CoreDNS 是 Kubernetes 环境的DNS add-on ^[1]^组件。它是在控制平面节点中运行的组件之一,使其正常运行和响应是 Kubernetes 集群正常运行的关键。学习如何监控 CoreDNS,以及它最重要的指标是什么,对于运维团队来说是必须的。

DNS 是每个体系结构中最敏感和最重要的服务之一。应用程序、微服务、服务、主机......如今,万物互联,并不一定意味着只用于内部服务。它也可以应用于外部服务。DNS 负责解析域名并关联内部或外部服务和 PodIP。维护 Pod 的 DNS 记录是一项关键任务,尤其是涉及到临时 Pod 时,IP 地址可以在没有警告的情况下随时更改。
如果您在 Kubernetes 中运行您的工作负载,并且您不知道如何监控 CoreDNS,请继续阅读本文:如何使用 Prometheus 来抓取 CoreDNS 指标,您应该检查哪些指标,以及它们的含义。
在本文中,我们将涵盖以下主题:
- 什么是 Kubernetes CoreDNS?
- 如何在 Kubernetes 中监控 CoreDNS?
- 监控 Kubernetes CoreDNS:应该检查哪些指标?
- 结论
什么是 Kubernetes CoreDNS?
从 Kubernetes 1.11 开始,在基于 DNS 的服务发现达到一般可用性 (GA) 之后,引入了CoreDNS ^[2]^ 作为 kube-dns 的替代方案,CoreDNS 到目前为止一直是 Kubernetes 集群事实上的 DNS 引擎。顾名思义,CoreDNS 是一种用 Go 编写的 DNS 服务,因其灵活性而被广泛采用。
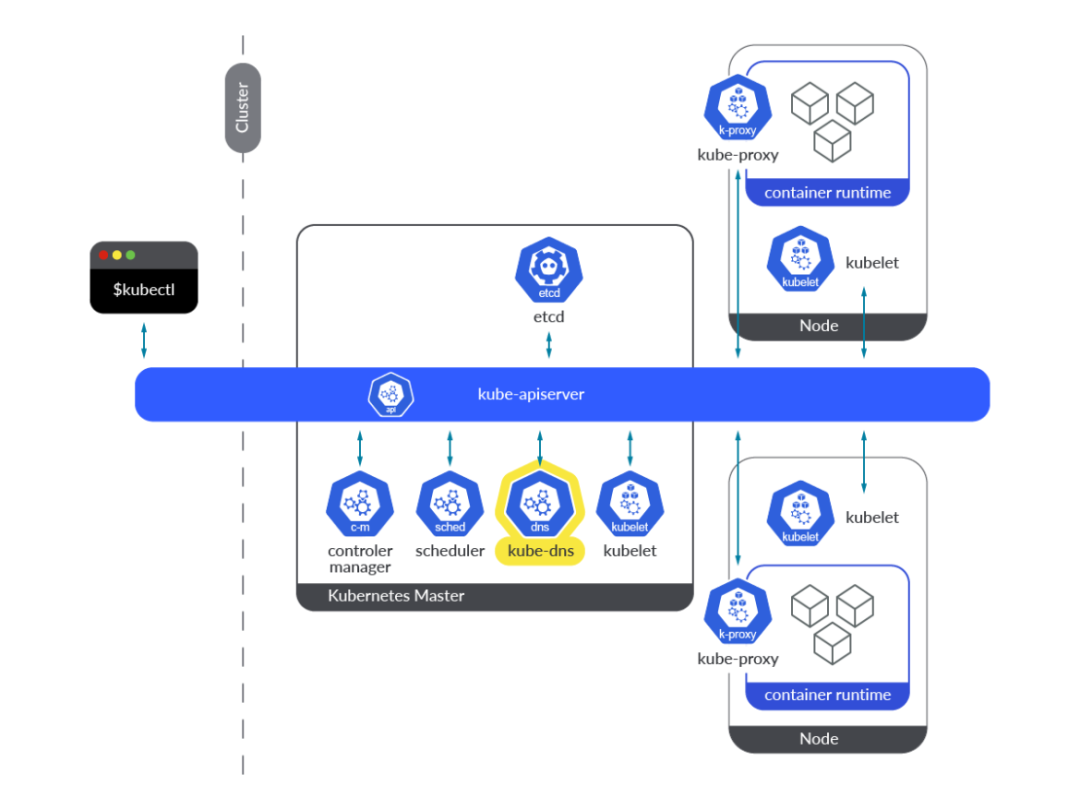
谈到 kube-DNS 附加组件,它是以单个 pod 中三个不同容器的形式提供整个 DNS 功能: kubedns、 dnsmasq 和 sidecar。我们来看看这三个容器:
kubedns:这是 Kubernetes 的 SkyDNS 实现。它负责 Kubernetes 集群内的 DNS 解析。它监视 Kubernetes API 并提供适当的 DNS 记录。dnsmasq: 为 SkyDNS 解析请求提供 DNS 缓存机制。sidecar:此容器导出指标并对 DNS 服务执行健康检查。
现在让我们谈谈 CoreDNS!
