# (一)介绍 {#一-介绍}
ElasticSearch的目标就是实现搜索 。在数据量少的时候,我们可以通过索引去搜索关系型数据库中的数据,但是如果数据量很大,搜索的效率就会很低,这个时候我们就需要一种分布式的搜索引擎。Elasticsearch是一个基于Lucene的搜索服务器 。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。
ES主要用于全文检索、结构化搜索以及分析。ES的应用十分广泛,比如维基百科、Github等都使用ES实现搜索。
# (二)核心概念理解 {#二-核心概念理解}
# 2.1 数据结构 {#_2-1-数据结构}
ES既然是用来搜索的,那么它必然也需要存储数据。在Mysql等关系型数据库中,数据的存储遵循下面的逻辑:
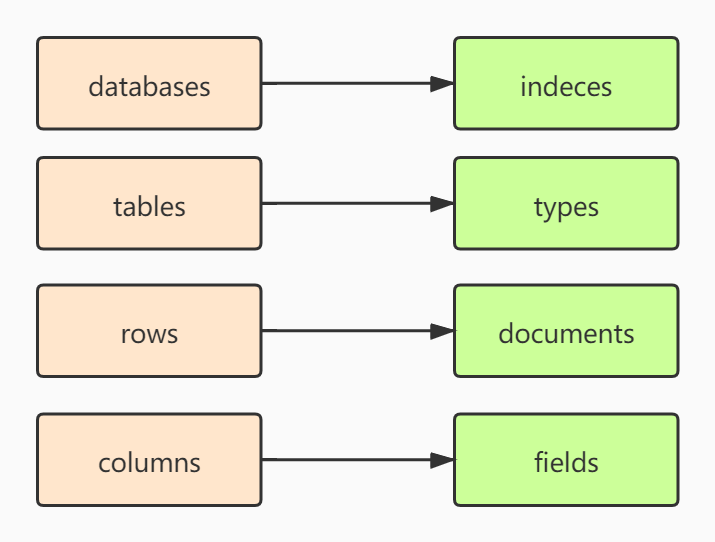
一个数据库(database)中有多个表(tables),每个表有多行数据(rows),每一行数据由多个字段(columns)组成。
ES中的存储是这样的:
一个索引(indeces)相当于一个数据库(database),每个索引中有多个类型types(相当于表结构),每个索引中有多个documents(相当于行),每个documents由多个fields组成(相当于字段)。
你可以把ES理解为他是一个面向文档的数据库。下面用一张图描述ES和关系型数据库之间的相似之处:
值得注意的是,在ES7.x版本中,types将慢慢被遗弃,在8.x版本中,types将会彻底弃用。
# 2.2 索引(indeces)和文档(documents) {#_2-2-索引-indeces-和文档-documents}
ES中的索引和Mysql中的索引不是同一种东西,ES中的索引是一个文档的集合,索引就是一个数据库。
