本文仅用于学术分享,如有侵权,请联系后台作删文处理 导读 TensorRT是NVIDIA开发的一个可以进行高性能推理的C++库,是一个高性能推理优化引擎,其核心库是使用C++去加速NVIDIA生产的GPU。本文讲解了Tensorrt性能优化的相关知识,希望对大家有帮助!
导读 TensorRT是NVIDIA开发的一个可以进行高性能推理的C++库,是一个高性能推理优化引擎,其核心库是使用C++去加速NVIDIA生产的GPU。本文讲解了Tensorrt性能优化的相关知识,希望对大家有帮助!
一. 是什么?
2016年Nvidia为自家GPU加速推理而提供的SDK,人们有时也把它叫做推理框架。
二. 为什么?
只有Nvidia最清楚自家GPU或DLA该如何优化,所以TensorRT跑网络的速度是最快的,比直接用Pytorch快N倍。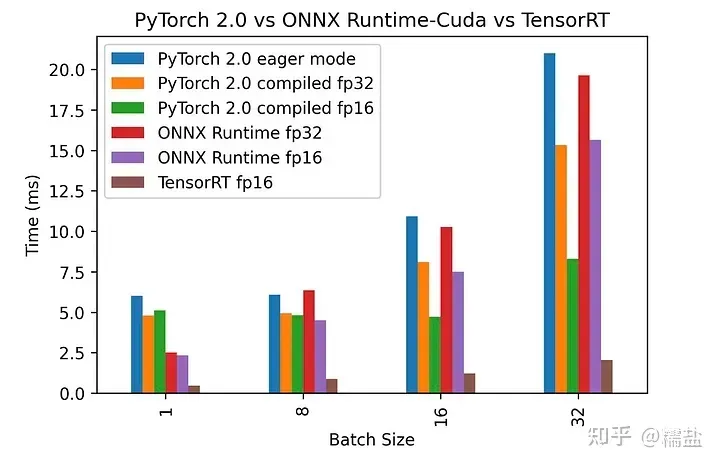 遥遥领先的TensorRT
遥遥领先的TensorRT
三. 怎么做到的?
1. 搜索整个优化空间
与Pytorch等其它训练框架最大区别是,TensorRT的网络优化算法是基于目标GPU或DLA硬件模型所做得推理性能的优化,而其它框架一方面需要综合考虑训练和推理,更重要的是它们没有在目标GPU上做针对性的优化。
TensorRT又是如何针对目标GPU优化的呢?
简单讲就是在可能的设计空间中搜索出全局最优解。
这个搜索空间有哪些变量呢?
比如CUDA架构中的编程模型所对应的,将tensor划分为多少个block?以及这些block如何组织到Grid中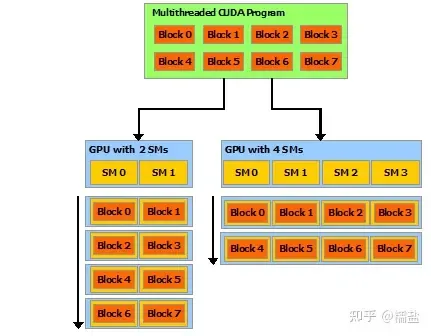
任务被划分为多个Block 
Block以Grid的方式组织起来 
再举例,使用什么样的指令完成计算,可能是FMA、MMA,可能是TensorCore指令... 更难的部分可能是tensor数据流的调度,把他们放在local、share还是global memory呢?如何摆放呢? 这些变量组合在一起是一个巨大的搜索空间,可能你的CPU计算几天也得不出个结果来。 但是我们知道神经网络的计算是由一个个粒度更大的算子组成的,算子上面还有粒度更大的层结构。我们也清楚地知道层与层之间相对独立,也就是说可以针对每层计算优化,最后把优化后的层串在一起大概率就是网络的全局最优解。 于是,TensorRT写了很多算子和层。当然这些算子的输入和输出tensor是可以配置的,以适应网络输入和输出的不同以及GPU资源的不同。  部分优化好的算子
部分优化好的算子
搜索空间变小了,从原来的指令级别的搜索,上升到了算子级别的搜索。因为这些算法都是用CUDA kernel所写,更准确的说是Kernel级别的搜索了。
但是tensor数据流的调度问题并没有解决,这也是最关键和复杂的地方。我们应该将输入tensor划分为多少个Block呢?这些Blocks应该分配给多少个线程呢?tensor存储在哪呢?local/share/global memory的哪些地方呢?中间计算结果存储在哪里呢?