CoreDNS 解决了 Kube-dns 当时带来的一些问题。Dnsmasq 引入了一些安全漏洞问题,导致在过去需要 Kubernetes 安全补丁。此外,CoreDNS 在一个容器中而不是 kube-dns 中需要的三个容器中提供所有功能,解决了 kube-dns 中外部服务的存根域的一些其他问题。
CoreDNS 在 9153 端口上公开其指标端点,并且可以从 SDN 网络中的 Pod 或主机节点网络访问它。
# kubectl get ep kube-dns -n kube-system -o json |jq -r ".subsets"
[
{
"addresses": [
{
"ip": "192.169.107.100",
"nodeName": "k8s-control-2.lab.example.com",
"targetRef": {
"kind": "Pod",
"name": "coredns-565d847f94-rz4b6",
"namespace": "kube-system",
"uid": "c1b62754-4740-49ca-b506-3f40fb681778"
}
},
{
"ip": "192.169.203.46",
"nodeName": "k8s-control-3.lab.example.com",
"targetRef": {
"kind": "Pod",
"name": "coredns-565d847f94-8xqxg",
"namespace": "kube-system",
"uid": "bec3ca63-f09a-4007-82e9-0e147e8587de"
}
}
],
"ports": [
{
"name": "dns-tcp",
"port": 53,
"protocol": "TCP"
},
{
"name": "dns",
"port": 53,
"protocol": "UDP"
},
{
"name": "metrics",
"port": 9153,
"protocol": "TCP"
}
]
}
]
您已经知道 CoreDNS 是什么以及已经解决的问题。是时候深入了解如何获取 CoreDNS 指标,以及如何配置 Prometheus 实例以开始抓取其指标。让我们开始吧!
如何在 Kubernetes 中监控 CoreDNS?
正如您刚刚看到的那样,CoreDNS 已经被检测并在每个 CoreDNS Pod 的端口 9153 上公开了 /metrics 端点。访问这个 /metrics 端点很简单,只需运行 curl 并立即开始提取 CoreDNS 指标!
手动访问端点
知道运行 CoreDNS 的端点或 IP 后,请尝试访问 9153 端口。
# curl http://192.169.203.46:9153/metrics
# HELP coredns_build_info A metric with a constant '1' value labeled by version, revision, and goversion from which CoreDNS was built.
# TYPE coredns_build_info gauge
coredns_build_info{goversion="go1.18.2",revision="45b0a11",version="1.9.3"} 1
# HELP coredns_cache_entries The number of elements in the cache.
# TYPE coredns_cache_entries gauge
coredns_cache_entries{server="dns://:53",type="denial",zones="."} 46
coredns_cache_entries{server="dns://:53",type="success",zones="."} 9
# HELP coredns_cache_hits_total The count of cache hits.
# TYPE coredns_cache_hits_total counter
coredns_cache_hits_total{server="dns://:53",type="denial",zones="."} 6471
coredns_cache_hits_total{server="dns://:53",type="success",zones="."} 6596
# HELP coredns_cache_misses_total The count of cache misses. Deprecated, derive misses from cache hits/requests counters.
