在科技日新月异的今天,我们似乎习惯了"更新换代"的节奏。但你有没有想过,那些陪伴我们多年的老手机,也能摇身一变成为AI神器?面壁智能的MiniCPM 2B大模型,就给我们带来了这样的惊喜。
你可能不知道,这个仅有20亿参数的大模型,却拥有"越级打怪"的实力。与业内知名的大模型相比,它在多项主流评测中都展现出了优越的性能。更令人振奋的是,它的成本极低,仅需1元就能驱动170万次AI推理!  那么,这个MiniCPM 2B大模型究竟有何魔力?首先,它是业界第一个在端侧部署多模态的大模型,这意味着它不仅能理解文字,还能处理图像、声音等多种信息。其次,它的推理速度极快,一张普通的1080Ti显卡就能高效微调,让AI推理变得更加轻松快捷。
那么,这个MiniCPM 2B大模型究竟有何魔力?首先,它是业界第一个在端侧部署多模态的大模型,这意味着它不仅能理解文字,还能处理图像、声音等多种信息。其次,它的推理速度极快,一张普通的1080Ti显卡就能高效微调,让AI推理变得更加轻松快捷。
更令人惊喜的是,这个强大的大模型竟然还能在老手机上运行!是的,你没有听错。那些曾经陪伴我们度过无数日夜的千元机,如今也能借助MiniCPM 2B焕发出新的生机。这不禁让我们感叹,技术的边界正在被不断推翻,智能的未来已经触手可及。
现在,你是不是已经迫不及待想要体验这个神奇的大模型了?别急,我们还有一个好消息要告诉你。面壁智能已经将这个大模型完全开源,供学术研究和有限商用。这意味着,你不仅可以亲自体验它的强大功能,还可以根据自己的需求进行二次开发。
