先立Flag:从今天开始(20240806),我会坚持每天日更,和大家一起学习AI大模型,也请各位一起监督!
先立Flag:从今天开始(20240806),我会坚持每天日更,和大家一起学习AI大模型,也请各位一起监督!
? 本篇会带给你
-
了解大模型能做什么
-
整体了解大模型应用开发技术栈
一、前言
在剧烈变革的时代,千万别只拿代码当干货!作为咱们新时代的IT人员,学会**拥抱AI、使用AI、学习AI、懂AI。**永远不会错。
目前,行业共识是:两个确定一个不确定
-
确定未来 - AI 必然重构世界
-
确定进入 - 想收获红利,必须现在进入
-
不确定落 地 - 解决什么需求,技术路线、产品策略都是什么,确定性还很低
等「不确定」确定了,代码的价值才是大的。
二、什么是 AI?
「深蓝」的创造者许峰雄博士说过:「AI is bullshit。深蓝没用任何 AI 算法,就是硬件穷举起步。」

思考: 你觉得哪些应用算是 AI?
一种观点:基于机器学习、神经网络的是 AI,基于规则、搜索的不是 AI。
三、大模型能干什么?
大模型,全称「大语言模型」,英文「Large Language Model」,缩写「LLM」。
现在,已经不需要再演示了。每人应该都至少和下面一个基于大模型的对话产品,对话过至少 100 次。
| 国家 | 对话产品 | 大模型 | 链接 | |----|-------------------|---------------|--------------------------------| | 美国 | OpenAI ChatGPT | GPT-3.5、GPT-4 | https://chat.openai.com/ | | 