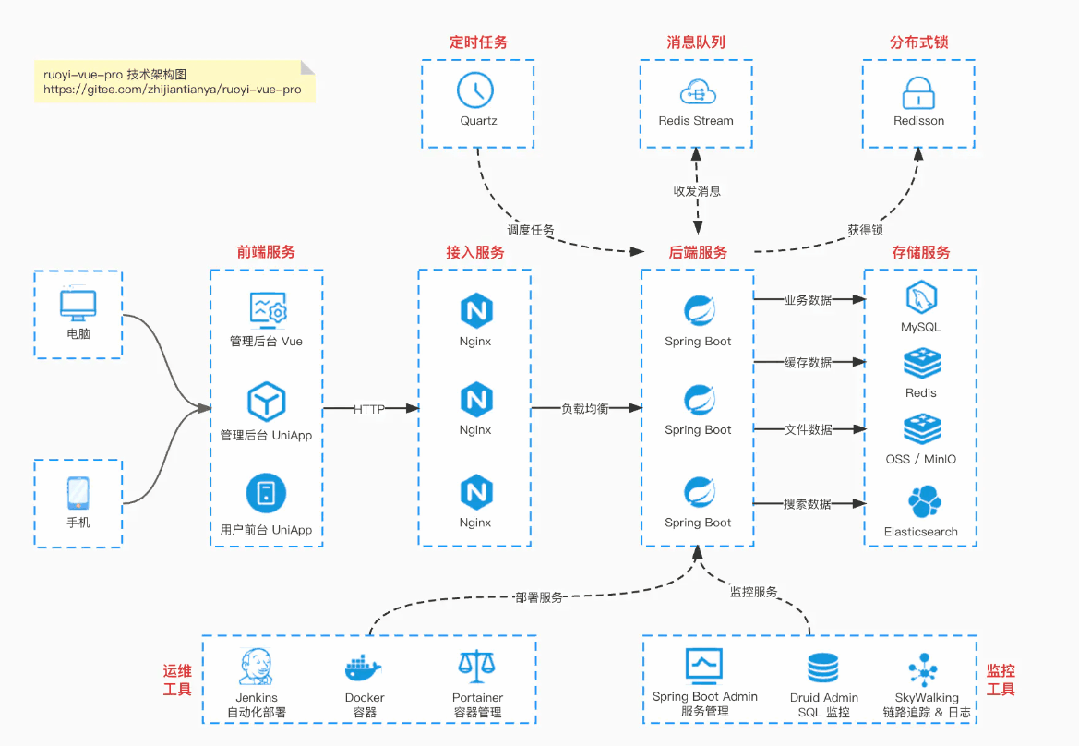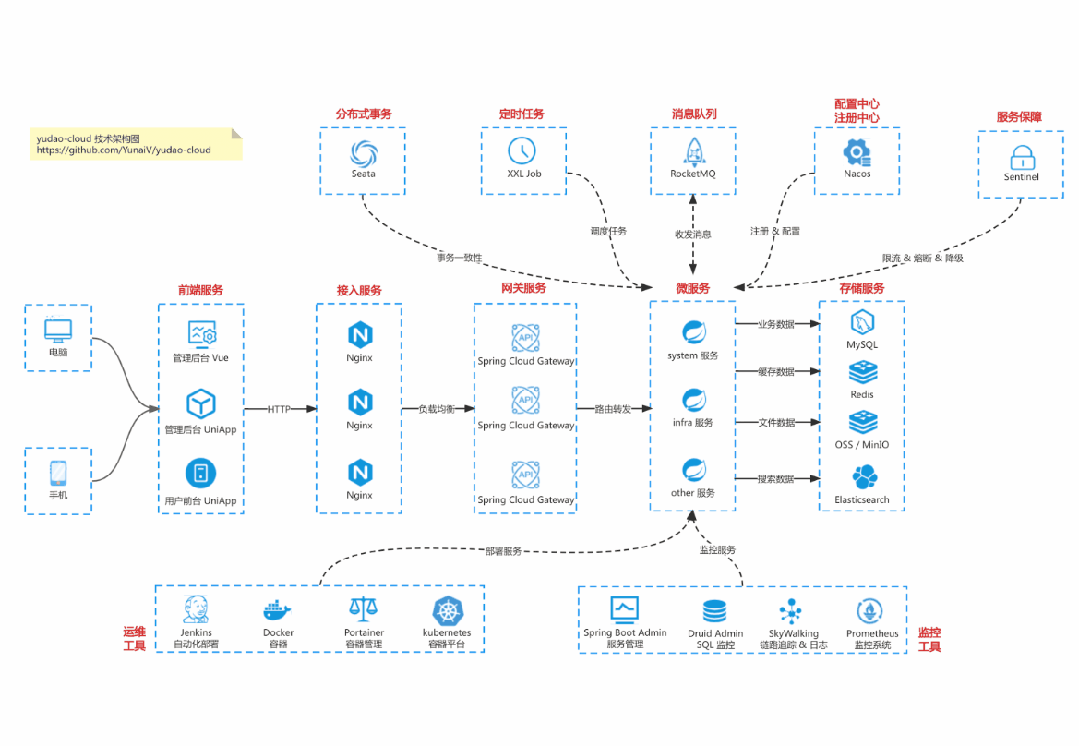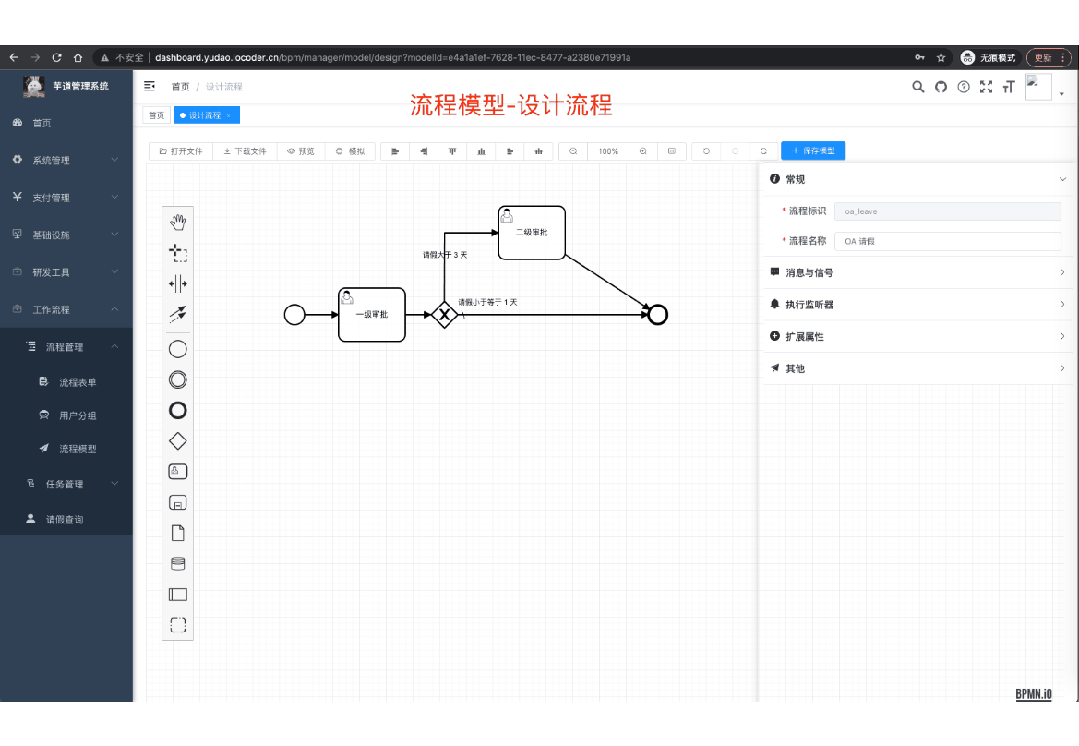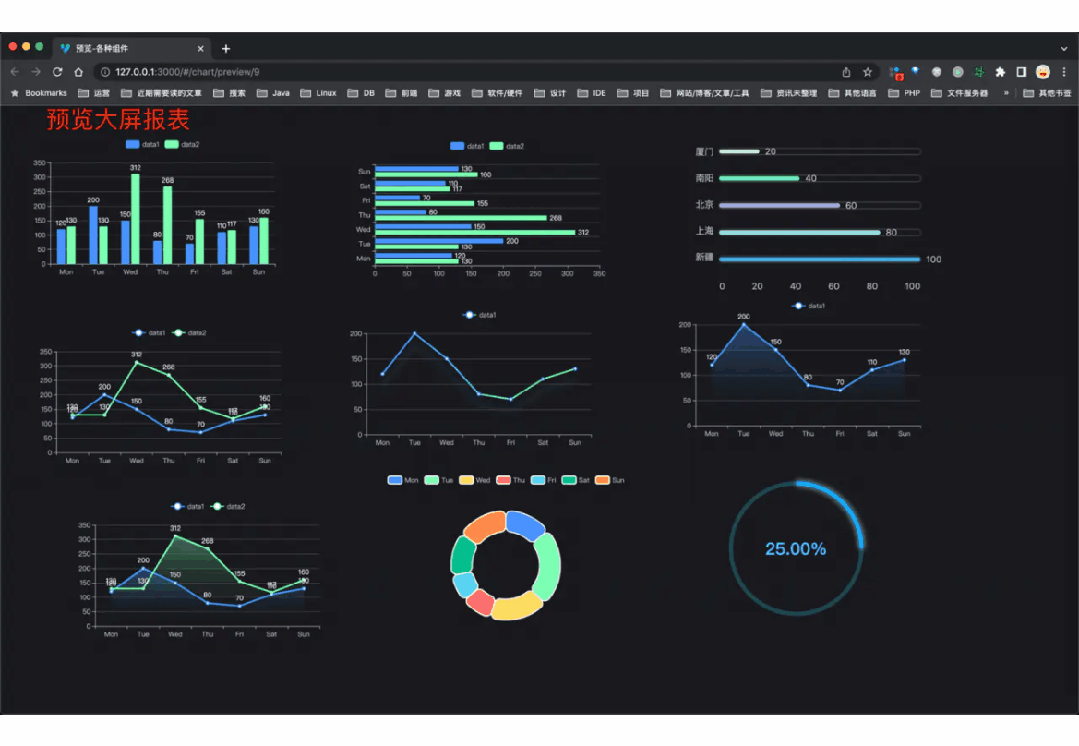
> 国产 Star 破 10w+ 的开源项目,前端包括管理后台 + 微信小程序,后端支持单体和微服务架构。
>
> 功能涵盖 RBAC 权限、SaaS 多租户、数据权限、商城、支付、工作流、大屏报表、微信公众号、CRM 等等功能:
>
> * Boot 仓库:https://gitee.com/zhijiantianya/ruoyi-vue-pro
>
> * Cloud 仓库:https://gitee.com/zhijiantianya/yudao-cloud
>
> * 视频教程:https://doc.iocoder.cn
>
> 【国内首批】支持 JDK 21 + SpringBoot 3.2.2、JDK 8 + Spring Boot 2.7.18 双版本
[来源:blog.csdn.net/weixin_56270372
/article/details/135936319](https://mp.weixin.qq.com/s?__biz=MzUzMTA2NTU2Ng==&mid=2247487551&idx=1&sn=18f64ba49f3f0f9d8be9d1fdef8857d9&scene=21#wechat_redirect)
* [背景](https://mp.weixin.qq.com/s?__biz=MzUzMTA2NTU2Ng==&mid=2247487551&idx=1&sn=18f64ba49f3f0f9d8be9d1fdef8857d9&chksm=fa496f8ecd3ee698f4954c00efb80fe955ec9198fff3ef4011e331aa37f55a6a17bc8c0335a8&scene=21&token=899450012&lang=zh_CN#wechat_redirect)
* [分布式联接算法](https://mp.weixin.qq.com/s?__biz=MzUzMTA2NTU2Ng==&mid=2247487551&idx=1&sn=18f64ba49f3f0f9d8be9d1fdef8857d9&chksm=fa496f8ecd3ee698f4954c00efb80fe955ec9198fff3ef4011e331aa37f55a6a17bc8c0335a8&scene=21&token=899450012&lang=zh_CN#wechat_redirect)