你是否也对这款能让老手机焕发新生的MiniCPM 2B感到好奇了呢?
性能小钢炮:参数量与成本的完美平衡
面壁智能MiniCPM 2B大模型,仅凭20亿参数量就做到了与2018年BERT相当的水平 ,这真的让人震惊!它的性能优化和成本控制做得太出色了,让人不得不佩服。而且,这个模型还是业界首个在端侧部署的多模态大模型,引领了新的技术潮流。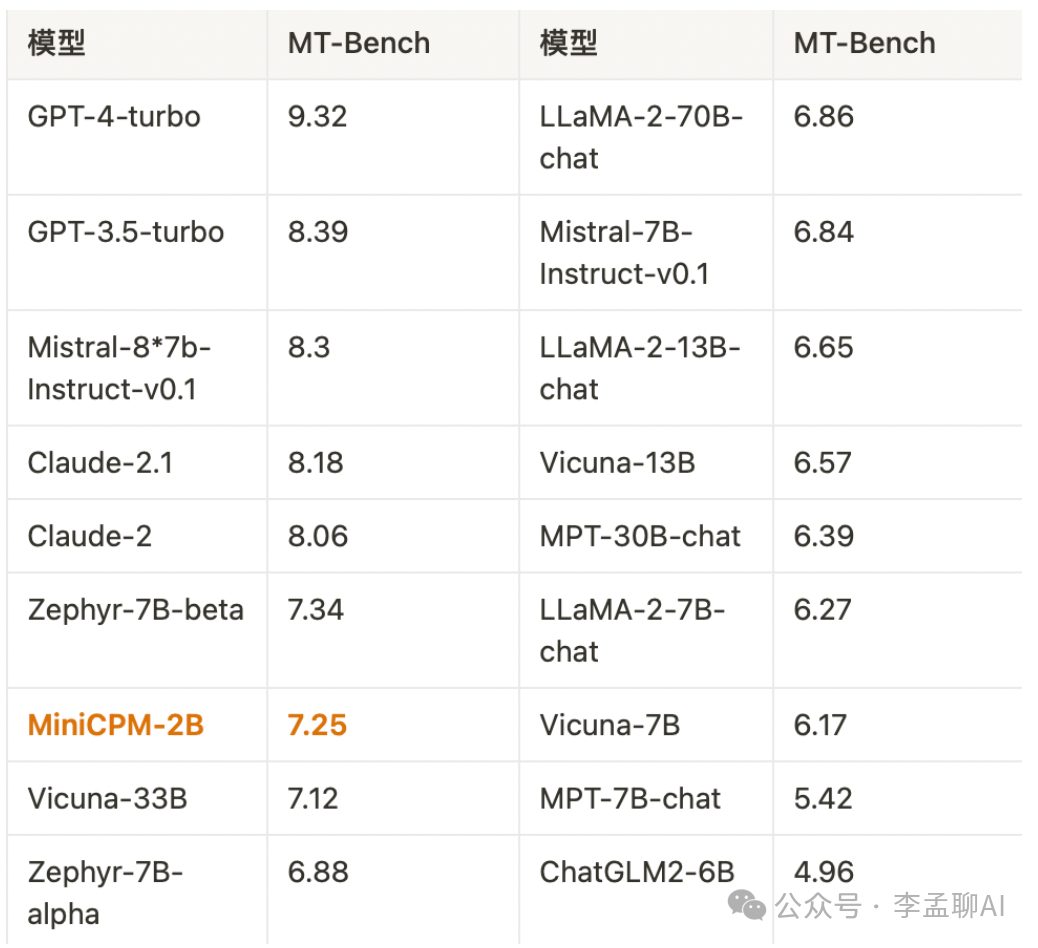
更厉害的是,MiniCPM 2B还能越级挑战更大规模的模型。(面壁智能联合创始人、CEO)李大海说,它甚至能实现13B、30B甚至40B模型的能力!在MT-Bench评测榜单上,它的成绩也非常亮眼,与GPT-4-Turbo不相上下。
而且哦,这个模型的英文能力也特别强,处理英文任务时非常得心应手。不管是翻译、识别还是对话,都能轻松应对。
让人惊喜的还有它的int4量化版,能在闪存应用压缩75%的情况下保持性能基本无损耗。这意味着,即使你的手机存储空间有限,也能顺畅运行这个模型。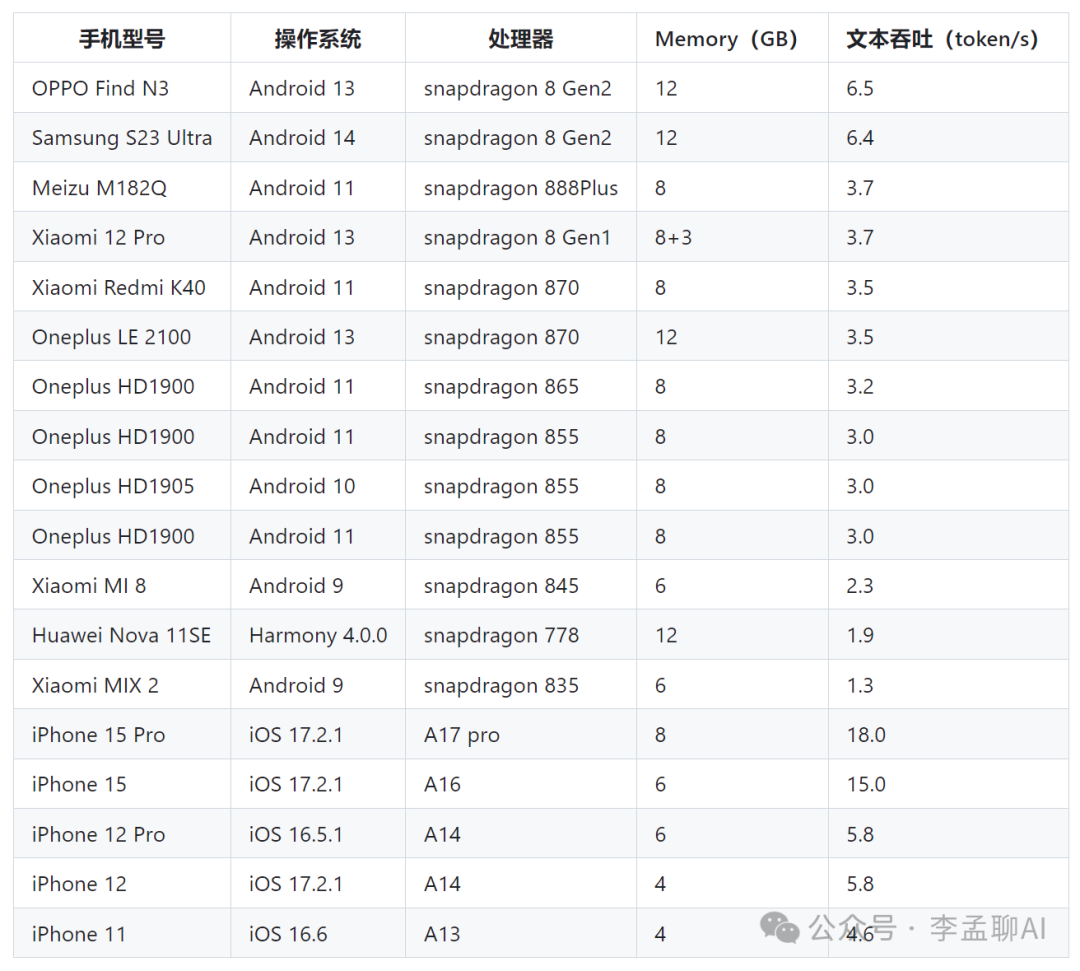 最重要的是,MiniCPM 2B支持移动端CPU推理,能大幅度节约使用成本。用搭载骁龙855的手机运行它,一块钱电费就能处理170万token!这个价格只是云端运行的Mistral-Medium的1%,简直太划算了!
