蒙特卡洛树搜索是一种基于树结构的蒙特卡洛方法,本文记录相关内容。
简介 {#简介}
蒙特卡洛树搜索(Monte Carlo Tree Search,MCTS)是一种基于树结构的蒙特卡洛方法,所谓的蒙特卡洛树搜索就是基于蒙特卡洛方法在整个决策空间中进行启发式搜索,基于一定的反馈寻找出最优的树结构路径(可行解)。概括来说就是,MCTS是一种确定规则驱动的启发式随机搜索算法。
MCTS的5个主要核心部分:
- 树结构:树结构定义了一个可行解的解空间,每一个叶子节点到根节点的路径都对应了一个解(solution),解空间的大小为2N(N等于决策次数,即树深度)
- 蒙特卡洛方法:MSTC不需要事先给定打标样本,随机统计方法充当了驱动力的作用,通过随机统计实验获取观测结果。
- 损失评估函数:有一个根据一个确定的规则设计的可量化的损失函数(目标驱动的损失函数),它提供一个可量化的确定性反馈,用于评估解的优劣。从某种角度来说,MCTS是通过随机模拟寻找损失函数代表的背后"真实函数"。
- 反向传播线性优化:每次获得一条路径的损失结果后,采用反向传播(Backpropagation)对整条路径上的所有节点进行整体优化,优化过程连续可微
- 启发式搜索策略:算法遵循损失最小化的原则在整个搜索空间上进行启发式搜索,直到找到一组最优解或者提前终止
算法的优化核心思想总结一句话就是:在确定方向的渐进收敛(树搜索的准确性)和随机性(随机模拟的一般性)之间寻求一个最佳平衡。体现了纳什均衡的思想精髓。
算法步骤 {#算法步骤}
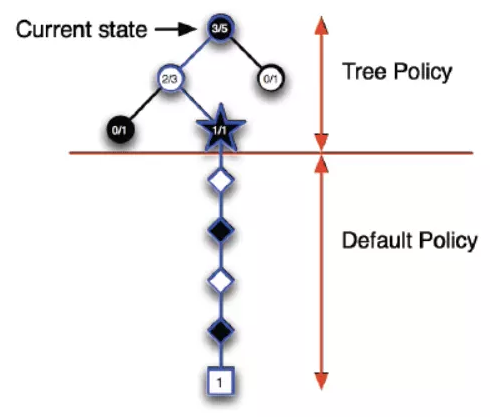
