掌握的技术
-
java 框架:ssm(spring,springmvc,mybatis) springboot+mybatis springcloud(不会)
-
数据库:oracle mybatis
-
代码管理工具:git maven
-
接口测试工具:swagger postman
-
前端:html css js 微信小程序
-
框架:elementUI vue(不会)
-
缓存工具:redis mq(不会)
-
代码编写工具:idea
-
权限控制:shiro(不会)
-
项目部署 ok
-
redis线程模型,各种高并发问题,如缓存雪崩、缓存穿透、缓存击穿
-
缓存击穿:当一个key非常热门(类似于爆款),比如之前的老坛酸菜牛肉面新闻一出,瞬间老坛酸菜牛肉面成为爆款,在这个key失效的一瞬间,大量的访问涌入缓存,缓存不存在又进入数据库中才查询,并存入Redis中,导致性能下降。
方案:设置永不过期、超过多少访问量永不过期、加锁排队(设置同步锁)、分布式锁。

-
-
缓存雪崩:缓存集中过期或者缓存服务器宕机,导致大量请求访问数据库,造成服务器瞬间压力过大导致宕机。 方案: (1)缓存集中过期:设置一个随机过期时间,不让它们同时过期。
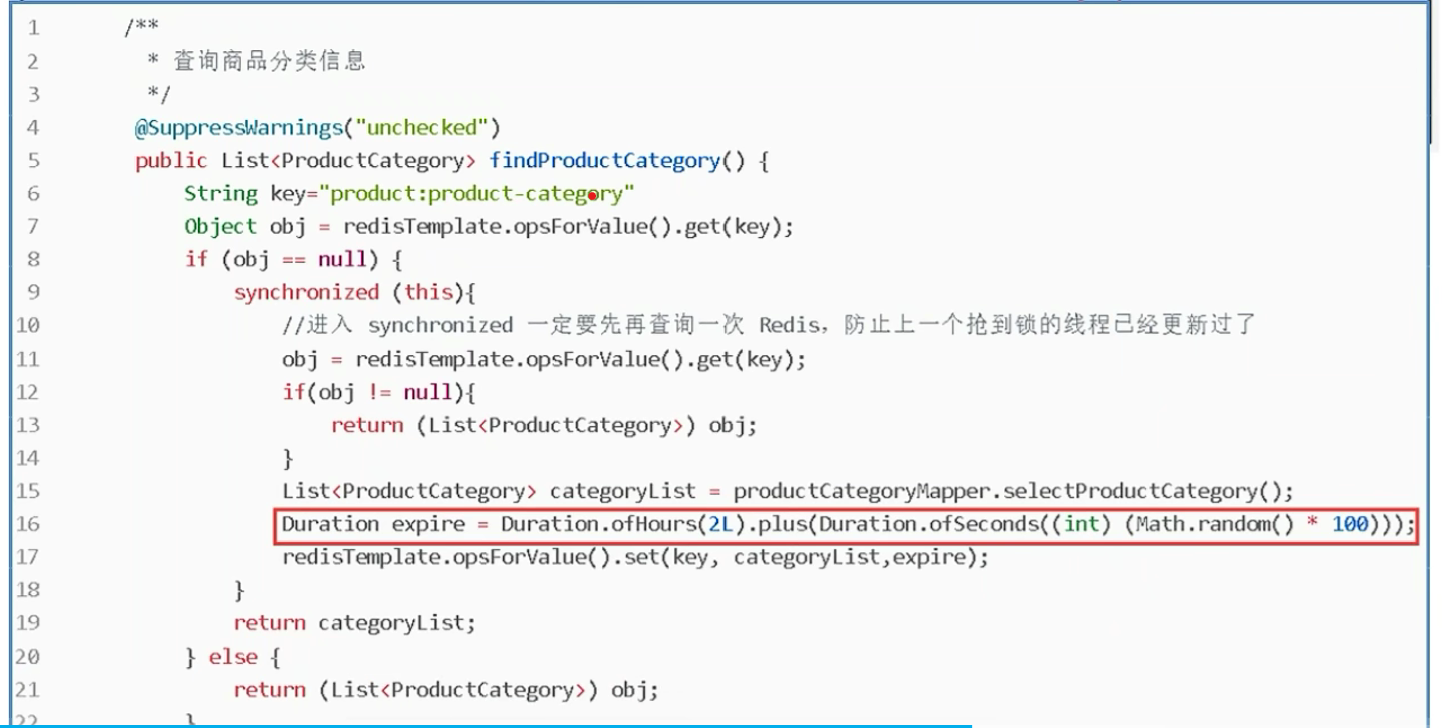 (2)宕机:设置多个redis集群,使用哨兵模式,当一个缓存服务器过期,切换另一个服务器。 (3)服务器断电:做多个机房,当一个机房断电时切换另一个机房。
(2)宕机:设置多个redis集群,使用哨兵模式,当一个缓存服务器过期,切换另一个服务器。 (3)服务器断电:做多个机房,当一个机房断电时切换另一个机房。 -
缓存穿透:redis中没有,然后请求数据库,数据库中也没有,这种现象称之为缓存穿透。请求大量的id,一些负数或者非常大的id,伪造大量的请求攻击我们的应用,系统撑不住然后挂掉(服务器宕机)。 方案: (1)参数校验,无法完全避免(id非常大或者redis和数据库中刚好没有) (2)无论数据库中没有数据都进行缓存,但是要设置过期时间(随机过期) (3)布隆过滤器(一种数据结构,比list、set更加高效,并且占用空间更少) 黑名单:将不存在的数据放入布隆过滤器中,id在布隆过滤器中查找没有数据然后在数据库中找也没有,缓存一个空的到布隆过滤器中。然后下次用户再找的话,布隆过滤器中就有了,直接返回空,这种称之为黑名单方式。黑名单就是我没有的数据放入布隆过滤器中。 白名单:将数据库有的数据放入布隆过滤器中,布隆过滤器中有就执行后面的操作,没有直接返回。
面试难点
-
单线程、多线程的运用
(1)实现Runnable接口,重写run()方法
(2)继承thread类,实现接口的同时还可以继承其它类,不能返回线程执行的结果