前面说了ES是面向文档的,文档是ES中最重要的单位,文档就是一条条的数据。文档中有几个重要的概念:
1、一篇文档中包含多个key:value
2、文档其实就是一个JSON字符串
# 2.3 分片 {#_2-3-分片}
我们通过EShead创建一个索引时,他会让我们选择分片数量和副本数量
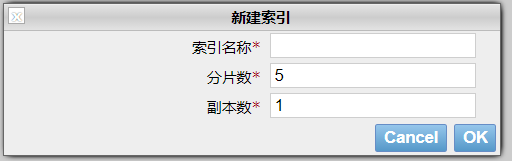
ES是一个分布式搜索引擎,分片就是把一堆数据分布到多个分片中。而索引是对每个分片的一个备份,这些副本同样能处理查询请求。
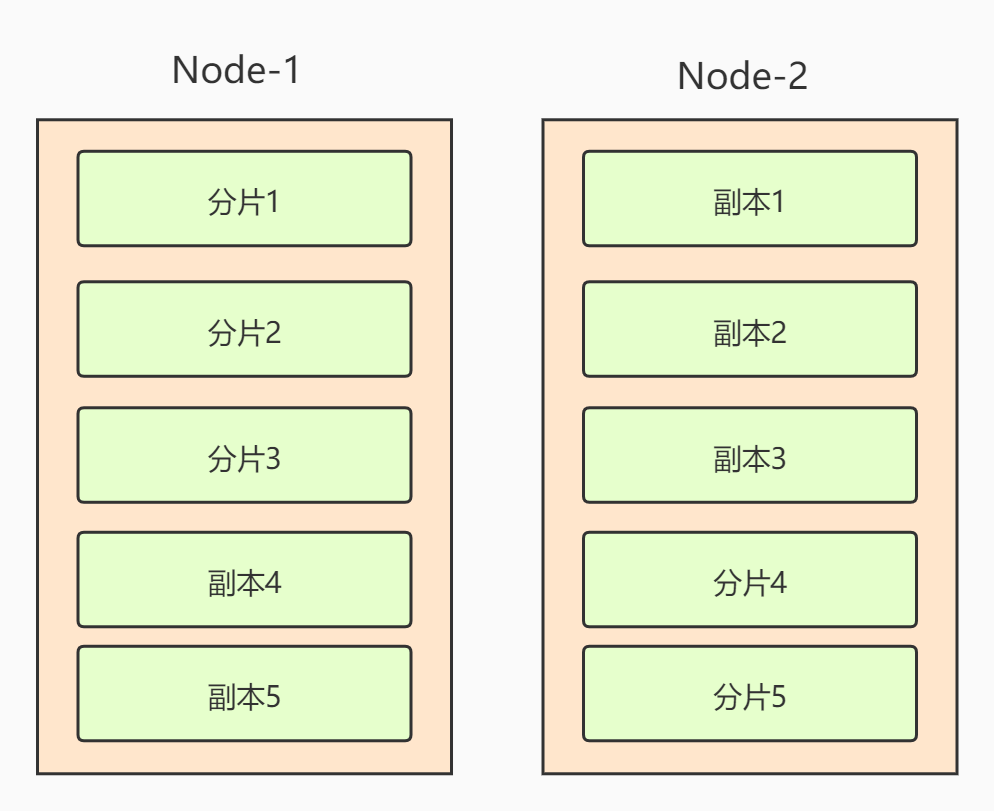
现在假设集群有两个node节点,设置分片数是5个,副本数是1个,那么数据存储结构将变成下面这样,可以保证副本和分片在不同的节点上:
# 2.4 倒排索引 {#_2-4-倒排索引}
为什么ES的搜索这么快,和其中所使用的倒排索引也有一定的关系。倒排索引建立的是分词和文档之间的映射关系。下面通过一个简单的例子来讲解一下什么是倒排索引
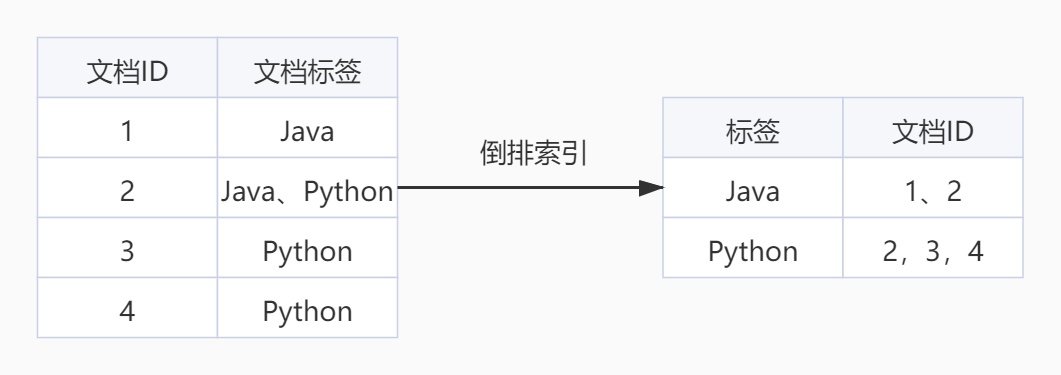
原来的数据中我们通过文档ID去关联标签,但是在查询时就需要遍历所有文档。通过倒排索引,我们可以通过关键词来找到最匹配的文档。
# (三)ES的基本操作 {#三-es的基本操作}
ES是基于Restful风格进行操作的,因此对于习惯了写crud的程序员来说,ES很容易上手。ES的操作可以使用Kibana,也可以使用Postman直接调用,因为归根结底它就是一个restful的操作。我这里使用Idea的ES插件直接调用。 3.1 创建文档
PUT http://ip:port/索引名/类型名/文档id