# TYPE coredns_cache_misses_total counter
coredns_cache_misses_total{server="dns://:53",zones="."} 1951
# HELP coredns_cache_requests_total The count of cache requests.
# TYPE coredns_cache_requests_total counter
coredns_cache_requests_total{server="dns://:53",zones="."} 15018
# HELP coredns_dns_request_duration_seconds Histogram of the time (in seconds) each request took per zone.
# TYPE coredns_dns_request_duration_seconds histogram
coredns_dns_request_duration_seconds_bucket{server="dns://:53",zone=".",le="0.00025"} 14098
coredns_dns_request_duration_seconds_bucket{server="dns://:53",zone=".",le="0.0005"} 14836
coredns_dns_request_duration_seconds_bucket{server="dns://:53",zone=".",le="0.001"} 14850
coredns_dns_request_duration_seconds_bucket{server="dns://:53",zone=".",le="0.002"} 14856
coredns_dns_request_duration_seconds_bucket{server="dns://:53",zone=".",le="0.004"} 14857
coredns_dns_request_duration_seconds_bucket{server="dns://:53",zone=".",le="0.008"} 14870
coredns_dns_request_duration_seconds_bucket{server="dns://:53",zone=".",le="0.016"} 14879
coredns_dns_request_duration_seconds_bucket{server="dns://:53",zone=".",le="0.032"} 14883
coredns_dns_request_duration_seconds_bucket{server="dns://:53",zone=".",le="0.064"} 14884
coredns_dns_request_duration_seconds_bucket{server="dns://:53",zone=".",le="0.128"} 14884
coredns_dns_request_duration_seconds_bucket{server="dns://:53",zone=".",le="0.256"} 14885
coredns_dns_request_duration_seconds_bucket{server="dns://:53",zone=".",le="0.512"} 14886
coredns_dns_request_duration_seconds_bucket{server="dns://:53",zone=".",le="1.024"} 14887
coredns_dns_request_duration_seconds_bucket{server="dns://:53",zone=".",le="2.048"} 14903
coredns_dns_request_duration_seconds_bucket{server="dns://:53",zone=".",le="4.096"} 14911
coredns_dns_request_duration_seconds_bucket{server="dns://:53",zone=".",le="8.192"} 15018
coredns_dns_request_duration_seconds_bucket{server="dns://:53",zone=".",le="+Inf"} 15018
coredns_dns_request_duration_seconds_sum{server="dns://:53",zone="."} 698.531992215999
coredns_dns_request_duration_seconds_count{server="dns://:53",zone="."} 15018
...
(output truncated)
您还可以/metrics通过 Kubernetes 集群中默认公开的 CoreDNS Kubernetes 服务访问端点。
# kubectl get svc -n kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kube-dns ClusterIP 10.96.0.10 53/UDP,53/TCP,9153/TCP 129d
kubectl exec -it my-pod -n default -- /bin/bash
===============================================
`curl http://kube-dns.kube-system.svc:9153/metrics`
如何配置 Prometheus 以抓取 CoreDNS 指标
Prometheus 提供了一组角色来开始发现目标并从多个来源(如 Pods、 Kubernetes 节点和 Kubernetes 服务等)获取指标。当需要从嵌入在 Kubernetes 集群中的 CoreDNS 服务中获取指标时,您只需要使用适当的配置来配置 prometheus.yml 文件。这一次,您应该使用 endpoints role ^[3]^ 来发现这个目标。
编辑包含prometheus.yml配置文件的ConfigMap。
# kubectl edit cm prometheus-server -n monitoring -o yaml
然后,在scrape_configs部分下添加下面的配置片段。
- honor_labels: true
job_name: kubernetes-service-endpoints
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- action: keep
regex: true
source_labels:
- __meta_kubernetes_service_annotation_prometheus_io_scrape
- action: drop
regex: true
source_labels:
- __meta_kubernetes_service_annotation_prometheus_io_scrape_slow
- action: replace
regex: (https?)
