- 引言 {#引言} ===========
1.1. 爬虫与NoSQL {#爬虫与nosql}
Python爬虫是一种通过模拟浏览器行为,从互联网上自动抓取数据的工具。它利用 Python 的多种网络请求库(如 requests、urllib 等)和 HTML 解析工具(如 BeautifulSoup、lxml、Scrapy 等)对网页内容进行访问和解析,将所需信息提取为结构化数据。
NoSQL(Not Only SQL)是一类不同于传统关系型数据库(RDBMS)管理系统的数据存储技术的统称。它主要的特点是具有灵活的架构、高性能和易扩展性;非常适合处理大规模的非结构化或半结构化的数据。
通俗解释:NoSQL 和 MySQL 的区别
如果把数据库比作仓库,MySQL 就像一个整齐划一的大型货架,每件商品(数据)都必须分类放在固定的格子里,存进去之前要先规划好架子怎么摆、格子多大、每个格子装什么。如果商品不符合规则,可能还要重新整理才能存进去。
而 NoSQL 就像一个杂物间,虽然没有固定的架子和分类,但只要有地方,就能随时放东西,而且你可以把东西装在各种不同大小的盒子里,甚至直接堆起来。这让它特别适合存储种类繁多、形状不一的东西,比如图片、文字、视频等,或者需要快速放进去、快速取出来的情况。
简单说,区别是:
- **MySQL(传统关系型数据库):**有严格的规则,需要提前设计好表格(类似架子),适合整理整齐的结构化数据,比如用户表、订单表。
- **NoSQL(非关系型数据库):**规则很灵活,没有固定表格,适合存储多样化、不固定的数据,比如社交网络的动态、实时传感器数据等。
如果你的数据像"表格"一样整齐有序,用 MySQL;如果你的数据更像"杂货"或者需要快速扩展,用 NoSQL。
Python爬虫为什么使用 NoSQL
爬取的数据往往结构不一致。例如,不同网页中的字段可能有所不同。NoSQL 数据库支持 JSON 或类似的文档格式存储数据(如 MongoDB),使得存储非结构化和半结构化数据变得简单,无需频繁更改数据库的模式。另外就是 NoSQL 数据库设计为分布式系统,支持大规模数据的高效读写操作。某些爬虫任务可能会产生海量数据。NoSQL 数据库通常支持水平扩展(Scale-out),通过增加节点扩展存储和处理能力,而传统关系型数据库的扩展则较为复杂。
当然,不同的业务场景也要选择不同类型的 NoSQL 数据库,例如:
- MongoDB:适合存储和查询 JSON 文档数据。
- Redis:适合缓存和实时数据处理。
- Elasticsearch:适合全文检索和分析爬取的数据。
1.2. Amazon DynamoDB简介 {#amazon-dynamodb简介}
