在正式介绍Mysql调优之前,先补充mysql的两种引擎
mysql逻辑分层
InnoDB:事务优先(适合高并发操作,行锁)
MyISAM:性能优先(表锁)
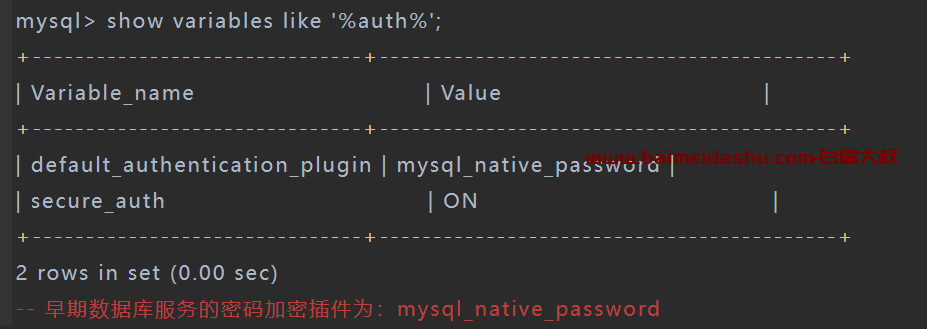
查看使用的引擎:
show variables like "%storage_engine%";
1
使用哪个引擎在创建表时通过Engine=InnoDB创建
# 一、为什么要对sql进行优化: {#一、为什么要对sql进行优化}
有时候数据库会出现性能低、执行时间太长、等待时间太长、SQL语句欠佳(连接查询)、索引失效等问题,这些问题会严重拖慢一个系统的速度,因此需要对sql进行优化。
SQL的编写过程和解析过程并非是一致的,下面是两者执行的先后顺序:
编写过程:
select..from..join..on..where..group by...having..order by...limit.
1
解析过程:
from..on..join..where..group by....having...select..order by...limit..
1
# 二、SQL如何优化: {#二、sql如何优化}
SQL优化,主要就是在优化索引
索引:相当于书的目录,是帮助MYSQL高效获取数据的数据结构。就好比我们查字典,如果没有目录查一个字就需要遍历整本字典,而有了目录之后只需要按目录查询。索引的数据结构有(树:B+树(默认)、Hash树等等)
B+树是一种数据结构,所有的元素全部放在叶子节点,因此B+树查询数据都需要n次,n与树的高度相同
# 2.1、索引的弊端: {#_2-1、索引的弊端}
- 索引本身很大,需要存放在内存/硬盘(通常为硬盘)
- 索引不是所有情况均适用,以下三种情况不适合用索引:
- 少量数据
- 频繁更新的字段
- 很少使用的字段
- 索引提高了查询速度,但是会降低增删改的效率
# 2.2 索引的优势: {#_2-2-索引的优势}
- 提高查询效率(降低IO使用率)
- 降低CPU使用率
# 2.3 关于索引的分类: {#_2-3-关于索引的分类}
单值索引:单列的索引,比如学生表中的grade。一个表可以有多个单值索引
唯一索引:与单值索引的区别是属性不能重复。比如主键id
主键索引:与唯一索引的区别是内容不能为null
复合索引:多个列构成的索引,(name,grade)构成索引后先查name,再查grade
# 2.4 如何创建索引: {#_2-4-如何创建索引}
方法一:
create 索引类型 索引名 on 表(字段)
1
单值索引:
create index name_index on student(name);
1
唯一索引:
create unique index id_index on student(id);
1
复合索引:
create index name_grade_index on student(name,grade);
1
方法二:
alter table 表名 add 索引类型 索引名(字段);
1
单值索引:
alter table student add index name_index(name);
1
唯一索引:
alter table student add unique index id_index(id);
1
复合索引:
alter table student add index name_grade_index(name,grade);
1
删除索引:
drop index 索引名 on 表名
1
# 2.5 explain关键字 {#_2-5-explain关键字}
通过explain关键字可以看到sql语句的执行过程,其中type、key、key_len、Extra需要尤其注重