最重要的是,MiniCPM 2B支持移动端CPU推理,能大幅度节约使用成本。用搭载骁龙855的手机运行它,一块钱电费就能处理170万token!这个价格只是云端运行的Mistral-Medium的1%,简直太划算了!
那么我们具体看看跟同量级大模型比较?
越级打怪:超越同量级大模型的多模态能力
开源惊艳!357M MiniCPM的惊人表现,何以碾压数十亿参数大模型?
首先,MiniCPM并没有采用什么神秘的结构设计,而是使用了标准的**Transformer encoder-decoder架构。**这就说明了,它的强大并不是靠复杂的结构,而是得益于高效的参数利用和精心的训练。
其次,开发团队在训练MiniCPM时可是下了不少功夫。他们利用了大量真实世界的数据,进行了多任务训练,让模型在各种场景下都能游刃有余。这种训练方式不仅提高了模型的泛化能力,还让它在英文和中文任务上都表现出色。
具体到中文任务上,MiniCPM更是展现出了惊人的实力。在权威的中文评测集CMMLU和C-Eval上,它的平均得分分别高达82.32和80.1,不仅超过了同规模的模型,甚至还超越了一些10B级别的大模型。这简直就是开源界的一股清流啊!
-
英文,选取了MMLU
-
中文,选取了CMMLU、C-Eval
-
代码,选取了HumanEval、MBPP
-
数学,选取了GSM8K、MATH
-
问答,选取了HellaSwag、ARC-E、ARC-C
-
逻辑,选取了BBH
与大模型相比:超过或持平大部分7B规模模型,超越部分10B以上的模型。 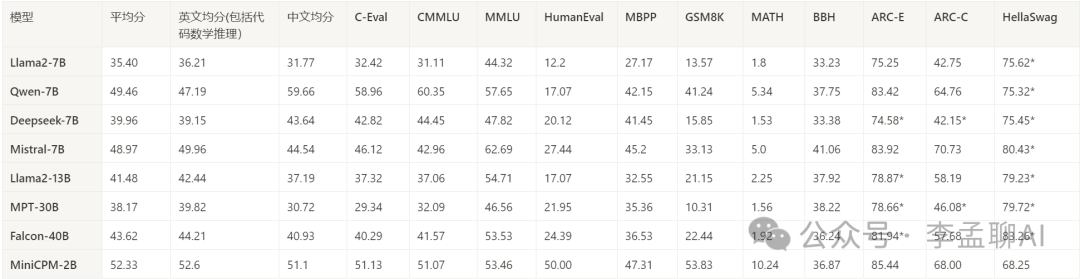 与小模型对比,除部分英文评测集外,其他测试集均超过现有模型。
与小模型对比,除部分英文评测集外,其他测试集均超过现有模型。 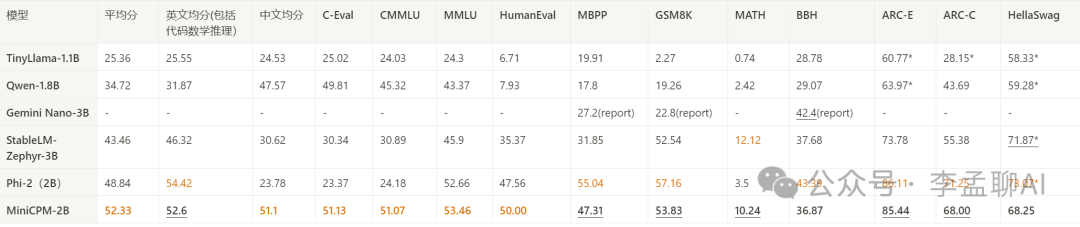
那么,MiniCPM的出现给我们带来了什么启示呢?其实,它告诉我们,在模型设计上,有时候"小而精"比"大而全"更能解决实际问题。而且,通过高效的训练和优化,小模型也能发挥出惊人的性能。
那么下面我们开始快速使用!