Amazon DynamoDB 是亚马逊云科技提供的一种完全托管型的 NoSQL 数据库服务,属于 键值存储和文档数据库 类型的组合。它被设计用于高吞吐量和低延迟的应用场景,支持水平扩展,是 NoSQL 数据库的一个典型实现。
【官方地址】 :什么是 Amazon DynamoDB?
-
怎么理解键值存储和文档数据库?
键值存储(Key-Value Store)可以理解为一个"超级词典"或者"超级储物柜",通过"键"(Key)快速找到对应的"值"(Value)。
Key:是唯一的标识,类似于储物柜的编号。
Value:是与 Key 关联的数据,类型可以是字符串、数字、JSON 对象,甚至是图片等文件。
键值存储中没有复杂的结构,也没有表格的概念,所有数据以"键值对"的形式存储。
假设要存储一个用户的名字和年龄:
-
键值存储的方式:
Key: "user:001:name", Value: "张三" Key: "user:001:age", Value: 25只要知道键(比如
"user:001:name"),就能直接获取对应的值("张三")。 -
传统数据库的方式:
必须用表格形式存储:| 用户ID | 姓名 | 年龄 | |--------|----------|------| | 001 | 张三 | 25 |然后写 SQL 查询语句
SELECT 姓名 FROM 用户表 WHERE 用户ID='001'才能找到值。
如果把传统数据库比作"Excel 表格",文档数据库就像一个"文件夹",里面装的是类似 Word 文档的结构化内容,比如一个产品的详细信息、一个用户的个人资料等。这些内容以 JSON 或 XML 格式存储,就像一篇篇灵活的电子文档。
-
传统数据库(比如 MySQL):
数据是"表格状"的,每一行是一个记录,每一列代表固定的字段(比如用户的姓名、邮箱)。需要提前设计表格格式(叫做"表结构")。比如一个用户表,需要先定义一个表格(比如叫users),然后每条数据都必须按照同样的字段存储:| 用户ID | 姓名 | 年龄 | 兴趣爱好 | |--------|---------|-----|-----------| | 001 | 张三 | 25 | 看书, 旅行 | | 002 | 李四 | 30 | 跑步 |如果有个用户没有"兴趣爱好"信息,可能要留空(
NULL)。 -
文档数据库(比如 MongoDB、DynamoDB):
数据像"电子文档"一样,存储在类似 JSON 的结构里。每条记录可以有不同的字段和格式,不需要提前设计表格,灵活性更高。同样的用户信息,每条记录是一个独立的"文档",没有固定格式。比如:{ "用户ID": "001", "姓名": "张三", "年龄": 25, "兴趣爱好": ["看书", "旅行"] }或者:
{ "用户ID": "002", "姓名": "李四", "年龄": 30 }不需要存空字段,数据结构可以随用随改。
