[转]官方推荐 Flow 取代 LiveData,有必要吗?
更加详细的文章:不做跟风党,LiveData,StateFlow,SharedFlow 的使用场景对比
前言
打开Android架构组件页面,我们可以发现一些最新发布的jetpack组件,如Room,DataStore, Paging3,DataBinding 等都支持了Flow
Google开发者账号最近也发布了几篇使用Flow的文章,比如:从 LiveData 迁移到 Kotlin 数据流
看起来官方在大力推荐使用Flow取代LiveData,那么问题来了,有必要吗?
我LiveData用得好好的,有必要再学Flow吗?本文主要回答这个问题,具体包括以下内容
1.LiveData有什么不足?
2.Flow介绍以及为什么会有Flow
3.SharedFlow与StateFlow的介绍与它们之间的区别
本文具体目录如下所示:

-
LiveData有什么不足?
要了解LiveData的不足,我们先了解下LiveData为什么被引入
LiveData的历史要追溯到 2017 年。彼时,观察者模式有效简化了开发,但诸如RxJava一类的库对新手而言有些太过复杂。为此,架构组件团队打造了LiveData: 一个专用于 Android 的具备自主生命周期感知能力的可观察的数据存储器类。LiveData被有意简化设计,这使得开发者很容易上手;而对于较为复杂的交互数据流场景,建议您使用RxJava,这样两者结合的优势就发挥出来了
可以看出,LiveData就是一个简单易用的,具备感知生命周期能力的观察者模式
它使用起来非常简单,这是它的优点,也是它的不足,因为它面对比较复杂的交互数据流场景时,处理起来比较麻烦
1.2 LiveData的不足
我们上文说过LiveData结构简单,但是不够强大,它有以下不足
-
LiveData只能在主线程更新数据 -
LiveData的操作符不够强大,在处理复杂数据流时有些捉襟见肘
关于LiveData只能在主线程更新数据,有的同学可能要问,不是有postValue吗?其实postValue也是需要切换到到主线程的,如下图所示:
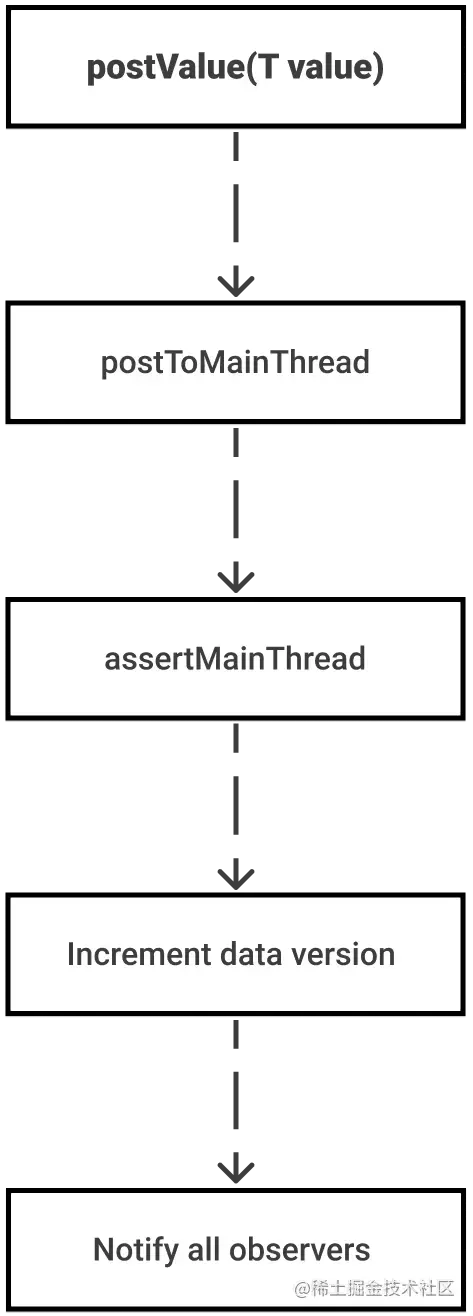
这意味着当我们想要更新LiveData对象时,我们会经常更改线程(工作线程→主线程),如果在修改LiveData后又要切换回到工作线程那就更麻烦了,同时postValue可能会有丢数据的问题。
-
Flow介绍
Flow 就是 Kotlin 协程与响应式编程模型结合的产物,你会发现它与 RxJava 非常像,二者之间也有相互转换的 API,使用起来非常方便。
2.1 为什么引入Flow
为什么引入Flow,我们可以从Flow解决了什么问题的角度切入
-
LiveData不支持线程切换,所有数据转换都将在主线程上完成,有时需要频繁更改线程,面对复杂数据流时处理起来比较麻烦 -
而
RxJava又有些过于麻烦了,有许多让人傻傻分不清的操作符,入门门槛较高,同时需要自己处理生命周期,在生命周期结束时取消订阅