实际应用与快速上手
你知道吗?我们手机里的那块小小GPU,成本大约600元,但它每秒钟可以处理7.5个tokens。假设这GPU连续工作5年后"退休",那么它总共能处理惊人的170万个tokens!这样一算,每个token的推理成本竟然才1元钱。
这里有个简单的数学公式帮你理解:1元=1700000tokens。是不是觉得很划算?
相比之下,GPT-4这个大家伙的推理成本就高得多了。用1元钱,它只能处理4700个tokens。看来,手机GPU在成本效益上真的是甩了GPT-4好几条街啊!
而且,就算是跟Mistral-medium这个级别的模型比,手机GPU的成本也只是它的1/100。这么看来,我们手里的这部小手机,真的是个超值的"推理小能手"!
vLLM 推理
安装支持 MiniCPM 的 vLLM
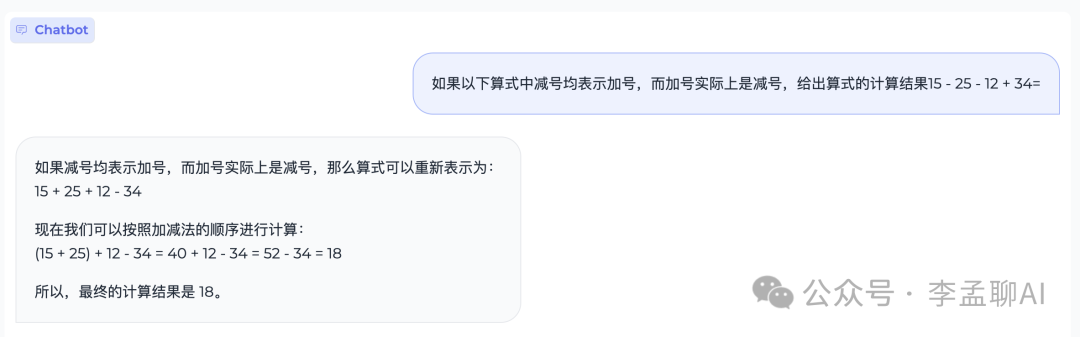
因为 MiniCPM 采用 MUP 结构,在矩阵乘法中存在一定的放缩计算,与Llama类模型结构有细微差别。我们基于版本为 0.2.2 的 vLLM 实现了 MiniCPM 的推理,代码位于仓库inference文件夹下,未来将会支持更新的vLLM 版本。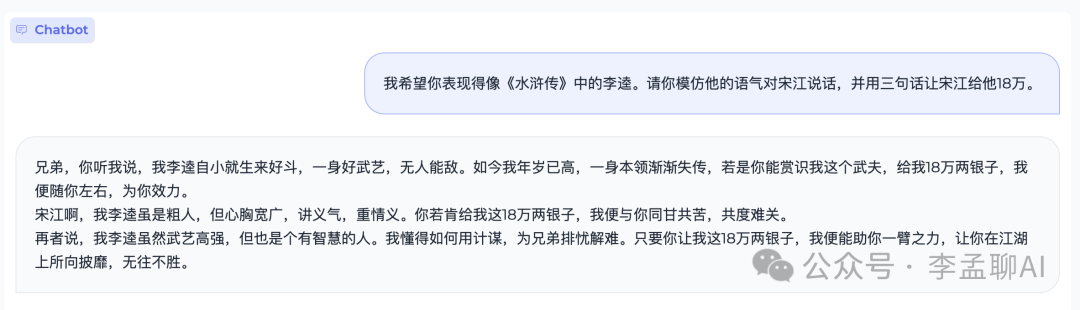
# 安装支持 MiniCPM 的 vLLM 版本
pip install inference/vllm
# 将Huggingface Transformers仓库转为vLLM-MiniCPM支持的格式,其中<hf_repo_path>, <vllmcpm_repo_path>均为本地路径
python inference/convert_hf_to_vllmcpm.py --load <hf_repo_path> --save <vllmcpm_repo_path>
# 测试样例
cd inference/vllm/examples/infer_cpm
python inference.py --model_path <vllmcpm_repo_path> --prompt_path prompts/prompt_demo.txt
手机部署
