目录
-
智能交易机器人
-
智能交易频道
-
训练机器学习模型(离线)
-
下载和合并源数据
-
生成特征
-
生成标签
-
训练预测模型
-
聚合与后处理
-
信号生成
-
训练信号模型
-
基于训练好的模型进行在线预测(服务)
-
Hyper-parameter (超参)调整
-
配置参数
-
Signaler(信号器) 服务
-
Trader(交易器)
-
更多
智能交易机器人
https://github.com/asavinov/intelligent-trading-bot
该项目的目标是开发一个智能交易机器人,用于使用最前沿的机器学习(ML)算法和特征工程技术自动化交易加密货币。该项目提供了以下主要功能:
-
使用自定义(Python)函数定义衍生特征,包括技术指标
-
分析历史数据,并以离线批处理模式训练机器学习模型
-
分析预测得分并选择最佳信号参数
-
信号服务会定期从交易所请求新数据,并通过应用之前训练的模型在线生成买卖信号
-
交易服务会根据生成的信号实际买入或卖出资产
智能交易频道
信号服务在云端运行,并将其信号发送到此 Telegram 频道:
? Intelligent Trading Signals ? https://t.me/intelligent_trading_signals
任何人都可以订阅该频道,了解这个机器人产生的信号情况。
目前,机器人配置了以下参数:
-
交易所:Binance
-
加密货币:₿ 比特币
-
分析频率:1分钟(目前唯一选项)
-
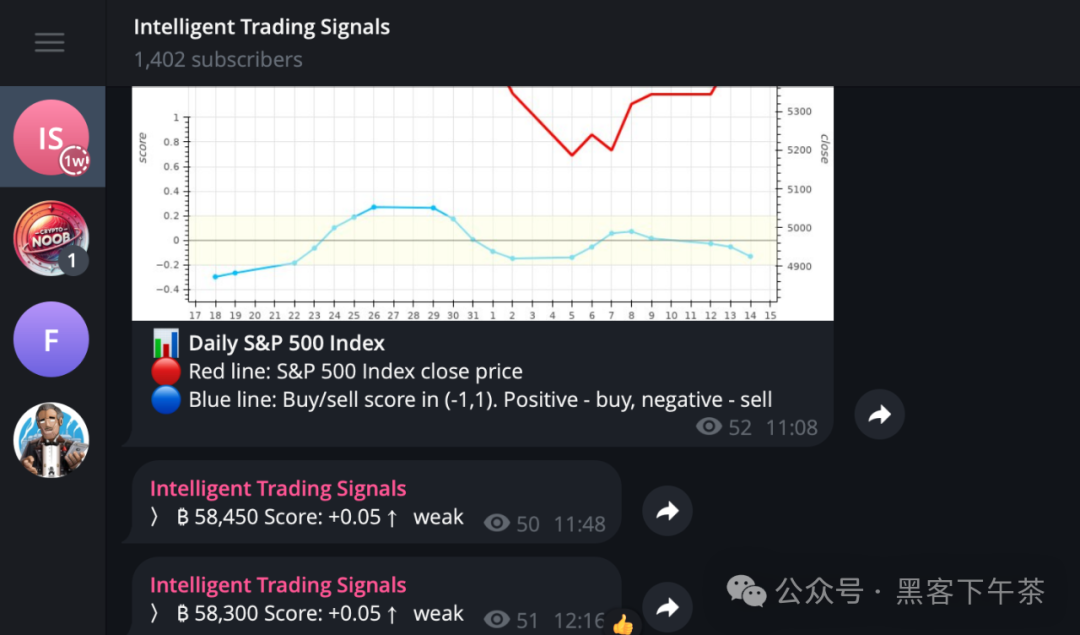
得分范围介于 -1 到 +1 之间。小于 0 表示可能下跌,大于 0 表示可能上涨
-
过滤器:仅当得分大于 ±0.20 时才发送通知(可能会改变)
-
每增加或减少 0.05 个单位(超过过滤阈值)就添加一个涨跌符号
存在一些静默期,当得分低于阈值时不会向频道发送通知。如果得分高于阈值,则每分钟都会发送一条通知,看起来像这样:
₿ 24.518 ??? 得分:-0.26
第一个数字是最新的收盘价。得分 -0.26 意味着价格很可能低于当前收盘价。
如果得分超过了模型中指定的某个阈值,则会生成买入或卖出信号,这意味着是进行交易的好时机。这样的通知看起来像这样:
? 买入:₿ 24,033 得分:+0.34
训练机器学习模型(离线)
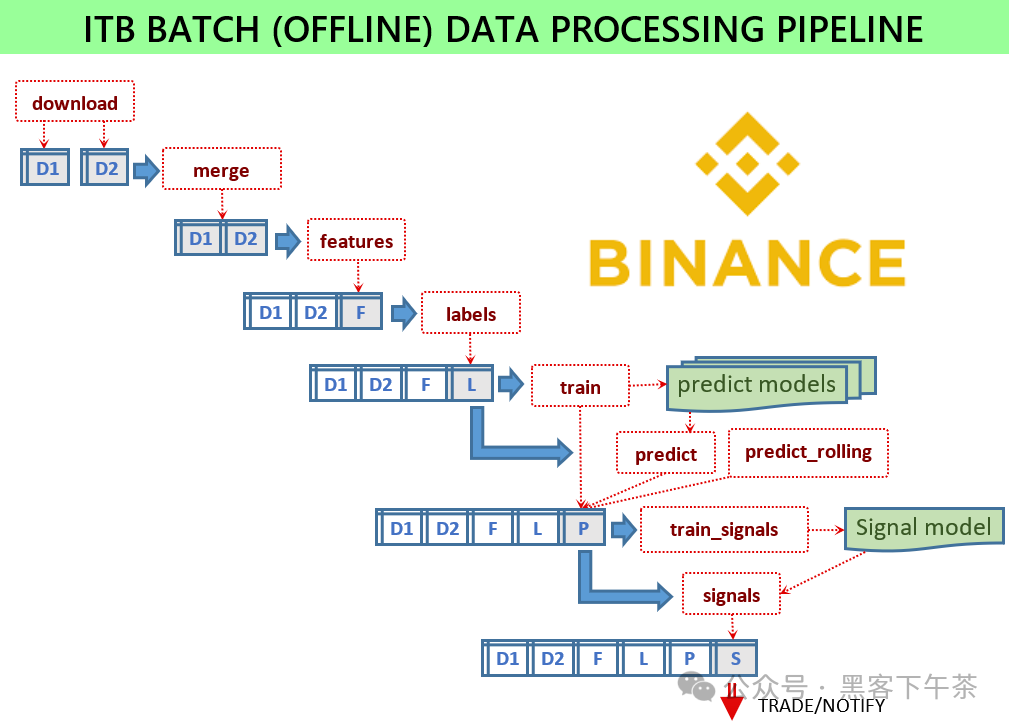
为了让信号服务能够工作,必须训练一系列的机器学习模型,并使这些模型文件可供服务使用。所有脚本都以批处理模式运行,加载一些输入数据并存储一些输出文件。批处理脚本位于 scripts 模块中。
如果一切配置妥当,则需要执行以下脚本:
-
python -m scripts.download_binance -c config.json -
python -m scripts.merge -c config.json -
python -m scripts.features -c config.json -
python -m scripts.labels -c config.json -
python -m scripts.train -c config.json -
python -m scripts.signals -c config.json -
python -m scripts.train_signals -c config.json
如果没有配置文件,脚本将使用默认参数,这对于测试目的很有用,但并不打算展示良好的性能。请使用每个版本提供的示例配置文件,例如 config-sample-v0.6.0.jsonc。