(3)实现callable接口,实现接口的同时还可以继承其它类,可以得到线程执行的结果

使用单线程或多线程主要取决于应用场景和需求。一般来说:使用单线程的情况:
-
当有多个任务可以并发执行时,可以通过多线程提高程序的执行效率。
-
当一个任务包含独立的多个子任务时,可以为每个子任务开一个线程,同时执行。
-
当需要在后台执行耗时较长的任务时,使用多线程可以避免程序被阻塞。
-
需要同时监控或更新多个数据源时,使用多线程可以同时监听每个数据源。
-
需要提高任务的响应速度,如GUI程序中的事件监听等,使用多线程可以在后台完成任务。所以,总结来说:如果任务简单、顺序性要求高且资源受限,应使用单线程。如果需要并发执行多个任务、提高执行效率或响应速度、在后台执行耗时任务,应使用多线程。在实际应用中,也会根据需要将单线程和多线程结合使用。如计算密集型任务使用多线程,I/O 密集型任务使用单线程等。需要注意的是,使用多线程也会带来额外的开销,如线程上下文切换、同步等会影响程序性能。所以并不意味着多线程一定比单线程效率高。
-
任务很简单,不需要并发执行。使用单线程可以简化程序逻辑,避免线程同步等问题。
-
资源受限,不能支持多线程同时访问。如一些硬件设备接口等。
-
需要保证任务以特定顺序串行执行。使用多线程的情况:
-
-
虚拟机jvm
JVM(Java Virtual Machine) 是 Java 语言的运行环境。它是一个虚拟机,能够执行 Java 字节码。JVM 的主要组成部分有:
-
类加载器(ClassLoader):用于加载 Java 类字节码,并将其转换为类的运行时数据结构。
-
运行时数据区:用于存储已加载的类信息、对象实例、数组等运行时数据。它包含:- 方法区:存储已加载的类信息、常量、静态变量等。 - 堆:存储对象实例。 - 栈:存储本地方法的变量、本地方法调用等。 - 本地方法栈:与操作系统交互的方法。
-
执行引擎:用于执行字节码并运行 Java 程序。它包含:- 解释器:逐行执行字节码。 - 编译器:将字节码编译为机器码,提高执行效率。 - 优化器:对编译后的代码进行优化,提高性能。
-
垃圾收集器(GC):用于自动释放未使用的堆内存,管理堆内存。
-
JVMTI(JVM Tool Interface):提供了对运行期 Java 应用程序进行监控和管理的能力。许多程序设计工具和框架使用该接口。所以,JVM 具有以下主要作用: 1. 运行 Java 字节码并执行 Java 程序 2. 提供与操作系统无关的运行环境,实现 "一次编写,到处运行" 3. 负责 Java 对象的创建、存储和垃圾收集 4. 存储并管理 Java 运行时数据 5. 加载和验证 Java 字节码文件
-
5.什么是面向对象?
