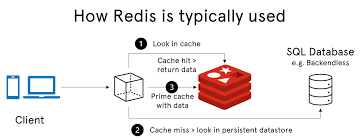
一句话总结:
Animate-anyone & Dreamoving 之外,更通用的"物体"+"动作"定制化的视频生成方案,同样开源。
github:https://github.com/damo-vilab/i2vgen-xl
核心模块:
DreamVideo的核心部分详细介绍了视频生成的两个关键阶段:主体学习 和 运动学习。以下是这两个阶段的详细内容。
主体学习:
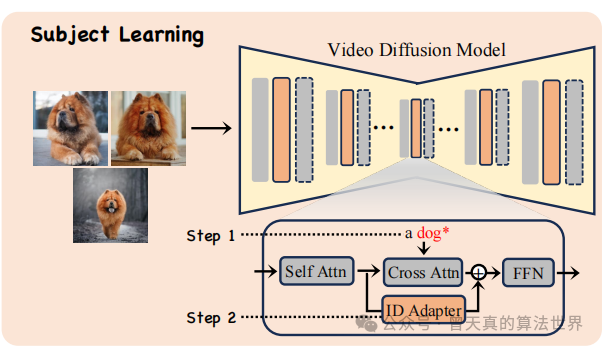
主体学习的目标是从提供的静态图片中准确地捕捉主体的外观。这个过程分为两个步骤:
-
文本Embedding优化:首先,使用 Textual Inversion 技术来学习一个文本表达,这个关键词代表了一个粗略的概念。这个过程涉及到冻结视频扩散模型,只优化关键词"S*"的文本Embedding。
-
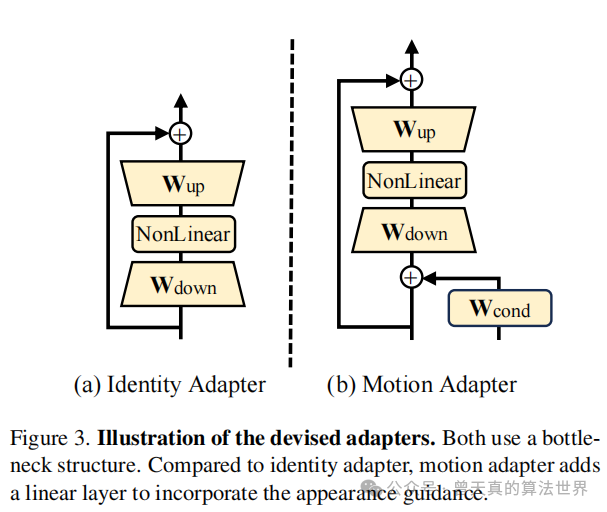
ID-Adapter训练:在文本embedding确定后,训练一个轻量级的微调模型(ID Adapter),以进一步细化主体的外观细节。这个适配器采用瓶颈结构,包括一个下投影线性层、一个非线性激活函数和一个上投影线性层。训练过程中,文本Embedding被冻结,只优化适配器的参数。为了保持预训练模型的能力,投影线性层的权重初始化为零。
运动学习(Motion Learning):
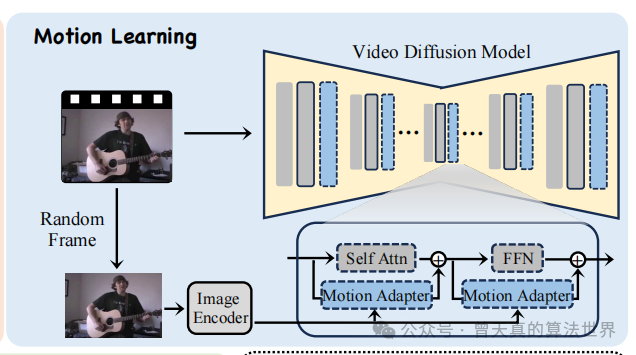
运动学习的目标是从给定的视频(或多个视频)中学习目标运动模式。这个过程同样涉及设计和训练一个运动适配器(Motion Adapter),其结构类似于ID-Adapter,但增加了一个线性层来整合外观引导。
-
外观引导:为了避免在训练过程中学习到主体的外观,运动适配器在时间隐藏状态中加入了一个条件线性层,用于整合外观信息。这个信息来自于通过CLIP图像编码器处理的随机选取的训练视频中的一帧图像。
-
训练过程:在训练过程中,运动适配器通过这个外观引导来学习纯粹的运动模式。在推理阶段,用户可以随机选择训练期间提供的一张图片作为外观条件输入到运动适配器中,以生成定制视频。
模型分析、训练及优化:
为了确定在微调过程中哪些参数对学习主体和运动最为关键,研究者分析了所有参数的变化。他们将参数分为四类:
-
交叉注意力(Cross-Attention):这些参数仅存在于空间参数中,对于学习主体的外观特征至关重要。
-
自注意力(Self-Attention):这些参数在模型中处理序列数据时起到核心作用。
-
前馈网络(Feed-Forward Network, FFN):这些是模型中的全连接层,用于处理和转换特征。
-
其他剩余参数:包括除上述三类之外的所有其他参数。
研究者使用权重变化率(∆l)来衡量每一层参数的变化程度,计算公式为:
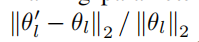
通过这种方式,研究者能够识别出在主体学习和运动学习中哪些层的贡献最大。
解耦训练策略
为了同时在图像和视频上定制主体和运动,研究者提出了一种解耦训练策略。这种策略允许独立优化身份和运动适配器,而不是同时对它们进行训练。这样做的好处是可以减少训练时间,提高模型的灵活性和实用性。
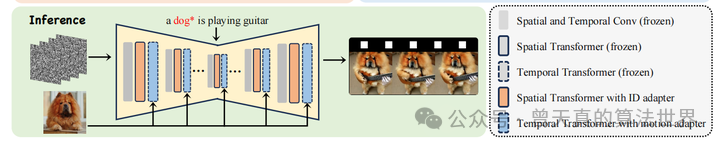
推理过程:
在推理阶段,研究者将训练好的主体适配器和运动适配器结合起来,生成定制视频。用户可以随机选择训练期间提供的一张图片作为外观条件输入到运动适配器中。这个过程不需要额外的训练,直接利用训练好的适配器生成视频。
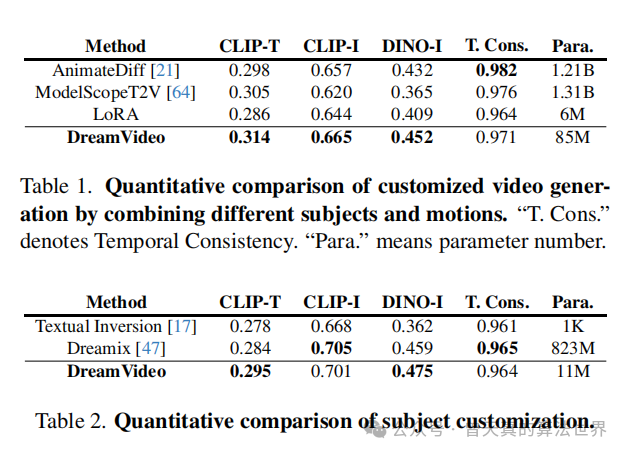
实验结果:
和目前主流的视频生成方案的对比:
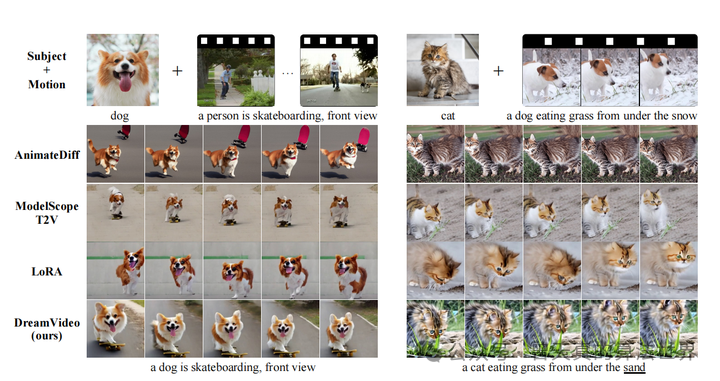
主体相关性效果对比:

运动一致性的对比:

量化指标的对比:
【-END-】
一起讨论: 对AIGC相关应用,算法前沿以及创业/工作感兴趣的同学,可以加微信:Zeng_AIGC,备注:***研究方向+学校/公司 + 公众号***即可 拉入交流群。欢迎大家与创业团队,大厂leader以及顶尖名校的算法研究同学共同交流。
AIGC课程: 为想转行到AIGC方向 工作的 在读/在职同学,提供从理论到实践完整辅导课程。在本公众号菜单栏下点击***"算法指导"*** ,欢迎咨询。目前已有43名同学成功上岸AIGC算法。
答疑解惑: 对工作,发展中遇到的任何问题欢迎咨询,同样添加Zeng_AIGC:备注,提升咨询 即可
对于AIGC,扩散模型相关应用,算法,实践感兴趣的欢迎关注。