文档数据库特别适合:数据结构经常变化(比如新增字段)的场景、数据内容很复杂,比如电商平台的商品详情(每个商品可能有不同的规格)、用 JSON 直接和前端对接的场景,比如 REST API 的数据输出。
文档数据库是用来存储像电子文档一样的结构化数据,以 JSON 等形式保存,提供更大的灵活性。
-
-
再说说 Amazon DynamoDB 的特点
作为一项完全托管的数据库服务,
DynamoDB可以处理管理数据库的无差别繁重工作,使您可以专注于为客户创造更多价值。它负责设置、配置、维护、高可用性、硬件配置、安全、备份、监控等。这将确保在创建DynamoDB表时,它可以立即为生产工作负载做好准备。DynamoDB无需升级或停机即可不断提高其可用性、可靠性、性能、安全性和功能。DynamoDB专为提高关系数据库的性能和可扩展性而设计,在任何规模下都能提供个位数的毫秒性能。为了实现这种规模和性能,DynamoDB针对高性能工作负载进行了优化,可提供推动高效使用数据库的 API。它省略了在规模上效率低下且性能不佳的功能,例如 JOIN 操作。无论您有 100 个还是 1 亿用户,DynamoDB都能为您的应用程序提供稳定的个位数毫秒性能^1{#fnref1}^。 -
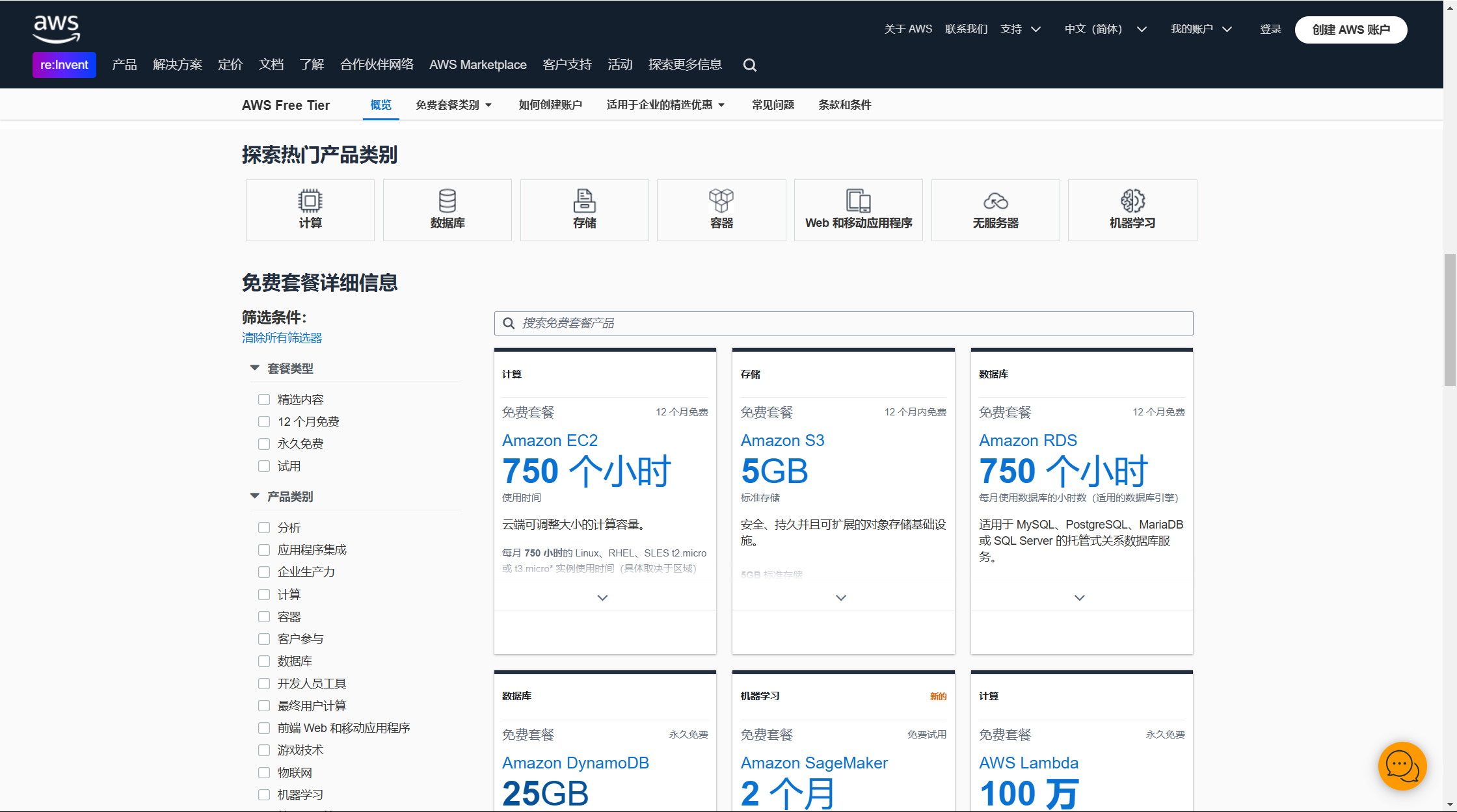
免费试用
亚马逊云科技是提供了很多的免费云服务的,之前给大家分享过云服务器、S3以及Lambda 无服务器架构服务,今天要分享的就是 Amazon DynamoDB,它也提供了免费服务,免费试用的套餐详情如下,看不懂没关系,接着往下看:

详细的定价参考官网说明:Amazon DynamoDB 定价
1. 25GB 的存储
DynamoDB 提供最多 25GB 的免费数据存储空间。数据存储是指 DynamoDB 用来存储你的表中数据的容量大小。每个表的键、属性、索引等都算在存储容量中。
2. 25 个预置写入容量单位 (WCU)
写入容量单位 (Write Capacity Unit, WCU) 表示 DynamoDB 处理写入请求的能力,定义为 每秒可以处理 1KB 的写入数据量 。如果你的写入数据小于或等于 1KB,1 WCU 足够每秒支持一次写操作。如果数据大小超过 1KB,写操作需要更多 WCU。例如写入 2KB 的数据需要 2 个 WCU、写入 3KB 的数据需要 3 个 WCU。25 WCU 意味着在免费套餐下,DynamoDB 表每秒可以处理 最多 25 次 1KB 大小的写操作。
3. 25 个预置读取容量单位 (RCU)
读取容量单位 (Read Capacity Unit, RCU) 表示 DynamoDB 处理读取请求的能力,定义为 每秒可以处理一次 4KB 的强一致性读取 或 两次 4KB 的最终一致性读取。