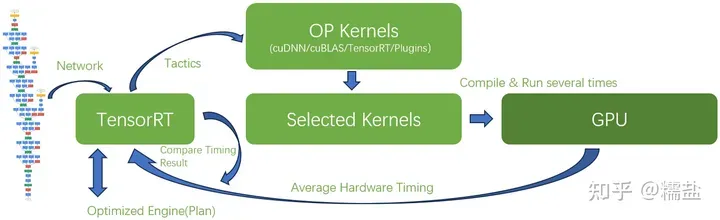
对于GPU上的share memory、L2 cache,也许可以通过模拟的方式(类似仿真器)计算得到性能的,但是加上Global Memory后就比较难通过CPU计算模拟较复杂的tensor数据流性能了,花费的时间可能无法让人忍受。所以干脆让某个优化结果在目标GPU上跑一跑试一试,统计出性能,多个优化结果对比选出最优解。
实际build(TensorRT流程的第一步)时**,TensorRT优化过程叫做Timing**,通过不同的优化策略得到的层会部署到硬件上实际运行,TensorRT甚至可以将优化的中间过程存储下来供你分析,叫做timing caching(通过trtexec --timingCacheFile= )
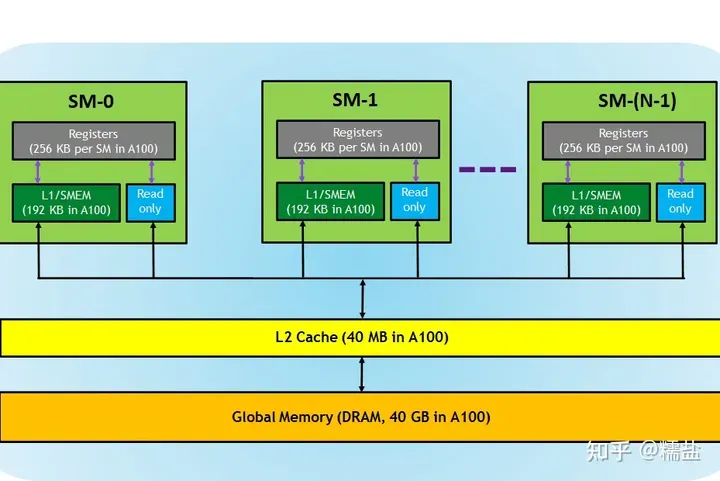 Nvida GPU memory架构
Nvida GPU memory架构
以上所描述的优化过程可以叫做Hardware Aware Optimazation 总结起来优化器会重点分析:
-
Type of hardware(DLA/Hardware capability...)
-
Memory footprint(Share, Cache, Global...)
-
Input and output shape
-
Weight shapes
-
Weight sparsity
-
Level of quantization (so, reconsider memory)
而这些是Pytorch等框架不会去深入挖掘的(会通过宏来适应一下不同线程数量,但类似适应很有限,尤其是存储系统的适配)
2. 强制选择Kernel
由于存储系统的具有很多不确定性,尤其是DRAM读写时间的不确定,多线程并行运行导致的访问随机性。优化结果可能不是最终实际推理时的最优结果。
如果这种不确定性导致了选择了不同的Kernel,TensorRT还提供了一个补救方法,就是强制制定只选择某个Kernel实现,如果你很确信它是最优解的话。
TensorRT提供的API叫做AlgorithmSelector
3. Plugin
当然,你对自己设计的算子更有把握,可以自己写Kernel,然后指定使用它
不过更多情况下,是因为发现TensorRT不支持某个算子,你才被迫去写Kernel,毕竟CUDA编程不简单,而且写的性能还足够好。
4. cuBLAS和cuDNN
TensorRT安装指导你需要先安装CUDA SDK和cuDNN
CUDA SDK需要安装是显而易见的,因为TensorRT所调用的Kernel需要NCCL编译器来编译成Nvidia GPU的汇编指令序列啊