{
"key":"value"
}
1
2
3
4
5
因为类型名在后续的版本中将会被删除,这里可以用_doc代表默认类型:
PUT http://ip:port/索引名/_doc/文档id
1
下面给出操作截图
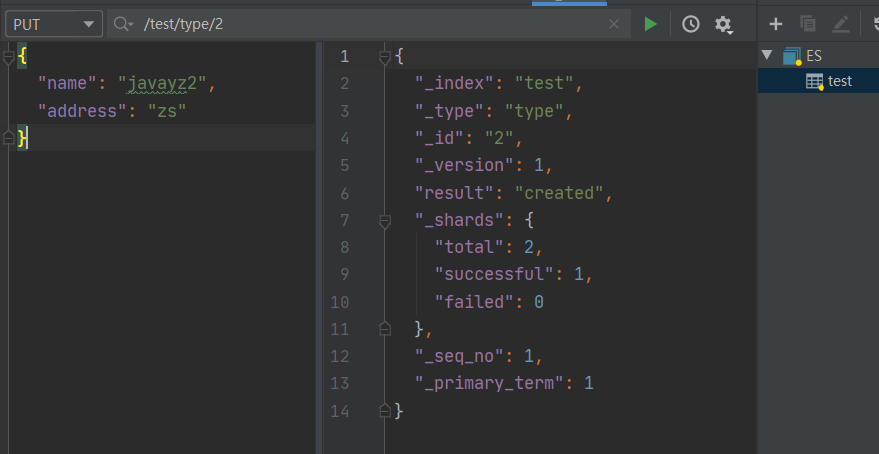
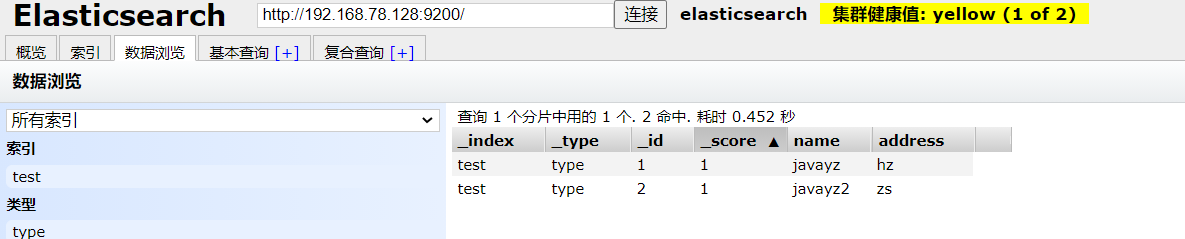
通过put创建一个索引之后,我们可以在head中看到对应的数据
# 3.2 创建带有数据类型的索引 {#_3-2-创建带有数据类型的索引}
3.1中创建数据时,没有指定具体的数据类型,我们当然也可以为索引指定数据类型
PUT http://ip:port/索引名
参数示例:
{
"mappings": {
"properties": {
"name": {
"type": "text"
},
"address": {
"type": "text"
}
}
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
ES中的核心数据类型如下:
(1)字符串类型: text, keyword
(2)数字类型:long, integer, short, byte, double, float, half_float, scaled_float
(3)日期:date
(4)日期 纳秒:date_nanos
(5)布尔型:boolean
(6)Binary:binary
(7)Range: integer_range, float_range, long_range, double_range, date_range
1
2
3
4
5
6
7