-
**强一致性读取 (Strongly Consistent Reads):**每次读取 DynamoDB 都保证返回最新写入的数据。
-
**最终一致性读取 (Eventually Consistent Reads):**数据可能会有轻微的延迟,适合不需要实时最新数据的应用。
如果你的读取数据小于或等于 4KB,1 RCU 足够支持一次强一致性读取或两次最终一致性读取。如果数据超过 4KB,读取需要更多的 RCU。例如读取 8KB 的数据需要 2 个 RCU(强一致性)、读取 8KB 的数据需要 1 个 RCU(最终一致性)。如果你每秒读取 10 次,每次数据大小为 2KB(小于 4KB),25 RCU 够用。
- 如果你每秒读取 5 次,每次 8KB,25 RCU 也够用,但强一致性读取会消耗掉 10 个 RCU(5 次 * 2 RCU/次)。
让我们逐一解读这些免费套餐中的内容:
4. 250 万个来自 DynamoDB Streams 的流读取请求
DynamoDB Streams 是一种功能,它记录 DynamoDB 表中数据的更改,比如新增、修改或删除的记录。这些更改会以事件的形式流入一个队列,你可以读取这些事件来实现诸如:
- 数据同步: 将 DynamoDB 的数据同步到其他服务(如 Elasticsearch、Redshift)。
- 触发器: 自动响应数据变化,例如触发 Amazon Lambda 函数。
可以把 DynamoDB Streams 想象成一个数据更新的"通知中心"。当表中的数据发生变化时,你可以通过读取流来获取这些变化的详细信息。免费套餐允许每月最多 250 万次读取这些流的请求。
5. 1GB 的数据传输(前 12 个月为 15GB)
数据传输是指 DynamoDB 与客户端或其他 Amazon 服务之间的数据移动。例如:客户端从 DynamoDB 读取数据。数据从 DynamoDB 流传输到其他服务(如 S3)。免费套餐允许每月传输 1GB 的数据,而新用户在前 12 个月可以享受 15GB 的数据传输。
总之如果你只是为了学习 DynamoDB 的特性和操作或者开发小型应用程序,比如一个简单的用户管理系统、留言板或日志记录服务。肯定是够用的;
更多的免费云服务可以进入亚马逊云科技官网查看:
-
- Python对接Amazon DynamoDB {#python对接amazon-dynamodb} =====================================================
2.2. 创建DynamoDB表 {#创建dynamodb表}
前提是你有一个亚马逊云科技的账号,注册教程可以参考之前写的用亚马逊云科技云服务器搭建个人博客的文章;