MCTS搜索就是建立一棵树的过程。蒙特卡罗树搜索大概可以被分成四步。选择(Selection),拓展(Expansion),模拟(Simulation),反向传播(Backpropagation)。下面我们逐个来分析。
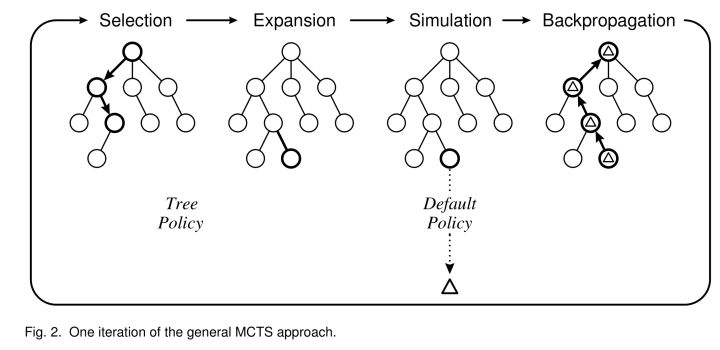
1. 初始化 {#1-初始化}
在开始阶段,搜索树只有一个节点,即根节点。搜索树中的每一个节点包含了三个基本信息:
- 当前需要决策的局面R:即下一步可选的action list,action list是构成解空间的基本要素
- 该节点被访问的次数:用于提供一个确定性的收敛方向判据
- 累计评分:用于提供一个确定性的收敛方向判据
2. 选择阶段(Selection) {#2-选择阶段-Selection}
在选择阶段,需要从父节点(首次选择从根节点开始),也就是要做决策的局面R出发向下选择出一个最急迫需要被拓展的节点N,即选择向哪个子节点方向生长。
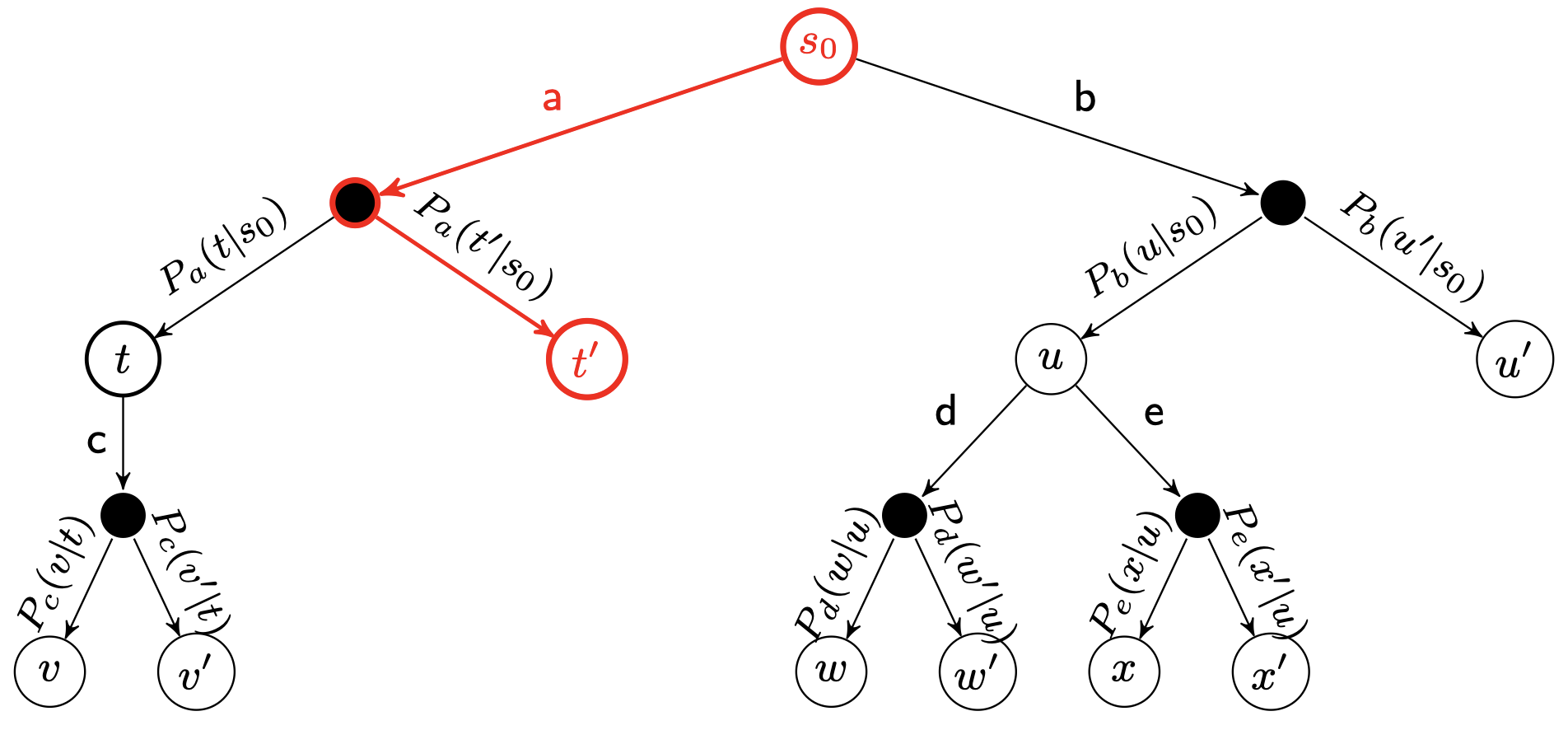
对于被检查的局面而言,存在三种可能:
- 该节点所有可行动作都已经被拓展过:如果所有可行动作都已经被拓展过了,这表示该节点已经完成了一个完整搜索(complete search),那么我们将使用UCB公式计算该节点所有子节点的UCB值,并找到值最大的一个子节点继续检查。反复向下迭代。
- 该节点有可行动作还未被拓展过:如果被检查的局面依然存在没有被拓展的子节点(例如说某节点有20个可行动作,但是在搜索树中才创建了19个子节点),那么会在剩下的可行动作中随机选取一个动作(子节点)A,执行下一步的拓展(expansion)操作。