美国 | Microsoft Copilot | GPT-4 和未知 | https://copilot.microsoft.com/ | | 美国 | Google Bard | Gemini | https://bard.google.com/ | | 中国 | 百度文心一言 | 文心 4.0 | https://yiyan.baidu.com/ | | 中国 | 讯飞星火 | 星火 3.5 | https://xinghuo.xfyun.cn/ | | 中国 | 智谱清言 | GLM-4 | https://chatglm.cn/ | | 中国 | 月之暗面 Kimi Chat | Moonshot | https://kimi.moonshot.cn/ | | 中国 | MiniMax 星野 | abab6 | https://www.xingyeai.com/ |
注意:分清对话产品 和大模型。

但是,千万别以为大模型只是聊天机器人。它的能量,远不止于此。
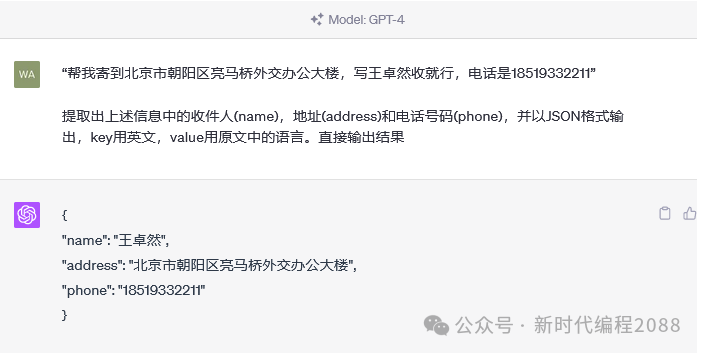
3.1、按格式输出
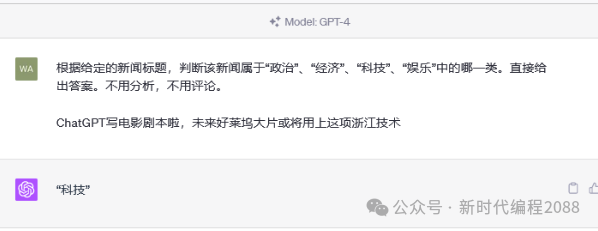
3.2、分类
3.3、聚类
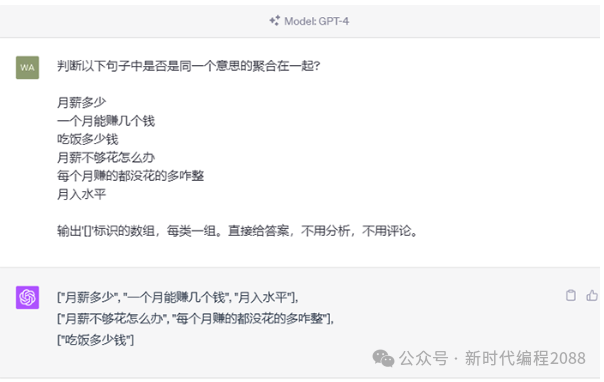
3.4、持续互动
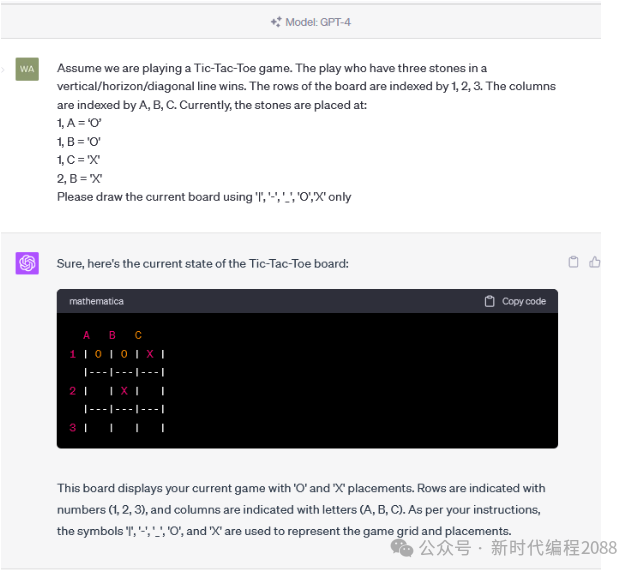

3.5、技术相关问题
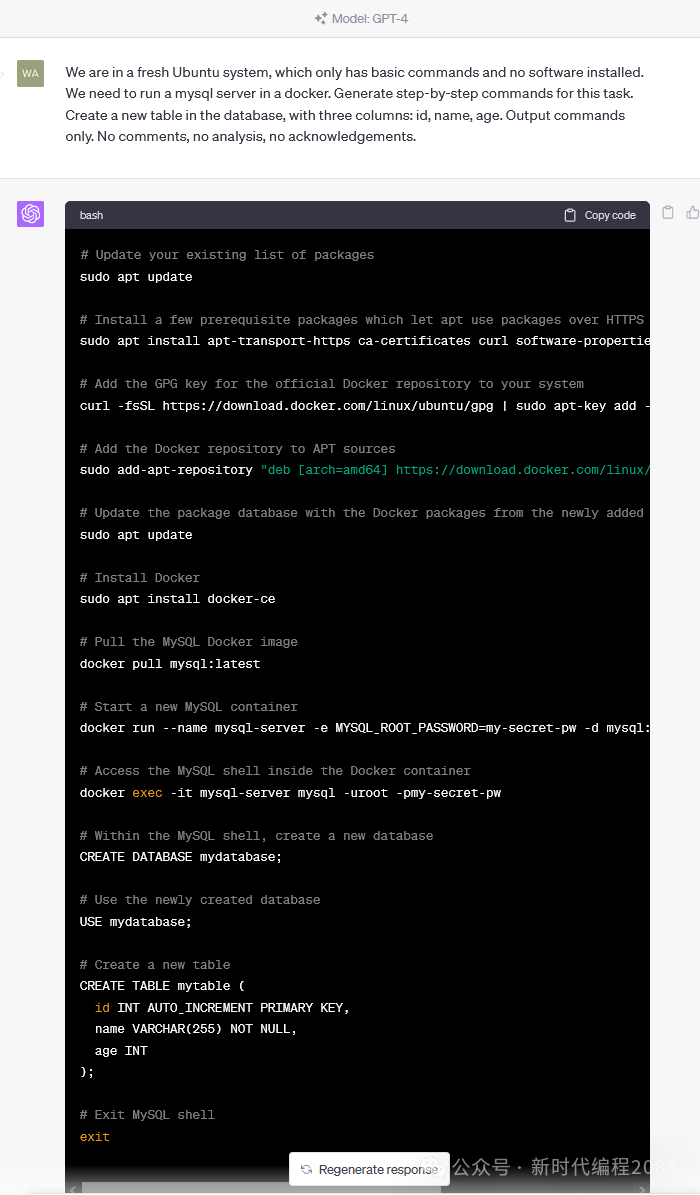
3.6、更多举例
-
**舆情分析:**从公司产品的评论中,分析哪些功能/元素是用户讨论最多的,评价是正向还是负向
-