2.2.1. 使用控制台创建 {#使用控制台创建}
进入控制台,选择对应服务
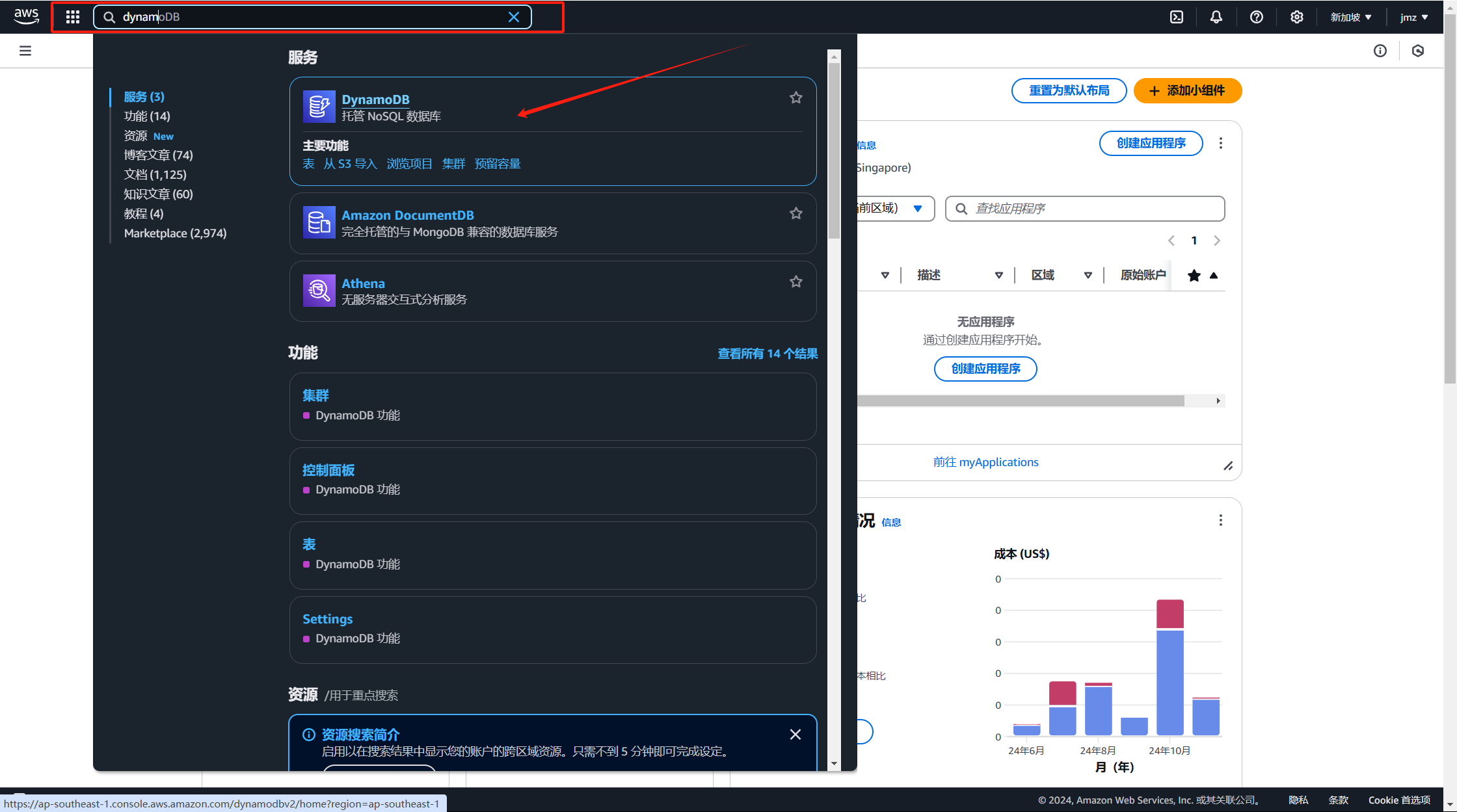
创建表
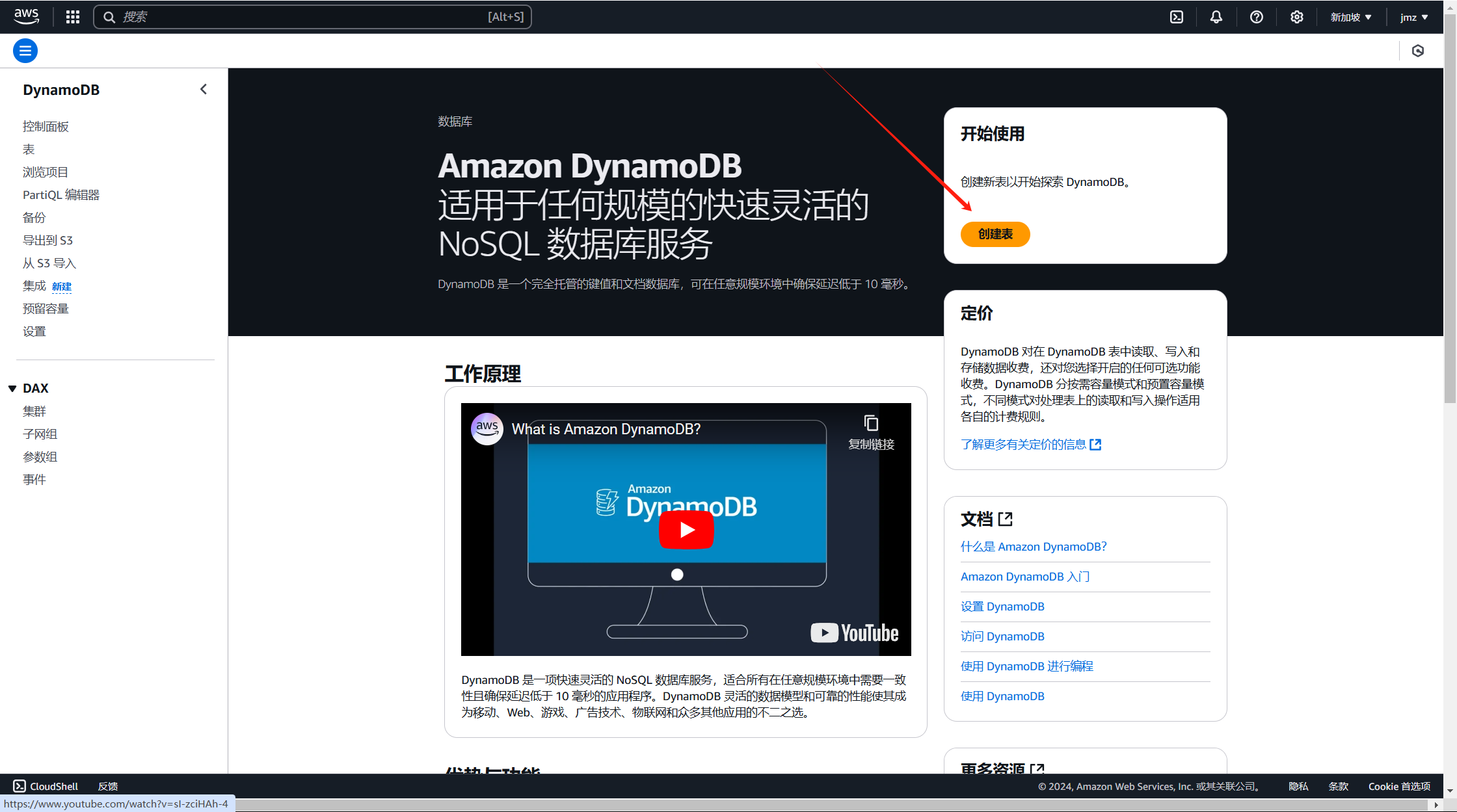
设定相应的值就可以了;
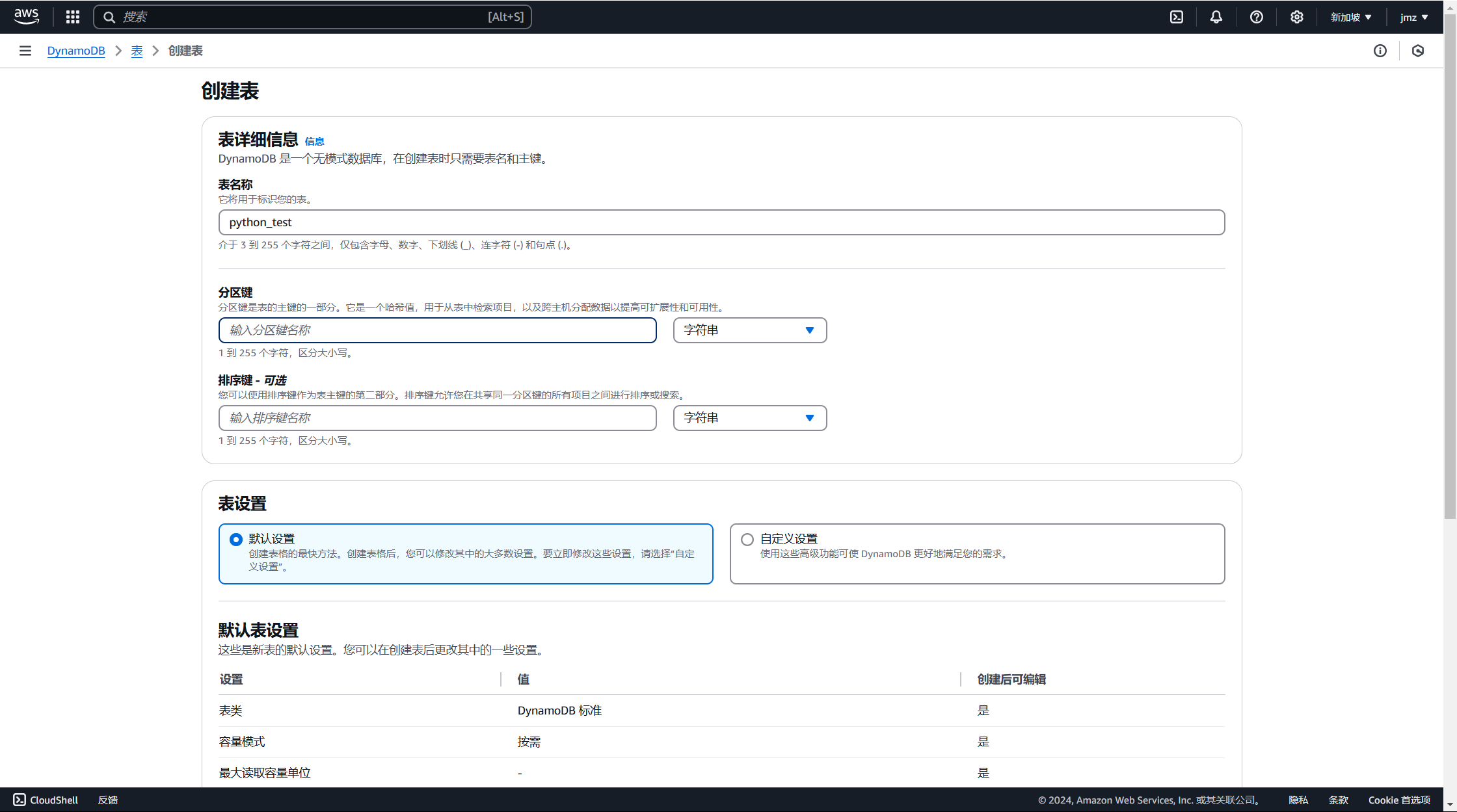
2.2.2. 使用 Python 创建 {#使用-python-创建}
- 创建访问密钥
首先要在控制台创建访问密钥,进入控制台后选择IAM服务;进入后点击我的安全凭证;
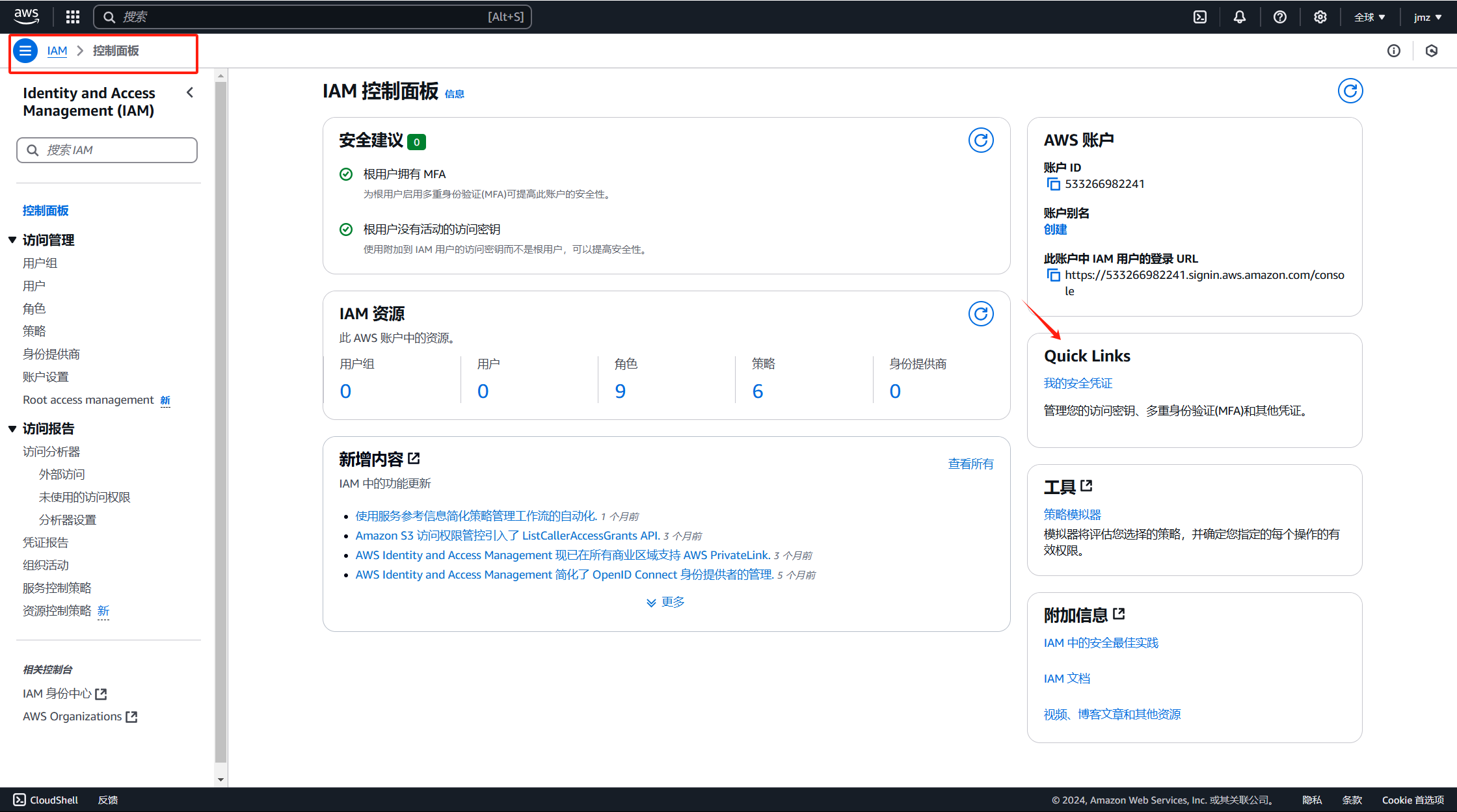
然后点击创建访问密钥;
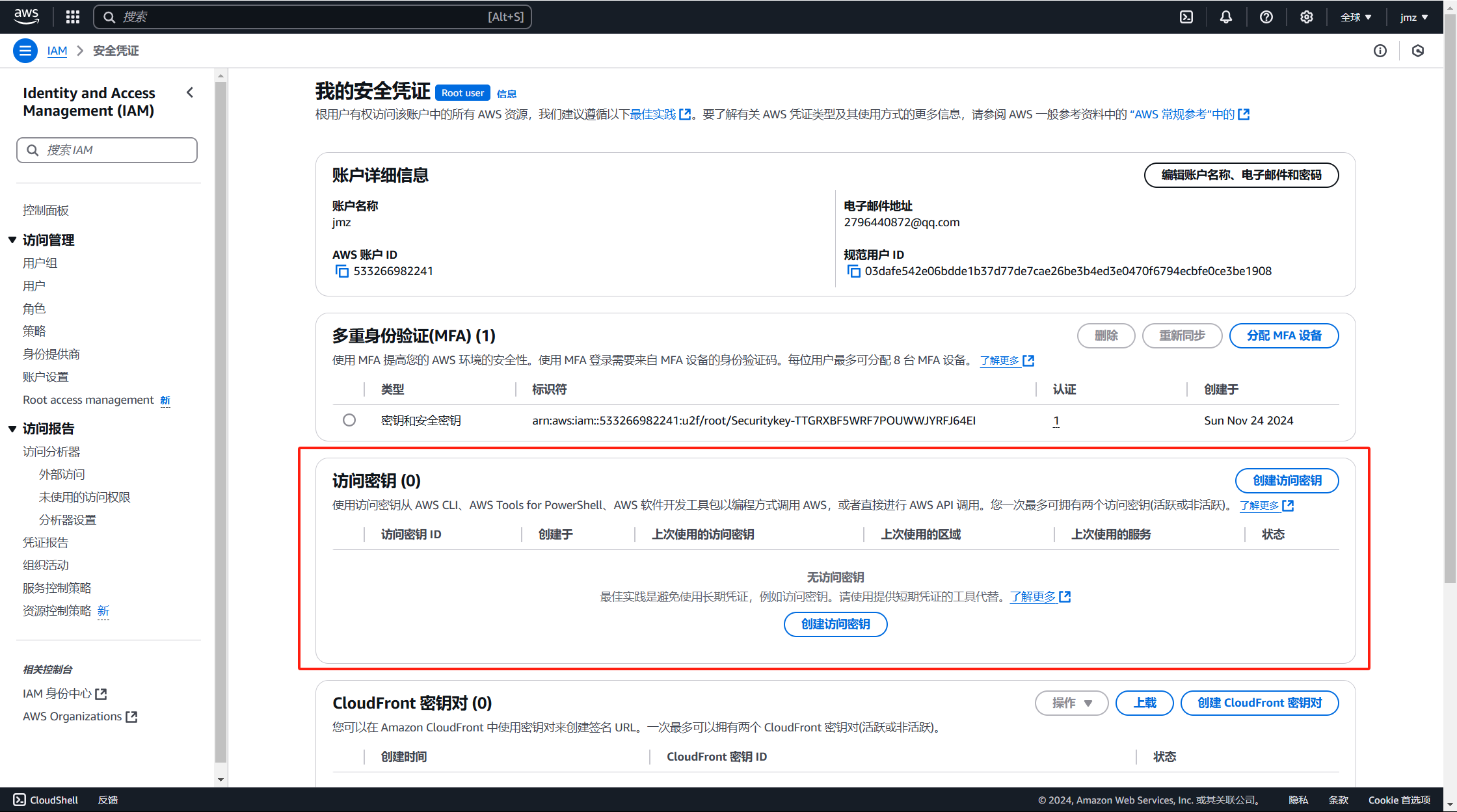
紧接着选择确认创建一个根访问的密钥;
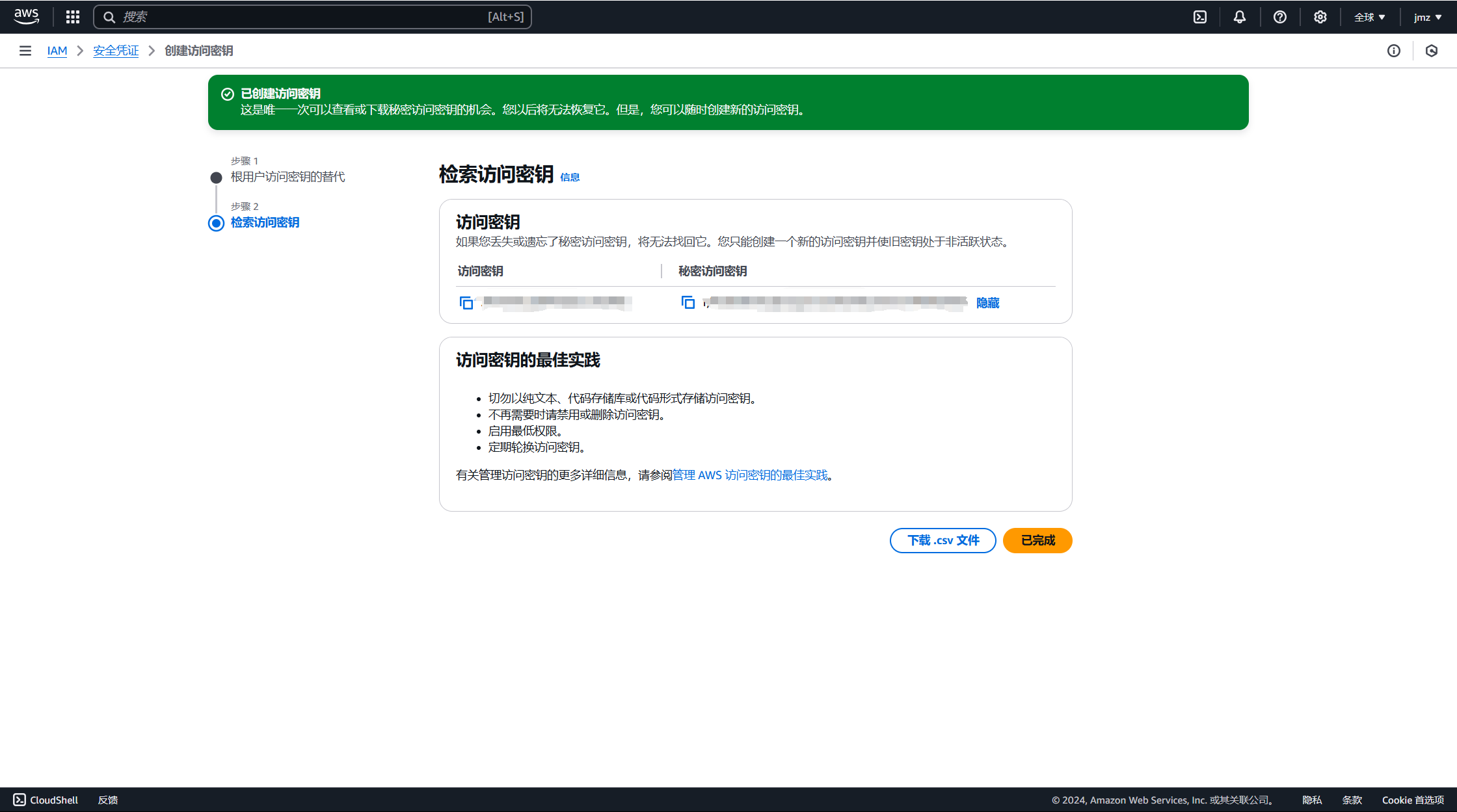
创建成功;
- 创建表
首页需要安装官方提供的 Python SDK,用于操作 DynamoDB
pip install boto3
# 清华大学的镜像源
pip install boto3 -i https://pypi.tuna.tsinghua.edu.cn/simple
创建表测试,直接放代码:
import boto3
初始化 DynamoDB 客户端
dynamodb = boto3.resource(
'dynamodb',
region_name='us-east-1',
aws_access_key_id='你的访问密钥ID',
aws_secret_access_key='你的秘密访问密钥'
)
创建 DynamoDB 表
table_name = 'Users'
table = dynamodb.create_table(
TableName=table_name,
KeySchema=[
{'AttributeName': 'UserID', 'KeyType': 'HASH'} # 主键定义
],
AttributeDefinitions=[
{'AttributeName': 'UserID', 'AttributeType': 'S'} # 主键类型(字符串)
],
ProvisionedThroughput={
'ReadCapacityUnits': 5,
'WriteCapacityUnits': 5
}
)
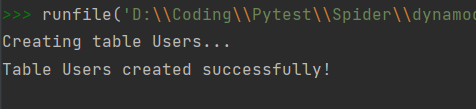
print(f"Creating table {table_name}...")
table.wait_until_exists()
print(f"Table {table_name} created successfully!")
