- 为什么需要二次调度
Kubernetes 调度器的作用是将 Pod 绑定到某一个最佳的节点。为了实现这一功能,调度器会需要进行一系列的筛选和打分。
Kubernetes 的调度是基于 Request,但是每个 Pod 的实际使用值是动态变化的。经过一段时间的运行之后,节点的负载并不均衡。一些节点负载过高、而有些节点使用率很低。
因此,我们需要一种机制,让 Pod 能更健康、更均衡的动态分布在集群的节点上,而不是一次性调度之后就固定在某一台主机上。
- descheduler 的几种运行方式
descheduler 是 kubernetes-sigs 下的子项目,先将代码克隆到本地,进入项目目录:
git clone https://github.com/kubernetes-sigs/descheduler
cd descheduler
如果运行环境无法拉取 gcr 的镜像,可以将 k8s.gcr.io/descheduler/descheduler 替换为 k8simage/descheduler。
- 一次性 Job
只执行一次
kubectl create -f kubernetes/base/rbac.yaml
kubectl create -f kubernetes/base/configmap.yaml
kubectl create -f kubernetes/job/job.yaml
- 定时任务 CronJob
默认是 */2 * * * * 每隔 2 分钟执行一次
kubectl create -f kubernetes/base/rbac.yaml
kubectl create -f kubernetes/base/configmap.yaml
kubectl create -f kubernetes/cronjob/cronjob.yaml
- 常驻任务 Deployment
默认是 --descheduling-interval 5m 每隔 5 分钟执行一次
kubectl create -f kubernetes/base/rbac.yaml
kubectl create -f kubernetes/base/configmap.yaml
kubectl create -f kubernetes/deployment/deployment.yaml
- CLI 命令行
先在本地生成策略文件,然后执行 descheduler 命令
descheduler -v=3 --evict-local-storage-pods --policy-config-file=pod-life-time.yml
descheduler 有 --help 参数可以查看相关帮助文档。
descheduler --help
The descheduler evicts pods which may be bound to less desired nodes
Usage:
descheduler [flags]
descheduler [command]
Available Commands:
completion generate the autocompletion script for the specified shell
help Help about any command
version Version of descheduler
- 测试调度效果
-
cordon 部分节点,仅允许一个节点参与调度
kubectl get node
NAME STATUS ROLES AGE VERSION node2 Ready,SchedulingDisabled worker 69d v1.23.0 node3 Ready control-plane,master,worker 85d v1.23.0 node4 Ready,SchedulingDisabled worker 69d v1.23.0 node5 Ready,SchedulingDisabled worker 85d v1.23.0
-
运行一个 40 副本数的应用
可以观察到这个应用的副本全都在 node3 节点上。
kubectl get pod -o wide|grep nginx-645dcf64c8|grep node3|wc -l
40
- 集群中部署 descheduler
这里使用的是 Deployment 方式。
kubectl -n kube-system get pod |grep descheduler
descheduler-8446895b76-7vq4q 1/1 Running 0 6m9s
- 放开节点调度
调度前,所有副本都集中在 node3 节点
kubectl top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
node2 218m 6% 3013Mi 43%
node3 527m 14% 4430Mi 62%
node4 168m 4% 2027Mi 28%
node5 93m 15% 785Mi 63%
放开节点调度
kubectl get node
NAME STATUS ROLES AGE VERSION
node2 Ready worker 69d v1.23.0
node3 Ready control-plane,master,worker 85d v1.23.0
node4 Ready worker 69d v1.23.0
node5 Ready worker 85d v1.23.0
