ver 0.1 前言 前面文章我介绍了Cache的基本架构、Cache的详细的结构,有了一定的cache的基础,对cache机制也有了sense。实际上Cache作为CPU架构中存储机制的核心组件和CPU的微架构以及系统的总线架构还是密切相关的,不同的体系下,Cache的类型、使用策略、同步策略也不尽相同。因此,在介绍具体的策略之前,我们还是先花一点时间对不同体系下的Cache类型,多级cache的连接方式等基础性的课题做一下梳理,然后结合具体的体系中Cache对策略展开讨论。本着研究质疑一切,论证一切的精神,我们一起来思考如下几个问题:
(1) 为什么前面cache的相关文章中,有的L2 Cache是多个PE-Core共享的,有的是PE-Core独占的?
(2) 多级cache架构下,为什么Cache Miss的时候,数据要逐级cache传递才能到PE,可不可以跨越传递?
(3) ARMv9的Cache架构和ARMv8是否一致,基于ARMv8的Cortext-A系列的芯片是否Cache架构都是一致的?
(4) 多级Cache是怎么链接在一起的,Cache和外存又是怎么关联到一起的?
(5) CPU读一个数据和写一个数据的时候,不同的策略下,Cache会发生什么事情? 正文 1 多级Cache 前文中我们已经了解到CPU的Cache分为三级L1、L2、L3,实际上随着CPU微架构的迭代,Cache的架构也在不断的向前迭代,所以我们要循着CPU微架构的步伐来介绍多级Cache的升级迭代,我们从一张SOC的架构框图开始多级Cache的架构探索。 1.1 SOC架构 先来简单回顾一下SOC的架构,如图1-1所示,现代芯片已经不是简单的计算单元,特别是在嵌入式领域将多个功能单元(Master)通过一个总线架构连接到一起,既节省物理空间,也降低了功耗,还能够有效提高整个系统的性能。各个Master包括CPU要按照总线架构中的接口(CHI、ACE5-Lite DVM、AXI5、ACE-Lite)规范进行设计和开发,然后通过Coherent interconnect上的接口(CHI、ACE5-Lite DVM、AXI5、ACE-Lite)做接合,就构成一个完整、具备一定功能的SOC。接合本文讨论的主题,自然我们更加关注的Master包括Memory System 、CPU节点(CPU 内部的Memory System)。 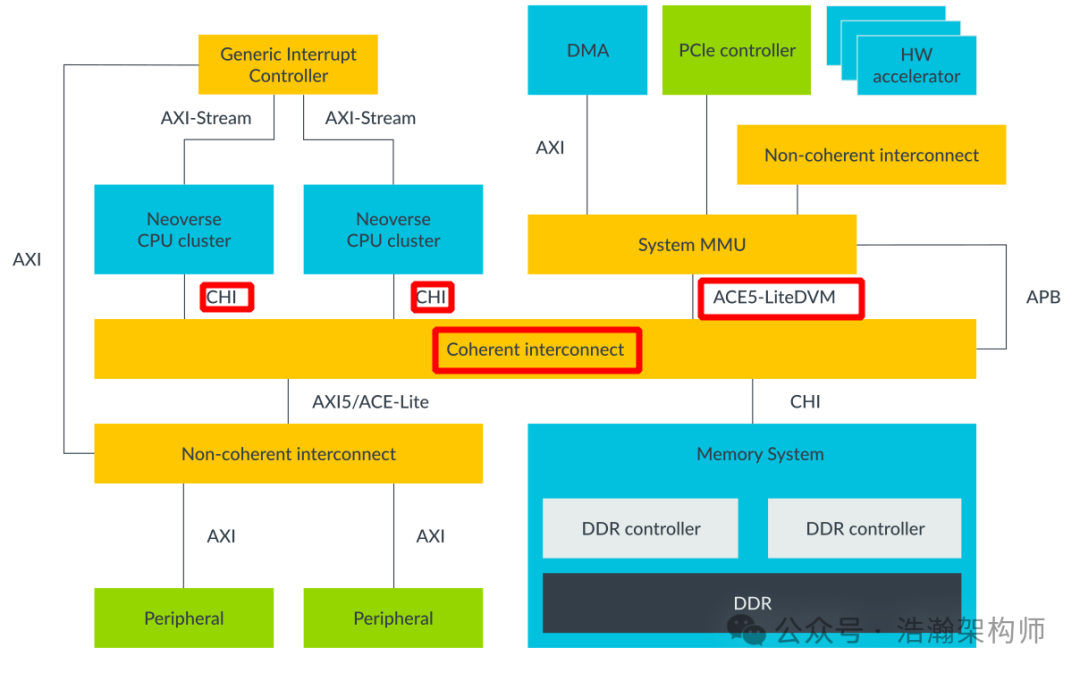
图1-1 典型SOC架构 1.2 总线架构 通过上面的介绍,我们可以看出SOC上各个Master接合的枢纽就是"Coherent interconnect",这个聚合的点就是总线架构,ARM系列的芯片采用的就是高级微控制器总线架构(Advanced Microcontroller Bus Architecture)。AMBA是一个协议簇,不是我们讨论的重点,我们更加关注的是ARM系列芯片设计中的具象化的实例,并通过实例来展现ARM芯片的Memory系统是如何串联到一起的。 1.2.1 缓存⼀致性总线-CCI CCI是ARM架构中用于实现多核处理器之间缓存一致性的关键技术。它通过硬件管理的一致性机制,确保多个处理器核心和其他资源(如GPU、DMA控制器等)在访问共享内存时能够保持数据的一致性,从而提高系统性能和降低功耗。我们看一下手册中描述: The CCI-550 is a programmable high-bandwidth interconnect that enables hardware-coherent systems. Hardware-managed coherency can improve system performance and reduce system power by sharing on-chip data. Managing coherency in hardware has the benefits of: • Reducing external memory accesses. • Reducing the software overhead and complexity. • Enabling use of Arm big.LITTLE ™ processing technology with multiple processor clusters. The CCI-550 is a configurable interconnect that supports connectivity of: • Up to six AMBA 4 ACE masters, such as the Arm Cortex ® -A57 or Cortex-A72 processors. • Up to six AMBA 4 ACE-Lite masters, such as the Arm Mali ™ -T880 Graphics Processing Unit (GPU).
• Up to seven AMBA 4 AXI4 slaves, such as memory and system peripherals. This includes support for up to six memory interfaces.
