事件背景
大家都知道 k8s 容量不够的时候,都是添加节点来解决问题。这几天有小伙伴在升级 k8s 容量的时候碰到一个问题,他将集群中某一个 node 节点的 CPU 做了升级,然后重启了这个 node 节点导致 kubelet 无法启动,然后大量 pod 被驱逐,报警电话响个不停。为了紧急恢复业务,果断参加故障恢复。
现象获取
在知道事件背景后,我登上了那个已经重启完毕的 node 节点,开始了一系列的网络测试,确认 node 这个宿主机到 Apiserver 和 Loadbalancer 的 ip 和 port 都是通的。随后赶紧看了下 kubelet 的日志,果不其然,一行日志让我看到问题点:
E1121 23:43:52.644552 23453 policy_static.go:158] "Static policy invalid state, please drain node and remove policy state file" err="current set of available CPUs \"0-7\" doesn't match with CPUs in state \"0-3\""
E1121 23:43:52.644569 23453 cpu_manager.go:230] "Policy start error" err="current set of available CPUs \"0-7\" doesn't match with CPUs in state \"0-3\""
E1121 23:43:52.644587 23453 kubelet.go:1431] "Failed to start ContainerManager" err="start cpu manager error: current set of available CPUs \"0-7\" doesn't match with CPUs in state \"0-3\""
说到这里,很多小伙伴会说:"就这??"。
真的就这。是因为啥呢?
是因为 kubelet 启动参数里面有一个参数很重要:--cpu-manager-policy。表示 kubelet 在使用宿主机的 cpu 是什么逻辑策略。如果你设定为 static ,那么就会在参数 --root-dir 指定的目录下生成一个 cpu_manager_state 这样一个绑定文件。
cpu_manager_state 内容大致长得如下:
{ "policyName": "static", "defaultCpuSet": "0-7", "checksum": 14413152 }
当你升级这个 k8s node 节点的 CPU 配置,并且使用了 static cpu 管理模式,那么 kubelet 会读取 cpu_manager_state 文件,然后跟现有的宿主运行的资源做对比,如果不一致,kubelet 就不会启动了。
原理分析
既然我们看到了具体现象和故障位置,不妨借着这个小问题我们一起开温馨下 k8s 的 cpu 管理规范。
官方文档如下:
https://kubernetes.io/zh-cn/docs/tasks/administer-cluster/cpu-management-policies/
当然我还想多少说点别的,关于 CPU Manager 整个架构,让小伙伴们有一个整体理解,能更加深入理解官方的 cpu 管理策略到底是做了些什么动作。
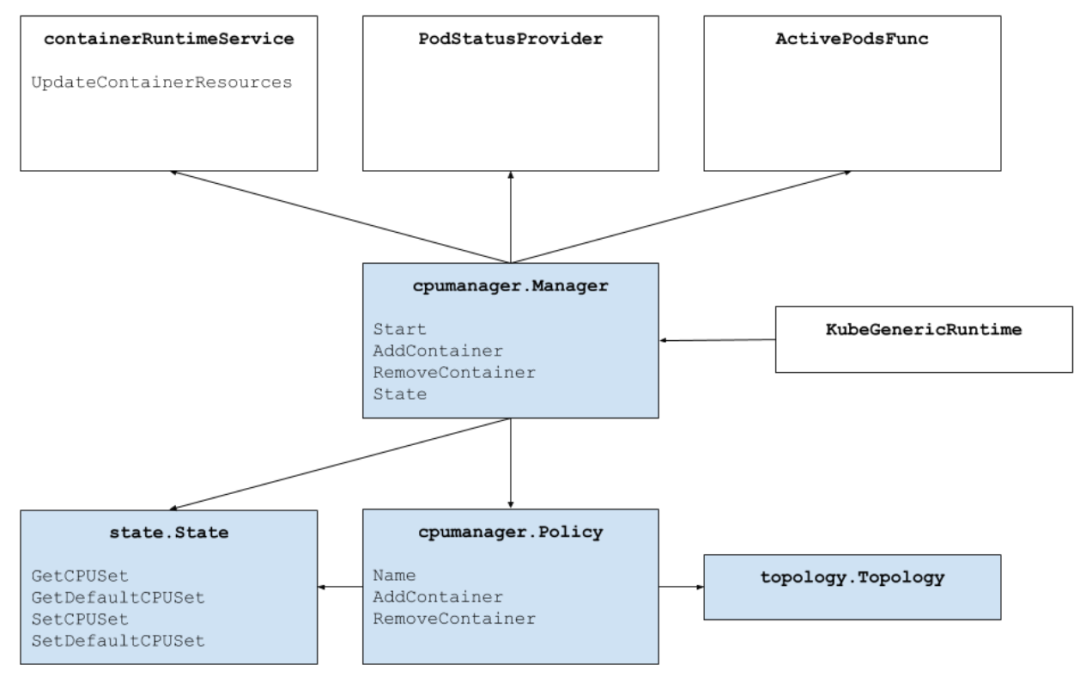
cpu-management-policies
CPU Manager 架构
CPU Manager 为满足条件的 Container 分配指定的 CPUs 时,会尽数按 CPU Topology 来分配,也就是参考 CPU Affinity,按如下的优先顺序进行 CPUs 选择:(Logic CPUs 就是 Hyperthreads)
- 如果 Container 要求的 Logic CPUs 数量不少于单块 CPU Socket 中 Logci CPUs 数量,那么会优先把整块 CPU Socket 中的 Logic CPUs 分配给 Container。
- 如果 Container 减余请求的 Logic CPU 数量不少于单块物理 CPU Core 提供的 Logic CPU 数量,那么会优先把整块物理 CPU Core 上的 Logic CPU 分配给 Container。
Container 托余请求的 Logic CPUs 则从按以下规则排列好的 Logic CPUs 列表中选择:
- 同一插槽上可用的 CPU 数量
- 同一核心上可用的 CPU 数量
参考代码:pkg/kubelet/cm/cpumanager/cpu_assignment.go
func takeByTopology(topo *topology.CPUTopology, availableCPUs cpuset.CPUSet, numCPUs int) (cpuset.CPUSet, error) {