- 查看 descheduler 相关日志
当满足定时要求时,descheduler 就会开始根据策略驱逐 Pod。
kubectl -n kube-system logs descheduler-8446895b76-7vq4q -f
I0610 10:00:26.673573 1 event.go:294] "Event occurred" object="default/nginx-645dcf64c8-z9n8k" fieldPath="" kind="Pod" apiVersion="v1" type="Normal" reason="Descheduled" message="pod evicted by sigs.k8s.io/deschedulerLowNodeUtilization"
I0610 10:00:26.798506 1 evictions.go:163] "Evicted pod" pod="default/nginx-645dcf64c8-2qm5c" reason="RemoveDuplicatePods" strategy="RemoveDuplicatePods" node="node3"
I0610 10:00:26.799245 1 event.go:294] "Event occurred" object="default/nginx-645dcf64c8-2qm5c" fieldPath="" kind="Pod" apiVersion="v1" type="Normal" reason="Descheduled" message="pod evicted by sigs.k8s.io/deschedulerRemoveDuplicatePods"
I0610 10:00:26.893932 1 evictions.go:163] "Evicted pod" pod="default/nginx-645dcf64c8-9ps2g" reason="RemoveDuplicatePods" strategy="RemoveDuplicatePods" node="node3"
I0610 10:00:26.894540 1 event.go:294] "Event occurred" object="default/nginx-645dcf64c8-9ps2g" fieldPath="" kind="Pod" apiVersion="v1" type="Normal" reason="Descheduled" message="pod evicted by sigs.k8s.io/deschedulerRemoveDuplicatePods"
I0610 10:00:26.992410 1 evictions.go:163] "Evicted pod" pod="default/nginx-645dcf64c8-kt7zt" reason="RemoveDuplicatePods" strategy="RemoveDuplicatePods" node="node3"
I0610 10:00:26.993064 1 event.go:294] "Event occurred" object="default/nginx-645dcf64c8-kt7zt" fieldPath="" kind="Pod" apiVersion="v1" type="Normal" reason="Descheduled" message="pod evicted by sigs.k8s.io/deschedulerRemoveDuplicatePods"
I0610 10:00:27.122106 1 evictions.go:163] "Evicted pod" pod="default/nginx-645dcf64c8-lk9pd" reason="RemoveDuplicatePods" strategy="RemoveDuplicatePods" node="node3"
I0610 10:00:27.122776 1 event.go:294] "Event occurred" object="default/nginx-645dcf64c8-lk9pd" fieldPath="" kind="Pod" apiVersion="v1" type="Normal" reason="Descheduled" message="pod evicted by sigs.k8s.io/deschedulerRemoveDuplicatePods"
I0610 10:00:27.225304 1 evictions.go:163] "Evicted pod" pod="default/nginx-645dcf64c8-mztjb" reason="RemoveDuplicatePods" strategy="RemoveDuplicatePods" node="node3"
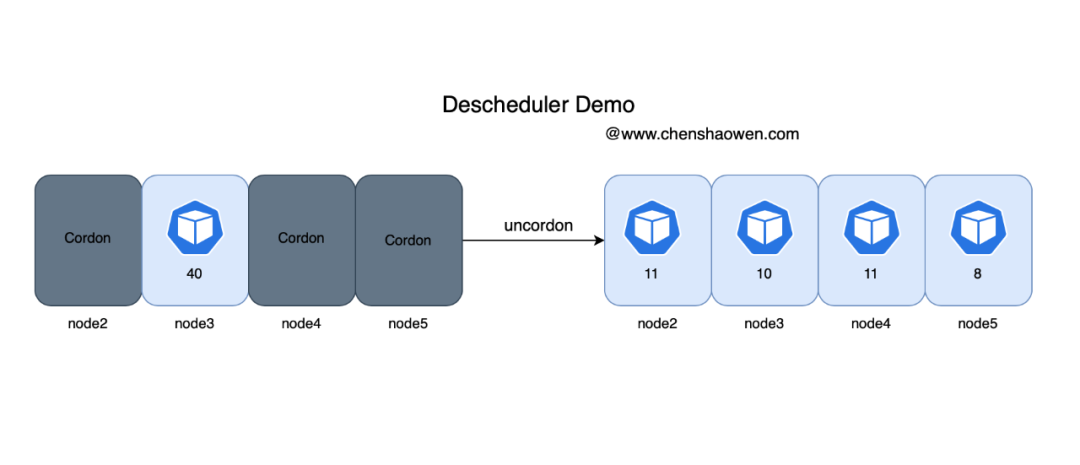
- 二次调度之后的 Pod 分布
节点的负载情况,node3 下降,其他节点都上升了一些。
kubectl top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
node2 300m 8% 3158Mi 45%
node3 450m 12% 3991Mi 56%
node4 190m 5% 2331Mi 32%
node5 111m 18% 910Mi 73%