可以看出,Flow是介于LiveData与RxJava之间的一个解决方案,它有以下特点
-
Flow支持线程切换、背压 -
Flow入门的门槛很低,没有那么多傻傻分不清楚的操作符 -
简单的数据转换与操作符,如
map等等 -
冷数据流,不消费则不生产数据,这一点与
LiveData不同:LiveData的发送端并不依赖于接收端。 -
属于
kotlin协程的一部分,可以很好的与协程基础设施结合
关于Flow的使用,比较简单,有兴趣的同学可参阅文档:Flow文档
-
SharedFlow介绍
我们上面介绍过,Flow 是冷流,什么是冷流?
-
冷流:只有订阅者订阅时,才开始执行发射数据流的代码。并且冷流和订阅者只能是一对一的关系,当有多个不同的订阅者时,消息是重新完整发送的。也就是说对冷流而言,有多个订阅者的时候,他们各自的事件是独立的。 -
热流:无论有没有订阅者订阅,事件始终都会发生。当 热流有多个订阅者时,热流与订阅者们的关系是一对多的关系,可以与多个订阅者共享信息。
3.1 为什么引入SharedFlow
上面其实已经说得很清楚了,冷流和订阅者只能是一对一的关系,当我们要实现一个流,多个订阅者的需求时(这在开发中是很常见的),就需要热流了
从命名上也很容易理解,SharedFlow即共享的Flow,可以实现一对多关系,SharedFlow是一种热流
3.2 SharedFlow的使用
我们来看看SharedFlow的构造函数
public fun <T> MutableSharedFlow(
replay: Int = 0,
extraBufferCapacity: Int = 0,
onBufferOverflow: BufferOverflow = BufferOverflow.SUSPEND
): MutableSharedFlow<T>
其主要有3个参数
1.replay表示当新的订阅者Collect时,发送几个已经发送过的数据给它,默认为0,即默认新订阅者不会获取以前的数据
2.extraBufferCapacity表示减去replay,MutableSharedFlow还缓存多少数据,默认为0
3.onBufferOverflow表示缓存策略,即缓冲区满了之后Flow如何处理,默认为挂起
简单使用如下
//ViewModel
val sharedFlow=MutableSharedFlow<String>()
viewModelScope.launch{
sharedFlow.emit("Hello")
sharedFlow.emit("SharedFlow")
}
//Activity
lifecycleScope.launch{
viewMode.sharedFlow.collect {
print(it)
}
}
3.3 将冷流转化为SharedFlow
普通flow可使用shareIn扩展方法,转化成SharedFlow
val sharedFlow by lazy {
flow<Int> {
//...
