点关注不迷路!
前面一张我们提到过,模型压缩主要分为以下四种方法:剪枝 、知识蒸馏 、量化 和低秩因子分解 。同时,同时也分享过低秩因子分解技术,那么今天就来谈谈另一项模型压缩技术-模型剪枝(Pruning)。
在整个模型压缩的技术里面,模型剪枝的应用没有其他的方法那么广。是因为这种方式相比其他的方法难度更高,会更加损害模型的性能。
模型剪枝是一种减少神经网络参数量和计算量的模型压缩技术。它并不是直观上的把某些参数直接从网络里面去掉,而是把某些不重要的参数或者激活值趋于0,以实现模型的压缩和加速计算。他其实并不是一个新的技术,比如说我们熟悉的Dropout,就是一种模型剪枝方法。
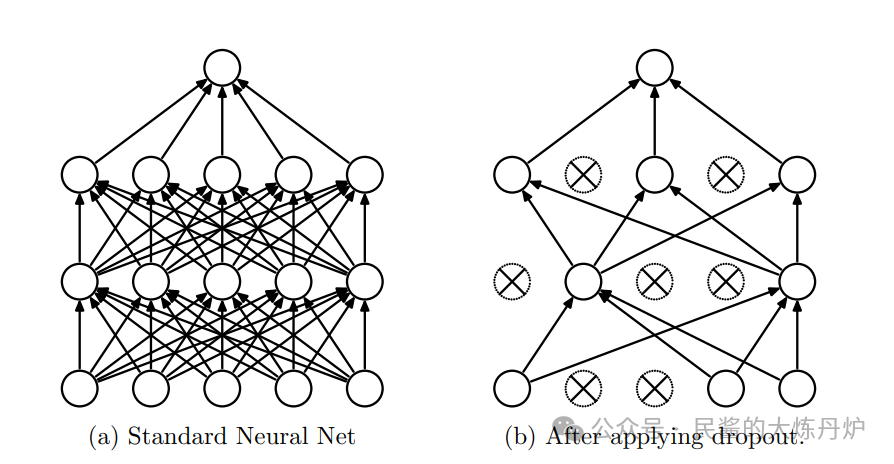
通常情况下来说,模型剪枝分为结构化剪枝和非结构化剪枝。
结构化剪枝(Structured Pruning):
剪枝方式: 结构化剪枝是按整个结构单元进行剪枝,同时保留整体的网络结构。例如,对LLM网络中的整个神经元、通道(channel)、或层(layer)进行剪枝,来简化LLM。
该方向的最著名一项工作之一是LLM-Pruner。它首先 对网络的参数进行分组,找到可移除的最小单元(通常称为 Group),并对各个组进行重要性评估。然后 ,在得到各个分组的重要性后,我们将冗余的组整个移除,从而降低模型的参数量。最后, 在剪枝后的模型上应用 LoRA 等高效微调策略,恢复模型性能。

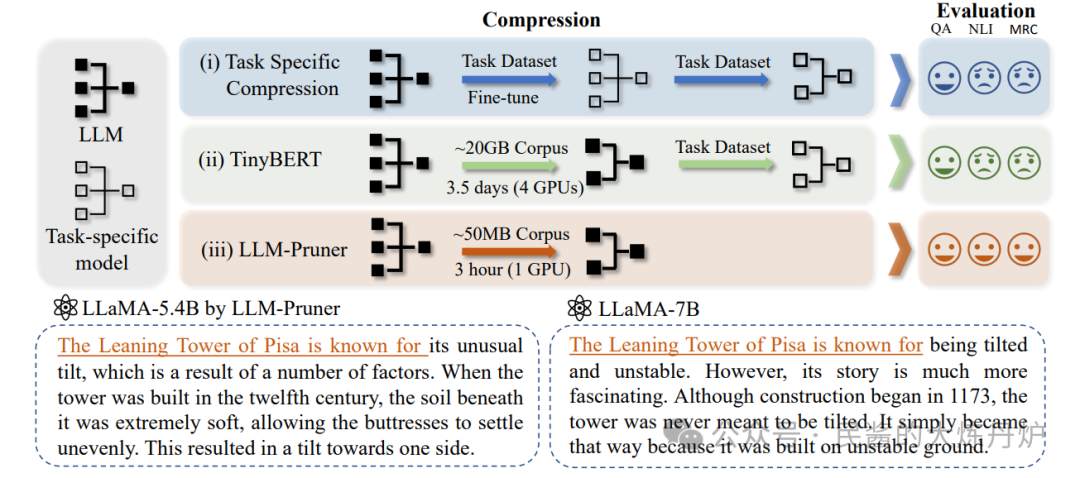
非结构化剪枝(Unstructured Pruning):
剪枝方式: 非结构化剪枝是对模型的单个参数(如权重)进行剪枝,而不考虑整个结构单元。
例如,在LLM模型压缩过程中,通过使低于某个阈值的参数置为0,实现模型的加速与压缩。但是这种方式会导致模型的不规则稀疏化,极大影响模型的精度。这种方法通常需要专门的压缩技术来存储和计算剪枝后的模型。比如,模型剪枝后进行重新训练或者微调,使模型恢复原来的效果。但是这种方式十分消耗资源,成本较高。
但是近段时间也有一些LLM剪枝算法,实现模型非结构化的稀疏性,而无需采用任何后续的训练或微调。比如SparseGPT,能使得GPT类的模型达到50%的稀疏性。比如在目前最大的开源模型 OPT‑175B 和 BLOOM‑176B 上执行SparseGPT 时,可以达到 60% 的稀疏度,同时将精度损失降到最小。