**坐席质检:**检查客服/销售人员与用户的对话记录,判断是否有争吵、辱骂、不当言论,话术是否符合标准
-
**知识库:**让大模型基于私有知识回答问题
-
**零代码开发/运维:**自动规划任务,生成指令,自动执行
-
**AI 编程:**用 AI 编写代码,提升开发效率
3.7、可能一切问题,都能解决,所以是 AGI(Artificial General Intelligence)
划重点:
-
把大模型看做是一个函数,给输入,生成输出
-
任何问题,都可以用语言描述,成为大模型的输入,就能生成问题的结果
这当然还是美好的理想,但正在无限逼近。我们很幸运,能亲历这个过程。
当下,如何发挥大模型的现有能力呢?最大障碍是没有形成认知对齐。
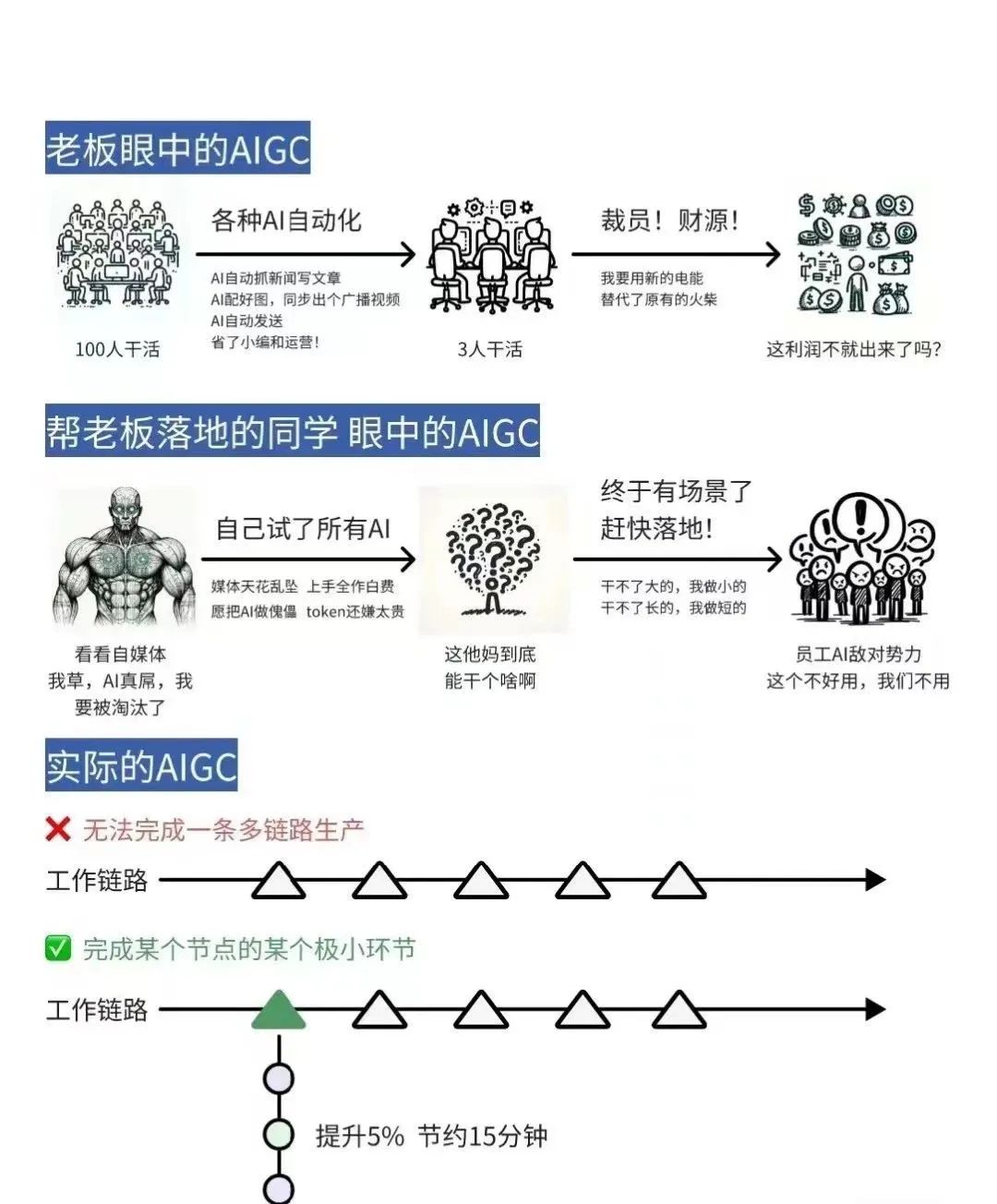
找落地场景的思路:
-
从最熟悉的领域入手
-
让 AI 学最厉害员工的能力,再让 ta 辅助其他员工,实现降本增效
-
找「文本进、文本出」的场景
-
别求大而全。将任务拆解,先解决小任务、小场景(周鸿祎:「小切口,大纵深」)
四、大模型是怎么生成结果的?
4.1、通俗原理
其实,它只是根据上文,猜下一个词(的概率)......

OpenAI 的接口名就叫「completion」,也证明了其只会「生成」的本质。
下面用程序演示「生成下一个字」。你可以自己修改 prompt 试试。还可以使用相同的 prompt 运行多次。 * * * * * * * * * * * * * * * * * * * *
from openai import OpenAI