# 3.3 查看索引或者文档的数据 {#_3-3-查看索引或者文档的数据}
通过GET请求可以查看索引以及文档的信息:
GET http://ip:port/索引名 #查看索引
GET http://ip:port/索引名/类型名/文档ID #查看文档
1
2
# 3.4 修改数据 {#_3-4-修改数据}
修改数据和创建数据一样,通过PUT操作就会更新原来的数据:
PUT http://ip:port/索引名/类型名/文档id
{
"key":"value"
}
1
2
3
4
如果是修改的话,响应结果中的version就会增加。
另外一种方法是使用Post请求:
POST http://ip:port/索引名/类型名/文档id/_update
参数实例:
{
"doc": {
"name": "javayz4"
}
}
1
2
3
4
5
6
7
更推荐使用这种方式,如果使用PUT方法忘了加某个key,更新就会变成新增
# 3.5 删除数据 {#_3-5-删除数据}
通过DELETE的方式删除数据
DELETE http://ip:port/索引名/类型名/文档id #删除具体的文档
DELETE http://ip:port/索引名 #删除索引
1
2
# (四)ES的搜索操作 {#四-es的搜索操作}
ES最重要的就是它的搜索操作了。
# 4.1 简单搜索 {#_4-1-简单搜索}
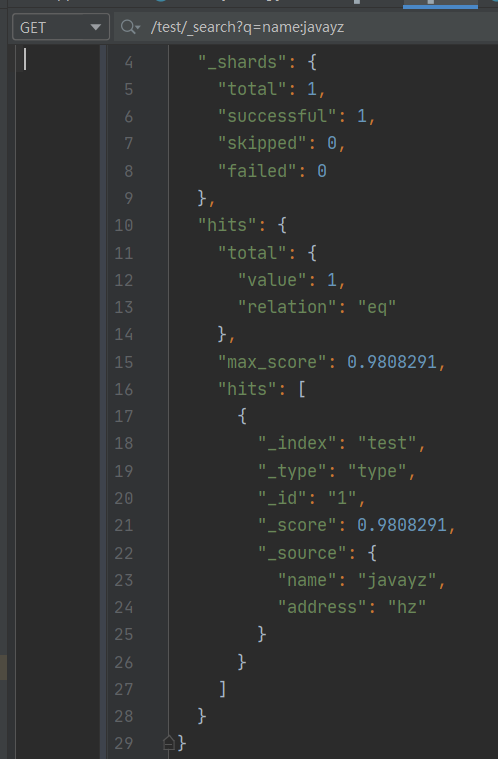
直接将搜索的参数带到链接中:
GET http://ip:port/索引名/_search?q=key:value
1
结果如下:
# 4.2 通过param传递参数 {#_4-2-通过param传递参数}
除了将参数放到链接当中,还可以将参数通过JSON请求体的方式传递,其中from和size是分页的参数 ,query中传递查询条件 ,_source表示结果中要展示的列,不写就表示展示所有。
