一、引言
在当前人工智能的发展中,大型语言模型(LLMs)已成为NLP研究和应用的关键。Qwen2-7B模型作为领域的领先者,以其巨大的参数量和强大的功能获得了广泛注意,尤其是它在经过微调后能更好地完成特定任务。本文旨在详述如何运用LLaMA-Factory框架高效微调Qwen2-7B模型,以优化其在特定任务中的表现。
**二、**LLaMA-Factory 简介
LLaMA-Factory是一个集多种微调技术于一身的高效框架 ,支持包括Qwen2-7B在内的多种大型语言模型。它通过集成如LoRA、QLoRA等先进的微调算法,以及提供丰富的实验监控工具,如LlamaBoard、TensorBoard等,为用户提供了一个便捷、高效的微调环境。此外,LLaMA-Factory还支持多模态训练方法和多硬件平台,包括GPU和Ascend NPU,进一步拓宽了其应用范围。

三、安装 modelscope
在国内,由于网络环境的特殊性,直接从国际知名的模型库如Hugging Face下载模型可能会遇到速度慢或连接不稳定的问题。为了解决这一问题,我们选择使用国内的ModelScope平台作为模型下载的渠道。ModelScope不仅提供了丰富的模型资源,还针对国内用户优化了下载速度。 修改模型库为modelscope * * *
export USE_MODELSCOPE_HUB=1
修改模型缓存地址,否则默认会缓存到/root/.cache,导致系统盘爆满export MODELSCOPE_CACHE=/root/autodl-tmp/models/modelscope
学术资源加速 *
source /etc/network_turbo
安装modelscope(用于下载modelscope的相关模型) *
pip install modelscope
四、模型下载