- 该节点游戏已经结束了(例如已经连成五子的五子棋局面):如果被检查到的节点是一个游戏已经结束的节点。那么从该节点直接执行反向传播(backpropagation)步骤。
每一个被检查的节点的被访问次数,在每次选择阶段阶段都会自增。
3. 拓展(Expansion) {#3-拓展-Expansion}
除非我们最终到达的结点是一个终止状态,否则我们将对选结点的子结点进行扩展,即通过选择一个行动并使用该行动的结果创建一些新的结点。
在选择阶段结束时候,我们查找到了一个最迫切被拓展的节点 $N$,以及他一个尚未拓展的动作 $A$。在搜索树中创建一个新的节点 $N_n$ 作为N的一个新子节点。$N_n$ 的局面就是节点 $N$ 在执行了动作 $A$ 之后的局面。
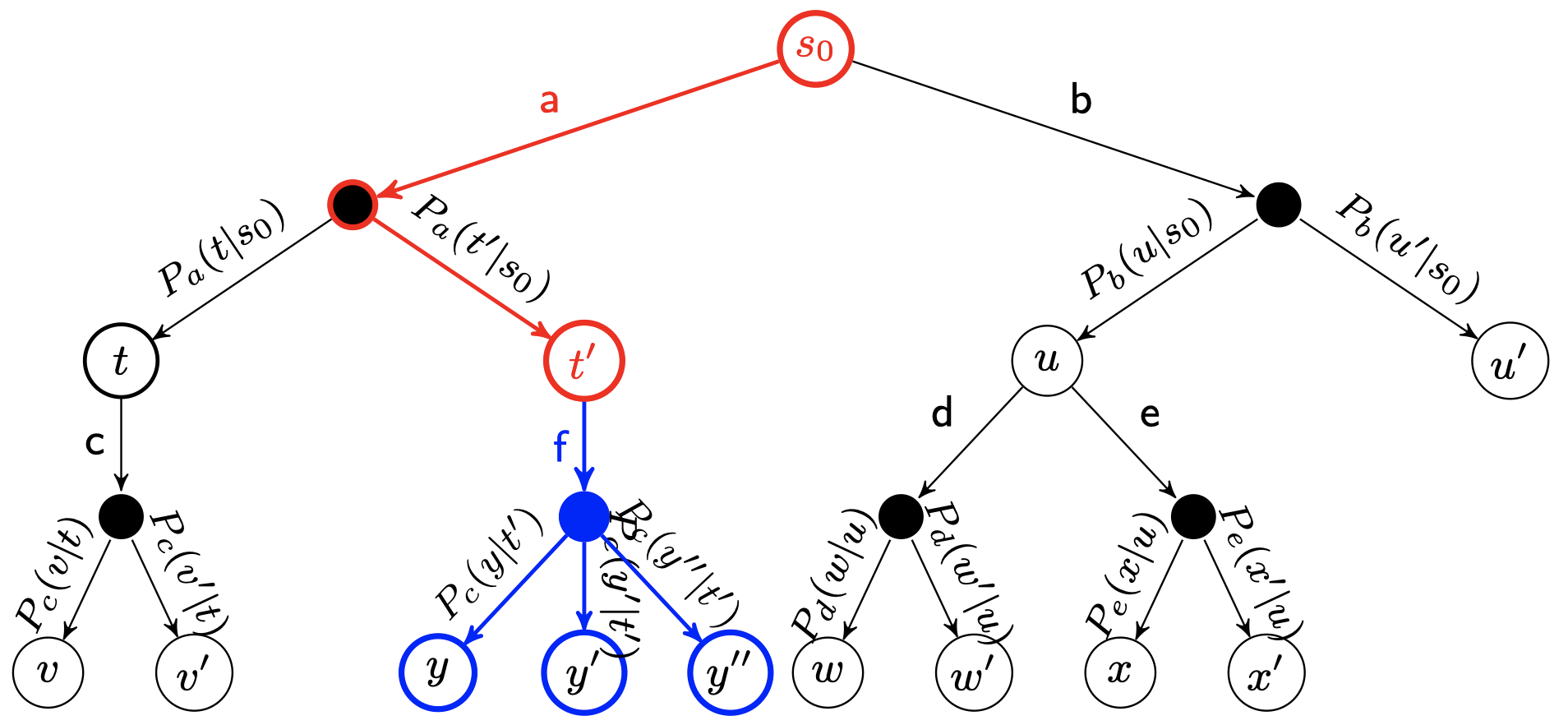
4. 模拟(Simulation) {#4-模拟-Simulation}
为了让新节点Nn得到一个初始的评分。我们从Nn开始,让游戏随机进行,直到得到一个游戏结局,这个结局将作为 $N_n$ 的初始评分。一般使用胜利/失败来作为评分,只有1或者0。
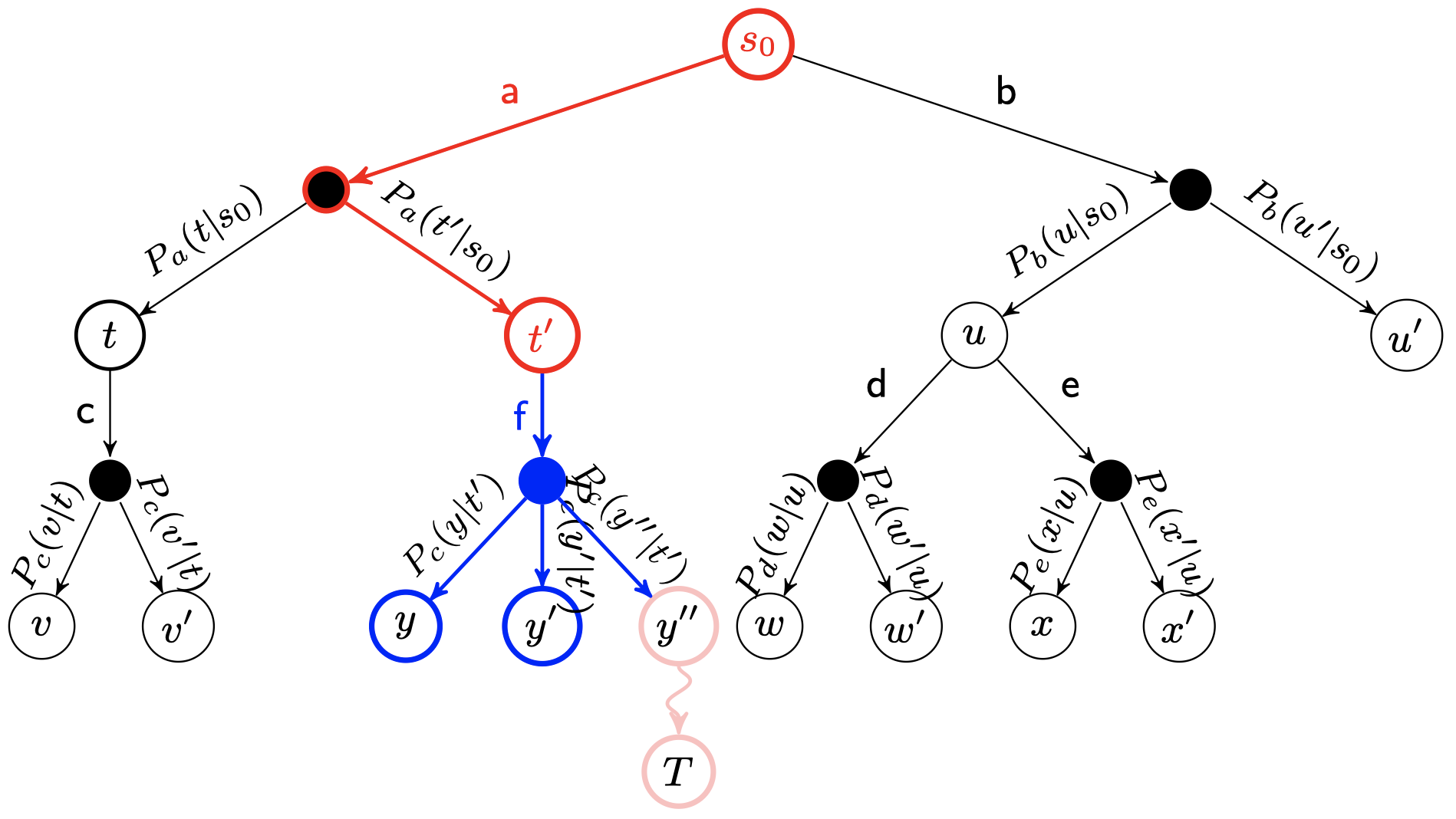
5. 反向传播(Backpropagation) {#5-反向传播-Backpropagation}
在Nn的模拟结束之后,它的父节点N以及从根节点到N的路径上的所有节点都会根据本次模拟的结果来修改自己的累计评分。注意,如果在选择环节中直接发现了一个游戏结局的话,根据该结局来更新评分。
每一次迭代都会拓展搜索树,随着迭代次数的增加,搜索树的规模也不断增加。当到了一定的迭代次数或者时间之后结束,选择根节点下最好的子节点作为本次决策的结果。