}.shareIn(viewModelScope, WhileSubscribed(500), 0)
}
shareIn主要也有三个参数:
@param
scope共享开始时所在的协程作用域范围
@paramstarted控制共享的开始和结束的策略
@paramreplay状态流的重播个数
started 接受以下的三个值:
-
Lazily: 当首个订阅者出现时开始,在scope指定的作用域被结束时终止。 -
Eagerly: 立即开始,而在scope指定的作用域被结束时终止。 -
WhileSubscribed:这种情况有些复杂,后面会详细讲解
对于那些只执行一次的操作,您可以使用Lazily或者Eagerly。然而,如果您需要观察其他的流,就应该使用WhileSubscribed来实现细微但又重要的优化工作
3.4 Whilesubscribed策略
WhileSubscribed策略会在没有收集器的情况下取消上游数据流,通过shareIn运算符创建的SharedFlow会把数据暴露给视图 (View),同时也会观察来自其他层级或者是上游应用的数据流。
让这些流持续活跃可能会引起不必要的资源浪费,例如一直通过从数据库连接、硬件传感器中读取数据等等。当您的应用转而在后台运行时,您应当保持克制并中止这些协程。
public fun WhileSubscribed(
stopTimeoutMillis: Long = 0,
replayExpirationMillis: Long = Long.MAX_VALUE
)
如上所示,它支持两个参数:
-
stopTimeoutMillis控制一个以毫秒为单位的延迟值,指的是最后一个订阅者结束订阅与停止上游流的时间差。默认值是 0 (立即停止).这个值非常有用,因为您可能并不想因为视图有几秒钟不再监听就结束上游流。这种情况非常常见------比如当用户旋转设备时,原来的视图会先被销毁,然后数秒钟内重建。 -
replayExpirationMillis表示数据重播的过时时间,如果用户离开应用太久,此时您不想让用户看到陈旧的数据,你可以用到这个参数 -
StateFlow介绍
4.1 为什么引入StateFlow
我们前面刚刚看了SharedFlow,为什么又冒出个StateFlow?
StateFlow 是 SharedFlow 的一个比较特殊的变种,StateFlow与 LiveData 是最接近的,因为:
-
它始终是有值的。
-
它的值是唯一的。
-
它允许被多个观察者共用 (因此是共享的数据流)。
-
它永远只会把最新的值重现给订阅者,这与活跃观察者的数量是无关的。
可以看出,StateFlow与LiveData是比较接近的,可以获取当前的值,可以想像之所以引入StateFlow就是为了替换LiveData
-
StateFlow继承于SharedFlow,是SharedFlow的一个特殊变种 -
StateFlow与LiveData比较相近,相信之所以推出就是为了替换LiveData
4.2 StateFlow的简单使用
我们先来看看构造函数:
public fun <T> MutableStateFlow(value: T): MutableStateFlow<T> = StateFlowImpl(value ?: NULL)
-
StateFlow构造函数较为简单,只需要传入一个默认值 -