但是CUDA SDK中还有一个cuBLAS库也是被TensorRT所依赖的,我们知道C++库BLAS(Basic Linear Algebra Subprograms),它是针对CPU进行的线性代数计算优化,那么cuBLAS就是针对CUDA GPU开发的线性代数计算库,它的底层当然也就是用CUDA Kernel写成的。典型的矩阵乘法算子就可以直接调用cuBLAS了。
cuBLAS开发的很早,应该是CUDA生态最早的一批库了吧,但是随着深度学习的普及,Nvidia又在生态中加入了cuDNN库,它的层次更高了,直接封装了优化后的网络层,所以其实TensorRT不是也可以直接调用优化好的cuDNN库中的Kernel吗?是也不是
从TensorRT源码看,TensorRT可以选择所谓**Tactic(策略)**来决定是使用TensorRT写的Kernel还是cuBLAS和cuDNN
5. Tactic
TensorRT的Tactic能决定很多优化选项
例如,每次timing某个算子时需要平均的运行次数。缺省TensorRT会运行四次,以降低存储系统不确定性带来的误差,但这个次数是可以修改的。
上面提到的Kernel库的选择,Plugin的选择等
甚至还有GPU的时钟频率,因为缺省情况下,GPU频率是动态变化的,基于此得到的优化结果可能和实际运行不一致,所以有时需要改为固定频率进行优化。
6. 量化
TensorRT当然具备网络量化能力,提供了将全网都量化到int8的隐性量化方式,也提供了插入Q/DQ Layer的显性量化方式。
混合量化是Nvidia做的很优秀的地方,这对于高效利用计算资源起到了重要作用,不过,这个另外的话题,以后有机会再谈。
- 多应用推理和多卡推理
其实这才是Nvidia强悍的地方,在友商都在谈单卡性能时,其实多卡或多节点才是Nvidia的杀手锏
另外,对于单卡性能富余的情况下,可能希望有多个流在并行推理,这个对于TensorRT来说也是必须支持的
由于这两个点暂时理解的还不够成熟,所以以后再谈。
四. TensorRT的里子到底是什么?
答:根据目标GPU的资源和能力,在各种已优化好的Kernel库中尝试挑选Kernel实际运行,然后选择最优结果的一个Hardware Aware优化器。
五. 编译器
最后,如果非要套用编译器前后端理论的话,上述谈到的部分应该属于编译器后端部分了,因为它已经和底层硬件息息相关了。只不过它逻辑上处于于NVCC这个实体编译器的上层。而编译器前端,也就是与硬件不相关的图融合部分是也是在TensorRT的Builder内完成的。
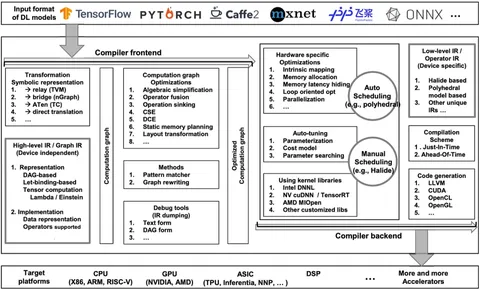 最后送上两幅图,作为总结
最后送上两幅图,作为总结 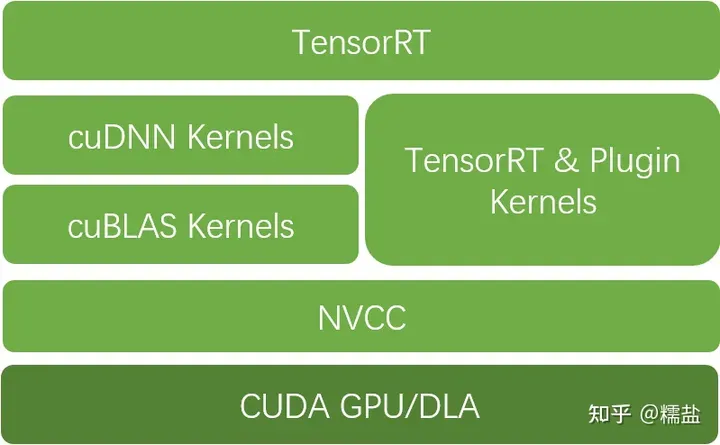
TensorRT工具链