面向对象是一种抽象和封装复杂问题的方法。它通过将问题分解为合适的对象来建模,而不是利用过程来组织代码。面向对象的主要特征包括:
* 封装(Encapsulation)将对象的数据与行为封装在一起,数据被隐藏在对象的内部,只能通过对象提供的接口访问。这有助于模块化设计和实现信息隐藏。
* 继承(Inheritance)子类继承父类的属性和方法,可以复用父类的代码并扩展其功能。这有利于实现代码重用和抽象不同的事物之间的共性。
* 多态(Polymorphism)子类可以实现父类的方法,产生不同的行为。这使得可以针对抽象父类进行设计和编程,从而具有更强的扩展性。
* 抽象(Abstraction)抽象是一种思维模型,关注对象的本质和忽略细节。它提取对象的共性特征,形成抽象类或接口。所以,面向对象通过将问题抽象为对象及其之间的关系进行建模,避免以过程为中心对事物进行组织,这使得我们可以清晰地表达概念、简洁地组织结构,并灵活地进行扩展。它带来的抽象、继承、封装和多态等概念,使得我们可以构建模块化、延展性强的系统。
-
java基本数据类型的二进制位以及字节 byte 1字节 short 2字节 int 4字节 long 8字节 char 2字节 float 4字节 double 8字节 boolean 1字节(实际使用1比特)
这是 Java 中各个基本类型的大小(以位为单位)。
-
byte:8位,范围为-128到127
-
char:16位,0到65535
-
short:16位,-32768到32767
-
int:32位,-2147483648到2147483647
-
float:32位,单精度浮点数
-
long:64位,-9223372036854775808到9223372036854775807
-
double:64位,双精度浮点数
-
boolean:未指定具体大小,true或false
-
-
常量池(Constant Pool)是 Java 中一个很重要的概念。它是方法区的一部分,用于存储编译期生成的各种字面量和符号引用。常量池主要有以下两种常量:
这里 s1 和 s2 指向的并不是两个不同的字符串对象,而是同一个常量池中的 "Hello" 常量。所以只占用一段内存空间。
-
字面量:如字符串常量
"Hello World" -
符号引用:用于类和接口的相关信息,如类名、方法名、字段名等常量池的主要作用是:节省内存空间。如果每个字符串对象都单独创建,会占用大量内存,而将重复的字符串常量放在常量池中进行共享,可以极大减少内存开销。举个例子:
String s1 = "Hello"; String s2 = "Hello";
-
-
class 的访问修饰符 1.private:私有的。只能在当前类中访问。 private 修饰的成员变量和方法,外部类无法访问。这也是对象封装的一种表现形式。
-
private 只能在当前类访问
-
默认在当前包可访问
-
protected 在当前类、同包类、子类可访问
-
public 所有地方都可访问
-
默认:默认就是 package private。在当前包内可以访问,外部包无法访问。如果不加修饰符,则默认为 package private。
-
public:公有的。可以在任意位置访问。public 修饰的成员变量和方法,可以在当前类中、同一包中的类中以及外部包的类中访问。
-
protected:受保护的。可以在当前类中、同一包中的类中以及继承当前类的子类中访问。对于同一包中的无关类,protected 修饰的成员变量和方法是invisible的。所以,总结来说:
-
-
io流是干什么的?