下载和合并源数据
这两个脚本的主要配置参数是在 data_sources 中的数据源列表。列表中的每一项指定了一个数据源以及column_prefix,用于区分来自不同源的同名列。
-
下载最新的历史数据:
python -m scripts.download_binance -c config.json- 它使用 Binance API,但也可以使用任何其他数据源或使用其他脚本手动下载数据
-
将多个历史数据集合并为一个数据集:
python -m scripts.merge -c config.json- 此脚本解决了两个问题:1) 可能有其他来源,如深度数据或期货 2) 数据源可能存在空缺,因此我们需要在输出文件中生成一个规则的时间网格
生成特征
此脚本用于计算派生特征:
-
脚本:
python -m scripts.features -c config.json -
目前它以非增量模式运行,计算所有可用输入记录的特征(而不仅仅是最新更新),因此对于复杂的配置可能需要数小时
-
脚本加载合并的输入数据,应用特征生成过程,并将所有派生特征存储在输出文件中
-
并非所有生成的特征都将用于训练和预测。对于训练/预测阶段,会指定一个单独的特征列表
-
特征函数从配置部分获取额外参数,如窗口大小
-
在线特征生成(在服务中为微批次生成)和离线特征生成必须使用相同的特征
要在配置文件中生成的特征列表通过feature_sets列表配置。特征如何生成由特征生成器定义,每个特征生成器在其配置部分中有一些参数。
-
talib特征生成器依赖于 TA-lib 技术分析库。这里是一个它的配置示例:"config": {"columns": ["close"], "functions": ["SMA"], "windows": [5, 10, 15]} -
itbstats特征生成器实现了可以在 tsfresh 中找到的函数,如scipy_skew、scipy_kurtosis、lsbm(均值以下最长连续序列)、fmax(最大值首次出现的位置)、mean、std、area、slope。这里是一些典型的参数:"config": {"columns": ["close"], "functions": ["skew", "fmax"], "windows": [5, 10, 15]} -
itblib特征生成器实现在 ITB 中,但其大多数特征可以通过talib更快地生成 -
tsfresh从 tsfresh 库生成函数
生成标签
此脚本与特征生成类似,因为它向输入文件添加新的列。然而,这些列描述了我们想要预测的内容,而在在线模式下执行时这些内容是未知的。例如,它可以是未来的价格上涨:
-
脚本:
python -m scripts.labels -c config.json -
脚本加载特征,计算标签列,并将结果存储在输出文件中
-
并非所有生成的标签都需要使用。用于训练的标签在单独的列表中指定
要在配置中生成的标签列表通过label_sets列表配置。一个标签集指向生成附加列的函数。它们的配置与特征配置非常相似。
-
highlow标签生成器如果价格在未来某个时间范围内高于指定阈值则返回True -
highlow2计算未来的价格上涨(下跌),条件是在此之前没有显著的价格下跌(上涨)。这里是一个典型的配置:"config": {"columns": ["close", "high", "low"], "function": "high", "thresholds": [1.0, 1.5, 2.0], "tolerance": 0.2, "horizon": 10080, "names": ["first_high_10", "first_high_15", "first_high_20"]} -