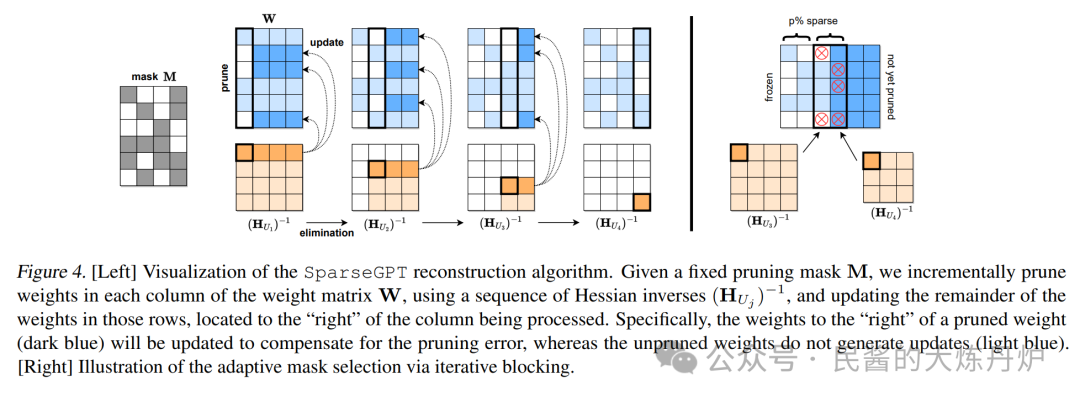
给定一个固定的剪枝掩码 M,使用 Hessian 逆序列(HU ~j~ )并更新这些行中位于列"右侧"的剩余权重,逐步修剪权重矩阵 W 的每一列中的权重处理。具体来说,修剪后权重(深蓝⾊)"右侧"的权重将被更新以补偿修剪错误,而未修剪的权重不会生成更新(浅蓝⾊)。
除此之外还有微软的SliceGPT,可以为 LLAMA-2 70B、OPT 66B 和 Phi-2 模型去除多达 25% 的模型参数(包括嵌入),同时分别保持密集模型 99%、99% 和 90% 的Zero-Shot任务性能。。

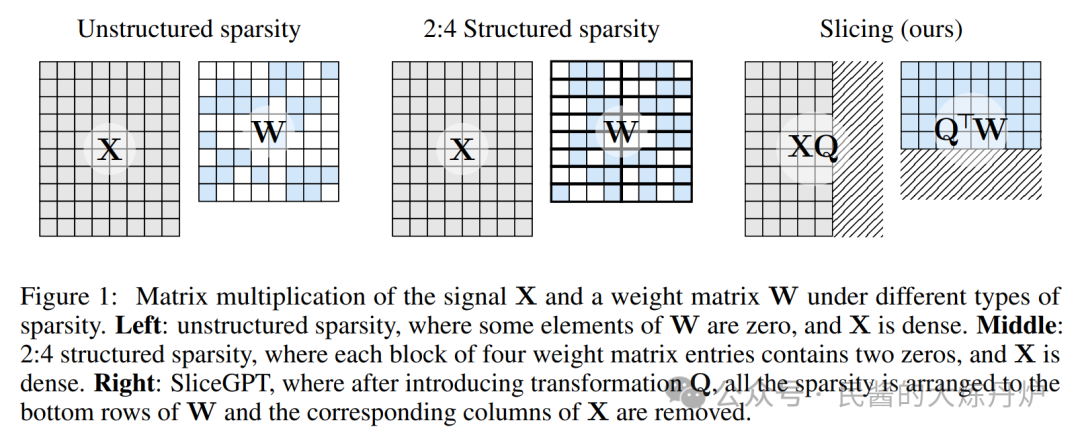
SliceGPT 会剪掉权重矩阵的整行或整列。在切之前,他们会对网络进行一次转换,使预测结果保持不变,但允许剪切过程带来轻微的影响。结果是权重矩阵变小了,神经网络块之间传递的信号也变小了:他们降低了神经网络的嵌入维度。
目前LLM的剪枝方法大致分为上面两大类,虽然模型剪枝的应用不如模型量化来的普及,但是,该方向的工作对减少越来越大的LLM的参数量是至关重要的。
https://blog.csdn.net/2401_82469710/article/details/137629451
https://arxiv.org/pdf/2301.00774
https://arxiv.org/pdf/2305.11627
https://arxiv.org/pdf/2401.15024