创建成功的信息可能不会立马就打印出来,因为 table.wait_until_exists() 的运行时间取决于 DynamoDB 的处理速度,可能导致代码延迟或误判创建结果。
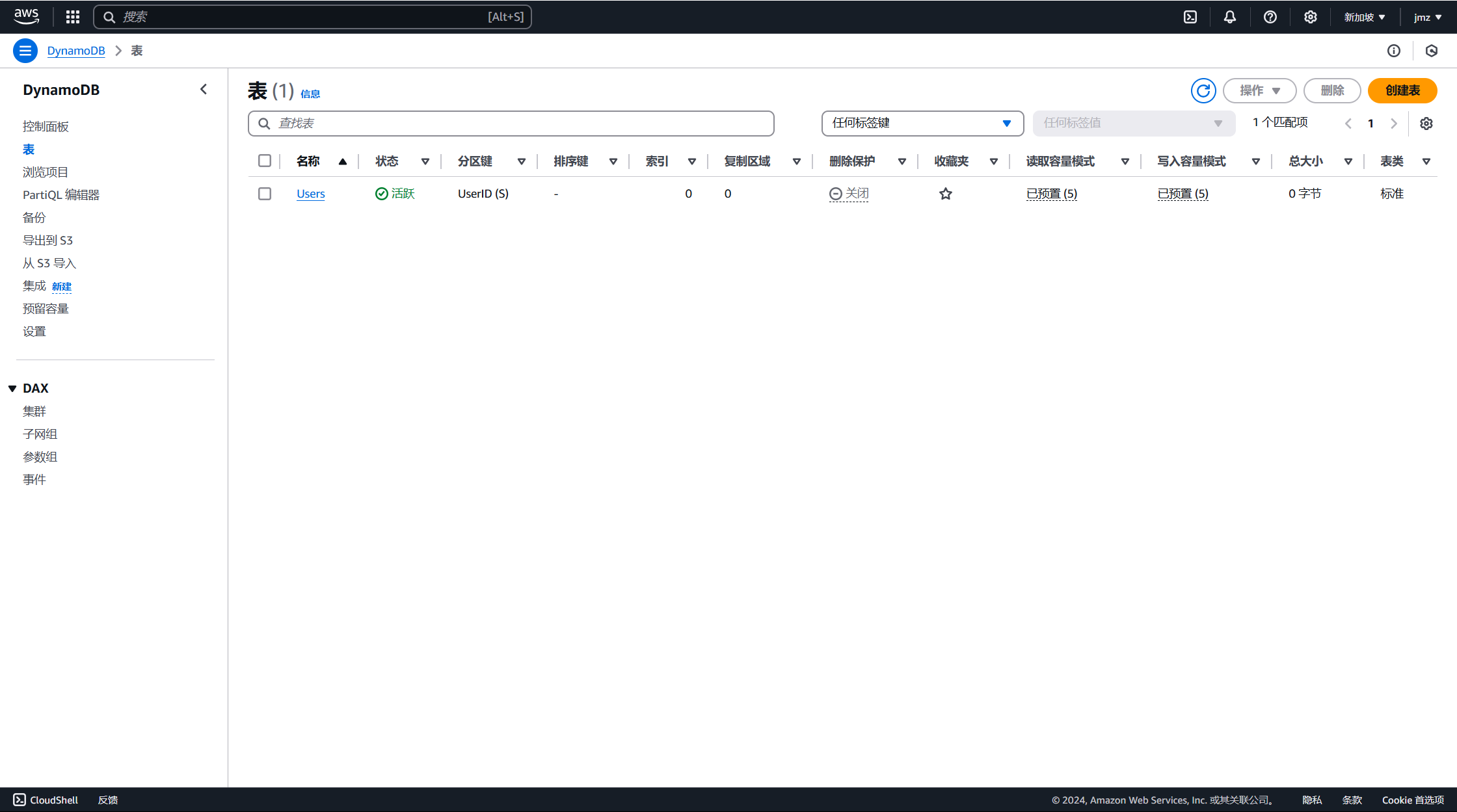
运行完了之后可以进入控制台查看,就已经创建成功了:
下面是代码的解释
# 初始化 DynamoDB 客户端 dynamodb = boto3.resource( 'dynamodb', # 使用 boto3 的 DynamoDB 资源对象 region_name='us-east-1', # 指定要操作的区域 aws_access_key_id='你的访问密钥ID', # 替换为你的访问密钥 ID,用于身份验证 aws_secret_access_key='你的秘密访问密钥' # 替换为你的秘密访问密钥,用于身份验证 )
作用:初始化一个 DynamoDB 资源对象,提供更高级的接口(相比客户端接口)。
关键点:
dynamodb是一个资源对象,用于管理 DynamoDB 表及其数据。
region_name指定区域,决定与哪个数据中心通信,如图:
aws_access_key_id和aws_secret_access_key是用于身份验证的凭证,确保用户有权限访问服务。# 创建 DynamoDB 表 table_name = 'Users'
- 作用 :定义要创建的 DynamoDB 表的名称为
Users,表名必须是全局唯一的,不同账户可以有相同的表名。table = dynamodb.create_table( TableName=table_name, # 指定表的名称 KeySchema=[ {'AttributeName': 'UserID', 'KeyType': 'HASH'} # 主键字段是 'UserID',类型为分区键 ], AttributeDefinitions=[ {'AttributeName': 'UserID', 'AttributeType': 'S'} # 定义主键的属性类型为字符串(S 表示 String) ], ProvisionedThroughput={ 'ReadCapacityUnits': 5, # 设置每秒允许的读取操作次数 'WriteCapacityUnits': 5 # 设置每秒允许的写入操作次数 } )
TableName指定 DynamoDB 表的名称,表名是每个 DynamoDB 实例的唯一标识符,用于操作表。
KeySchema定义表的主键结构,这里只有分区键(
UserID)。DynamoDB 使用主键(分区键或分区键+排序键)来定位数据。
- 分区键(HASH):通过哈希算法确定数据存储的物理位置。
- 排序键(RANGE,可选):在同一分区键内,用于排序数据。
AttributeDefinitions指定主键字段的属性名和类型,DynamoDB 支持三种数据类型作为主键字段类型:
'S':字符串(String)'N':数字(Number)'B':二进制(Binary)
ProvisionedThroughput为表预置吞吐量,定义读取和写入的容量。
print(f"Creating table {table_name}...")输出一条消息,通知用户表正在创建。
table.wait_until_exists()阻塞代码的执行,直到表创建完成(表状态变为
ACTIVE),DynamoDB 表的创建是异步的,wait_until_exists会在后台轮询表状态,直到创建成功。print(f"Table {table_name} created successfully!")输出一条消息,通知用户表已成功创建,如果代码执行到这里,表已经可以正常使用。
2.2. Python操作DynamoDB {#python操作dynamodb}
基本的读、写、更新、删除操作都包含在下面代码里面了,注释相对还是比较清晰的,我就不做过多的解释了:
import boto3
from pprint import pprint
初始化 DynamoDB 客户端
dynamodb = boto3.resource(
'dynamodb',
region_name='ap-southeast-1', # 使用合适的区域
aws_access_key_id='你的访问密钥ID',
aws_secret_access_key='你的秘密访问密钥'
)
获取 DynamoDB 表对象
table = dynamodb.Table('Users') # 通过表名获取表对象
写入用户信息
def write_user_info(table):
"""
写入一些用户信息到 DynamoDB 表。
"""
users = [
{'UserID': 'user001', 'Name': '张伟', 'Age': 30, 'City': '北京', 'Email': 'zhangwei@example.com'},
{'UserID': 'user002', 'Name': '李娜', 'Age': 25, 'City': '上海', 'Email': 'lina@example.com'},
{'UserID': 'user003', 'Name': '王磊', 'Age': 35, 'City': '广州', 'Email': 'wanglei@example.com'},
{'UserID': 'user004', 'Name': '刘洋', 'Age': 28, 'City': '深圳', 'Email': 'liuyang@example.com'},
{'UserID': 'user005', 'Name': '陈晨', 'Age': 40, 'City': '成都', 'Email': 'chenchen@example.com'},
{'UserID': 'user006', 'Name': '赵强', 'Age': 22, 'City': '南京', 'Email': 'zhaoqiang@example.com'},
{'UserID': 'user007', 'Name': '孙婷', 'Age': 26, 'City': '武汉', 'Email': 'sunting@example.com'},
{'UserID': 'user008', 'Name': '周杰', 'Age': 32, 'City': '重庆', 'Email': 'zhoujie@example.com'},
]
for user in users:
table.put_item(Item=user)
print(f"User {user['UserID']} added successfully!")