GET http://ip:port/索引名/_search
参数示例:
{
"from": 0,
"size": 20,
"query": {
"match": {
"name": "javayz2"
}
},
"_source": ["name","address"]
}
1
2
3
4
5
6
7
8
9
10
11
12
除了上面示例中的这些参数之外,还有很多参数可以使用,比如排序:
"sort": [
{
"age": {
"order": "desc"
}
}
]
1
2
3
4
5
6
7
多条件查询 :must表示下面的两个条件都要满足,还可以填should ,表示任意满足其中一个条件即可,或者是must_not ,表示must的相反值
"query": {
"bool": {
"must": [
{
"match": {
"name": "javayz"
}
},
{
"match": {
"address": "hz"
}
}
]
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
如果你的数据中存在集合,可以通过空格对多个条件进行查询:
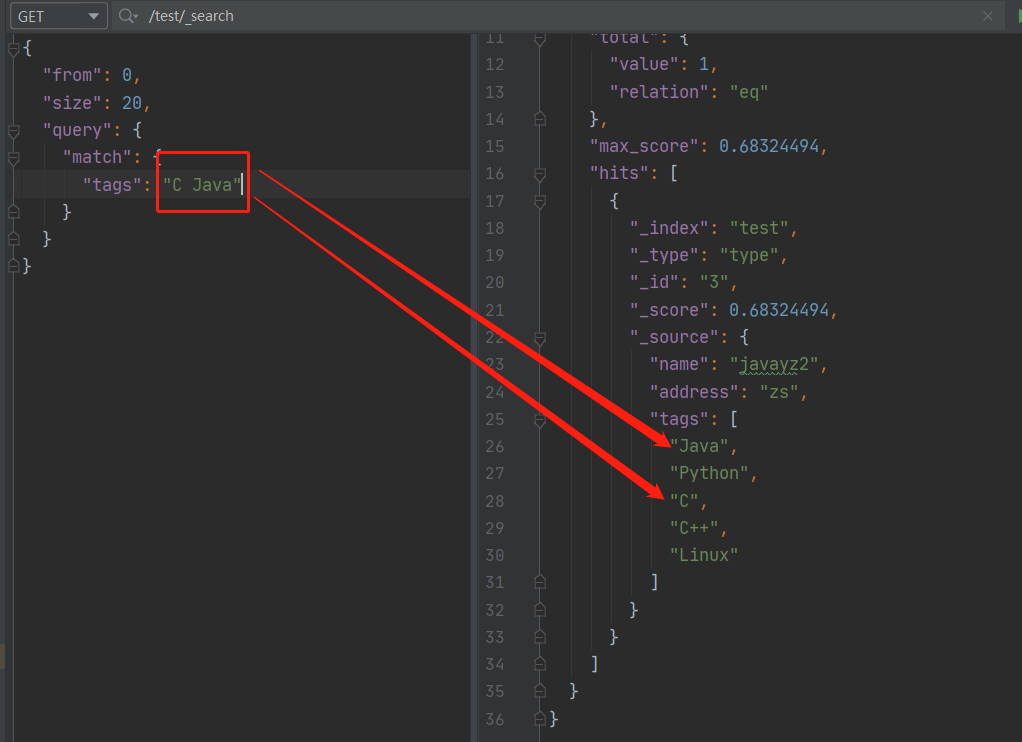
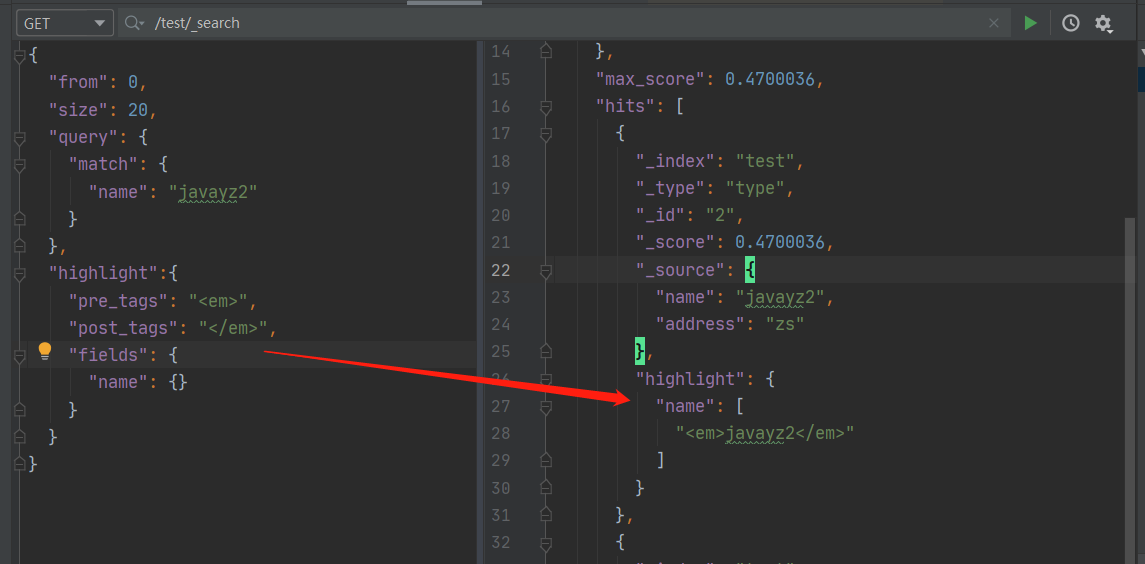
查询过程中还支持高亮查询
"highlight":{
"pre_tags": "<em>",
"post_tags": "</em>",
"fields": {
"name": {}
}
}
1
2
3
4
5
6
7