StateFlow本质上是一个replay为1,并且没有缓冲区的SharedFlow,因此第一次订阅时会先获得默认值 -
StateFlow仅在值已更新,并且值发生了变化时才会返回,即如果更新后的值没有变化,也没会回调Collect方法,这点与LiveData不同
与SharedFlow类似,我们也可以用stateIn将普通流转化成StateFlow
val result: StateFlow<Result<UiState>> = someFlow
.stateIn(
scope = viewModelScope,
started = WhileSubscribed(5000),
initialValue = Result.Loading
)
与shareIn类似,唯一不同的时需要传入一个默认值
同时之所以WhileSubscribed中传入了5000,是为了实现等待5秒后仍然没有订阅者存在就终止协程的功能,这个方法有以下功能
-
用户将您的应用转至后台运行,5 秒钟后所有来自其他层的数据更新会停止,这样可以节省电量。
-
最新的数据仍然会被缓存,所以当用户切换回应用时,视图立即就可以得到数据进行渲染。
-
订阅将被重启,新数据会填充进来,当数据可用时更新视图。
-
在屏幕旋转时,因为重新订阅的时间在5s内,因此上游流不会中止
4.3 在页面中观察StateFlow
与LiveData类似,我们也需要经常在页面中观察StateFlow
观察StateFlow需要在协程中,因此我们需要协程构建器,一般我们会使用下面几种
-
lifecycleScope.launch: 立即启动协程,并且在本Activity或Fragment销毁时结束协程。 -
LaunchWhenStarted和LaunchWhenResumed,它会在lifecycleOwner进入X状态之前一直等待,又在离开X状态时挂起协程
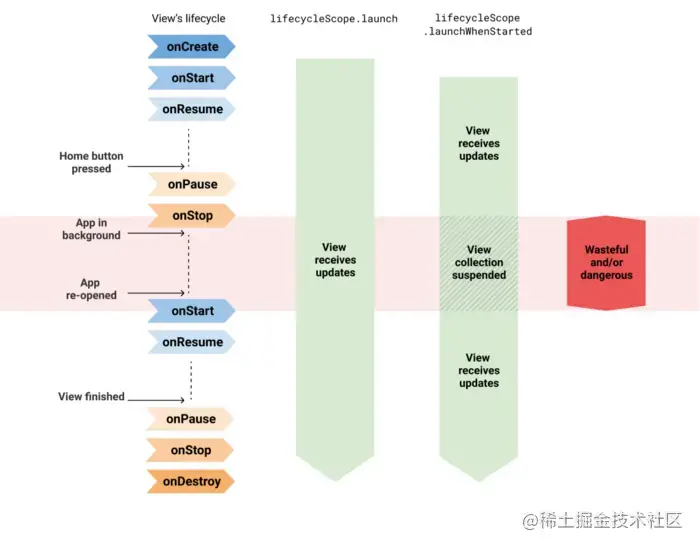
如上图所示:
1.使用launch是不安全的,在应用在后台时也会接收数据更新,可能会导致应用崩溃
2.使用launchWhenStarted或launchWhenResumed会好一些,在后台时不会接收数据更新,但是,上游数据流会在应用后台运行期间保持活跃,因此可能浪费一定的资源
这么说来,我们使用WhileSubscribed进行的配置岂不是无效了吗?订阅者一直存在,只有页面关闭时才会取消订阅
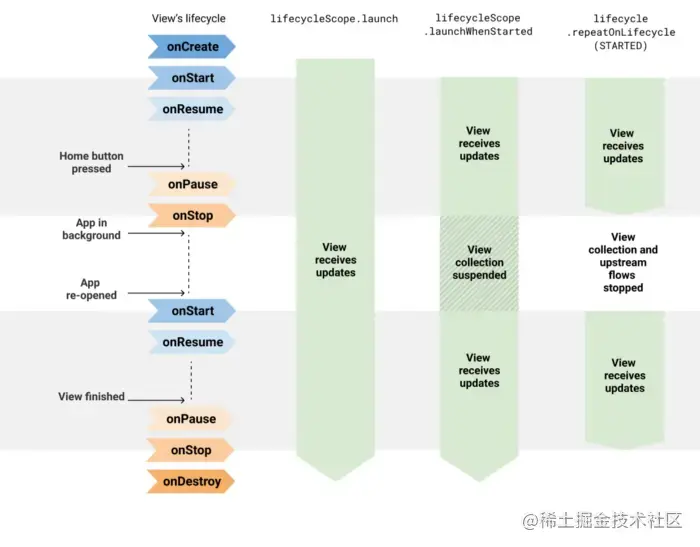
官方推荐repeatOnLifecycle来构建协程
在某个特定的状态满足时启动协程,并且在生命周期所有者退出该状态时停止协程,如下图所示。
比如在某个Fragment的代码中:
onCreateView(...) {
viewLifecycleOwner.lifecycleScope.launch {
viewLifecycleOwner.lifecycle.repeatOnLifecycle(STARTED) {
myViewModel.myUiState.collect { ... }
}
}
}
当这个Fragment处于STARTED状态时会开始收集流,并且在RESUMED状态时保持收集,最终在Fragment进入STOPPED状态时结束收集过程。