source_labels:
- __meta_kubernetes_service_annotation_prometheus_io_scheme
target_label: __scheme__
- action: replace
regex: (.+)
source_labels:
- __meta_kubernetes_service_annotation_prometheus_io_path
target_label: __metrics_path__
- action: replace
regex: (.+?)(?::\d+)?;(\d+)
replacement: $1:$2
source_labels:
- __address__
- __meta_kubernetes_service_annotation_prometheus_io_port
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_service_annotation_prometheus_io_param_(.+)
replacement: __param_$1
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- action: replace
source_labels:
- __meta_kubernetes_namespace
target_label: namespace
- action: replace
source_labels:
- __meta_kubernetes_service_name
target_label: service
- action: replace
source_labels:
- __meta_kubernetes_pod_node_name
target_label: node
此时,在重新部署 Prometheus Pod 后,您应该能够在 Prometheus 控制台中看到可用的 CoreDNS 指标端点(转到 Status -> Targets)。
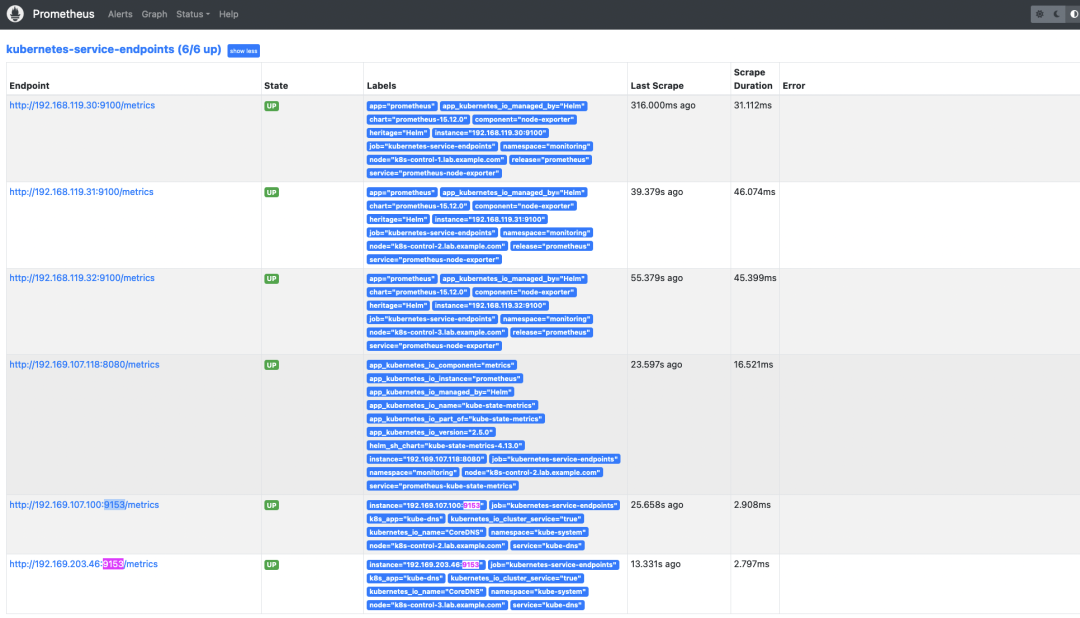
CoreDNS 指标从现在开始可用,并可从 Prometheus 控制台访问。
应该检查哪些指标?