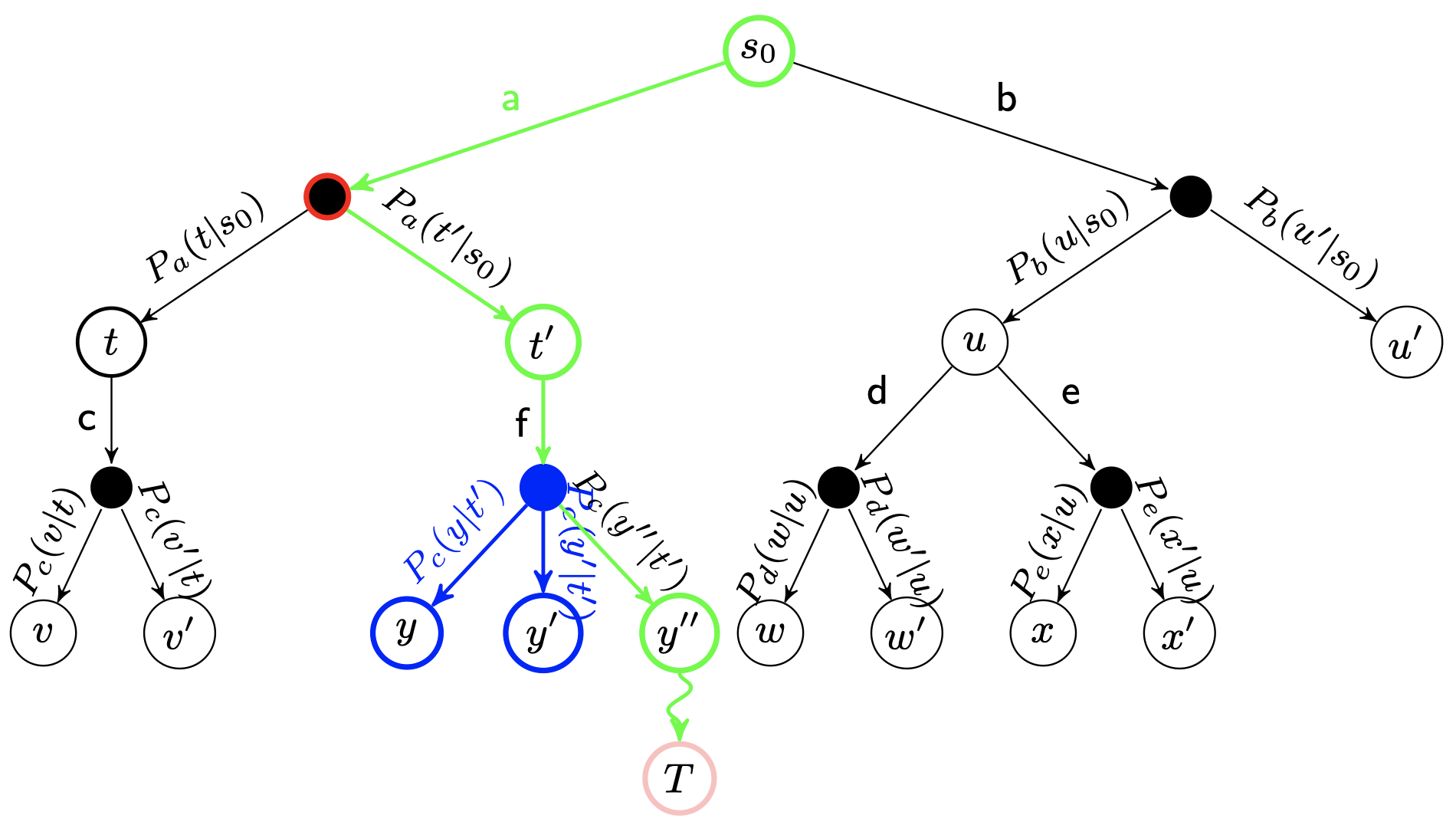
节点选择策略 {#节点选择策略}
1. Upper Confidence Bounds(UCB)- 节点评估函数 {#1-Upper-Confidence-Bounds(UCB)-节点评估函数}
我们知道,蒙特卡洛树搜索过程中,有两个情况下需要用到节点评估值,
- 「选择阶段」,在选择阶段,对一个已经完成探索的节点(所有可行动作都已探索过),我们需要按照一定的策略,根据子节点的评估值选择一个最优的子节点往下拓展。每拓展一次,就朝得到最终可行解的目标靠近了一些
- 「反向传播更新路径上节点的评估值」
UCB公式如下:
$$
v_i+C\times\sqrt{\frac{\ln N}{n_i}}
$$
其中 $v_i$ 是节点估计值,$n_i$ 是节点被访问的次数,而 $N$ 则是其父节点已经被访问的总次数。$C$ 是可调整参数。
UCB 公式对已知收益节点加强收敛,同时鼓励接触那些相对未曾访问的节点的尝试性探索。这是一个动态均衡公式。
每个节点的收益估计基于随机模拟不断更新,所以节点必须被访问若干次来确保估计变得更加可信,事实上,这也是随机统计的要求(大数情况下频率近似估计概率)。
理论上说,MCTS 估计会在搜索的开始不大可靠,而最终会在给定充分的时间后收敛到更加可靠的估计上,在无限时间下能够达到最优估计。
2. Asymmetric(非对称建树过程) {#2-Asymmetric(非对称建树过程)}
MCTS 按照一种非对称的策略进行树的搜索空间拓扑结构增长。这个算法会更频繁地访问更加有可能导致成功的节点,并聚焦其搜索时间在更加相关的树的部分。
