软件介绍
Surya 是一个文档OCR工具包,提供强大的OCR(光学字符识别)和线条检测功能,支持90多种语言。近期热文:
|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------| | 5.5K Star 强强强!!!PPT在线制作的开源方案 13.8K Star开源!这个电子表格厉害了 1.5K 强强强!!!开源超强的AI助手,支持多系统 OA必备!!!开源一个好看的工作流设计器 |



-
OCR: 支持90多种语言的OCR,优于云服务的基准测试;
-
文本行检测: 可以在任何语言中进行行级文本检测;
-
排版分析: 包括表格、图像、页眉等的检测;
-
阅读顺序检测: 有助于文档内容的阅读顺序。
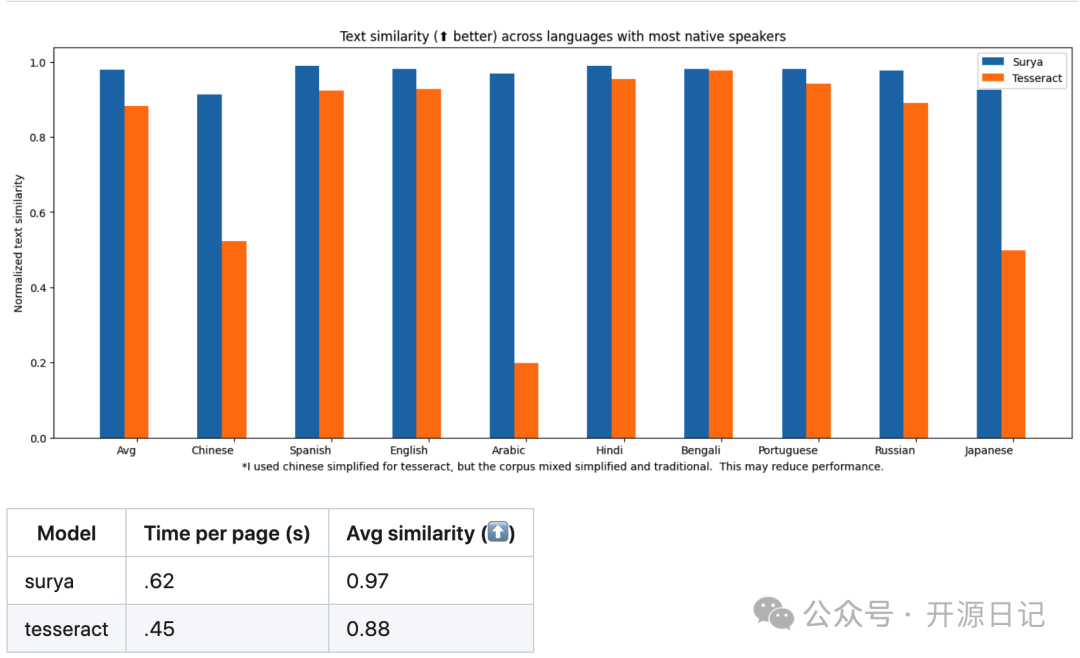
性能对比
surya和tesseract光学字符识别性能对比
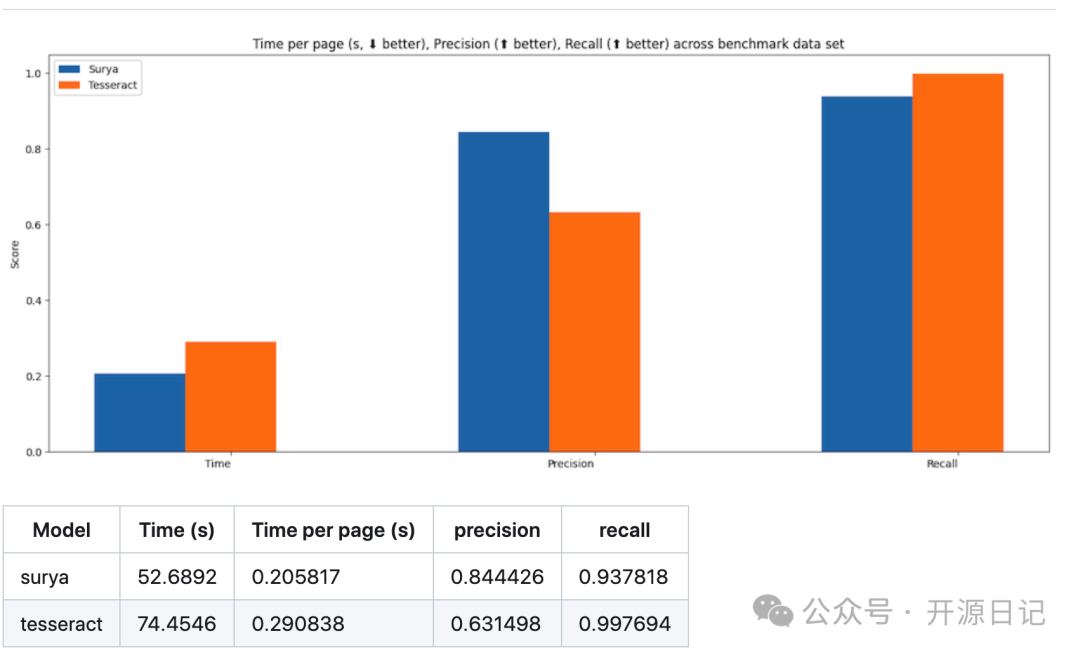
surya和tesseract文本行检测性能对比
快速入门
-
1.安装: 安装
surya-ocr需要 Python 3.9+ 和 PyTorch。首次运行会自动下载模型权重。pip install surya-ocr
-
2.文本识别(OCR): 根据示例代码运行OCR,识别图片中的文本信息;
from PIL import Image from surya.ocr import run_ocr from surya.model.detection import segformer from surya.model.recognition.model import load_model from surya.model.recognition.processor import load_processor
读取图像
image = Image.open(IMAGE_PATH) langs = ["en"] # 替换为具体语言 det_processor, det_model = segformer.load_processor(), segformer.load_model() rec_model, rec_processor = load_model(), load_processor()
运行 OCR
predictions = run_ocr([image], [langs], det_model, det_processor, rec_model, rec_processor)
-
3.文本行检测: 使用相应的模型进行文本行检测;
from PIL import Image from surya.detection import batch_text_detection from surya.model.detection.segformer import load_model, load_processor
读取图像