* [Shuffle Join(洗牌联接)](https://mp.weixin.qq.com/s?__biz=MzUzMTA2NTU2Ng==&mid=2247487551&idx=1&sn=18f64ba49f3f0f9d8be9d1fdef8857d9&chksm=fa496f8ecd3ee698f4954c00efb80fe955ec9198fff3ef4011e331aa37f55a6a17bc8c0335a8&scene=21&token=899450012&lang=zh_CN#wechat_redirect)
* [Broadcast Join(广播联接)](https://mp.weixin.qq.com/s?__biz=MzUzMTA2NTU2Ng==&mid=2247487551&idx=1&sn=18f64ba49f3f0f9d8be9d1fdef8857d9&chksm=fa496f8ecd3ee698f4954c00efb80fe955ec9198fff3ef4011e331aa37f55a6a17bc8c0335a8&scene=21&token=899450012&lang=zh_CN#wechat_redirect)
* [MapReduce Join(MapReduce联接)](https://mp.weixin.qq.com/s?__biz=MzUzMTA2NTU2Ng==&mid=2247487551&idx=1&sn=18f64ba49f3f0f9d8be9d1fdef8857d9&chksm=fa496f8ecd3ee698f4954c00efb80fe955ec9198fff3ef4011e331aa37f55a6a17bc8c0335a8&scene=21&token=899450012&lang=zh_CN#wechat_redirect)
* [Sort-Merge Join(排序-合并联接)](https://mp.weixin.qq.com/s?__biz=MzUzMTA2NTU2Ng==&mid=2247487551&idx=1&sn=18f64ba49f3f0f9d8be9d1fdef8857d9&chksm=fa496f8ecd3ee698f4954c00efb80fe955ec9198fff3ef4011e331aa37f55a6a17bc8c0335a8&scene=21&token=899450012&lang=zh_CN#wechat_redirect)
*** ** * ** ***
[背景](https://mp.weixin.qq.com/s?__biz=MzUzMTA2NTU2Ng==&mid=2247487551&idx=1&sn=18f64ba49f3f0f9d8be9d1fdef8857d9&scene=21#wechat_redirect)
-----------------------------------------------------------------------------------------------------------------------------------------