在下载Qwen2-7B模型之前,我们首先需要设置modelscope的环境变量,确保模型能够被正确地缓存到指定的路径,避免因为默认路径导致的空间不足问题。接下来,通过编写一个简单的Python脚本,我们可以使用modelscope的API来下载所需的模型。
使用 modelscope 中的 snapshot_download 函数下载模型,第一个参数为模型名称,参数 cache_dir 为模型的下载路径。 * * * * *
from modelscope import snapshot_downloadmodel_dir = snapshot_download('qwen/Qwen2-7B',cache_dir='/root/autodl-tmp',revision='master')
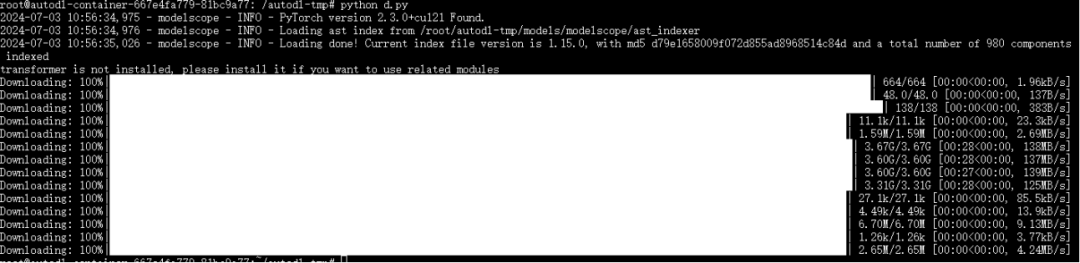
运行python /root/autodl-tmp/d.py 执行下载;执行完成如下:
五、安装LLaMA-Factory
LLaMA-Factory的安装过程相对简单,通过Git克隆仓库后,使用pip安装即可。这一步骤是整个微调流程的基础,为后续的操作提供了必要的工具和库。
*
*
*
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.gitcd LLaMA-Factorypip install -e ".[torch,metrics]"
六、启动 LLaMA-Factory
在LLaMA-Factory安装完成后,我们可以通过简单的命令启动其Web UI界面。这一界面提供了一个用户友好的操作环境,使得微调过程更加直观和便捷。 修改gradio默认端口
*
export GRADIO_SERVER_PORT=6006
启动LLaMA-Factory *