-
读写文件:I/O 流可以用于读取和写入文件,实现文件的上传、下载等操作。例如使用 FileInputStream 读取文件,FileOutputStream 写入文件。
-
网络传输:I/O 流可以用于实现网络通信中的数据传输。例如 SocketInputStream 从 Socket 中读取数据,SocketOutputStream 写入数据到 Socket。
-
读写内存:I/O 流可以操作字节数组和字符数组,实现内存中的数据读写。例如 ByteArrayInputStream 从字节数组中读取数据, CharArrayWriter 写入数据到字符数组。
-
数据转换:I/O 流可以在字节流和字符流之间进行转化,实现编码与解码的功能。例如 InputStreamReader 将字节流转为字符流,OutputStreamWriter 将字符流转为字节流。
-
对象序列化:对象流可以实现 Java 对象的序列化与反序列化。例如 ObjectInputStream 读取和反序列化对象,ObjectOutputStream 将 Java 对象序列化为字节输出。所以,总的来说,I/O 流主要用于:- 文件读写:实现文件上传下载等操作 - 网络通信:Socket 编程中的数据传输 - 内存操作:读写内存中的字节数组与字符数组 - 数据转换:在字节流与字符流之间相互转化 - 对象序列化:实现对象的序列化与反序列化I/O 流为我们提供了一套抽象的接口,通过这套接口我们可以以统一的方式操作各种数据源。理解和熟练使用 Java 的 I/O 流有助于我们编写更加强大和灵活的程序
-
-
java项目cpu满了怎么办
当 Java 项目 CPU 占用过高时,我们需要对项目进行优化,以减少 CPU 的使用量。主要有以下优化措施:
-
分析 CPU 占用高的原因:使用 CPU 分析工具查看项目的 CPU 占用情况,找到占用率最高的方法或代码块,分析其原因。常见原因有:- 过度优化:如无谓的循环嵌套导致 CPU 计算量剧增。 - 缺乏算法:采用的算法效率较低,可以使用更高效的算法改进。 - 频繁 I/O:如遍历大文件等,可通过缓存提高效率。 - 同步阻塞:如使用同步方法频繁阻塞线程,可以改使用异步非阻塞方式。 - GC 过于频繁:可通过调整堆内存大小等方式优化 GC。
-
选择高效算法:如使用更高效的排序、查找算法;采用缓存策略等来减少计算量。
-
避免过度优化:避免不必要的循环嵌套、方法调用等,保持代码优化得当。
-
提高并发度:如使用多线程提高并发执行,充分利用 CPU 资源。但需注意线程同步和上下文切换的性能开销。
-
缓存和批处理:如使用数据缓存减少数据库访问;采用批处理提高网络 I/O 效率等。
-
减少对象创建:避免创建不必要的对象,特别在高频循环或方法中。可重用已有对象。
-
JVM 调优:可以调整 JVM 参数以优化运行环境,如设置堆内存大小、GC 策略、JIT 编译器参数等。
-
分布式部署:可以将项目分布到多台服务器上部署,分散 CPU 资源的消耗,提高整体Throughput。除此之外,也可以从代码架构上进行优化,提高项目的扩展性和低耦合。这有助于系统的性能提高。总之,进行 Java 项目 CPU 优化需要全面分析项目,从代码算法、架构设计、运行环境等多方面采取优化措施。只有深入理解代码运行机制和环境,才能达到很好的优化效果。
-
-
什么是mq(消息队列),它是干什么的?