下面来看一个具体CCI实例,如图1-2所示。 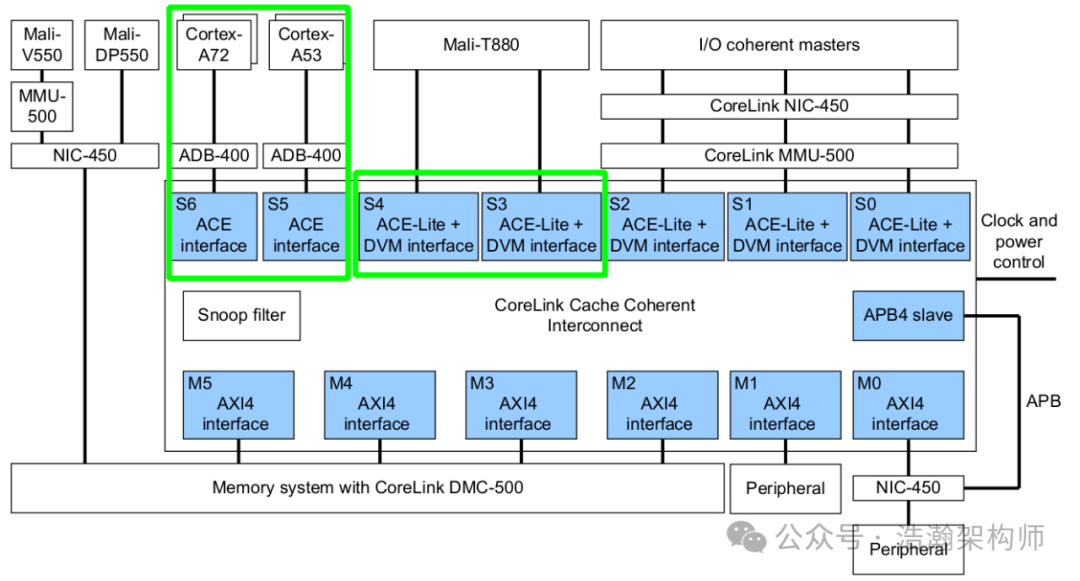
图1-2 CCI实例
通过CCI的实例可以看到外围的Master通过接入缓存一致性总线的接口ACE等接入到了SOC系统,这里就包括Cortex-A72 CPU簇和Cortex-A53 CPU簇。显然Cortex-A系列的微架构内肯定也要支持ACE接口规范才能够和CCI契合,进而才能够连接并接受总线规范约束,后面章节我们会论证这一点。 1.2.2 缓存⼀致性总线-CMN 缓存一致性总线CMN(Coherent Mesh Network)是一种先进的片上网络互连技术,基于Mesh拓扑结构,支持AMBA CHI/ACE-LITE等接口,内部采用路由结构转发数据,提供硬件一致性和系统缓存。旨在提供高性能、低延迟和高可靠性的缓存一致性解决方案。下面摘录手册中对CMN的一些官方介绍: The CMN‑700 product is a scalable configurable coherent interconnect that is designed to meet the Power, Performance, and Area (PPA) requirements for Coherent Mesh Network systems that are used in high-end networking and enterprise compute applications. CMN‑700 is a scalable mesh interconnect with 1-256 processor compute clusters. CMN‑700 supports Arm ® AMBA ® 5 CHI Issue E, including the following features: • MakeReadUnique, writes with optional data, and write zero with no data transactions • Enhanced Exclusive transactions • Various transaction optimizations and enhancements • Connection of devices with multiple interfaces • Connection of devices with replicated channels • Extended TxnID and GroupID • Distributed Virtual Memory (DVM) updates
• Memory tagging
下面来看一个CMN总线的接口,如图1-3所示。 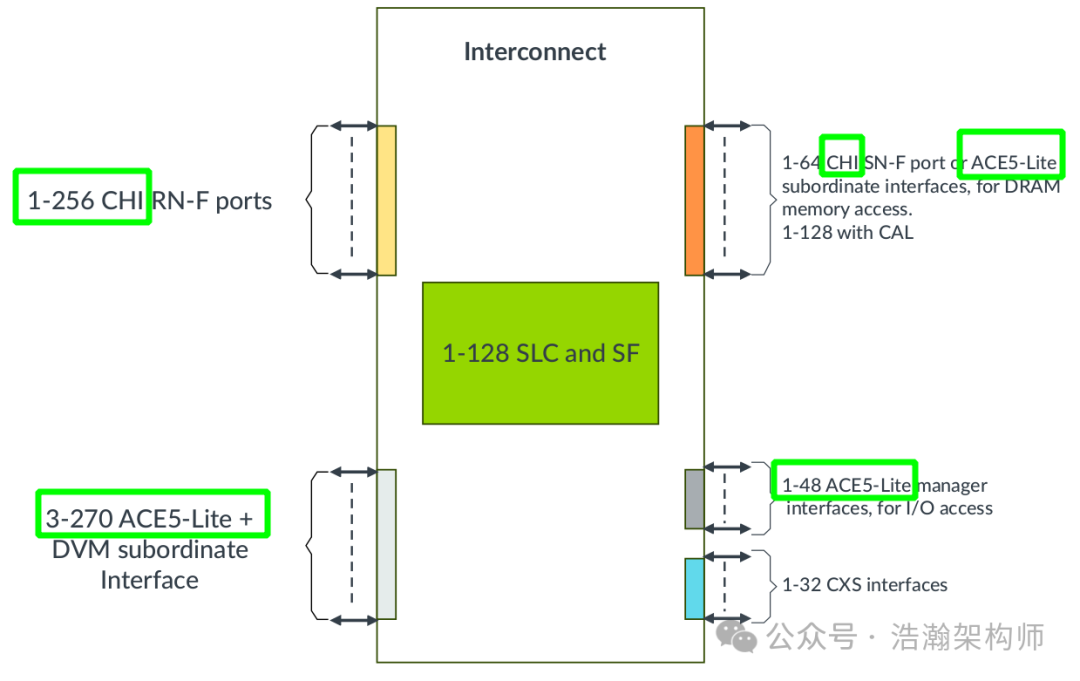
图1-3 CMN接口
通过上图可以看出,CMN的主要作⽤是可以互联多个CHI Master 、 ACE - lite Master ,然后通过CHI接⼝协议,做到多个Master之间的缓存⼀致性。可以看出Master(CPU)要接入CMN总线需要支持CHI或者ACE接口规范,这里后面章节也会具体通过实例进行论证。 1.3 CPU微架构 上面的章节SOC架构、总线架构、总线架构的接口都准备好了,到这里该聊聊总线上功能单元Master了,围绕着本文的主题Cache,这里自然要介绍CPU这个节点。
当然其他总线上的其他Master节点,例如GPU、VPU、aDspc等处理内部微架构中也有Cache,理论上其实和Cortex-A系列是相通的,只不过其他的Master可能是基于Cortex-R、Cortex-M系列的微架构,但这里暂时不展开讨论。1.3.1 big.Little架构 苹果搞出了Iphone之后,移动电子设备迎来了蓬勃发展的黄金时期,研发人员、消费者都是受益者,这里要短暂的停留,致敬一下那些真正的科技产品的先驱。移动电子产品带给人们的便利自然不必细说,但是移动电子产品一直以来的一个问题就是功耗问题,电池的容量毕竟是有限的,所以除了不断加大电池的容量之外,提高电池的使用效率也是无数的研发人员主攻的方向。在这样的背景下,ARM公司采用了Big.Little架构方案。核心的思想如下:
Software can run on big or the LITTLE processors (or both) depending on performance requirements. When peak performance is equired software can be moved to run only on big processors. For normal tasks, software can be run perfectly well on LITTLE processors. Through this combination, big.LITTLE provides a solution capable of delivering the peak performance required by the latest mobile devices, within the thermal bounds of the system, and with maximum energy efficiency.