from dotenv import load_dotenv, find_dotenv_ = load_dotenv(find_dotenv())
client = OpenAI()
prompt = "今天我很" # 改我试试prompt = "下班了,今天我很"prompt = "放学了,今天我很"prompt = "AGI 实现了,今天我很"response = client.completions.create( model="gpt-3.5-turbo-instruct", prompt=prompt, max_tokens=512, stream=True)
for chunk in response: print(chunk.choices[0].text, end='')
4.2、略深一点的通俗原理
用不严密但通俗的语言描述大模型的工作原理:
-
大模型阅读了人类曾说过的所有的话。这就是「机器学习 」,这个过程叫「训练」
-
把一串 token 后面跟着的不同 token 的概率存入「神经网络 」。保存的数据就是「参数 」,也叫「权重」
-
当我们给它若干 token,大模型就能算出概率最高的下一个 token 是什么。这就是「生成 」,也叫「推理」
-
用生成的 token,再加上上文,就能继续生成下一个 token。以此类推,生成更多文字
Token 是什么?
-
可能是一个英文单词,也可能是半个,三分之一个
-
可能是一个中文词,或者一个汉字,也可能是半个汉字,甚至三分之一个汉字
-
大模型在开训前,需要先训练一个 tokenizer 模型。它能把所有的文本,切成 token
思考:
-
AI 做对的事,怎么用这个原理解释?
-
AI 的幻觉,一本正经地胡说八道,怎么用这个原理解释?