MQ(Message Queue)消息队列是一种应用程序之间的通信方式,应用程序通过读取和写入消息的方式来通信,而无需专用连接来链接它们。MQ 的主要作用有:
-
点对点模型:一条消息只能被一个消费者消费。常见的如ActiveMQ、RabbitMQ等。
-
发布/订阅模型:一条消息可以被多个消费者消费。常见的如Kafka等。所以,总体来说,MQ 的主要作用是:
-
在分布式系统中实现异步通信,提高响应速度和吞吐量。
-
实现流量削峰,通过消息缓存实现生产者和消费者的解耦。
-
提供高可靠的消息传输机制,确保消息不丢失。
-
实现应用程序的松耦合,生产者和消费者无需知道对方的存在。
-
异步通信:应用程序通过消息传递来实现异步通信,无需等待对方的响应。这样可以提高系统的响应速度和吞吐量。
-
流量削峰:通过消息队列缓存消息,达到流量削峰的目的。应用程序可以先将消息写入队列,再从队列按自己的消费速度获取消息进行消费。
-
解耦:生产者无需知道具体的消费者,只需将消息发送到 MQ 即可;消费者无需知道具体的生产者,只需从 MQ 获取消息即可。这样应用程序之间可以实现松耦合。
-
可靠性:MQ 本身具有消息持久化、高可用等特性,能够确保消息不丢失,提高系统的可靠性。MQ 的基本模型有两种:
-
-
mysql一些基本的操作
MySQL 中常用的基本操作有:
- 唯一性:UNIQUE - 非空性:NOT NULL - 外键:FOREIGN KEY - 默认值:DEFAULT
-
数据库操作 - 创建数据库:CREATE DATABASE database_name; - 删除数据库:DROP DATABASE database_name; - 选择数据库:USE database_name; - 列出数据库:SHOW DATABASES;
-
表操作 - 创建表:CREATE TABLE table_name(...); - 删除表:DROP TABLE table_name; - 修改表:ALTER TABLE table_name ...; - 列出表:SHOW TABLES; - 查看表结构:DESC table_name;
-
记录操作 - 插入记录:INSERT INTO table_name (field1, field2) VALUES (value1, value2); - 批量插入:INSERT INTO table_name (field1, field2) VALUES (value1, value2), (value3, value4); - 更新记录:UPDATE table_name SET field1=value1 WHERE ...; - 删除记录:DELETE FROM table_name WHERE ...; - 查询记录:SELECT * FROM table_name;
-
数据类型 - 整数:TINYINT、SMALLINT、MEDIUMINT、INT、BIGINT - 浮点数:FLOAT、DOUBLE - 定点数:DECIMAL - 字符串:CHAR、VARCHAR、TEXT、BLOB - 日期时间:DATE、TIME、DATETIME、TIMESTAMP - ...
-
运算符和函数 - 算术运算符:+、-、*、/、% 等 - 比较运算符:=、!=、>、<、>=、<= 等 - 逻辑运算符:AND、OR、NOT 等 - 函数:COUNT()、MAX()、MIN()、AVG()、SUM()、...
-
约束 - 主键:PRIMARY KEY
-
索引 - 普通索引:CREATE INDEX - 唯一索引:CREATE UNIQUE INDEX - 主键自动创建唯一索引 - 可以创建复合索引
-
mysql如何优化?
MySQL 优化主要从以下几个方面进行:
-
SQL 语句优化:- 避免全表扫描:使用索引来避免全表扫描。 - 避免在 WHERE 条件中对字段进行 NULL 值判断:这会导致索引失效,转成全表扫描。 - 尽量使用数字型字段的范围条件而不是 LIKE:LIKE 会导致全表扫描。 - 优化子查询:可以将子查询转为联表查询。 - 避免排序和分组:排序和分组会消耗大量资源。
-
索引优化:- 选择适当的索引类型: Hash索引、B-tree索引等。 - 索引列的选择:选择区分度高和频繁作为条件的列。 - 索引顺序的选择:索引的顺序会影响查找效率。 - 索引分类:可单列索引、组合索引、前缀索引等。 - 过多索引的避免:不要在低区分度的列或小表上创建太多索引。
-
数据库结构优化:- 表结构拆分:将大表拆分为小表,提高查询效率。 - 行数过大的表拆分:行数过大会影响查询效率,应考虑拆分。 - 字段类型的选择:选择正确的字段类型可以节省存储空间,提高查询效率。 - favor 并行处理:提高并发操作的性能。
-
服务器参数优化:- 提高 sort_buffer_size 参数:增大 ORDER BY 的效率。 - 提高 read_buffer_size 参数:增大索引的效率。 - 设置合理的 max_connections 参数:控制最大连接数,避免过多连接导致服务器负载过高。 - 设置 query_cache_size 参数:控制 Query 缓存区大小,加速重复查询。 - 修改 table_cache 参数:控制表缓存数量,加速表打开操作。
-
存储引擎的选择:- InnoDB:支持事务、行级锁,适合高并发操作。 - MyISAM:不支持事务和行级锁,读性能高,适合作为数据仓库。 - MEMORY:数据存放在内存,速度最快,数据量有限。
-
-
map和hashmap的区别?
