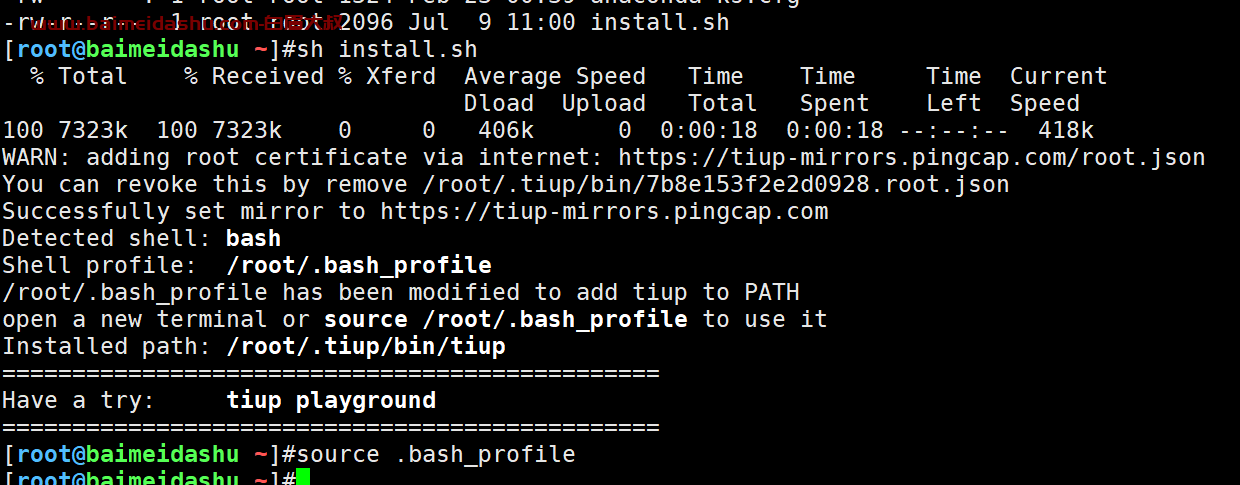
Elasticsearch报错initial heap size
<p>当前elasticsearch版本8.11.4,报错内容如下:<br /> [ERROR][o.e.b.Elasticsearch ] [ceph1] node validation exception [1] bootstrap checks failed. You must address the points described in the...
<p>当前elasticsearch版本8.11.4,报错内容如下:<br /> [ERROR][o.e.b.Elasticsearch ] [ceph1] node validation exception [1] bootstrap checks failed. You must address the points described in the...

<p>一定要安装bzip2包、一定要安装bzip2包、一定要安装bzip2包</p> <p>1、下载head插件源码<br /> cd /usr/local/src git clone https://github.com/mobz/elasticsearch-head.git cd elasticsearch-head</...
<p>说到 Elasticsearch,其中最明显的一个特点就是 near real-time 准实时,当文档存储在 Elasticsearch 中时,将在 1 秒内以几乎实时的方式对其进行索引和完全搜索。那为什么说 ES 是准实时的呢?</p> <h2>Lucene 和 ES</h2> <h3><strong&...
--Bodisparking恶意代码")
<h1>0x00 发现</h1> <hr /> <p>接到客户需求,对其互联网办公区域主机安全分析。在对某一台主机通信数据进行分析时,过滤了一下HTTP协议。</p> <p><img src="http://static.51tbox.com/static/2024-12-22/col/05...
<h1>0x00 发现</h1> <hr /> <p>接到客户需求,对其互联网办公区域主机安全分析。在对某一台主机通信数据进行分析时,过滤了一下HTTP协议。</p> <p><img src="http://static.51tbox.com/static/2024-12-23/col/32...
<p>Spark SQL允许大家在Python、Java以及Scala中使用数据帧;利用多种结构化格式读取并写入数据;通过SQL进行大数据查询。</p> <p>Spark SQL属于Spark用于处理结构化与半结构化数据的接口。结构化数据是指那些拥有一定模式的数据,包括JSON、Hive Tables以及Parquet。模式意味着每条记录都拥...
<p>1月才刚释出1.6版的大数据技术Spark,下一个2.0版本预计4、5月释出,将提供可运行在SQL/Dataframe上的结构化串流即时引擎,并统一化Dataset及DataFrame</p> <br /> <p><img src="http://static.51tbox.com/static/2024-1...

<p>有些时候我们想从 DQYDJ 网站的数据中分析点有用的东西出来,在过去,我们要<a href="https://dqydj.com/how-to-import-fixed-width-data-into-a-spreadsheet-via-r-playing-with-ipums-cps-data/">用 R 语言提取固定宽度的...

<blockquote> <p>Spark SQL 是 Spark 生态系统中处理结构化格式数据的模块。它在内部使用 Spark Core API 进行处理,但对用户的使用进行了抽象。这篇文章深入浅出地告诉你 Spark SQL 3.x 的新内容。</p> </blockquote> <p>有了 Spark SQL,用...
<p>在 DataEase 中使用 Elasticsearch 类型的数据源时,有的用户不希望给查询 Elasticsearch 数据的账号开放过高的权限,希望开放最小的权限满足 DataEase 的访问需求即可,如果你有这样的需求,那么你可以参考下面的步骤进行操作,在 ES 中创建一个只读角色,然后创建一个用户并将此用户设置为只读角色。</p> <...