最近在阅读查询优化器的论文,发现System R中对于Join操作的定义一般分为了两种,即嵌套循环、排序-合并联接。
考虑到我的领域是在处理分库分表或者其他的分区模式,这让我开始不由得联想我们怎么在分布式场景应用这个Join逻辑,对于两个不同库里面的不同表我们是没有办法直接进行Join操作的。查阅资料后发现原来早有定义,即分布式联接算法。
> 基于 Spring Boot + MyBatis Plus + Vue \& Element 实现的后台管理系统 + 用户小程序,支持 RBAC 动态权限、多租户、数据权限、工作流、三方登录、支付、短信、商城等功能
>
> * 项目地址:https://github.com/YunaiV/ruoyi-vue-pro
>
> * 视频教程:https://doc.iocoder.cn/video/
[分布式联接算法](https://mp.weixin.qq.com/s?__biz=MzUzMTA2NTU2Ng==&mid=2247487551&idx=1&sn=18f64ba49f3f0f9d8be9d1fdef8857d9&scene=21#wechat_redirect)
----------------------------------------------------------------------------------------------------------------------------------------------
跨界点处理数据即分布式联接算法,常见的有四种模型:`Shuffle Join`(洗牌联接)、`Broadcast Join`(广播联接)、`MapReduce Join`(MapReduce联接)、`Sort-Merge Join`(排序-合并联接)。
接下来将进行逐一了解与分析,以便后续开发的应用。
### [Shuffle Join(洗牌联接)](https://mp.weixin.qq.com/s?__biz=MzUzMTA2NTU2Ng==&mid=2247487551&idx=1&sn=18f64ba49f3f0f9d8be9d1fdef8857d9&scene=21#wechat_redirect)
先上原理解释:
> "
>
> `Shuffle Join`的核心思想是将来自不同节点的数据重新分发(洗牌),使得可以联接的数据行最终位于同一个节点上。
>
> "
>
> 通常,对于要联接的两个表,会对联接键应用相同的哈希函数,哈希函数的结果决定了数据行应该被发送到哪个节点。这样,所有具有相同哈希值的行都会被送到同一个节点,然后在该节点上执行联接操作。
可能解释完还是有点模糊,举个例子,有两张表,分别以id字段进行分库操作,且哈希算法相同(为了简单,这里只介绍分库场景,分库分表同理。算法有很多种,这里举例是hash算法),那么这两张表的分片或许可以在同一个物理库中,这样我们不需要做大表维度的处理,我们可以直接下推Join操作到对应的物理库操作即可。