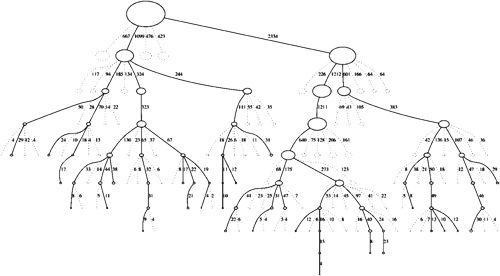
这使得 MCTS 更加适合那些有着更大的分支搜索空间的博弈游戏,比如说 $19 \times 19$ 的围棋。这么大的组合空间会给标准的基于深度或者宽度的搜索方法带来问题。但是 MCTS 会有选择地朝某些方向进行深度搜索,同时选择性地放弃其他显然不可能的方向。
MCTS算法代码示例 {#MCTS算法代码示例}
这个小节,我们来看一个MCTS实现的简单游戏对弈代码,笔者会先给出各个主要模块的说明,最后给出完整的可运行代码,
1. 节点类 {#1-节点类}
TreeNode 类里初始化了一些数值,主要是 父节点,子节点,访问节点的次数,Q值和u值,还有先验概率。同时还定义了选择评估函数(决定下一个子节点的生长方向),
选择函数根据每个动作(就是子节点)的UCB损失函数值,选择最优的动作作为下一个子节点生长方向。
2. 节点扩展 {#2-节点扩展}
expend() 的输入参数 action_priors 是一个包括的所有合法动作的列表(list),表示在当前局面我可以在哪些地方落子。此函数为当前节点扩展了子节点。
3. 模拟 {#3-模拟}
这里实现了一个基本的对弈游戏类,
-
MCTS类的初始输入参数:
-
policy_value_fn:当前采用的策略函数,输入是当前棋盘的状态,输出 (action, prob)元祖和score[-1,1]。
-
c_puct:控制探索和回报的比例,值越大表示越依赖之前的先验概率。
-
n_playout:MCTS的执行次数,值越大,消耗的时间越多,效果也越好。
-
-
_playout(self, state):