举例手机上一个音乐app在后台播放音乐,用户在跑步,那么就可以将这个task调度到低功耗的PE-Core上执行,当用户需要玩游戏的时候,由于游戏app需要重度算力需求的时候,这个时候就把游戏task调度到高功耗PE-Core上执行,此时用户会获得更好的使用体验。big.Little的具象场景就在这里。 下面我们看一个具体big.Little架构,如图1-4所示。 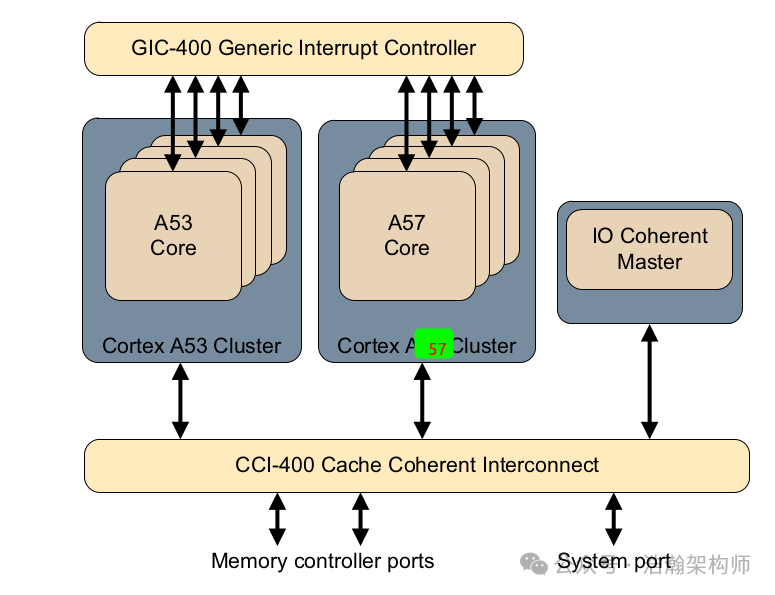
图1-4 典型的big.Little架构
在 big . LITTLE 架构中,⼤核⼩核在不同的cluster中,作为两个不同的ACE或CHI Master,连接到缓存⼀致性总线上(CCI或CMN)。⼤核cluster和⼩核cluster的缓存⼀致性,也需要通过⼀致性总线来解决。big.LittleCluster中的PE-Core是支持可配置的,例如上图中就是小核A53和大核A57组成的两个Cluster。 现在我们需要看一下,这些Cortex-A系列的处理器是如何和总线架构CCI对接的,如图1-5。 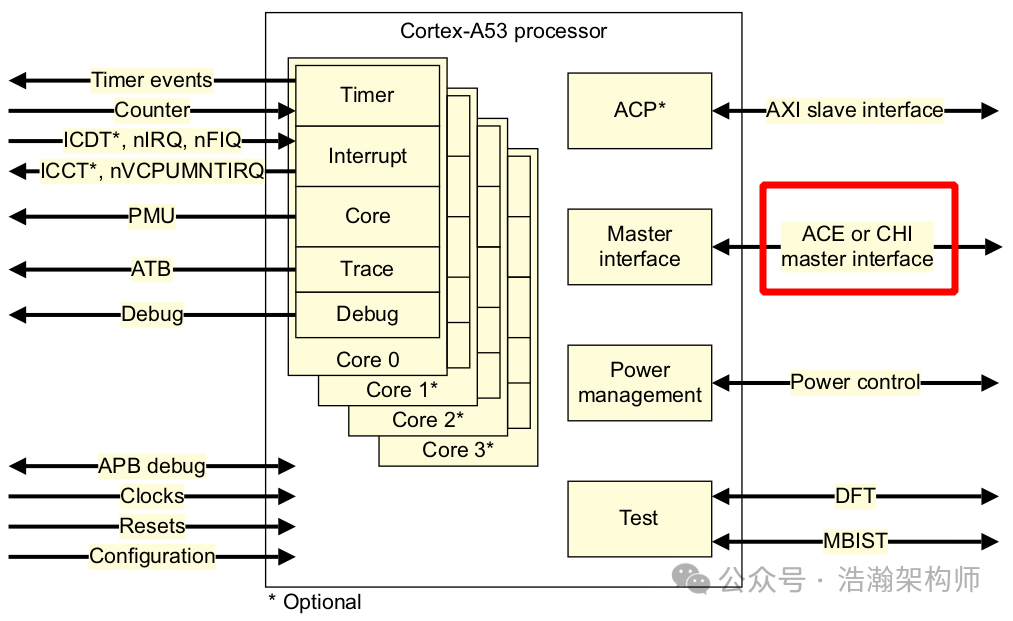
图1-5 A53处理器配置实例
通过图1-5所示,A53处理器配置了ACE或者CHI接口以后,就可以和CCI总线的ACE或者CHI接口对接,进而联接到整个SOC系统中。那么这里我们可以得出一个结论只要是配置的ACE或者CHI接口的处理器都可以接入CCI总线(如图1-6所示),当两个算力有差异的Cluster都连接到SOC系统后,就形成了典型的Big.Little架构。 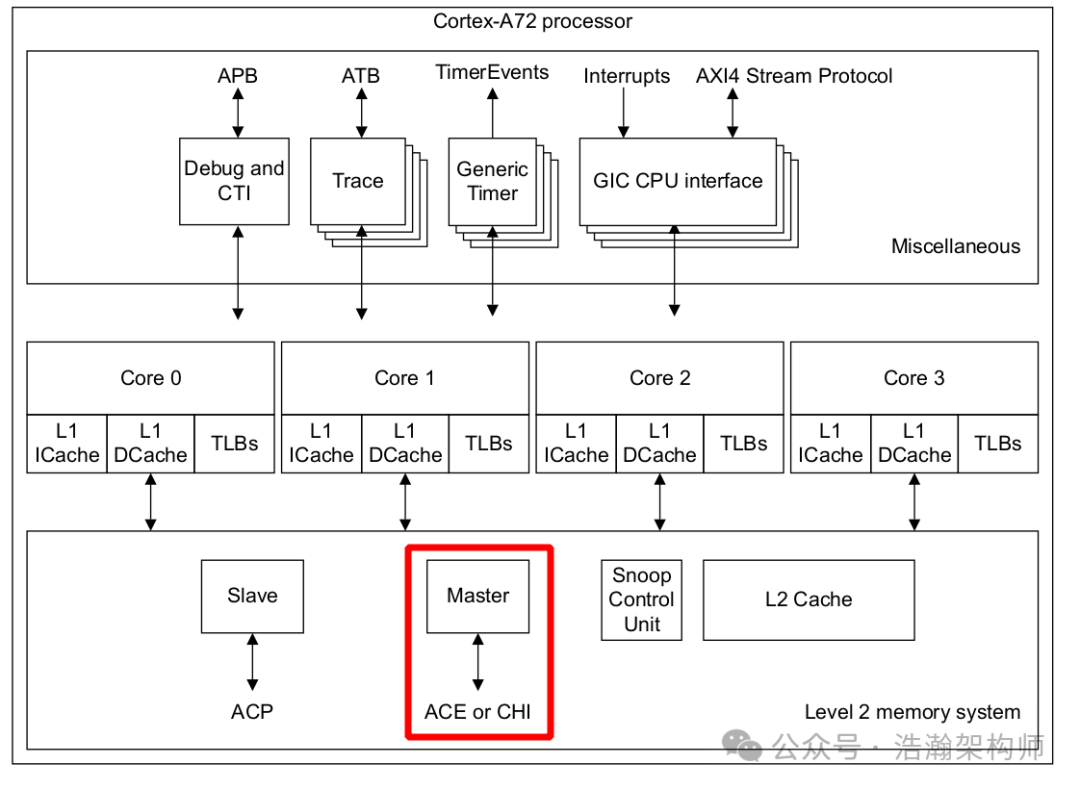
图1-6 A72处理器配置实例
1.3.2 DynamIQ架构 在big.LITTLE架构中,要求big处理器和LITTLE处理器位于不同的cluster内,big处理器cluster和LITTLE处理器cluster通过Cache Coherent Interconnect(CCI)进行数据传输,因此会不可避免地带来传输延迟,引起整体性能下降。于是ARM于2017年3月发布了DynamIQ技术。DynamIQ技术是big.LITTLE技术的升级,两者均为ARM提出的异构处理技术,big.LITTLE技术已经成为了DynamIQ技术的组成部分。