topbot已废弃 -
topbot2计算最大值和最小值(标记为True)。每一个标记的最大值(最小值)都保证被低于(高于)指定水平的最小值(最大值)包围。相邻最小值和最大值之间的所需最小差异通过level参数指定。容差参数允许包含接近最大值/最小值的点。这里是一个典型的配置:"config": {"columns": "close", "function": "bot", "level": 0.02, "tolerances": [0.1, 0.2], "names": ["bot2_1", "bot2_2"]}
训练预测模型
此脚本使用指定的输入特征和标签来训练多个机器学习模型:
-
脚本:
python -m scripts.train -c config.json -
超参数调整不是此过程的一部分------假设已知超参数
-
算法描述和超参数在模型存储中指定
-
结果作为多个模型文件存储在模型文件夹中。文件名等于预测列名,遵循此模式:(标签名称, 算法名称)
-
此脚本为所有指定的标签和所有指定的算法训练模型
-
脚本还会生成
prediction-metrics.txt文件,其中包含所有模型的预测分数
配置:
-
模型和超参数在
model_store.py中描述 -
用于训练的特征在
train_features中指定 -
标签列表在
labels中指定 -
算法列表在
algorithms中指定
聚合与后处理
此步骤的目标是聚合不同算法为不同标签生成的预测分数。结果是一个分数,该分数预计将在下一步由信号规则消费。聚合参数在score_aggregation部分中指定。buy_labels和sell_labels指定了经过聚合过程处理的输入预测分数。window是用于滚动聚合的前几步的数量,而combine是指两种分数类型(买入和卖出)如何组合成一个输出分数的方法。
信号生成
聚合过程生成的分数是一个数值,信号规则的目标是做出交易决策:买入、卖出或什么都不做。信号规则的参数在trade_model中描述。
训练信号模型
此脚本模拟使用多种买入-卖出信号参数进行交易,然后选择表现最佳的信号参数:
- 脚本:
python -m scripts.train_signals -c config.json
基于训练好的模型进行在线预测(服务)
此脚本启动一个服务,该服务周期性地执行同一任务:加载最新数据、生成特征、进行预测、生成信号、通知订阅者:
-
启动脚本:
python -m service.server -c config.json -
该服务假定模型是使用配置中指定的特征进行训练的
-
该服务使用配置中指定的凭证访问交易所
Hyper-parameter (超参)调整
存在两个问题:
-
如何为机器学习模型选择最佳的超参数。这个问题通常采用经典方法解决,例如网格搜索。例如,对于梯度提升,我们在相同的数据上使用不同的超参数训练模型,然后选择那些显示最佳分数的超参数。这种方法有一个缺点------我们优化的是最佳分数而不是交易性能。这意味着交易性能无法保证良好(实际上也不会良好)。因此,我们将这个分数用作中间特征,目的是在后续阶段优化交易性能。
-
如果我们计算最终的聚合分数(例如+0.21),那么问题在于我们应该买入、卖出还是什么都不做?事实上,这是最难的问题。为了帮助解答这个问题,开发了额外的脚本来回测并优化买卖信号的生成:
-