llamafactory-cli webui
启动如下:
 七、LLaMA-Factory 操作实践
七、LLaMA-Factory 操作实践
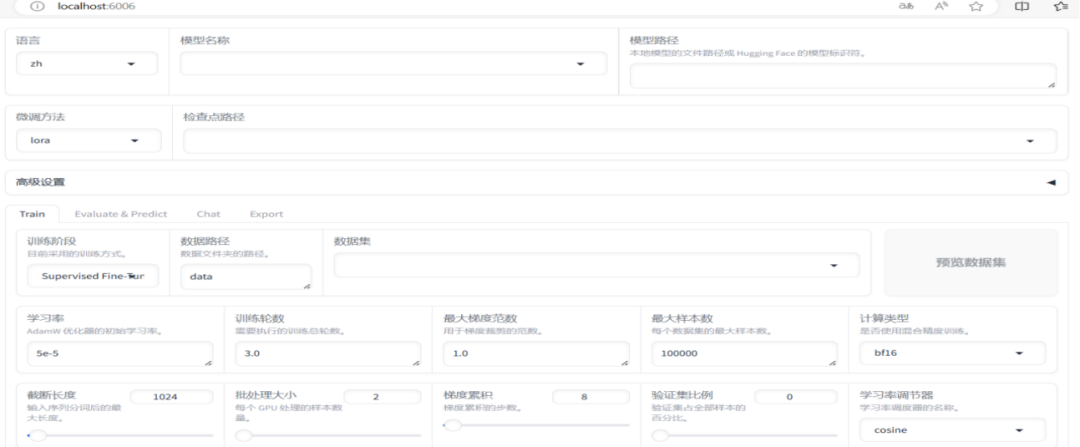
1、访问UI界面
http://localhost:6006/
通过访问Web UI,用户可以进行模型的配置、训练参数的设置以及微调过程的监控。
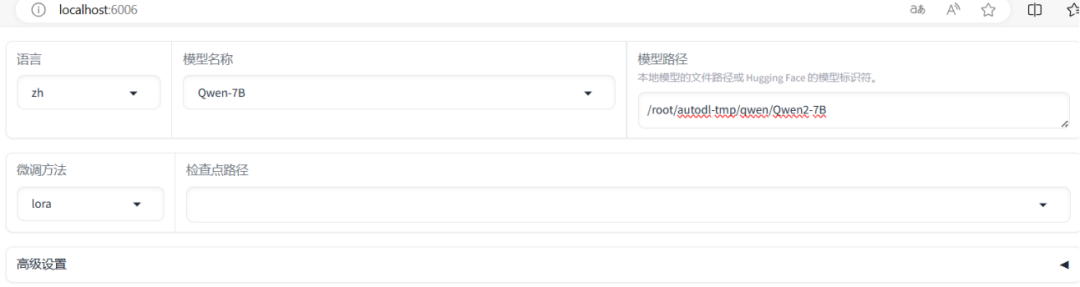
2、配置模型本地路径
在UI界面中,用户可以根据自己的需求选择模型来源,无论是直接使用Hugging Face模型库中的资源,还是加载本地下载的模型。
 3、微调相关配置 微调配置是整个流程中至关重要的一步。用户需要根据具体的任务需求,设置训练阶段、数据集、学习率、批次大小等关键参数。
3、微调相关配置 微调配置是整个流程中至关重要的一步。用户需要根据具体的任务需求,设置训练阶段、数据集、学习率、批次大小等关键参数。
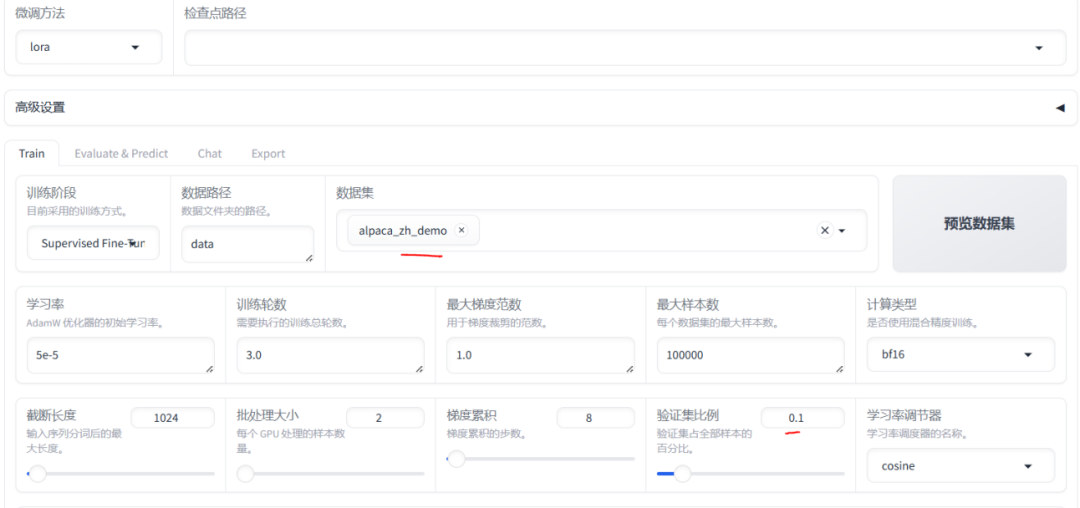 4、预览训练参数 在开始训练之前,用户可以预览所有的训练参数,确保配置无误。
4、预览训练参数 在开始训练之前,用户可以预览所有的训练参数,确保配置无误。
点击"预览命令"按钮,查看训练的参数配置,可以进行手工修改调整
|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------| | llamafactory-cli train \ --stage sft \ --do_train True \ --model_name_or_path /root/autodl-tmp/qwen/Qwen2-7B \ --preprocessing_num_workers 16 \ --finetuning_type lora \ --quantization_method bitsandbytes \ --template default \ --flash_attn auto \ --dataset_dir data \ --dataset alpaca_zh_demo \ --cutoff_len 1024 \ --learning_rate 5e-05 \ --num_train_epochs 3.0 \ --max_samples 100000 \ --per_device_train_batch_size 2 \ --gradient_accumulation_steps 8 \ --lr_scheduler_type cosine \ --max_grad_norm 1.0 \ --logging_steps 5 \ --save_steps 100 \ --warmup_steps 0 \ --optim adamw_torch \ --packing False \ --report_to none \ --output_dir saves/Qwen-7B/lora/train_2024-07-03-11-30-41 \ --bf16 True \ --plot_loss True \ --ddp_timeout 180000000 \ --include_num_input_tokens_seen True \ --lora_rank 8 \ --lora_alpha 16 \ --lora_dropout 0 \ --lora_target all \ --val_size 0.1 \ --eval_strategy steps \ --eval_steps 100 \ --per_device_eval_batch_size 2 |
5、开始训练
一旦确认配置无误,用户可以启动训练过程。LLaMA-Factory将根据用户的配置进行模型的微调。 点击"开始"按钮,开始训练 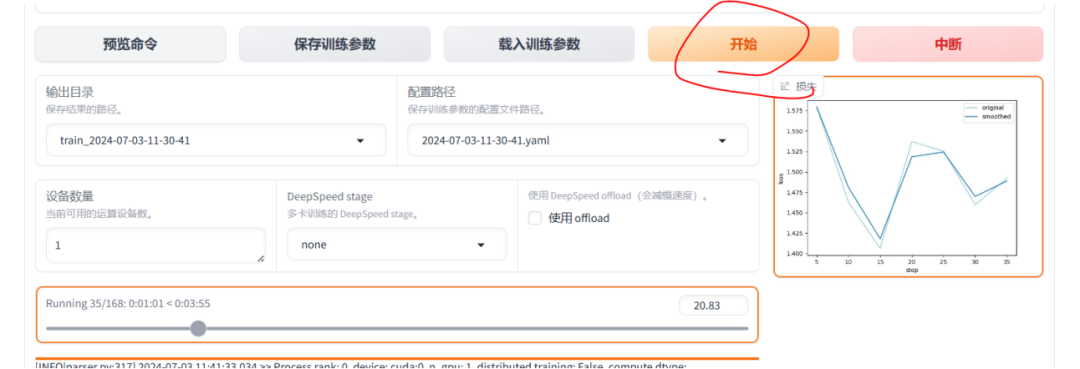
训练完成结果如下:
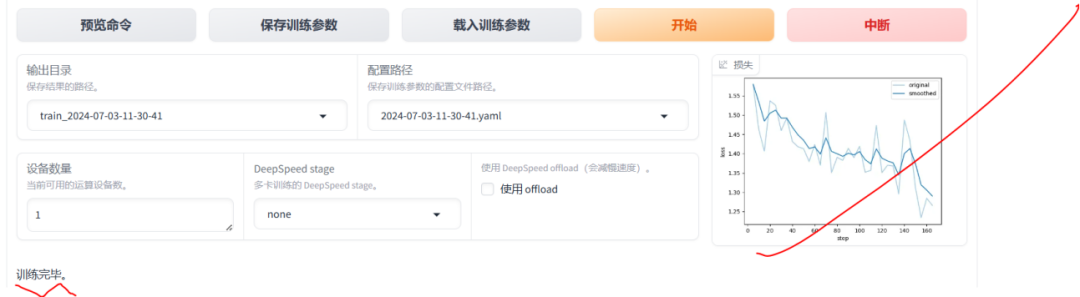
训练完成后,会在本地输出微调后的相关权重文件,Lora权重文件输出如下:
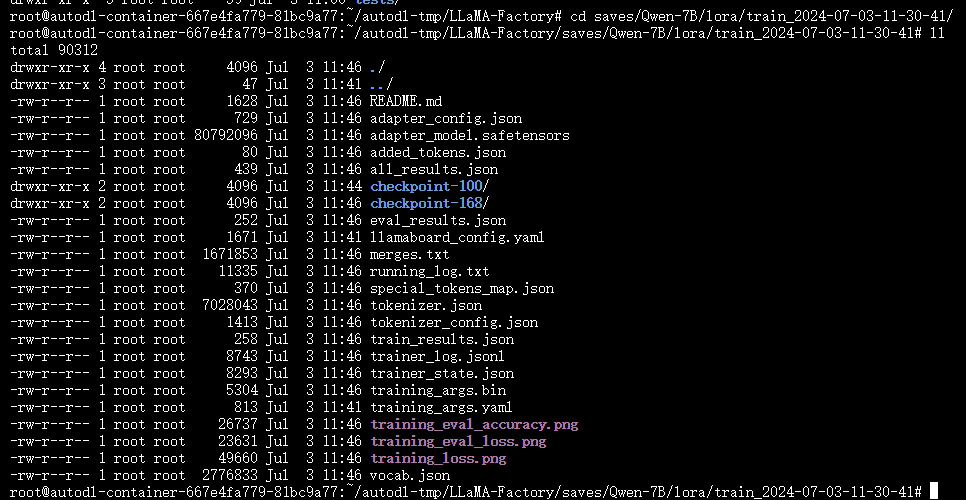
6、模型加载推理
在高级设置中有一个"Chat"页签,可用于模型推理对话
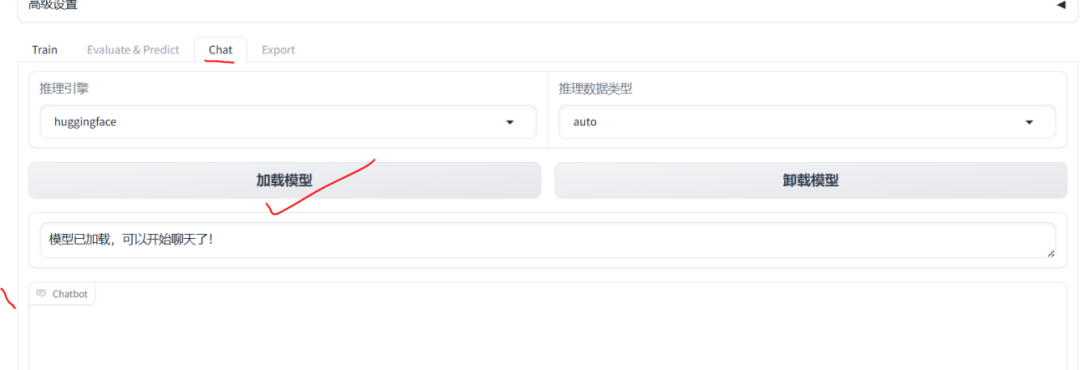 模型对话
模型对话 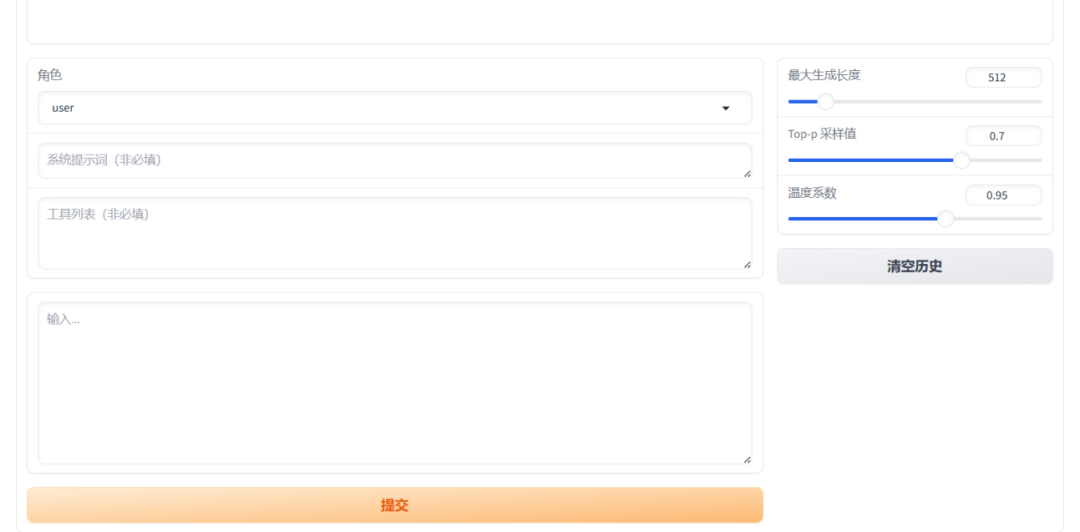 7、模型合并导出 模型训练完成后,我们可以将训练完后的Lora相关权重文件,和基础模型进行合并导出生成新的模型
7、模型合并导出 模型训练完成后,我们可以将训练完后的Lora相关权重文件,和基础模型进行合并导出生成新的模型
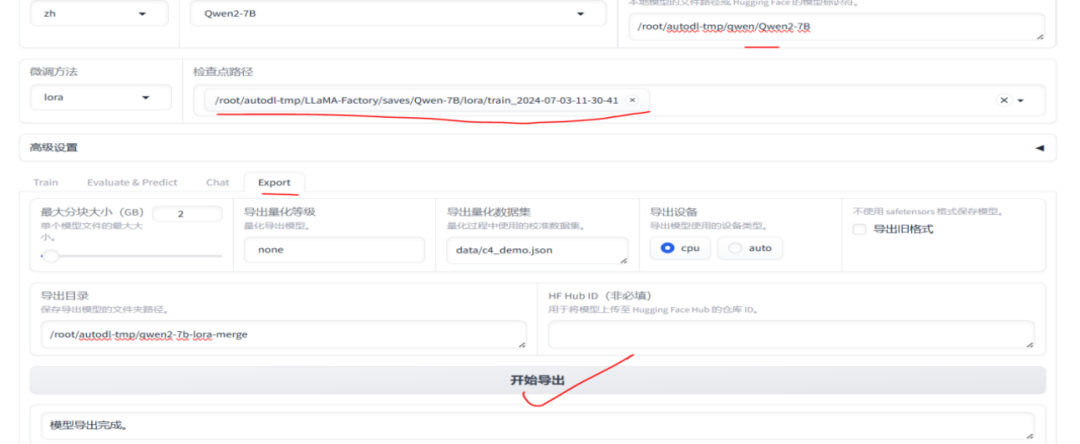 合并后模型文件如下:
合并后模型文件如下: 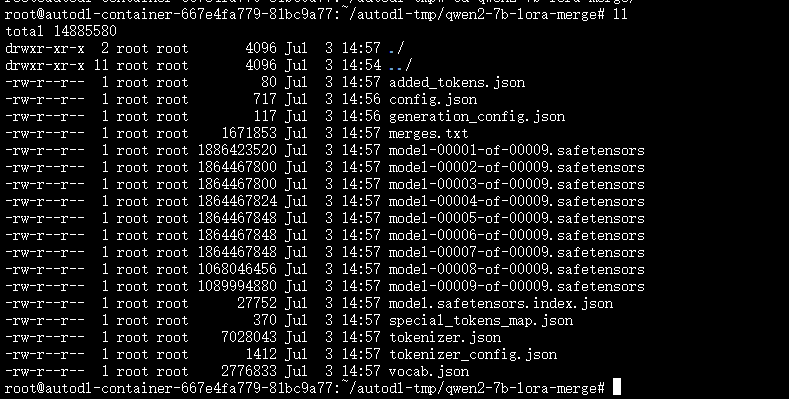
导出后我们可以基于导出后的新模型进行推理对话。
八、结语
通过本文的详细介绍,大家应该对如何使用LLaMA-Factory对Qwen2-7B进行微调有了清晰的认识。微调不仅能够提升模型在特定任务上的表现,还能够为模型赋予更加丰富的应用场景。希望本文能够为大家在大型语言模型的微调实践中提供有价值的参考和指导。随着技术的不断进步,我们期待LLaMA-Factory和Qwen2-7B能够在未来的AI领域发挥更大的作用。