与big.LITTLE技术不同,DynamIQ技术支持了将big处理器、LITTLE处理器和DynamIQ Shared Unit (DSU)集成在同一个cluster中,称为DynamIQ cluster,每个芯片可以集成多个DynamIQ cluster;在同一个cluster内,big处理器和LITTLE处理器的数据传输不必依赖big.LITTLE架构中的Cache Coherent Interconnect(CCI)硬件,而是通过DSU中的L3 Cache实现,从而简化了big处理器和LITTLE处理器间任务切换的数据共享复杂度,改善了传输延迟性能,提高了能效。与big.LITTLE技术相比,DynamIQ技术具有以下区别及相应的优势:
(1) 同1个DynamIQ cluster内支持同时集成big处理器和LITTLE处理器,最多集成8个不同种类的处理器,从而使得big处理器和LITTLE处理器的配置数量更加灵活;
(2) 同1个DynamIQ cluster内不同处理器的工作电压和频率可以通过DSU进行单独配置,有利于提高能效;
(3) 在保证高性能的同时,进一步提高了芯片能效。
下面看一个典型的基于DynamIQ的架构的SOC拓扑,如图1-7所示。 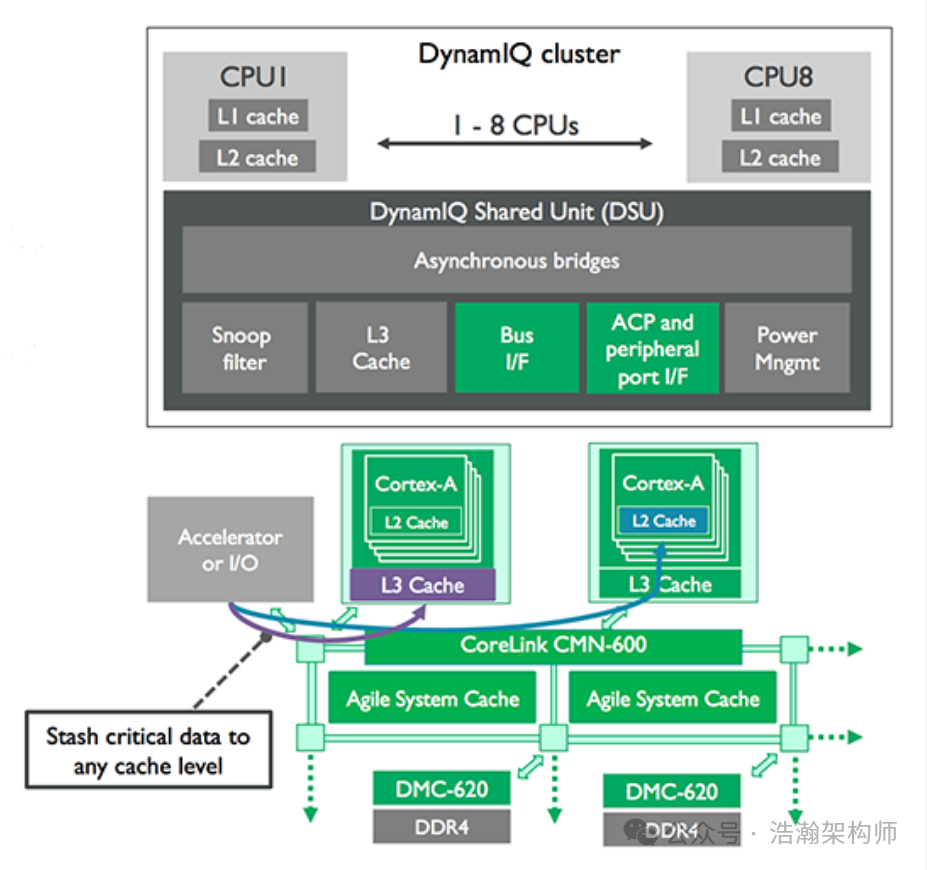
图1-7 典型基于DSU的总线架构
关于DSU的细节我们不展开讨论,这里直接说两个结论:
(1) 缓存一致性总线上(CCI or CMN)上可以接入2个基于DSU架构的CPU Cluster,稍后我们也会从接口层面论证这一结论。
(2) DSU内部的PE-Core支持异构架构,也可以通过Big.Little的方式组合,但是PE-Core数量的上限是8个。
下面我们看一下DSU的接口,来回应下前面遗留的课题,看一下DSU是如何接入到SOC系统总线上的,如图1-8所示。 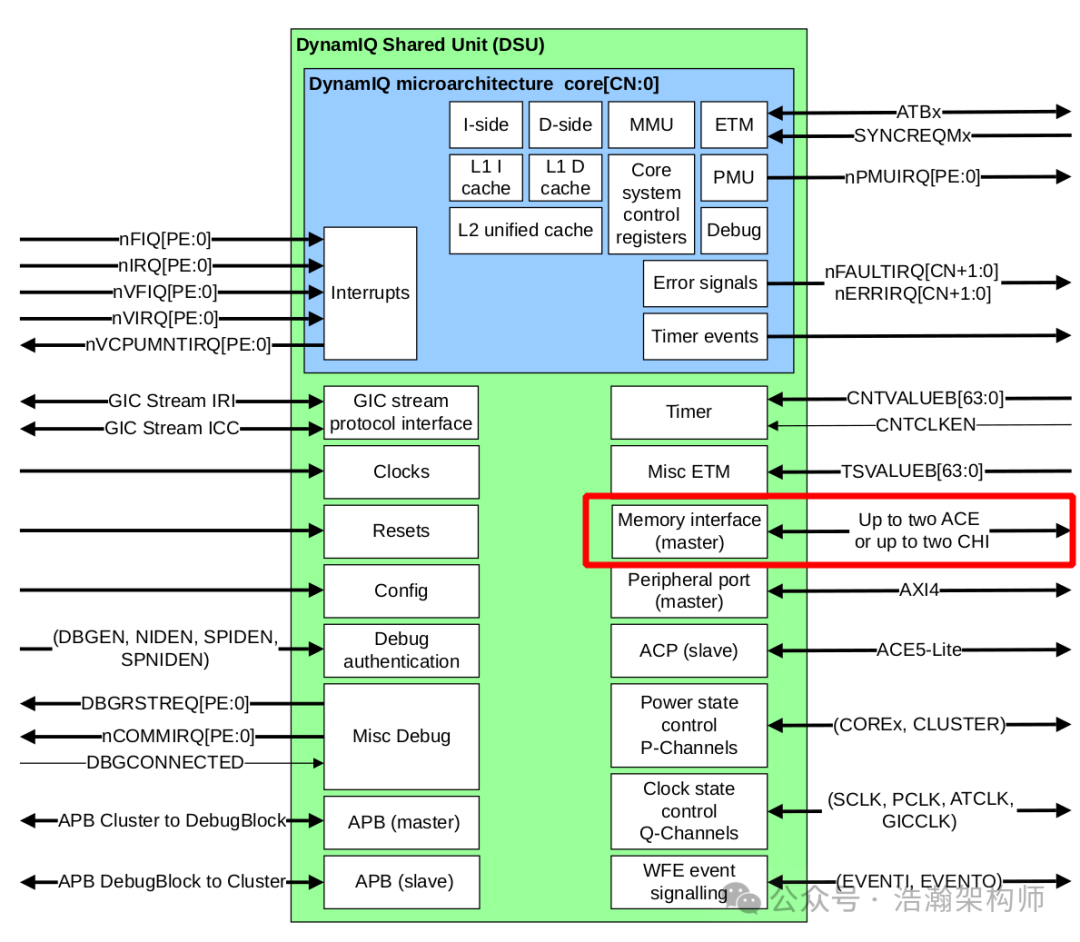
图1-8 典型DSU配置实例
通过上图可以看出DSU配置了ACE或者CHI接口之后,就可以和SOC的缓存一致性总线CCI或者CMN的ACE或者CHI接口契合,最终合入到SOC系统。注意这里的DSU其实是一个封装PE-Core的架构,它的内部还会按照异构架构设计模式自由组合,如图1-9所示。 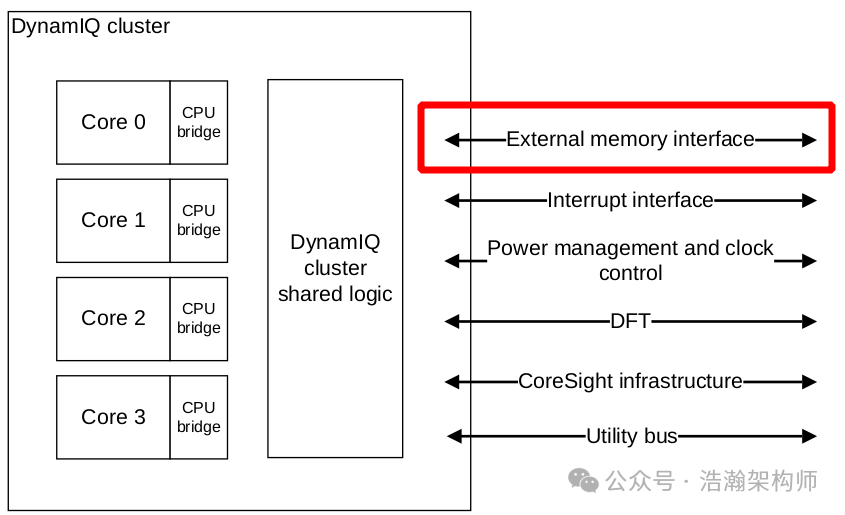
图1-9 Cortex-A710配置实例
这里我们直接引用手册中的描述,介绍一下A710以及其月DSU的关系,可以看出新一代的ARM芯片基本都要依托DSU架构才能工作。 