# (五)分词器 {#五-分词器}
所谓分词器,就是将一段话分成一个个关键字,搜索时就按照这些关键字进行搜索。比较好用的分词器有中文的IK分词器。
# 5.1 基本使用 {#_5-1-基本使用}
给出下载链接:https://github.com/medcl/elasticsearch-analysis-ik/releases
下载和自己ES相同的版本,在plugin目录下新建一个ik文件夹,将下载的文件解压到ik目录下,重新启动即可。
IK分词器提供了两种算法:
1、ik_smart:最少切分
2、ik_max_word:最细粒划分
首先最少切分是根据字典给出最少的切分:
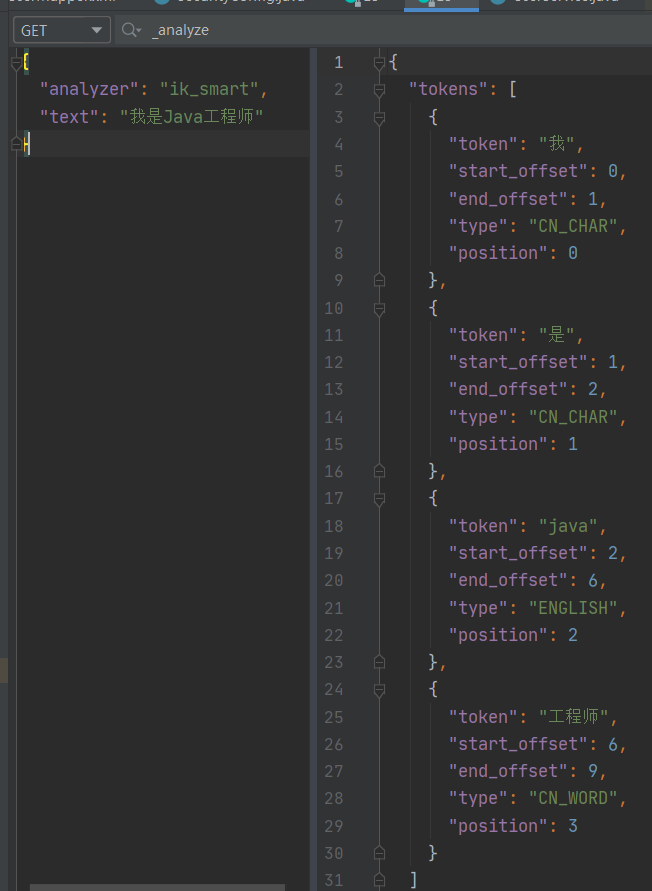
ik_max_word是最细粒划分,他会给出最多的结果:
{
"analyzer": "ik_max_word",
"text": "我是Java工程师"
}
1
2
3
4
结果:
{
"tokens": [
{
"token": "我",
"start_offset": 0,
"end_offset": 1,
"type": "CN_CHAR",
"position": 0
},
{
"token": "是",
"start_offset": 1,
"end_offset": 2,
"type": "CN_CHAR",
"position": 1
},
{
"token": "java",
"start_offset": 2,
"end_offset": 6,
"type": "ENGLISH",
"position": 2
},
{
"token": "工程师",
"start_offset": 6,
"end_offset": 9,
"type": "CN_WORD",
"position": 3