acc := newCPUAccumulator(topo, availableCPUs, numCPUs)
if acc.isSatisfied() {
return acc.result, nil
}
if acc.isFailed() {
return cpuset.NewCPUSet(), fmt.Errorf("not enough cpus available to satisfy request")
}
// Algorithm: topology-aware best-fit
// 1. Acquire whole sockets, if available and the container requires at
// least a socket's-worth of CPUs.
for _, s := range acc.freeSockets() {
if acc.needs(acc.topo.CPUsPerSocket()) {
glog.V(4).Infof("[cpumanager] takeByTopology: claiming socket [%d]", s)
acc.take(acc.details.CPUsInSocket(s))
if acc.isSatisfied() {
return acc.result, nil
}
}
}
// 2. Acquire whole cores, if available and the container requires at least
// a core's-worth of CPUs.
for _, c := range acc.freeCores() {
if acc.needs(acc.topo.CPUsPerCore()) {
glog.V(4).Infof("[cpumanager] takeByTopology: claiming core [%d]", c)
acc.take(acc.details.CPUsInCore(c))
if acc.isSatisfied() {
return acc.result, nil
}
}
}
// 3. Acquire single threads, preferring to fill partially-allocated cores
// on the same sockets as the whole cores we have already taken in this
// allocation.
for _, c := range acc.freeCPUs() {
glog.V(4).Infof("[cpumanager] takeByTopology: claiming CPU [%d]", c)
if acc.needs(1) {
acc.take(cpuset.NewCPUSet(c))
}
if acc.isSatisfied() {
return acc.result, nil
}
}
return cpuset.NewCPUSet(), fmt.Errorf("failed to allocate cpus")
}
发现 CPU Topology
参考代码:vendor/github.com/google/cadvisor/info/v1/machine.go
type MachineInfo struct {
// The number of cores in this machine.
NumCores int `json:"num_cores"`
...
// Machine Topology
// Describes cpu/memory layout and hierarchy.
Topology []Node json:"topology"
...
}
type Node struct {
Id int json:"node_id"
// Per-node memory
Memory uint64 json:"memory"
Cores []Core json:"cores"
Caches []Cache json:"caches"
}
cAdvisor 通过 GetTopology 完成 cpu 拓普信息生成,主要是读取宿主机上 /proc/cpuinfo 中信息来渲染 CPU Topology,通过读取 /sys/devices/system/cpu/cpu 来获得 cpu cache 信息。
参考代码:vendor/github.com/google/cadvisor/info/v1/machine.go
func GetTopology(sysFs sysfs.SysFs, cpuinfo string) ([]info.Node, int, error) {
nodes := []info.Node{}
...