4.3、再深一点点
这套生成机制的内核叫「Transformer 架构」。但其实,transformer 已经不是最先进的了。
| 架构 | 设计者 | 特点 | 链接 | |-------------|-----------------------------|----------------------|----------------| | Transformer | Google | 最流行,几乎所有大模型都用它 | OpenAI 的代码 | | RWKV | PENG Bo | 可并行训练,推理性能极佳,适合在端侧使用 | 官网、RWKV 5 训练代码 | | Mamba | CMU & Princeton University | 性能更佳,尤其适合长文本生成 | GitHub |
五、用好 AI 的核心心法
OpenAI 首席科学家 Ilya Sutskever 说过:
数字神经网络和人脑的生物神经网络,在数学原理上是一样的。
所以,我们要:
把 AI 当人看。把 AI 当人看。把 AI 当人看。
凯文·凯利老师,他说了类似的观点:「和人怎么相处,就和 AI 怎么相处。」
-
用「当人看」来理解 AI
-
用「当人看」来控制 AI
-
用「当人看」来说服用户正确看待 AI 的不足
六、大模型应用架构
大模型技术分两个部分:
-
训练基础大模型:全世界只需要 1000 人做这个
-
建造大模型应用:所有技术人,甚至所有人,都需要掌握
大模型应用技术特点:门槛低,天花板高。
6.1、典型业务架构
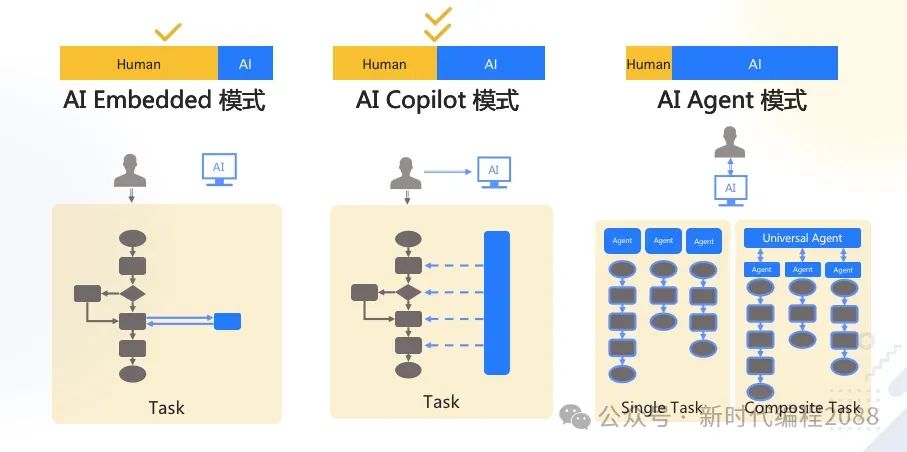
Agent 还太超前,Copilot 值得追求。
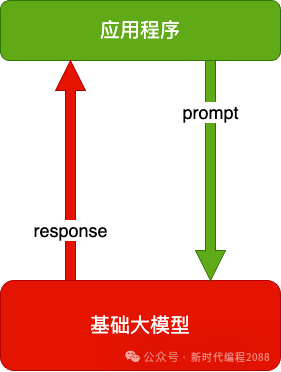
6.2、技术架构
纯 Prompt
就像和一个人对话,你说一句,ta 回一句,你再说一句,ta 再回一句......