},
{
"token": "工程",
"start_offset": 6,
"end_offset": 8,
"type": "CN_WORD",
"position": 4
},
{
"token": "师",
"start_offset": 8,
"end_offset": 9,
"type": "CN_CHAR",
"position": 5
}
]
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
# 5.2 字典 {#_5-2-字典}
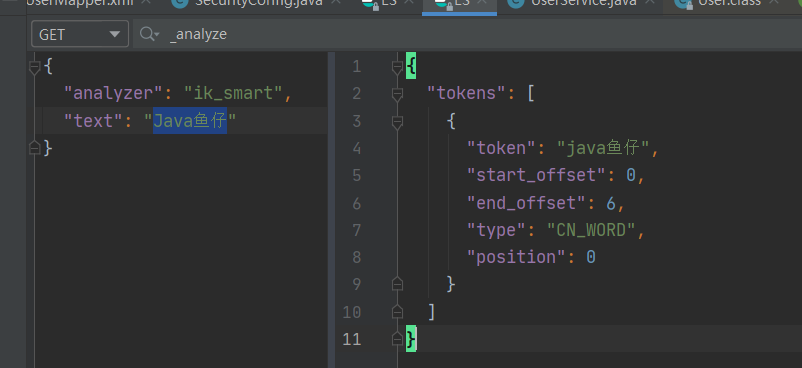
对于一些名词,IK自带的字典无法区分,比如我的博客名Java鱼仔,它分词后是这样的:
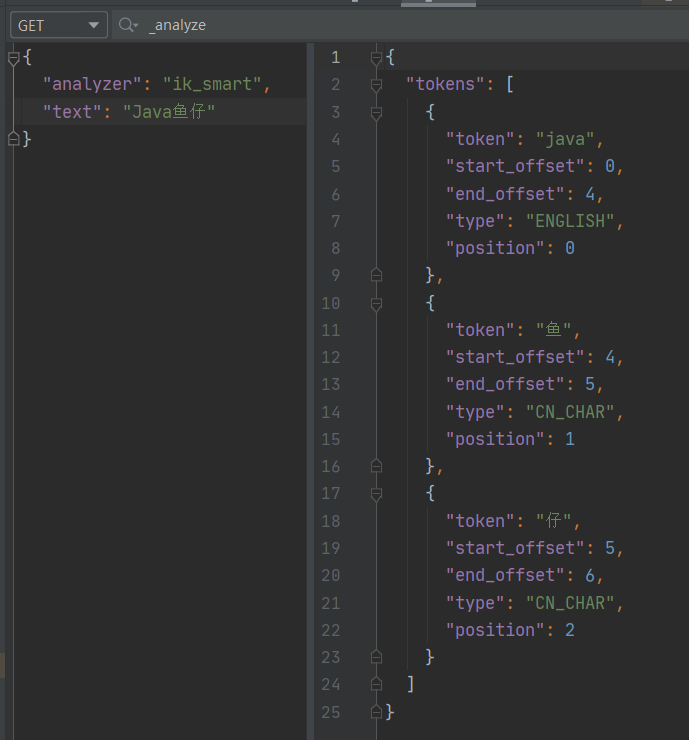
因此我们需要手动去增加这样的字典,IK目录下的config/IKAnalyzer.cfg.xml中可以添加自己的字典,首先我在config下新建一个my.dic文件,里面的词汇现在只写了一个Java鱼仔。然后在配置文件中配置自己的my.dic
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">my.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
1
2
3
4
5
6
7
8
9
10
11
12
13
重启后再次进行分词,结果如下:
如果字典无法被识别,可能是格式等问题。
# (六)总结 {#六-总结}
这篇文章主要对ES的概念以及基本的操作进行讲解,项目中使用时我们会将ES集成到Springboot中。本期的分享就到这了,我是鱼仔,我们下期再见!