结合使用repeatOnLifecycle API和WhileSubscribed,可以帮助您的应用妥善利用设备资源的同时,发挥最佳性能
4.4 页面中观察Flow的最佳方式
通过ViewModel暴露数据,并在页面中获取的最佳方式是:
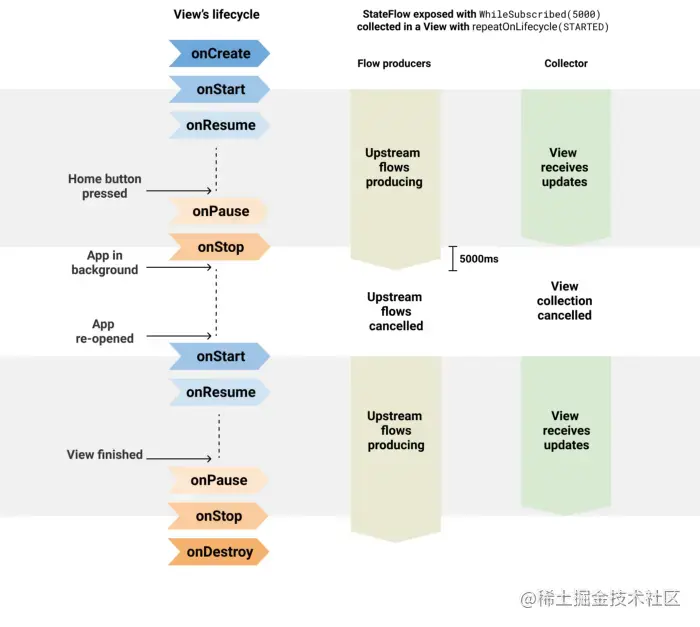
最佳实践如上图所示,如果采用其他方式,上游数据流会被一直保持活跃,导致资源浪费
当然,如果您并不需要使用到Kotlin Flow的强大功能,就用LiveData好了 :)
5 StateFlow与SharedFlow有什么区别?
从上文其实可以看出,StateFlow与SharedFlow其实是挺像的,让人有些傻傻分不清,有时候也挺难选择该用哪个的
我们总结一下,它们的区别如下:
-
SharedFlow配置更为灵活,支持配置replay,缓冲区大小等,StateFlow是SharedFlow的特化版本,replay固定为1,缓冲区大小默认为0 -
StateFlow与LiveData类似,支持通过myFlow.value获取当前状态,如果有这个需求,必须使用StateFlow -
SharedFlow支持发出和收集重复值,而StateFlow当value重复时,不会回调collect
对于新的订阅者,StateFlow只会重播当前最新值,SharedFlow可配置重播元素个数(默认为0,即不重播)
可以看出,StateFlow为我们做了一些默认的配置,在SharedFlow上添加了一些默认约束,这些配置可能并不符合我们的要求
-
它忽略重复的值,并且是不可配置的。这会带来一些问题,比如当往
List中添加元素并更新时,StateFlow会认为是重复的值并忽略 -
它需要一个初始值,并且在开始订阅时会回调初始值,这有可能不是我们想要的
-
它默认是粘性的,新用户订阅会获得当前的最新值,而且是不可配置的,而
SharedFlow可以修改replay
StateFlow施加在SharedFlow上的约束可能不是最适合您,如果不需要访问myFlow.value,并且享受SharedFlow的灵活性,可以选择考虑使用SharedFlow
总结
简单往往意味着不够强大,而强大又常常意味着复杂,两者往往不能兼得,软件开发过程中常常面临这种取舍。
LiveData的简单并不是它的缺点,而是它的特点。StateFlow与SharedFlow更加强大,但是学习成本也显著的更高.
我们应该根据自己的需求合理选择组件的使用
-
如果你的数据流比较简单,不需要进行线程切换与复杂的数据变换,
LiveData对你来说相信已经足够了 -
如果你的数据流比较复杂,需要切换线程等操作,不需要发送重复值,需要获取
myFlow.value,StateFlow对你来说是个好的选择 -
如果你的数据流比较复杂,同时不需要获取
myFlow.value,需要配置新用户订阅重播无素的个数,或者需要发送重复的值,可以考虑使用SharedFlow
参考资料
Google 推荐在 MVVM 架构中使用 Kotlin Flow
Migrate from LiveData to StateFlow and SharedFlow
从 LiveData 迁移到 Kotlin 数据流
关于kotlin中的Collections、Sequence、Channel和Flow (二)