Agent + Function Calling
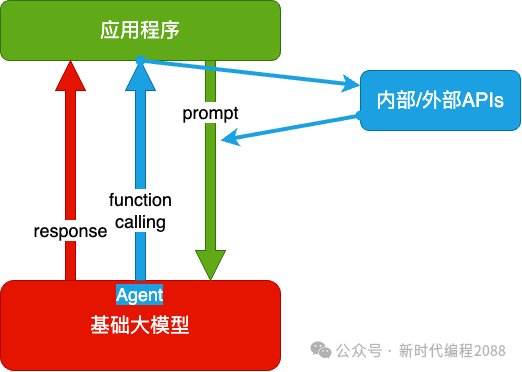
-
Agent:AI 主动提要求
-
Function Calling:AI 要求执行某个函数
-
场景举例:你问过年去哪玩,ta 先反问你有多少预算
RAG(Retrieval-Augmented Generation)
-
Embeddings:把文字转换为更易于相似度计算的编码。这种编码叫向量
-
向量数据库:把向量存起来,方便查找
-
向量搜索:根据输入向量,找到最相似的向量
-
场景举例:考试时,看到一道题,到书上找相关内容,再结合题目组成答案。然后,就都忘了
Fine-tuning
努力学习考试内容,长期记住,活学活用。

6.3、如何选择技术路线
面对一个需求,如何选择技术方案?下面是个不严谨但常用思路。
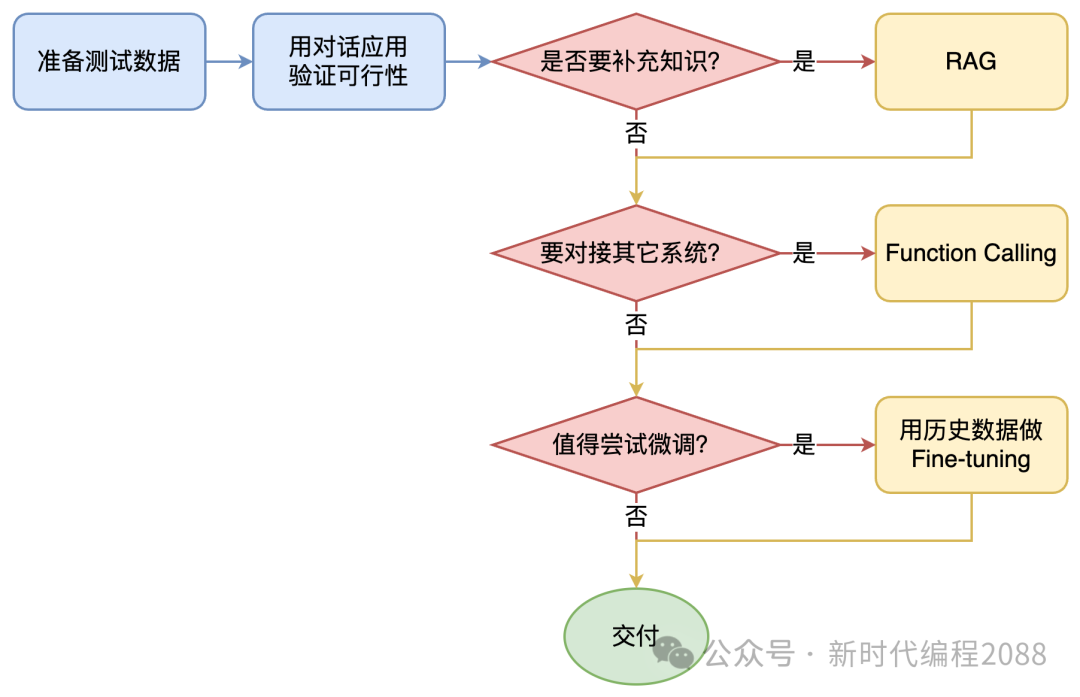
值得尝试 Fine-tuning 的情况:
-
提高大模型的稳定性
-
用户量大,降低推理成本的意义很大
-
提高大模型的生成速度
基础模型选型,也是个重要因素。合规和安全是首要考量因素。
| 需求 | 国外大模型 | 国产大模型 | 开源大模型 | |----------|-------|-------|-------| | 国内 2C | ? | ✅ | ✅ | | 国内 2G | ? | ✅ | ✅ | | 国内 2B | ✅ | ✅ | ✅ | | 出海 | ✅ | ✅ | ✅ | | 数据安全特别重要 | ? | ? | ✅ |
然后用测试数据,在可以选择的模型里,做测试,找出最优。
AI 全栈课程主要以 OpenAI 为例,少量介绍国产大模型,微调会讲开源大模型。因为:
-
OpenAI 使用量最大,即便国内也是如此
-
OpenAI 最好用,最先进,没有之一
-
其它模型都在追赶和模仿 OpenAI。学会 OpenAI,其它模型触类旁通;反之,不一定
六、总结
咱们今天主要了解:
-
AI 是什么
-
大模型可以做什么
-
大模型是如何生成结果的
-
大模型应用架构
下次分享基于Python带着大家做个入门哦,期待和大家的见面,大家如果有问题可以留言哦!