✨ 1: MemFree
MemFree是一款开源的混合AI搜索引擎,可搜索个人知识库和互联网。
MemFree 是一个开源的混合AI搜索引擎,可以同时在你的个人知识库(如书签、笔记、文档等)和互联网中进行搜索。这款搜索引擎的主要特点包括:
混合AI搜索引擎:结合了本地知识库和互联网搜索,提供精准的即时答案。
自托管的无服务器矢量数据库:快速且高效。
自托管的本地嵌入与重排服务:提高搜索结果的准确性。
一键索引Chrome书签:便于快速访问个人收藏的网页内容。
完全开源代码:方便开发者进行二次开发和功能扩展。
即将推出的一键生产环境部署:简化部署过程。
地址:https://github.com/memfreeme/memfree
✨ 2: Fine-tune Claude 3 Haiku
Amazon Bedrock 支持用户定制 Claude 3 Haiku 模型以提升业务效果。
Fine-tune Claude 3 Haiku 是一种通过定制模型来提升其知识和能力,使其更有效地完成特定任务的技术。通过在Amazon Bedrock平台上进行微调,企业可以根据自己的业务需求对Claude 3 Haiku模型进行个性化定制,从而在特定领域内表现得更出色。
微调的好处包括:
提升在特定任务上的表现:通过编码公司和行业知识,微调使Claude 3 Haiku在分类、与定制API交互或处理行业特定数据方面表现更好。
提供更快、更低成本的生产部署:相较其他模型,Claude 3 Haiku在降低成本的同时还能更快地返回结果。
一致且符合品牌的格式输出:生成符合企业规范和内部协议的标准化报告或定制模式输出。
简便易用的API:无需深入的技术知识,各类公司都可以有效地进行创新。
安全保障:训练数据保存在客户的AWS环境中,确保数据安全。
地址:https://www.anthropic.com/news/fine-tune-claude-3-haiku
✨ 3: SOLO
SOLO 是一种单一 Transformer 架构的统一视觉语言模型,接受图像和文本输入。
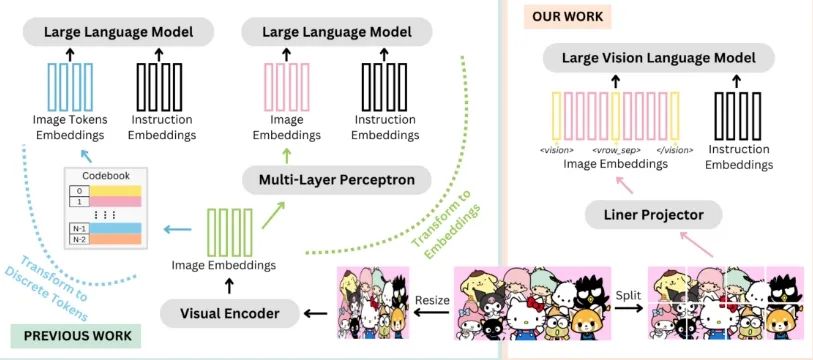
SOLO:适用于大规模视觉-语言模型的单一Transformer
简介:
SOLO(Single Transformer for Scalable Vision-Language Modeling)是一种统一的视觉-语言建模架构。与传统方法不同,SOLO接受原始图像(以像素形式)和文本作为输入,而无需借助单独的预训练视觉编码器。
使用场景:
视觉问答:利用SOLO处理包含图像和文本的问题,生成准确的回答。
图像字幕生成:输入图像,SOLO可以自动生成描述图像内容的文字。
多模态检索:可用于从包含文本和图像的数据库中检索相关内容。
跨模态生成:基于文本生成图像,或基于图像生成相关文本。
地址:https://github.com/Yangyi-Chen/SOLO
✨ 4: Video-to-Audio
视频转音频生成方法,实现语义与时间对齐的音频内容生成。
视频转音频(Video-to-Audio)技术在现代研究中备受关注,尤其是在文本生成视频技术取得显著突破之后。该技术的核心目标是在语义和时间上生成与视频输入内容高度一致的音频。以下是基于论文《Video-to-Audio Generation with Hidden Alignment》的总结及其使用场景:
视频转音频(Video-to-Audio)是通过输入视频片段生成具有相应语义和时间对齐的音频内容。这一过程借助了深度学习模型,尤其利用了隐式对齐机制(Hidden Alignment)来保持生成内容的高质量和一致性。
地址:https://github.com/ariesssxu/vta-ldm
✨ 5: aTrain
aTrain是一款确保数据隐私的离线自动转录工具,支持多国语言和说话人检测。
aTrain 是一个自动转录语音录音的工具,采用了最先进的机器学习模型,无需上传任何数据即可实现功能。它由格拉茨大学商业分析与数据科学中心的研究人员开发,并由格拉茨知识中心的研究人员测试。以下是aTrain的一些主要特点及其使用场景:
快速且精准:aTrain 利用 OpenAI 的 Whisper 模型实现了高质量的转录,同时在本地计算机上运行速度快。
说话人检测:采用 pyannote.audio 模型,可以分析每个文本段落所在的说话人。
隐私保护和GDPR合规:所有处理过程都在本地设备上完成,保证数据隐私和符合法律要求。
多语言支持:支持57种语言的语音录制转录。
兼容常用质性分析工具:生成的转录文件可以无缝导入 ATLAS.ti、MAXQDA 和 NVivo 等工具。
支持NVIDIA GPU:可以在NVIDIA GPU上运行,大大提高转录速度。
地址:https://github.com/JuergenFleiss/aTrain