Map 和 HashMap 都是 Java 中的集合类,用于存储键值对。主要区别有:
-
Map 是接口,HashMap 是接口的具体实现类。
-
HashMap 使用散列结构存储,允许 null 键和值,线程不安全;Map 接口没有规定存储结构和 null 值,也不涉及线程安全。
-
HashMap 有默认的初始容量 16 和负载因子 0.75;Map 接口中未定义默认值。
-
HashMap 实现了 Map 接口,继承自 AbstractMap。需要注意的是,虽然 HashMap 是非同步的,但 Java 还提供了线程安全的 HashMap,即 ConcurrentHashMap。所以根据需要可以选择使用 HashMap 或 ConcurrentHashMap。
-
Map 是接口,HashMap 是接口的实现类。Map 定义了键值对接口,HashMap 实现了该接口,提供了具体功能。
-
HashMap 存储数据采用哈希表结构,由数组和链表组成。Map 接口仅定义了方法,没有具体存储结构。
-
HashMap 中的 key 和 value 都允许为 null,Map 接口中没有对 null 值作出规定。
-
HashMap 是非同步的,而 Hashtable 是线程安全的,其实现也不同。HashMap适用于单线程环境,Hashtable 适用于多线程环境。
-
HashMap 的初始容量大小为 16,负载因子是 0.75。Map 接口中没有定义默认值。
-
HashMap 实现了 Map 接口,继承于 AbstractMap,所以它是一个 Map 的具体实现类。所以,主要区别可以归纳为:
-
-
java的基本数据类型?
-
float:4 个字节,约 6-7 位有效数字,范围约 ±3.403E38
-
double:8 个字节,约 15-16 位有效数字,范围约 ±1.797E3083. 字符型:用于存储字符。
-
char:2 个字节,范围 0 ~ 655354. 布尔型:用于存储真或假。
-
boolean:1 个字节,只有 true 和 false 两个值
-
short:2 个字节,范围 -32768 ~ 32767
-
int:4 个字节,范围 -2147483648 ~ 2147483647
-
long:8 个字节,范围 -9223372036854775808 ~ 9223372036854775807
-
浮点数型:用于存储小数值。
-
整数型:用于存储整数值。- byte:1 个字节,范围 -128 ~ 127
-
-
对象的基本特征
面向对象编程的基本特征有:
-
封装:隐藏对象的实现细节,提高程序的安全性和可维护性。
-
继承:可以重用已有类的方法和字段。
-
多态:可以编写可重用的代码。
-
抽象:可以提取对象共有的特征,提高代码的复用性。掌握这四大特征,是学习面向对象编程的基础。它们通过提高代码的安全性、复用性和可维护性,使我们能够更高效和低成本地进行软件开发。
-
封装:将对象的属性和方法封装在一起,对外提供有限的访问接口。这可以隐藏对象的实现细节,提高程序的安全性和可维护性。Java 中通过 private、public、protected 等访问修饰符来控制封装程度。
-
继承:继承允许创建一个新类,这个新类继承一个已有的类的字段和方法。继承可以让我们重用已有类的方法和字段,而无需重新编写代码。在 Java 中使用 extends 关键字来实现继承,子类继承父类。
-
多态:多态允许使用父类类型的变量调用子类对象的方法。这允许我们编写可以重用的代码。在 Java 中,我们可以通过方法重载(overloading)和方法重写(overriding)来实现多态。前者在编译时就确定调用的方法,后者在运行时才确定调用的方法。
-
抽象:抽象允许提取对象共有的特征,并将非共有的特征抽象出去。这可以提高代码的复用性。在 Java 中,我们可以使用抽象类和接口来定义抽象方法,让子类实现具体的方法。所以,面向对象的四大特征为:
-