生成滚动预测,这模拟了我们定期重新训练模型并用其进行预测的过程:
python -m scripts.predict_rolling -c config.json -
训练信号模型以选择最佳的买卖信号阈值,在历史数据上产生最佳性能:
python -m scripts.train_signals -c config.json
-
配置参数
配置参数在两个文件中指定:
-
service.App.py中App类的config字段 -
-c config.jsom参数用于服务和脚本。当此配置文件加载到脚本或服务中时,该文件中的值会覆盖App.config中的值
以下是一些最重要的字段(在 App.py 和 config.json 中都有):
-
data_folder- 数据文件的位置,这些文件仅用于批处理离线脚本 -
symbol这是一个交易对,如BTCUSDT -
分析器参数。这些主要是列名。
-
labels标签列名列表。如果你定义了一个新的用于训练和预测的标签,则需要在这里指定它的名称 -
algorithms用于训练的算法名称列表 -
train_features用于训练和预测的所有输入特征的列名列表
-
-
信号器:
-
buy_labels和sell_labels用于信号的预测列列表 -
trade_model信号器的参数(主要是一些阈值)
-
-
trader是交易参数的部分。目前,这部分尚未彻底测试。 -
collector这个参数部分是为数据收集服务设计的。有两种类型的数据收集服务:定期请求数据提供商的同步服务和订阅数据提供商并在新数据可用时接收通知的异步流式服务。它们可以工作,但尚未彻底测试和集成到主服务中。当前的主要使用模式依赖于手动批量数据更新、特征生成和模型训练。拥有这些数据收集服务的一个原因是 1)更快的更新 2)获取正常 API 中不可用的数据,例如订单簿(存在一些使用这些数据的特征,但它们尚未集成到主工作流程中)。
更多详细信息,请参见示例配置文件和 App.config 中的注释。
Signaler(信号器) 服务
每分钟,信号器执行以下步骤来预测价格是否可能上涨或下跌:
-
从服务器检索最新数据,并更新当前数据窗口(包括一些历史记录,历史长度由配置参数定义)
-
根据最近收集的历史记录计算派生特征(现在包括最新数据)。要计算的特征在配置文件中描述,并且与模型训练期间批量模式中使用的特征完全相同
-
应用几个(预先训练好的)机器学习模型来预测一些未来值(不一定是价格),这些值也被视为(更复杂的)派生特征。我们对几个目标变量(标签)应用几种预测模型(目前有梯度提升、神经网络和线性回归)
-
聚合不同机器学习模型产生的预测结果,并计算最终的信号分数,反映上涨或下跌趋势的强度。这里我们使用许多之前计算的分数作为输入,并推导出一个输出分数。目前,它实现为一个聚合过程,但它也可以基于一个专门的机器学习模型,该模型是在之前收集的分数和目标变量上训练的。正分数表示增长,负分数表示下降
-
使用最终分数进行通知
注意事项:
-
信号器的最终结果是分数(介于-1和+1之间)。分数应与其他参数和数据源结合考虑,用于进一步决定买入或卖出
-
为了让信号器服务运行,需要有训练好的模型并且存储在"MODELS"文件夹中。模型是在批量模式下训练的,相关过程在相应的章节中有描述。
启动服务:python3 -m service.server -c config.json
Trader(交易器)
交易器可以工作,但尚未彻底调试,特别是没有针对稳定性和可靠性进行测试。因此,它应该被视为具有基本功能的原型。它目前与信号器集成在一起,但在更好的设计中应该是独立的服务。