# id {#id}
标识符
如果有多个id,id值相同,顺序执行;id值不同,id值越大越优先查询
- select_type:查询类型
- primary:包含子查询SQL中的主查询(最外层)
- subquery:包含子查询SQL中的子查询(非最外层)
- simple:简单查询(不包含子查询、union)
- derived:衍生查询(使用到了临时表)
- union:当查询时用到了table1 union table2,table1类型是derived,table2的类型是union
- union result:哪些表存在union查询
# table: {#table}
查询的是哪张表
# type: {#type}
索引类型
system>const>eq_ref>ref>range>index>all
system>const存在于理想状态,实际能达到ref,索引的优化一般到ref为止
- const:仅仅能查到一条数据的SQL,用于主键索引和唯一索引
- eq_ref:唯一性索引:对于每个索引键的查询,返回匹配唯一行数据(有且只有1个,不能多、不能0)
- ref:非唯一性索引,对于每个索引键的查询,返回匹配的所有行
- range:检索指定范围的行,where后面是一个范围查询(between,>,<)等。
- index:查询全部索引中的数据
- all:查询全部表中的数据
- possible_keys 可能用到的索引
# key {#key}
实际用到的索引
# key_len {#key-len}
索引的长度,用于判断复合索引是否被完全使用
# ref {#ref}
指明当前表所参照的字段
# rows {#rows}
被索引优化查询的数据个数(实际通过索引查询到的数据个数)
# Extra {#extra}
- using filesort:性能消耗大;需要"额外"的一次排序,常见于orderby语句
- using temporary:性能损耗大,用到了临时表,一般出现在groupby中
- using index:性能提升;索引覆盖(覆盖索引)。原因:不读取原文件,只从索引文件中获取数据
- using where:回表查询;
# 三、索引优化实例: {#三、索引优化实例}
建一张book表,插入一些数据
create table book
(
bid int(4) primary key,
name varchar(20) not null,
authorid int(4) not null,
typeid int(4) not null
);
insert into book values(1,'java',1,1);
insert into book values(2,'c',2,2);
insert into book values(3,'math',3,3);
insert into book values(4,'english',4,3);
1
2
3
4
5
6
7
8
9
10
11
首先不建立索引查看查询情况:
explain select bid from book where typeid in(2,3) and authorid=2 order by bid;
1

虽然我没建立索引,但是mysql5.7自动建立了主键索引,现在的type是index,继续优化:
添加一个复合索引,将查询时所用到的属性均加入进去
alter table book add index a_t_b(authorid,typeid,bid);
1

此时的type已经到了ref,达到了最好的优化效果,在额外信息中依旧存在using where,因为当使用in时,部分索引可能会失效,所以一部分数据从索引中查询,一部分数据回表查询。
# 四、加索引的技巧: {#四、加索引的技巧}
1、小表驱动大表:
select ... from .... where 小表.x=大表.x;
1
2、索引建立在经常使用的字段上
3、exist和in:
如果主查询的数据集大,则使用in,如果子查询的数据集大,则使用exist
select .. from table where exist/in (子查询)
1
4、order by优化:
- 避免select *的使用
- 复合索引不要跨列使用
- 保证所有排序字段排序顺序的一致性(都是升序或降序)
5、最左前缀原则
索引要按照建立时的字段要和查询时的字段位置一致,比如一个索引(name,age,home),查询时就要写 where name=xxx and age=xxx and home=xxx
# 五、避免索引失效的原则 {#五、避免索引失效的原则}
- 复合索引不要跨列或无序使用(最佳左前缀):索引的顺序和sql语句查询时的顺序一致
- 复合索引尽量使用全索引匹配
- 不要在索引上进行任何操作(计算、函数、类型转换)
- like尽量以"常量"开头,不要以%开头,否则索引失效
- 尽量不要使用类型转换(显示、隐式),否则索引失效,如: name的属性是varchar,这里变成了int select * from teacher where name=123
- 尽量不要使用or,否则索引失效
- 尽量把条件字段(大于或小于)放到最后,遇到条件字段索引失效,比如 select * from user where name='javayz' and age>23 and home='zhejiang' 当执行到age>23时,索引就失效了。因此把age>23放到最后。
- 两个表或者字段编码格式不同导致索引失效,比如table1编码格式是utf8,table2编码格式是utf8mb4,两个表join时on字段就无法走索引。
# 六、慢查询日志的使用 {#六、慢查询日志的使用}
慢查询日志是mysql提供的一种日志记录,用于记录Mysql响应时间超过阈值的Sql语句(long_query_time,默认10秒)。
慢查询日志默认是关闭的,建议开发时开启,部署时关闭
查看慢查询日志
show variables like '%slow_query_log%';
1

临时开启慢查询日志
set global slow_query_log=1;
1
永久开启:在mysql的配置文件里增加下面两句话:
slow_query_log=1
slow_query_log_file=XXX/slow.log
1
2
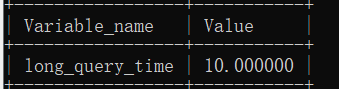
查看慢查询时间阈值:
show variables like '%long_query_time%';
1
更改慢查询时间阈值
临时:
set global long_query_time=5;
永久,在配置文件中添加:
long_query_time=5
1
2
3
4