image = Image.open(IMAGE_PATH) model, processor = load_model(), load_processor()
进行文本行检测
predictions = batch_text_detection([image], model, processor)
-
4.排版分析: 使用提供的模型和处理器进行文档的排版分析;
from PIL import Image from surya.detection import batch_text_detection from surya.layout import batch_layout_detection from surya.model.detection.segformer import load_model, load_processor from surya.settings import settings
读取图像
image = Image.open(IMAGE_PATH) model = load_model(checkpoint=settings.LAYOUT_MODEL_CHECKPOINT) processor = load_processor(checkpoint=settings.LAYOUT_MODEL_CHECKPOINT) det_model = load_model() det_processor = load_processor()
进行排版分析
line_predictions = batch_text_detection([image], det_model, det_processor) layout_predictions = batch_layout_detection([image], model, processor, line_predictions)
-
5.阅读顺序检测: 进行文档内容的阅读顺序检测。
from PIL import Image from surya.ordering import batch_ordering from surya.model.ordering.processor import load_processor from surya.model.ordering.model import load_model
image = Image.open(IMAGE_PATH)
bboxes应该是一个包含[x1,y1,x2,y2]格式的图像布局框的列表
例如,可以从layout_model获取此信息,参见上面的用法示例
bboxes = [bbox1, bbox2, ...]
model = load_model() processor = load_processor()
进行阅读顺序检测
order_predictions = batch_ordering([image], [bboxes], model, processor)
Surya 的强大功能使其适用于处理各种类型的文档,其中包括文字识别、文本行检测、排版分析和内容阅读顺序检测。