读取单个用户信息
def read_user_info(table, user_id):
"""
根据 UserID 读取用户信息。
"""
response = table.get_item(Key={'UserID': user_id})
if 'Item' in response:
print(f"User {user_id} found: {response['Item']}")
else:
print(f"User {user_id} not found.")
更新用户信息
def update_user_info(table, user_id, new_name, new_age, new_city, new_email):
"""
根据 UserID 更新用户信息。
"""
table.update_item(
Key={'UserID': user_id},
UpdateExpression='SET #name = :name, #age = :age, #city = :city, #email = :email',
ExpressionAttributeNames={'#name': 'Name', '#age': 'Age', '#city': 'City', '#email': 'Email'},
ExpressionAttributeValues={':name': new_name, ':age': new_age, ':city': new_city, ':email': new_email}
)
print(f"User {user_id} updated successfully!")
删除用户信息
def delete_user_info(table, user_id):
"""
根据 UserID 删除用户信息。
"""
table.delete_item(Key={'UserID': user_id})
print(f"User {user_id} deleted successfully!")
读取所有用户信息
def read_all_users(table):
"""
读取 DynamoDB 表中的所有用户信息。
"""
response = table.scan()
items = response.get('Items', [])
print("All Users:")
pprint(items)
主函数
if name == "main":
写入用户信息
write_user_info(table)
# 读取单个用户信息
read_user_info(table, 'user001')
# 更新用户信息
update_user_info(table, 'user001', '张伟更新', 32, '北京', 'zhangwei_updated@example.com')
# 删除用户信息
delete_user_info(table, 'user002')
# 更新或删除后读取所有用户信息
read_all_users(table)
这里使用了
pprint,pprint是 Python 标准库中的一个模块,专门用于"美化"打印输出,使得复杂的结构(如字典、列表等)更加易读。pprint是pretty-print的缩写,它会对数据进行格式化,使得层次结构清晰、易于理解。可以使用
pprint()函数来打印复杂的数据结构。例如:data = { 'name': '张伟', 'age': 30, 'address': { 'city': '北京', 'street': '长安街1号' }, 'friends': [ {'name': '李娜', 'age': 25}, {'name': '王磊', 'age': 35} ] }使用 pprint 格式化打印输出
pprint(data)
输出结果
{'address': {'city': '北京', 'street': '长安街1号'}, 'age': 30, 'friends': [{'age': 25, 'name': '李娜'}, {'age': 35, 'name': '王磊'}], 'name': '张伟'}
pprint与普通print()的区别
print():会将数据以原始格式输出,结构较为紧凑,可能不易读取。示例:
print(data)输出:
{'name': '张伟', 'age': 30, 'address': {'city': '北京', 'street': '长安街1号'}, 'friends': [{'name': '李娜', 'age': 25}, {'name': '王磊', 'age': 35}]}
pprint():会格式化输出,调整缩进,使得嵌套的结构更加清晰。示例:
pprint(data)输出:
{'address': {'city': '北京', 'street': '长安街1号'}, 'age': 30, 'friends': [{'age': 25, 'name': '李娜'}, {'age': 35, 'name': '王磊'}], 'name': '张伟'}主要参数
width:每行打印的最大字符数,超过后自动换行。depth:控制打印时的嵌套层次,限制最大深度。compact:如果设置为True,则会将结构更紧凑地打印。示例:
pprint(data, width=30) # 限制每行最多输出 30 个字符
- 爬取bing搜索结果并存入 DynamoDB {#爬取bing搜索结果并存入-dynamodb} ===================================================
其实上面的东西是本文的核心内容,这个章节主要就是记录爬取必应搜索结果并存储,爬取的内容意义不是特别大;
- 主要思路
初始化 DynamoDB 客户端 :通过 boto3.resource 连接 DynamoDB,指定区域和访问凭证。
创建 DynamoDB 表 :表名:BingSearchResults、主键:URL,用于唯一标识每条搜索结果、吞吐量:设置为每秒 5 次读取和写入。
爬取 Bing 搜索结果 :使用 requests 向 Bing 搜索发送 HTTP 请求,进一步解析返回的 HTML,提取搜索结果中的标题和 URL,测试爬取前两页,每页包含 10 条结果。
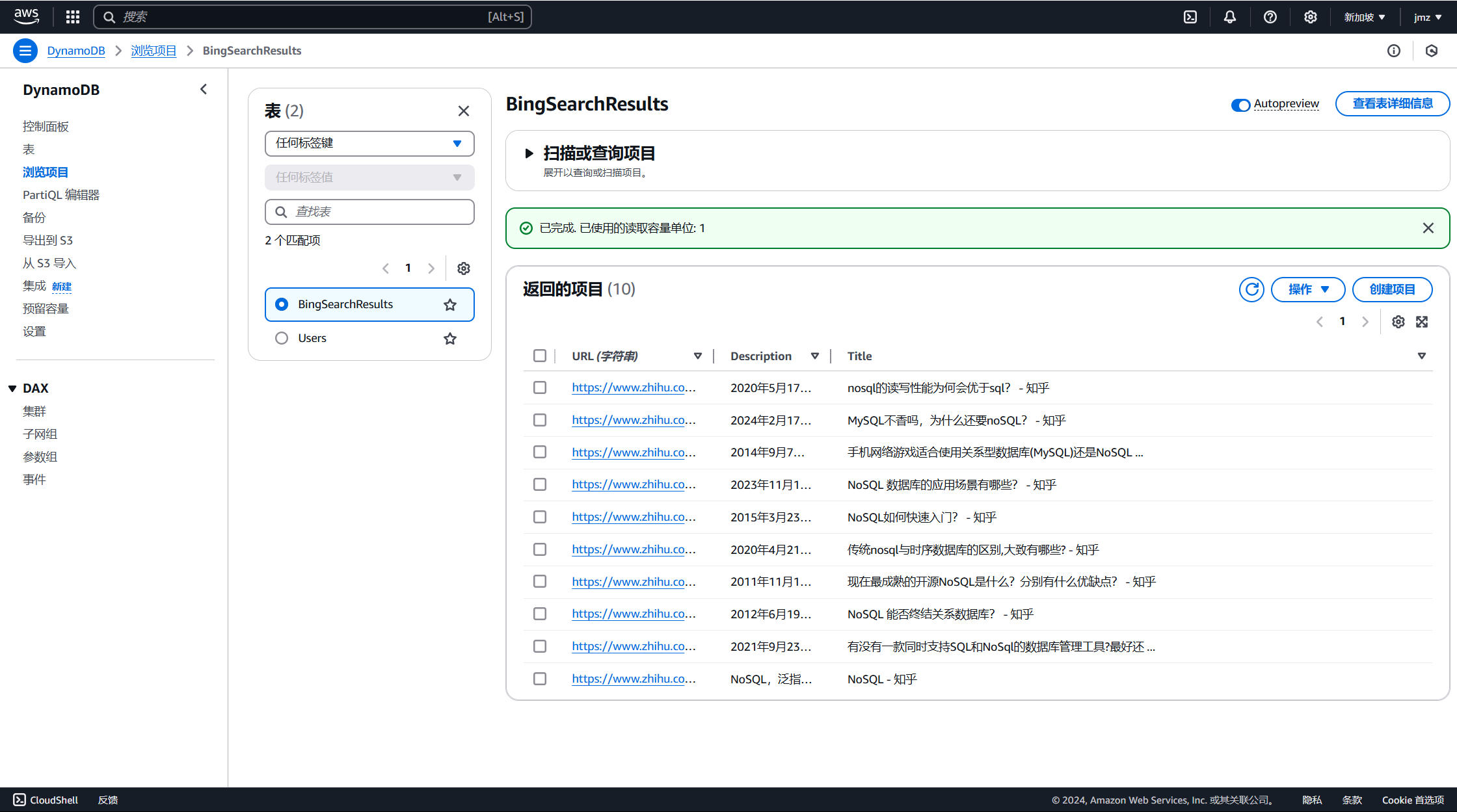
存储到 DynamoDB :遍历爬取的搜索结果,将每条结果存储到表中,利用 table.put_item 方法插入数据。
- 完整代码
import boto3
import requests
from bs4 import BeautifulSoup
import time
from pprint import pprint
Step 1: 初始化 DynamoDB 客户端
dynamodb = boto3.resource(
'dynamodb', # DynamoDB 资源对象
region_name='us-east-1', # 替换为你选择的区域
aws_access_key_id='你的访问密钥ID', # 替换为你的访问密钥 ID
aws_secret_access_key='你的秘密访问密钥' # 替换为你的秘密访问密钥
)
Step 2: 创建 DynamoDB 表
def create_table():
"""
创建一个名为 'BingSearchResults' 的 DynamoDB 表,用于存储 Bing 搜索结果。
主键为 URL(字符串类型)。
"""
table_name = 'BingSearchResults'
try:
table = dynamodb.create_table(
TableName=table_name,
KeySchema=[
{'AttributeName': 'URL', 'KeyType': 'HASH'} # 使用 URL 作为分区键
],
AttributeDefinitions=[
{'AttributeName': 'URL', 'AttributeType': 'S'} # 定义 URL 类型为字符串
],
ProvisionedThroughput={
'ReadCapacityUnits': 5, # 读取容量单位
'WriteCapacityUnits': 5 # 写入容量单位
}
)
print(f"正在创建表 {table_name}...")