注意 :CoreDNS 指标可能因 Kubernetes 版本和平台而异。在这里,我们使用了 Kubernetes 1.25 和 CoreDNS 1.9.3。您可以在 CoreDNS 存储库 ^[4]^ 中检查适用于您的版本的指标。
首先,让我们谈谈可用性。集群中运行的 CoreDNS 副本数量可能会有所不同,因此最好进行监控,以防出现任何可能影响可用性和性能的变化。
-
CoreDNS 副本数:如果您想监控在 Kubernetes 环境中运行的 CoreDNS 副本数,您可以通过计算
coredns_build_info metric. 此指标提供有关在此类 Pod 上运行的 CoreDNS 构建的信息。count(coredns_build_info)
从现在开始,让我们遵循四个黄金信号方法。在本节中,您将学习如何从该角度监控 CoreDNS,测量错误、延迟、流量和饱和度。
错误 Errors
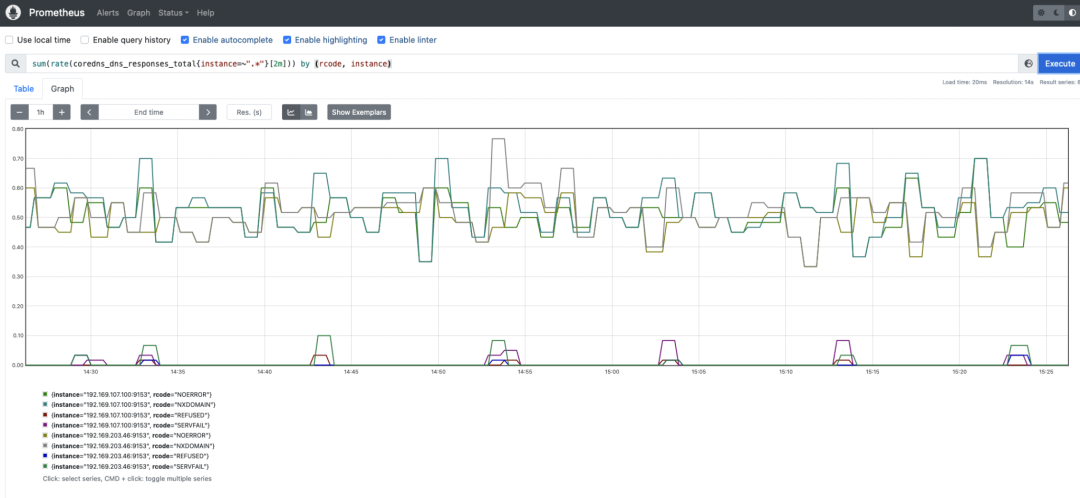
能够测量 CoreDNS 服务中的错误数量是更好地了解 Kubernetes 集群、应用程序和服务健康状况的关键。如果任何应用程序或内部 Kubernetes 组件从 DNS 服务收到意外错误响应,您可能会遇到严重的麻烦。当心 SERVFAIL 和 REFUSED 错误。在解析 Kubernetes 内部组件和应用程序的名称时,这些可能意味着问题。
-
coredns_dns_responses_total:此计数器提供有关 CoreDNS 响应代码、命名空间和 CoreDNS 实例的数量的信息。您可能希望获取每个响应代码的速率。它始终是测量 CoreDNS 实例中的错误率的有用方法。sum(rate(coredns_dns_responses_total{instance=~".*"}[2m])) by (rcode, instance)