Android系统、iOS系统使用MiniCPM,太简单了!只需要几步,马上就能在手机上跑起来这个2GB大小的模型。
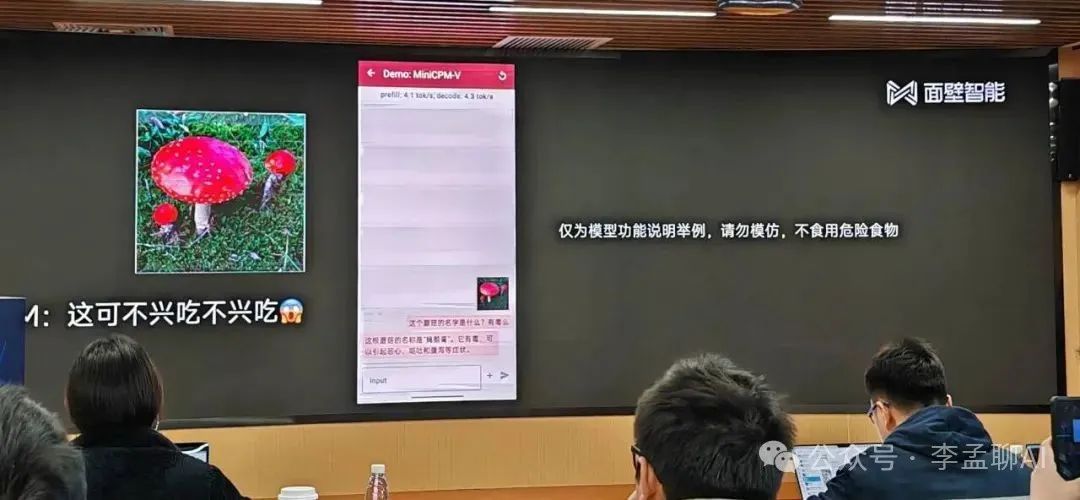
第一步,下载安装支持MiniCPM的开源框架。Android和Harmony OS使用MLC-LLM,iOS使用LLMFarm。这两个框架都开源免费,能运行各种规模的LLM。
第二步,克隆MiniCPM模型仓库,编译生成支持手机端的模型文件。参考仓库README就能完成这一步。
第三步,准备好测试样例,可以用仓库里自带的,也可以自己写。建议先从简单的无交互、单轮问答开始,验证部署成功。
**第四步,**运行框架示例程序,传入刚刚编译好的模型和测试样例,在手机上获得AI的回复。是不是很简单!
需要注意,目前框架对手机的适配还在完善中,不是所有系统版本或芯片都能保证成功。但基本流程是一致的,遇到问题可以在issue里反馈。
使用MiniCPM,不需要云服务器。它集成了问答、翻译、写作等多种能力,秒回响应,省去来回网络传输的时间。这对保护隐私非常友好。也节省了服务器成本。
AI能帮你处理日常问题,写邮件、聊天、记录。甚至能创作、设计、编码!想想都激动人心。
快加入MiniCPM的手机用户吧! 相信未来手机AI会给你全新的体验。
MiniCPM 项目源码:https://github.com/OpenBMB/MiniCPM
手机部署(Android、Harmony):https://github.com/OpenBMB/mlc-MiniCPM
手机部署(iOS):https://github.com/OpenBMB/LLMFarm
结语
面壁智能的MiniCPM 2B大模型,以其20亿参数量的轻巧身姿,打破了我们对大模型的固有认知。它不仅在性能上达到了与BERT相当的水平,更在成本控制和多模态能力上展现了惊人的实力。老手机在它的加持下焕发出第二春,而智能的未来也因此变得更加亲民和触手可及。
最后,让我们一起思考一个问题:当技术的边界被不断推翻,当智能的未来变得触手可及,我们的生活将会发生怎样的变化?让我们一起期待并见证这个充满无限可能的未来吧!
如果有其他疑问,欢迎朋友关注留言!