The Cortex ® ‑A710 core is a high-performance, low-power, and constrained area product that implements the Arm ® v9.0-A architecture. The Arm ® v9.0-A architecture extends the architecture defined in the Armv8-A architectures up to Arm ® v8.5-A. The Cortex ® ‑A710 core targets clamshell and premium high-end smartphone applications. The Cortex ® ‑A710 core is implemented inside a DynamIQ ™ -110 cluster and is always connected to the DynamIQ ™ Shared Unit-110 (DSU-110) that behaves as a full interconnect with L3 cache and snoop control. 1.4 多级Cache架构 前面画了很多篇幅介绍了SOC的架构、总线架构、以及CPU的微架构,目的就是想让大家知道多级Cache在不同架构体系下的详细架构以及区别。"大夫的目的很简单,就是想让大家了解它们到底是怎么来的。(80后应该了解这句话的含义,哈哈)"。很多时候,如果不能把背景交代清楚,大家理解起来还是有困难的,总是觉得心里发虚的,所以我们花费一点笔墨是值得的。这里我们把Big.Little和DynamIQ架构下的多级Cache架构捏合在一起看,如图1-10、图1-11所示。 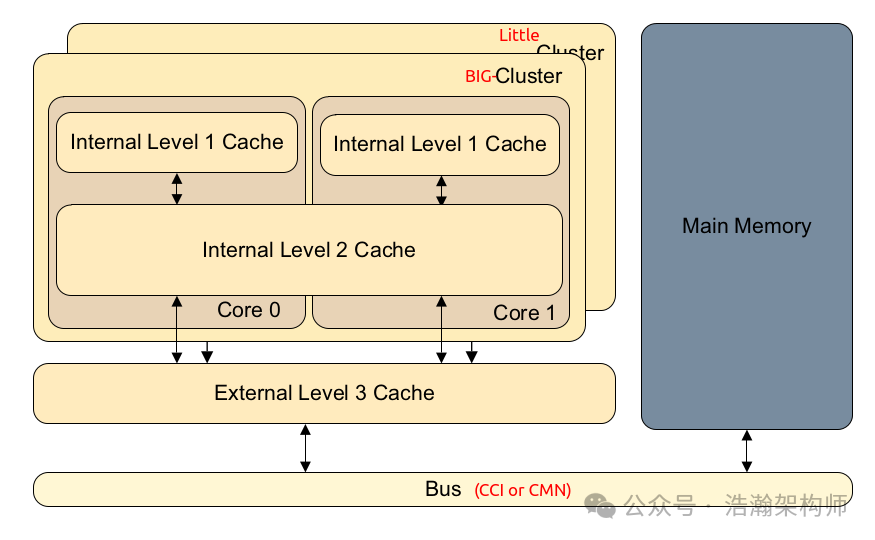 图1-10 Big.Little架构下的多级Cache
图1-10 Big.Little架构下的多级Cache 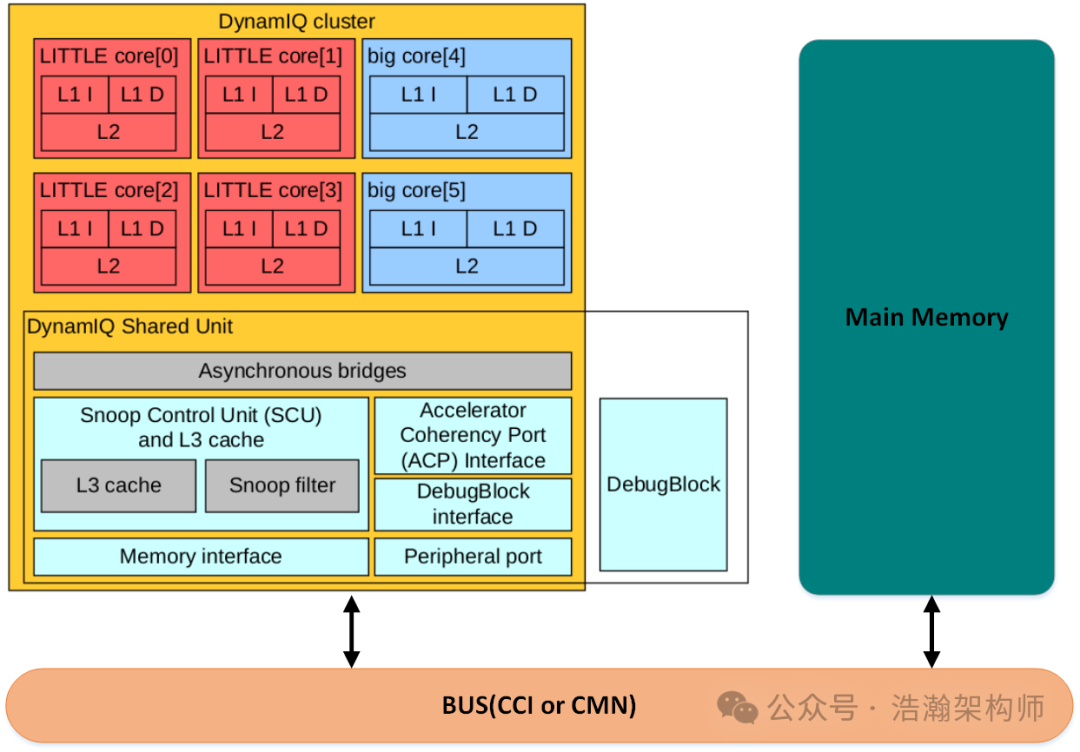 图1-11 DSU架构下的多级Cache 通过上面两图的展示和对比,我们可以总结归纳一下ARM体系下到目前为止的多级Cache的特征如下: (1) 传统的Big.Little架构和DynamIQ架构下,无论PE-Core怎么分簇,都支持3级Cache架构(L1、L2、L3)。(其实L3在工程实践中是可选的,但是省下这一层cache硬件,就要花费更多的指令周期去做不同的CPU Cluster的数据同步。) (2) 在Big.Little的架构中,L1是在core中的,是core私有的;L2是在cluster中的,对cluster中的core是共享的;L3则对所有cluster共享。 (3) 在DynamIQ的架构中,L1和L2都在core中的,都是core私有的;L3则是在cluster中的,对cluster中的core是共享的;如有L3或system cache,则是所有cluster共享。 搞清楚了多级Cache的架构之后,我们还不能停止步伐,下面来看两款具体的CPU实例来印证我们的结论。 基于Big.Little的PE-Core 多级Cache实例 通过图1-12,我们能够清晰的看到,早期的A72芯片的L2Cache是各个PE-Core共享的,而L1级别的Cache是各个PE-Core独立,而且分成了指令Cache和数据Cache。从手册中摘录一下Cache的特征信息: The Cortex-A72 processor includes the following features: • Dynamic branch prediction with Branch Target Buffer (BTB) and Global History Buffer (GHB) • RAMs, a return stack, and an indirect predictor. • 48-entry fully-associative L1 instruction Translation Lookaside Buffer (TLB) with native support for 4KB, 64KB, and 1MB page sizes. • 32-entry fully-associative L1 data TLB with native support for 4KB, 64KB, and 1MB page sizes. • 4-way set-associative unified 1024-entry Level 2 (L2) TLB in each processor. • Fixed 48K L1 instruction cache and 32K L1 data cache. • Shared L2 cache of 512KB, 1MB, 2MB or 4MB configurable size. • Optional Error Correction Code (ECC) protection for L2 cache, and optional ECC protection for L1 data cache and parity protection for L1 instruction cache. • AMBA 4 AXI Coherency Extensions (ACE) or CHI master interface.