延迟 Latency
测量延迟是确保 DNS 服务性能最佳以在 Kubernetes 中正常运行的关键。如果延迟很高或随着时间的推移而增加,则可能表示存在负载问题。如果 CoreDNS 实例过载,您可能会遇到 DNS 名称解析问题,并预计您的应用程序和 Kubernetes 内部服务会出现延迟甚至中断。
-
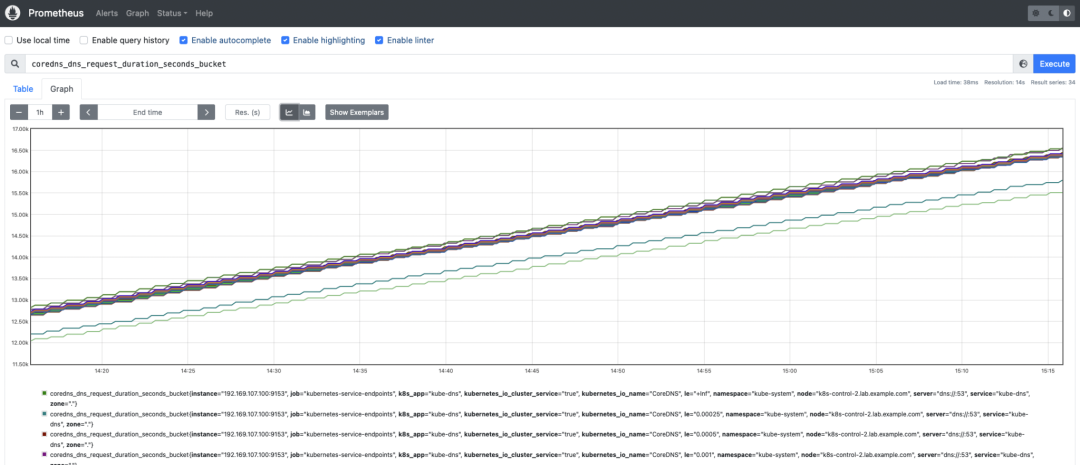
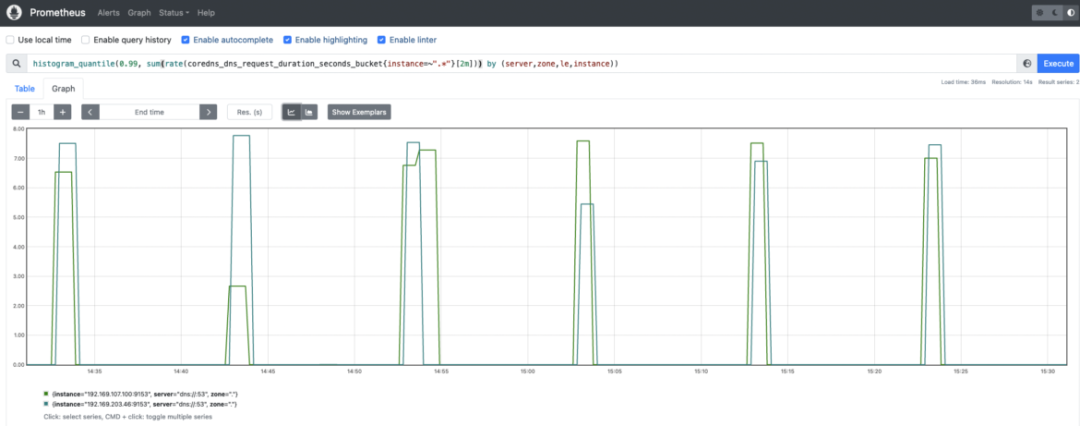
coredns_dns_request_duration_seconds_bucket:CoreDNS 请求持续时间(以秒为单位)。您可能想要计算第 99 个百分位数,以查看延迟在 CoreDNS 实例之间的分布情况。histogram_quantile(0.99, sum(rate(coredns_dns_request_duration_seconds_bucket{instance=~".*"}[2m])) by (server,zone,le,instance))
流量 Traffic
CoreDNS 服务正在处理的流量或请求量。监控 CoreDNS 中的流量非常重要,值得定期检查。观察流量是否有峰值或任何趋势变化是保证良好性能和避免问题的关键。
-
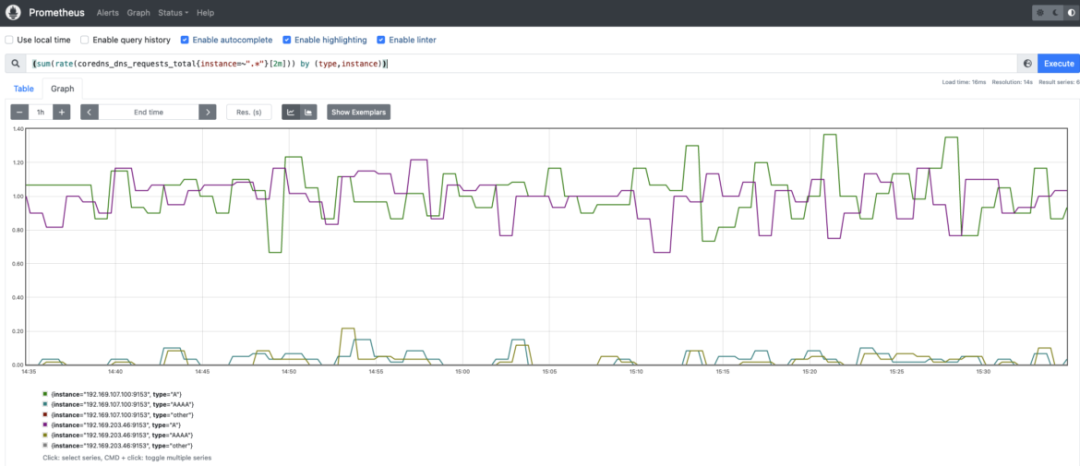
coredns_dns_requests_total:每个区域、协议和系列的 DNS 请求计数器。您可能希望按类型(A、AAAA)测量和监控 CoreDNS 请求的速率。A代表 ipv4 查询,而AAAA是 ipv6 查询。(sum(rate(coredns_dns_requests_total{instance=~".*"}[2m])) by (type,instance))