table.wait_until_exists()
print(f"表 {table_name} 创建成功!")
except Exception as e:
print(f"表 {table_name} 可能已经存在。错误信息:{str(e)}")
return dynamodb.Table(table_name)
Step 3: 爬取 Bing 搜索结果
def scrape_bing_results(query):
"""
使用 requests 和 BeautifulSoup 爬取 Bing 搜索结果的前两页。
:param query: 搜索关键词
:return: 包含 URL、标题和描述的结果列表
"""
base_url = "https://www.bing.com/search"
results = []
for page in range(2): # 爬取前两页
params = {'q': query, 'first': page * 10 + 1} # 分页参数
response = requests.get(base_url, params=params)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
for item in soup.find_all('li', {'class': 'b_algo'}):
title = item.find('h2')
link = item.find('a')
description = item.find('p')
if title and link:
results.append({
'URL': link['href'],
'Title': title.get_text(),
'Description': description.get_text() if description else "无描述"
})
else:
print(f"获取第 {page + 1} 页失败,状态码:{response.status_code}")
time.sleep(1) # 避免被封禁,设置爬取间隔
return results
Step 4: 将爬取数据存储到 DynamoDB
def store_results_to_dynamodb(table, results):
"""
将 Bing 搜索结果存储到 DynamoDB 表中。
:param table: DynamoDB 表对象
:param results: 爬取的搜索结果列表
"""
for result in results:
try:
table.put_item(Item=result) # 写入每一条数据
print(f"存储成功: {result['URL']}")
except Exception as e:
print(f"存储 {result['URL']} 失败。错误信息:{str(e)}")
主函数
if name == "main":
用户输入搜索关键词
query = input("请输入您的搜索关键词:")
# 创建表
table = create_table()
# 爬取 Bing 搜索结果
print(f"正在爬取 Bing 搜索结果,关键词:{query}...")
search_results = scrape_bing_results(query)
# 使用 pprint 打印结果
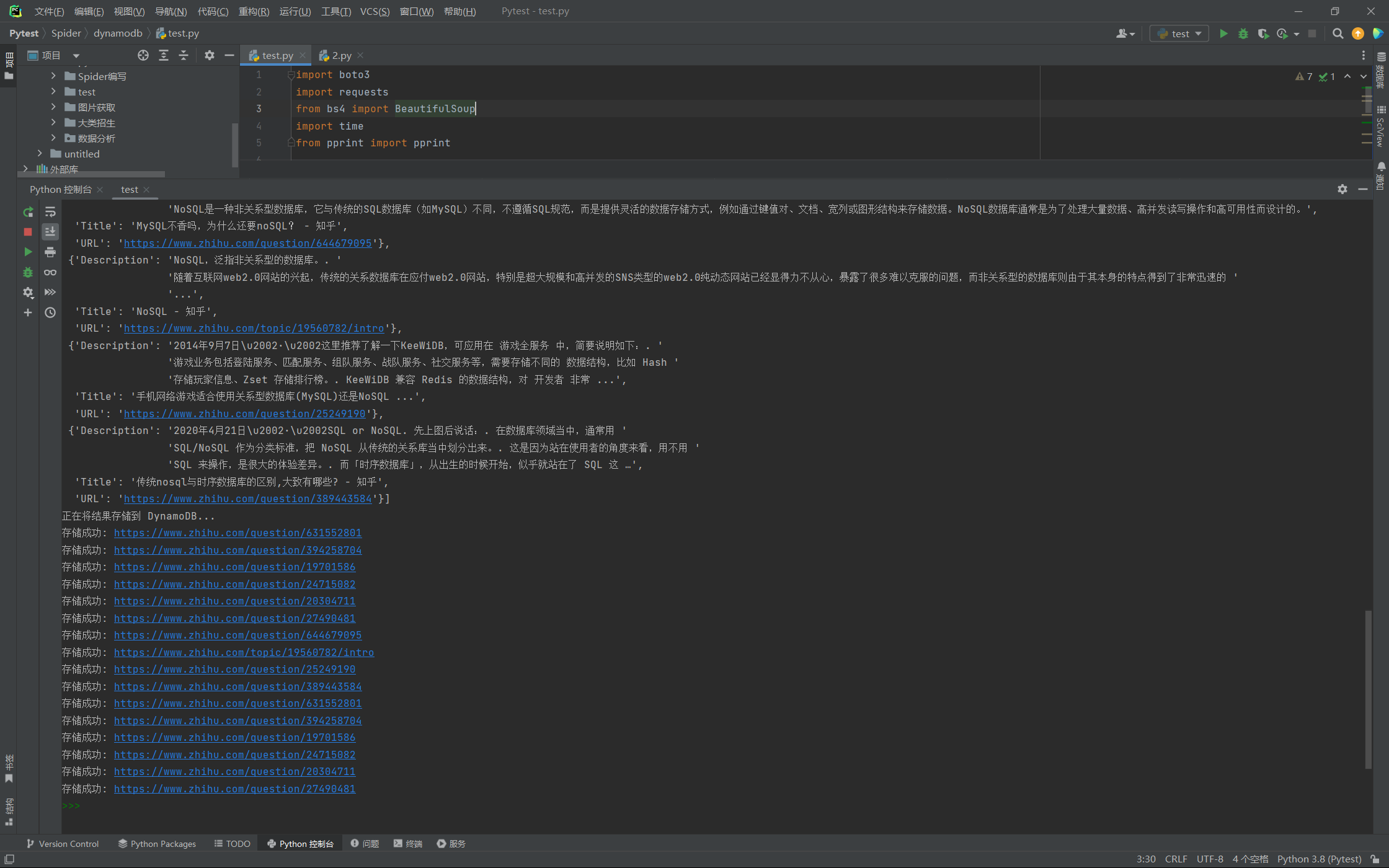
print("爬取结果:")
pprint(search_results)
# 存储结果到 DynamoDB
print("正在将结果存储到 DynamoDB...")
store_results_to_dynamodb(table, search_results)
print("所有任务已成功完成!")
执行成功:
进入控制台查看效果:
结语 {#结语}
本文主要就是打通了流程,没有太多的爬取实践。当然,就本文的主要思路拓展一下的话,结合DynamoDB 的 Python 爬虫,可以简化数据存储的开发流程,还能充分利用 DynamoDB 的灵活性、扩展性和高性能特点,解决大规模爬取任务中常见的存储和管理难题。后续有时间的话,再进一步的探索。
希望本文能给你一些启发,当然,如果你有什么好的想法或者建议,欢迎评论区留言讨论!
-
{#fn1} {#fn1}