图1-11 DSU架构下的多级Cache 通过上面两图的展示和对比,我们可以总结归纳一下ARM体系下到目前为止的多级Cache的特征如下: (1) 传统的Big.Little架构和DynamIQ架构下,无论PE-Core怎么分簇,都支持3级Cache架构(L1、L2、L3)。(其实L3在工程实践中是可选的,但是省下这一层cache硬件,就要花费更多的指令周期去做不同的CPU Cluster的数据同步。) (2) 在Big.Little的架构中,L1是在core中的,是core私有的;L2是在cluster中的,对cluster中的core是共享的;L3则对所有cluster共享。 (3) 在DynamIQ的架构中,L1和L2都在core中的,都是core私有的;L3则是在cluster中的,对cluster中的core是共享的;如有L3或system cache,则是所有cluster共享。 搞清楚了多级Cache的架构之后,我们还不能停止步伐,下面来看两款具体的CPU实例来印证我们的结论。 基于Big.Little的PE-Core 多级Cache实例 通过图1-12,我们能够清晰的看到,早期的A72芯片的L2Cache是各个PE-Core共享的,而L1级别的Cache是各个PE-Core独立,而且分成了指令Cache和数据Cache。从手册中摘录一下Cache的特征信息: The Cortex-A72 processor includes the following features: • Dynamic branch prediction with Branch Target Buffer (BTB) and Global History Buffer (GHB) • RAMs, a return stack, and an indirect predictor. • 48-entry fully-associative L1 instruction Translation Lookaside Buffer (TLB) with native support for 4KB, 64KB, and 1MB page sizes. • 32-entry fully-associative L1 data TLB with native support for 4KB, 64KB, and 1MB page sizes. • 4-way set-associative unified 1024-entry Level 2 (L2) TLB in each processor. • Fixed 48K L1 instruction cache and 32K L1 data cache. • Shared L2 cache of 512KB, 1MB, 2MB or 4MB configurable size. • Optional Error Correction Code (ECC) protection for L2 cache, and optional ECC protection for L1 data cache and parity protection for L1 instruction cache. • AMBA 4 AXI Coherency Extensions (ACE) or CHI master interface. 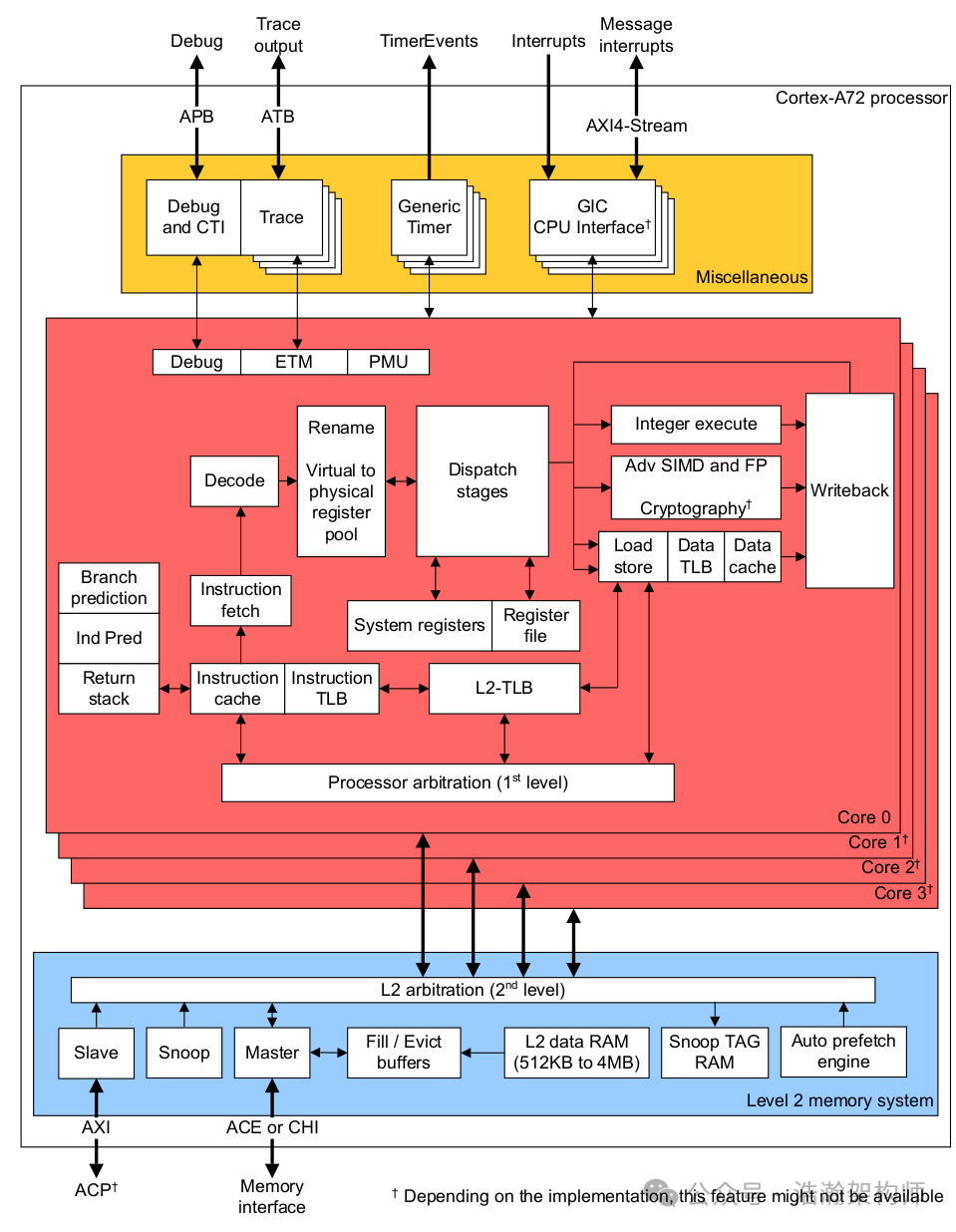 图1-12 Cortex-A72 功能框图 基于DSU的PE-Core多级Cache实例 通过1-12,可以看出到了ARMv9的时代,比较新的芯片的L1和L2级别的Cache都变成PE-Core私有的了。这里同样摘录手册中对Cache相关Feature的描述: Cache features • Separate L1 data and instruction caches • Private, unified data and instruction L2 cache • Error protection on L1 instruction and data caches, L2 cache, and MMU Translation Cache (MMU TC) with parity or Error Correcting Code (ECC) allowing Single Error Correction and Double Error Detection (SECDED) • Support for Memory System Resource Partitioning and Monitoring (MPAM)
图1-12 Cortex-A72 功能框图 基于DSU的PE-Core多级Cache实例 通过1-12,可以看出到了ARMv9的时代,比较新的芯片的L1和L2级别的Cache都变成PE-Core私有的了。这里同样摘录手册中对Cache相关Feature的描述: Cache features • Separate L1 data and instruction caches • Private, unified data and instruction L2 cache • Error protection on L1 instruction and data caches, L2 cache, and MMU Translation Cache (MMU TC) with parity or Error Correcting Code (ECC) allowing Single Error Correction and Double Error Detection (SECDED) • Support for Memory System Resource Partitioning and Monitoring (MPAM) 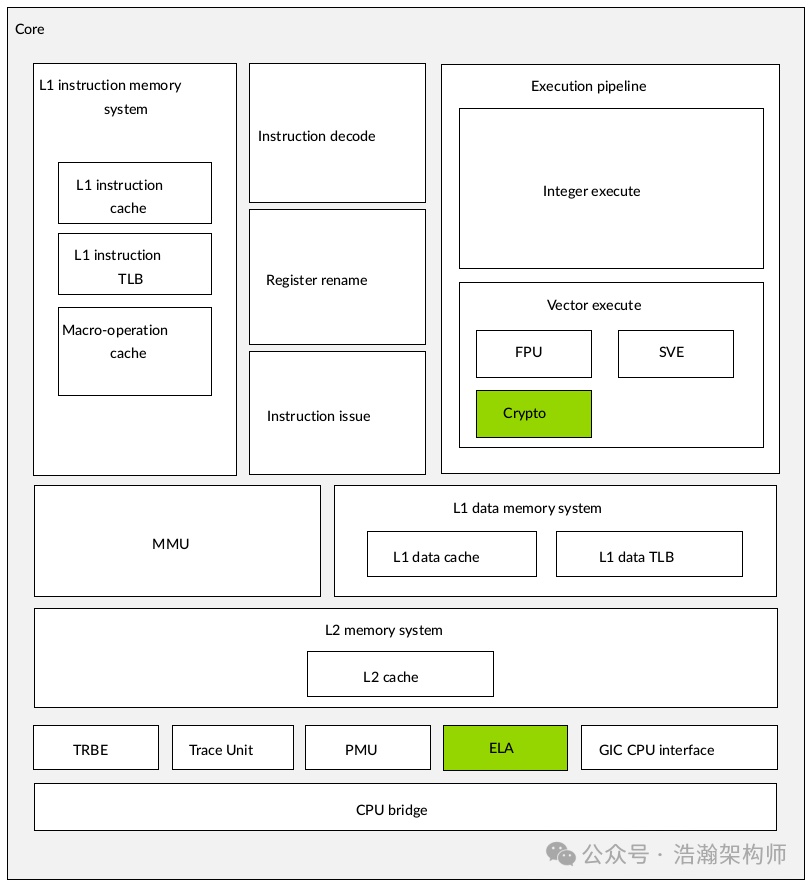