饱和度 Saturation
您可以使用系统资源消耗指标(例如 CoreDNS Pod 的 CPU、内存和网络使用情况)轻松监控 CoreDNS 饱和度。
其他的
CoreDNS 实现了一种缓存机制 ^[5]^,允许 DNS 服务缓存记录长达 3600 秒。此缓存可以显着降低 CoreDNS 负载并提高性能。
-
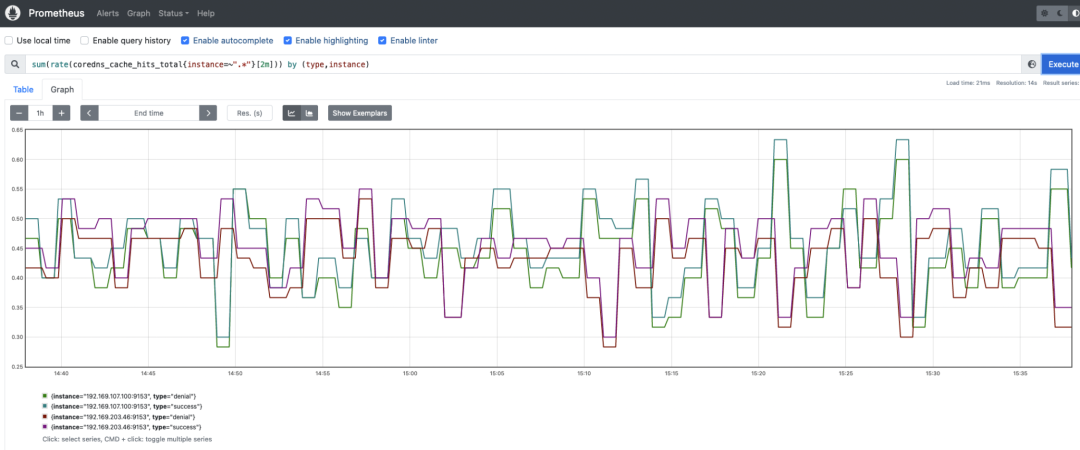
coredns_cache_hits_total:缓存命中计数器。您可能希望通过运行以下查询来监视缓存命中率。多亏了这个 PromQL 查询,您可以轻松监控 CoreDNS 缓存命中的拒绝率和成功率。sum(rate(coredns_cache_hits_total{instance=~".*"}[2m])) by (type,instance)
结论
与 kube-dns 一起,CoreDNS 是可用于在 Kubernetes 环境中实施 DNS 服务的选择之一。DNS 是 Kubernetes 集群正常运行所必需的,而 CoreDNS 一直是大多数人的首选,因为它的灵活性以及与 kube-dns 相比它解决的问题数量。
如果您想确保您的 Kubernetes 基础设施健康且正常工作,您必须持续检查您的 DNS 服务。确保在每个应用程序、操作系统、IT 架构或云环境中正常运行是关键。
在本文中,您了解了如何提取 CoreDNS 指标以及如何配置您自己的 Prometheus 实例以从 CoreDNS 端点抓取指标。得益于 CoreDNS 的关键指标,您可以轻松地在任何 Kubernetes 环境中开始监控您自己的 CoreDNS。