此函数有一个输入参数:state, 它表示当前的状态。
这个函数的功能就是 模拟。它根据当前的状态进行游戏,用贪心算法一条路走到黑,直到叶子节点,再判断游戏结束与否。如果游戏没有结束,则 扩展 节点,否则 回溯 更新叶子节点和所有祖先的值。
- get_move_probs(self, state, temp):
它的功能是从当前状态开始获得所有可行行动以及它们的概率。也就是说它能根据棋盘的状态,结合之前介绍的代码,告诉你它计算的结果,在棋盘的各个位置落子的胜率是多少。有了它,我们就能让计算机学会下棋。
- update_with_move(self, last_move):
自我对弈时,每走一步之后更新MCTS的子树。
与玩家对弈时,每一个回合都要重置子树。
4. 反向传播更新 {#4-反向传播更新}
将子节点的评估值反向传播更新父节点,每传播一次,来自初始子节点的评估值影响力就逐渐减弱。
update_recursive() 的功能是回溯,从该节点开始,自上而下地更新所有的父节点。
5. 构建一个MCTS的玩家 {#5-构建一个MCTS的玩家}
MCTSPlayer类的主要功能在函数 get_action(self, board, temp=1e-3, return_prob=0) 里实现。自我对弈的时候会有一定的探索几率,用来训练。与人类下棋是总是选择最优策略。
6. 完整代码 {#6-完整代码}
围棋AI AlphaGo中蒙特卡洛树搜索的应用 {#围棋AI-AlphaGo中蒙特卡洛树搜索的应用}
我们知道,下棋其实就是一个马尔科夫决策过程(MDP),根据当前棋面状态,确定下一步动作。问题在于,该下哪步才能保证后续赢棋的概率比较大呢?