图1-13 Cortex-A710 功能框图
结语 这一篇文章创作的时候,开始只想讲讲Cache的策略,但是写着写着觉得有必要把Cache的多级架构的演变也写一写,于是推到重来,重新扎进手册里和前辈的文章里面,目的一方面就是对Cache的机制有更加全面深入的了解,才能理解与软件相关的Cache策略和接口的设计初衷。 本篇,我们以几个问题的思考开始,带大家从一个SOC的架构一直到多级Cache的诞生的过程,做了一个全景的展示,为我们后续的Cache策略和一致性的学习打下了基础。 谢谢大家,坚持到了这里,预计还有两篇文章,完成我们的Cache之旅。 Reference [01] <DDI0487K_a_a-profile_architecture_reference_manual.pdf> [02] <DEN0024A_v8_architecture_PG.pdf> [03] <80-LX-MEM-yk0008_CPU-Cache-RAM-Disk关系.pdf> [04] <80-ARM-ARCH-HK0001_一文搞懂CPU工作原理.pdf> [05] <80-ARM-MM-Cache-wx0003_Arm64-Cache.pdf> [06] <80-ARM-MM-HK0002_一文搞懂cpu-cache工作原理.pdf> [07] <80-MM-yd0001_Caches-From-a-Mostly-OS-Software-Perspective.pdf> [08] <80-MM-yd0002_Improving-Kernel-Performance-by-Unmapping-the-Page-Cache.pdf> [09] <arm_cortex_a710_core_trm_101800_0201_07_en.pdf> [10] <DDI0608B_a_armv9a_supplement_RETIRED.pdf> [11] <arm_cortex_a520_core_trm_102517_0003_06_en.pdf> [12] <arm_cortex_a720_core_trm_102530_0002_05_en.pdf> [13] <79-LX-LK-z0002_奔跑吧Linux内核-V-2-卷1_基础架构.pdf> [14] <80-ARM-MM-Cache-wx0001_Cache多核之间的一致性MESI.pdf> [15] <80-ARM-MM-Cache-wx0002_深度学习armv8_armv9_cache的原理.pdf> [16] <80-ARM-MM-Cache-ym0001_带着几个疑问-从Cache的应用场景学起.pdf> [17] <80-ARM-MM-Cache-ym0002_Cache是如何工作的-概念以及工作过程.pdf> [18] <80-ARM-MM-Cache-ym0003_多核多Cluster多系统之间的缓存一致性.pdf> [19] <DDI0500J_cortex_a53_trm.pdf> [20] <DDI0488H_cortex_a57_mpcore_trm.pdf> [21] <cortex_a72_mpcore_trm_100095_0003_06_en.pdf> [22] <corelink_cci550_cache_coherent_interconnect_technical_reference_manual_en.pdf> [23] <80-ARM-DyIQ-wx0001_ARM架构系列(2)-DynamIQ技术.pdf> [24] <ARM_DynamIQ_The_future_of_multi-core_computing.pdf> [25] <cortex_a72_mpcore_trm_100095_0003_06_en.pdf>
[26] <arm_cortex_a710_core_trm_101800_0201_07_en.pdf>Glossary SRAM - Static Random-Access Memory DRAM - Dynamic Random Access Memory SSD - Solid state disk HDD - Hard Disk Drive SOC - System on a chip AMBA - Advanced Microcontroller Bus Architecture 高级处理器总线架构 TLB - translation lookaside buffer(地址变换高速缓存) VIVT - Virtual Index Virtual Tag PIPT - Physical Index Physical Tag VIPT - Virtual Index Physical Tag AHB - Advanced High-performance Bus 高级高性能总线 ASB - Advanced System Bus 高级系统总线 APB - Advanced Peripheral Bus 高级外围总线 AXI - Advanced eXtensible Interface 高级可拓展接口 DSU - DynamIQ Share Unit ACE - AXI Coherency Extensions CHI - Coherent Hub Interface 一致性集线器接口 CCI - Cache Coherent Interconnect ADB - AMBA Domain Bridge CMN - Coherent Mesh Network