在`ShardingSphere`中,这种场景类似于绑定表的定义,如果两张表的算法相同,可以直接配置绑定表的关系,进行相同算法的连接查询,避免复杂的笛卡尔积。
这样做的好处是可以尽量下推到数据库操作,在中间件层面我们可以做并行处理,适合大规模的数据操作。
但是,这很理想,有多少表会采用相同算法处理呢。
### [Broadcast Join(广播联接)](https://mp.weixin.qq.com/s?__biz=MzUzMTA2NTU2Ng==&mid=2247487551&idx=1&sn=18f64ba49f3f0f9d8be9d1fdef8857d9&scene=21#wechat_redirect)
先上原理解释:
> "
>
> 当一个表的大小相对较小时,可以将这个小表的全部数据广播到所有包含另一个表数据的节点上。
>
> "
>
> 每个节点上都有小表的完整副本,因此可以独立地与本地的大表数据进行联接操作,而不需要跨节点通信。
举个例子,有一张非常小的表A,还有一张按照ID分片的表B,我们可以在每一个物理库中复制一份表A,这样我们的Join操作就可以直接下推到每一个数据库操作了。
这种情况比Shuffle Join甚至还有性能高效,这种类似于`ShardingSphere`中的广播表的定义,其存在类似于字典表,在每一个数据库都同时存在一份,每次写入会同步到多个节点。
这种操作的好处显而易见,不仅支持并行操作而且性能极佳。
但是缺点也显而易见,如果小表不够小数据冗余不说,广播可能会消耗大量的网络带宽和资源。
### [MapReduce Join(MapReduce联接)](https://mp.weixin.qq.com/s?__biz=MzUzMTA2NTU2Ng==&mid=2247487551&idx=1&sn=18f64ba49f3f0f9d8be9d1fdef8857d9&scene=21#wechat_redirect)
先上原理解释:
MapReduce是一种编程模型,用于处理和生成大数据集,其中的联接操作可以分为两个阶段:Map阶段和Reduce阶段。
##### [Map阶段:](https://mp.weixin.qq.com/s?__biz=MzUzMTA2NTU2Ng==&mid=2247487551&idx=1&sn=18f64ba49f3f0f9d8be9d1fdef8857d9&scene=21#wechat_redirect)
* 每个节点读取其数据分片,并对需要联接的键值对应用一个映射函数,生成中间键值对。
##### [Reduce阶段:](https://mp.weixin.qq.com/s?__biz=MzUzMTA2NTU2Ng==&mid=2247487551&idx=1&sn=18f64ba49f3f0f9d8be9d1fdef8857d9&scene=21#wechat_redirect)
* 中间键值对会根据键进行排序(在某些实现中排序发生在Shuffle阶段)和分组,然后发送到Reduce节点。