Pod 在节点上的分布,这是在没有配置任何亲和性、反亲和性的场景下。
| 节点 | Pod数量(共40副本) | |-------|--------------| | node2 | 11 | | node3 | 10 | | node4 | 11 | | node5 | 8 |
Pod 的数量分布非常均衡,其中 node2-4 虚拟机配置一样,node5 配置较低。如下图是整个过程的示意图:
- descheduler 调度策略
查看官方仓库推荐的默认策略配置:
cat kubernetes/base/configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: descheduler-policy-configmap
namespace: kube-system
data:
policy.yaml: |
apiVersion: "descheduler/v1alpha1"
kind: "DeschedulerPolicy"
strategies:
"RemoveDuplicates":
enabled: true
"RemovePodsViolatingInterPodAntiAffinity":
enabled: true
"LowNodeUtilization":
enabled: true
params:
nodeResourceUtilizationThresholds:
thresholds:
"cpu" : 20
"memory": 20
"pods": 20
targetThresholds:
"cpu" : 50
"memory": 50
"pods": 50
默认开启了 RemoveDuplicates、RemovePodsViolatingInterPodAntiAffinity、LowNodeUtilization 策略。我们可以根据实际场景需要进行配置。
descheduler 目前提供了如下几种调度策略:
- RemoveDuplicates
驱逐同一个节点上的多 Pod
- LowNodeUtilization
查找低负载节点,从其他节点上驱逐 Pod
- HighNodeUtilization
查找高负载节点,驱逐上面的 Pod
- RemovePodsViolatingInterPodAntiAffinity
驱逐违反 Pod 反亲和性的 Pod
- RemovePodsViolatingNodeAffinity
驱逐违反 Node 反亲和性的 Pod
- RemovePodsViolatingNodeTaints
违反 NoSchedule 污点的 Pod
- RemovePodsViolatingTopologySpreadConstraint
驱逐违反拓扑域的 Pod
- RemovePodsHavingTooManyRestarts
驱逐重启次数太多的 Pod
- PodLifeTime
驱逐运行时间超过指定时间的 Pod
- RemoveFailedPods
驱逐失败状态的 Pod
- descheduler 有哪些不足
- 基于 Request 计算节点负载并不能反映真实情况
在源码 https://github.com/kubernetes-sigs/descheduler/blob/028f205e8ccc49440bd52940eb78a737f8f5b824/pkg/descheduler/node/node.go#L253 中可以看到,descheduler 是通过合计 Node 上 Pod 的 Request 值来计算使用情况的。
这种方式可能并不太适合真实场景。如果能直接拿 metrics-server 或者 Prometheus 中的数据,会更有意义,因为很多情况下 Request、Limit 设置都不准确。有时,为了节约成本提高部署密度,Request 甚至会设置为 50m,甚至 10m。
- 驱逐 Pod 导致应用不稳定
descheduler 通过策略计算出一系列符合要求的 Pod,进行驱逐。好的方面是,descheduler 不会驱逐没有副本控制器的 Pod,不会驱逐带本地存储的 Pod 等,保障在驱逐时,不会导致应用故障。但是使用 client.PolicyV1beta1().Evictions 驱逐 Pod 时,会先删掉 Pod 再重新启动,而不是滚动更新。
在一个短暂的时间内,在集群上可能没有 Pod 就绪,或者因为故障新的 Pod 起不来,服务就会报错,有很多细节参数需要调整。
- 依赖于 Kubernetes 的调度策略
descheduler 并没有实现调度器,而是依赖于 Kubernetes 的调度器。这也意味着,descheduler 能做的事情只是驱逐 Pod,让 Pod 重新走一遍调度流程。如果节点数量很少,descheduler 可能会频繁的驱逐 Pod。
- descheduler 有哪些适用场景
descheduler 的视角在于动态,其中包括两个方面:Node 和 Pod。Node 动态的含义在于,Node 的标签、污点、配置、数量等发生变化时。Pod 动态的含义在于,Pod 在 Node 上的分布等。
根据这些动态特征,可以归纳出如下适用场景:
- 新增了节点
- 节点重启之后
- 修改节点拓扑域、污点之后,希望存量的 Pod 也能满足拓扑域、污点
- Pod 没有均衡分布在不同节点
- 参考
- https://github.com/kubernetes-sigs/descheduler