哇,你听说了吗?微软最近提出了一个超级厉害的语音合成系统,名叫 EmoCtrl-TTS!
想象一下,它就像是一个超级厉害的配音演员,不仅能模仿任何人的声音,还能随心所欲地控制情绪。开心的时候哈哈大笑,伤心的时候呜呜哭泣,甚至还能在一句话里从喜到悲,无缝切换!EmoCtrl-TTS 现在可以随意控制语音里的情感起伏,就像是在演奏一首复杂的情感交响曲。它还能模仿任何人的声音。想听某个明星用超悲伤的语气朗读菜单吗?没问题!想听你最讨厌的老师用兴高采烈的声音宣布明天要加倍作业?也行!
一些demo:
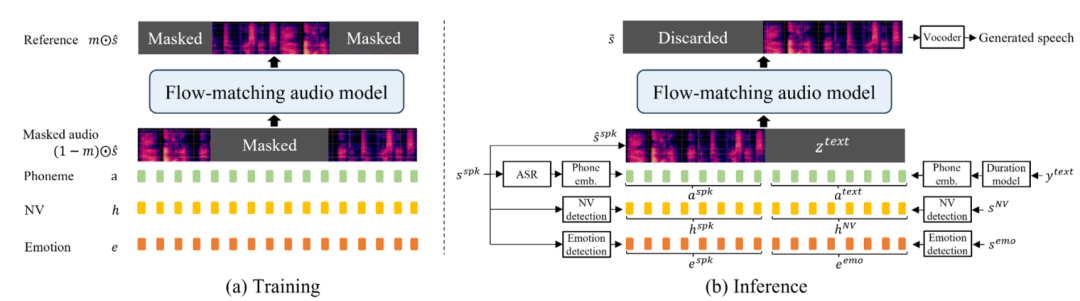
EmoCtrl-TTS 能够生成任何说话者的声音,包括笑声和哭声等非语言发声。 EmoCtrl-TTS 专门设计用于模仿零样本语音合成中 audio prompt 中的情感变化状态。
Prompt audio:
Voicebox baseline EmoCtrl-TTS:

标题: Laugh Now Cry Later: Controlling Time-Varying Emotional States of Flow-Matching-Based Zero-Shot Text-to-Speech
更多demo:
https://www.microsoft.com/en-us/research/project/emoctrl-tts/文章链接:
https://arxiv.org/abs/2407.12229
摘要
人们常常通过非语言发声(NVs)如笑声和哭声,来传达丰富的情感。然而,大多数语音生成系统缺乏生成具有丰富情感(包括NVs)的语音的能力。本文介绍了 EmoCtrl-TTS,一种能实现细粒度情感控制的零样本TTS,能为任何说话者生成情感丰富的语音,包括NVs。EmoCtrl-TTS 利用 arousal 和 valence 值,以及笑声信息,来调节基于flow-matching的零样本TTS。为了实现高质量的情感语音生成,EmoCtrl-TTS 使用表现力丰富的数据进行训练,这些数据基于伪标签进行筛选。综合评估表明,EmoCtrl-TTS 在语音到语音翻译场景中出色地模仿了源语音的情感。EmoCtrl-TTS也能够捕捉情感变化,表达强烈情感,并在零样本TTS中生成各种NVs。
介绍
人类通过改变语气来表达广泛的情感,常常伴随着非语言发声(NVs)如笑声和哭声。虽然当前的情感文本转语音(TTS)系统已经取得了重大进展,但它们仍然缺乏生成具有精细控制的情感语音(例如在单个生成的话语中改变情感状态)以及各种类型NVs(如笑声和哭声)的能力。此外,当前的情感TTS系统通常在有限数量说话者的staged数据集上进行训练;在极端情况下,有些系统只使用一个说话者进行训练。这些TTS模型往往缺乏为任何说话者生成情感语音的能力,而这一特性对于需要在生成翻译语音时保留源音频的情感和说话者特征的语音到语音翻译系统等应用来说至关重要。
在本文中,我们介绍了 EmoCtrl-TTS ,这是一种情感可控的零样本TTS系统,能够为任何说话者生成高度情感化的语音,包括NVs。EmoCtrl-TTS 通过模仿音频样本(称为音频提示)所呈现的声音特征和情感来生成语音。EmoCtrl-TTS 基于 flow-matching 的零样本TTS,并利用valence和arousal值来模仿情感的时变特征。此外,它还利用笑声嵌入,我们发现这不仅对生成笑声有效,对生成其他NVs(包括哭声)也有效。此外,通过利用高度表现力丰富的真实世界数据(通过精心的数据挖掘获得),EmoCtrl-TTS 在鲁棒性方面实现了显著提升。EmoCtrl-TTS 在语音到语音翻译场景中出色地再现了多种语言的音频提示中的情感。我们还展示了EmoCtrl-TTS能够捕捉情感变化,表达强烈情感,并在零样本TTS中生成各种类型的NVs。