* 在Reduce节点上,具有相同键的所有值都会聚集在一起,这时就可以执行联接操作。
`MapReduce Join`不直接应用于传统数据库逻辑,而是适用于Hadoop这样的分布式处理系统中。但是为了方便理解,还是用SQL语言来分析,例如一条SQL:
```
SELECT orders.order_id, orders.date, customers.name
FROM orders
JOIN customers ON orders.customer_id = customers.customer_id;
```
会被转换为两个SQL:
```
SELECT customer_id, order_id, date FROM orders;
SELECT customer_id, name FROM customers;
```
这个过程就是Map阶段,即读取orders和customers表的数据,并为每条记录输出键值对,键是`customer_id`,值是记录的其余部分。
下一个阶段可有可无,即Shuffle阶段。如果不在这里排序可能会在Map阶段执行SQL时候排序/分组或者在接下来的Reduce阶段进行额外排序/分组。在这个阶段主要将收集到的数据按照`customer_id`排序分组,以确保相同的`customer_id`的数据达到Reduce阶段。
Reduce阶段将每个对应的`customer_id`进行联接操作,输出并返回最后的结果。
这种操作普遍应用于两个算法完全不相同的表单,也是一种标准的处理模型,在这个过程中,我们以一张逻辑表的维度进行操作。这种算法可能会消耗大量内存,甚至导致内存溢出,并且在处理大数据量时会相当耗时,因此不适合需要低延迟的场景。
##### [额外补充](https://mp.weixin.qq.com/s?__biz=MzUzMTA2NTU2Ng==&mid=2247487551&idx=1&sn=18f64ba49f3f0f9d8be9d1fdef8857d9&scene=21#wechat_redirect)
内存溢出场景普遍在如下场景:
* **大键值对数量:** 如果Map阶段产生了大量的键值对,这些数据需要在内存中进行缓存以进行排序和传输,这可能会消耗大量内存。
* **数据倾斜:** 如果某个键非常常见,而其他键则不那么常见,那么处理这个键的Reducer可能会接收到大量的数据,导致内存不足。这种现象称为数据倾斜。
* **大值列表:** 在Reduce阶段,如果某个键对应的值列表非常长,处理这些值可能会需要很多内存。
* **不合理的并行度:** 如果Reduce任务的数量设置得不合适(太少或太多),可能会导致单个任务处理不均匀,从而导致内存问题。
我能想到的相应解决方案:
* 内存到磁盘的溢写:当Map任务的输出缓冲区满了,它会将数据溢写到磁盘。这有助于限制内存使用,但会增加I/O开销。
* 通过设置合适的Map和Reduce任务数量,可以更有效地分配资源,避免某些任务过载。具体操作可以将Map操作的分段比如1\~100,100~200,Reduce阶段开设较少的并发处理。
* 优化数据分布,比如使用范围分区(`range partitioning`)或哈希分区(`hash partitioning`)来减少数据倾斜。
### [Sort-Merge Join(排序-合并联接)](https://mp.weixin.qq.com/s?__biz=MzUzMTA2NTU2Ng==&mid=2247487551&idx=1&sn=18f64ba49f3f0f9d8be9d1fdef8857d9&scene=21#wechat_redirect)
先上原理解释:
> "
>
> 在分布式环境中,`Sort-Merge Join`首先在每个节点上对数据进行局部排序,然后将排序后的数据合并起来,最后在合并的数据上执行联接操作。
>
> "
>
> 这通常涉及到多阶段处理,包括局部排序、数据洗牌(重新分发),以及最终的排序和合并。
举个理解,还是上面的SQL。
```
SELECT orders.order_id, orders.date, customers.name
FROM orders
JOIN customers ON orders.customer_id = customers.customer_id;
```
* 对orders表按`customer_id`进行排序。
* 对customers表按`customer_id`进行排序。
* 同时遍历两个已排序的表,将具有相同`customer_id`的行配对。
这个就有点类似于原生的排序-合并联接了。也是数据库场景的标准处理办法。
对于已经排序的数据集或数据分布均匀的情况,这种方法非常有效。如果数据未预先排序,这种方法可能会非常慢,因为它要求数据在联接之前进行排序。
当然,这个算法也会造成内存溢出的场景,解决方案如下:
* 当数据集太大而无法一次性加载到内存中时,可以使用外部排序算法。外部排序算法会将数据分割成多个批次,每个批次单独排序,然后将排序后的批次合并。这种方法通常涉及到磁盘I/O操作,因此会比内存中操作慢。
* 对于合并步骤,可以使用流式处理技术,一次只处理数据的一小部分,并持续将结果输出到下一个处理步骤或存储系统。这样可以避免一次性加载大量数据到内存中。
* 当内存不足以处理数据时,可以使用磁盘空间作为临时存储。数据库管理系统通常有机制来处理内存溢出,比如创建磁盘上的临时文件来存储过程中的数据。
* 在分布式系统中,可以将数据分散到多个节点上进行处理,这样每个节点只需要处理数据的一部分,从而减少单个节点上的内存压力。
```
文章有帮助的话,在看,转发吧。谢谢支持哟 (\*\^__\^\*)
```
![]()
众生皆苦,唯有自渡!