对于这个问题,人类世界演化出了很多围棋流派,例如,
这些流派充满了领域先验主义的味道,完全是个别的领域专家通过自己长期的实战实践中通过归纳总结得到的一种指导性方法论。
现在转换视角,我们尝试用现代计算机思维来解决下围棋问题,最容易想到的就是枚举之后的每一种下法,然后计算每步赢棋的概率,选择概率最高的就好了:
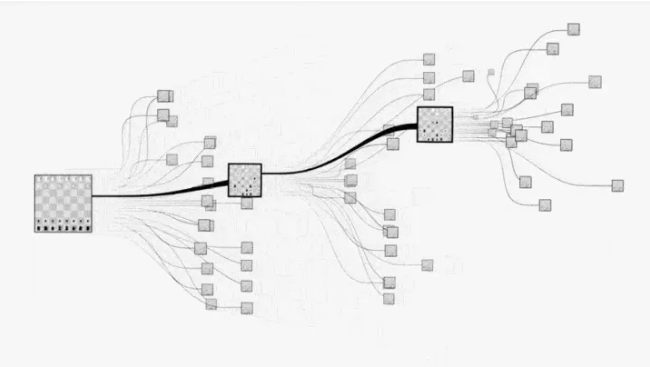
但是,对于围棋而言,状态空间实在是太大了,没有办法完全枚举。
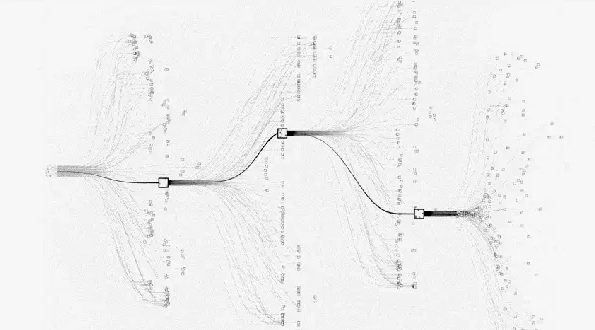
这个时候就需要蒙特卡洛树搜索进行启发式地搜索,这里所谓的启发式搜索,就是一种小范围尝试性探索的优化思路,随机朝一个方向前进,如果效果好就继续,如果效果不好就退回来。
- 在当前状态(每一步棋)的基础上,选择一个备选动作/状态(下一步棋),即一次采样;
- 从备选动作/状态开始,「走两步」,不需要枚举后续所有状态,只要以一定的策略(如随机策略和 AlphaGo 中的快速走棋网络)一直模拟到游戏结束为止;
- 计算这次采样的回报;
- 重复几次,将几次回报求平均,获得该备选动作/状态的价值。
参考资料 {#参考资料}
- https://www.cnblogs.com/LittleHann/p/11608182.html
- https://yey.world/2020/05/05/COMP90054-08/
- https://www.jiqizhixin.com/articles/monte-carlo-tree-search-beginners-guide

![左耳朵耗子 CoolShell 博客备份&基于 ChatGPT 问答机器人[开源]](https://img1.51tbox.com/static/2024-11-01/TvtxpoUQGajd.jfif)