return nodes, numCores, nil
}
创建 pod 过程
对于前面提到的 static policy 情况下 Container 如何创建呢?kubelet 会为其选择约定的 cpu affinity 来为其选择最佳的 CPU Set。
Container 的创建时 CPU Manager 工作流程大致下:
- Kuberuntime 调用容器运行时去创建容器。
- Kuberuntime 将容器传递给 CPU Manager 处理。
- CPU Manager 为 Container 按照静态策略进行处理。
- CPU Manager 从当前 Shared Pool 中选择"最佳"Set 拓结构的 CPU,对于不满 Static Policy 的 Contianer,则返回 Shared Pool 中所有 CPU 组合的 Set。
- CPU Manager 将针对容器的 CPUs 分配情况记录到 Checkpoint State 中,并从 Shared Pool 中删除刚刚分配的 CPUs。
- CPU Manager 再从 state 中读取该 Container 的 CPU 分配信息,然后通过 UpdateContainerResources cRI 接口将其更新到 Cpuset Cgroups 中,包例如对于非 Static Policy Container。
- Kuberuntime 调用容器运行时启动该容器。
参考代码:pkg/kubelet/cm/cpumanager/cpu_manager.go
func (m *manager) AddContainer(pod *v1.Pod, container *v1.Container, containerID string) {
m.Lock()
defer m.Unlock()
if cset, exists := m.state.GetCPUSet(string(pod.UID), container.Name); exists {
m.lastUpdateState.SetCPUSet(string(pod.UID), container.Name, cset)
}
m.containerMap.Add(string(pod.UID), container.Name, containerID)
}
参考代码:pkg/kubelet/cm/cpumanager/policy_static.go
func NewStaticPolicy(topology *topology.CPUTopology, numReservedCPUs int, reservedCPUs cpuset.CPUSet, affinity topologymanager.Store, cpuPolicyOptions map[string]string) (Policy, error) {
opts, err := NewStaticPolicyOptions(cpuPolicyOptions)
if err != nil {
return nil, err
}
klog.InfoS("Static policy created with configuration", "options", opts)
policy := &staticPolicy{
topology: topology,
affinity: affinity,
cpusToReuse: make(map[string]cpuset.CPUSet),
options: opts,
}
allCPUs := topology.CPUDetails.CPUs()
var reserved cpuset.CPUSet
if reservedCPUs.Size() > 0 {
reserved = reservedCPUs
} else {
// takeByTopology allocates CPUs associated with low-numbered cores from
// allCPUs.
//
// For example: Given a system with 8 CPUs available and HT enabled,
// if numReservedCPUs=2, then reserved={0,4}
reserved, _ = policy.takeByTopology(allCPUs, numReservedCPUs)
}
if reserved.Size() != numReservedCPUs {
err := fmt.Errorf("[cpumanager] unable to reserve the required amount of CPUs (size of %s did not equal %d)", reserved, numReservedCPUs)
return nil, err
}
klog.InfoS("Reserved CPUs not available for exclusive assignment", "reservedSize", reserved.Size(), "reserved", reserved)
policy.reserved = reserved
return policy, nil
}
func (p *staticPolicy) Allocate(s state.State, pod *v1.Pod, container *v1.Container) error {
if numCPUs := p.guaranteedCPUs(pod, container); numCPUs != 0 {
klog.InfoS("Static policy: Allocate", "pod", klog.KObj(pod), "containerName", container.Name)
// container belongs in an exclusively allocated pool
if p.options.FullPhysicalCPUsOnly && ((numCPUs % p.topology.CPUsPerCore()) != 0) {
// Since CPU Manager has been enabled requesting strict SMT alignment, it means a guaranteed pod can only be admitted
// if the CPU requested is a multiple of the number of virtual cpus per physical cores.
// In case CPU request is not a multiple of the number of virtual cpus per physical cores the Pod will be put
// in Failed state, with SMTAlignmentError as reason. Since the allocation happens in terms of physical cores
// and the scheduler is responsible for ensuring that the workload goes to a node that has enough CPUs,
// the pod would be placed on a node where there are enough physical cores available to be allocated.
// Just like the behaviour in case of static policy, takeByTopology will try to first allocate CPUs from the same socket
// and only in case the request cannot be sattisfied on a single socket, CPU allocation is done for a workload to occupy all
// CPUs on a physical core. Allocation of individual threads would never have to occur.
return SMTAlignmentError{
RequestedCPUs: numCPUs,
CpusPerCore: p.topology.CPUsPerCore(),
}
}
if cpuset, ok := s.GetCPUSet(string(pod.UID), container.Name); ok {
p.updateCPUsToReuse(pod, container, cpuset)
klog.InfoS("Static policy: container already present in state, skipping", "pod", klog.KObj(pod), "containerName", container.Name)
return nil
}
// Call Topology Manager to get the aligned socket affinity across all hint providers.
hint := p.affinity.GetAffinity(string(pod.UID), container.Name)
klog.InfoS("Topology Affinity", "pod", klog.KObj(pod), "containerName", container.Name, "affinity", hint)
// Allocate CPUs according to the NUMA affinity contained in the hint.
cpuset, err := p.allocateCPUs(s, numCPUs, hint.NUMANodeAffinity, p.cpusToReuse[string(pod.UID)])
if err != nil {
klog.ErrorS(err, "Unable to allocate CPUs", "pod", klog.KObj(pod), "containerName", container.Name, "numCPUs", numCPUs)
return err
}
s.SetCPUSet(string(pod.UID), container.Name, cpuset)
p.updateCPUsToReuse(pod, container, cpuset)
}
// container belongs in the shared pool (nothing to do; use default cpuset)
return nil
}
func (p *staticPolicy) allocateCPUs(s state.State, numCPUs int, numaAffinity bitmask.BitMask, reusableCPUs cpuset.CPUSet) (cpuset.CPUSet, error) {
klog.InfoS("AllocateCPUs", "numCPUs", numCPUs, "socket", numaAffinity)
allocatableCPUs := p.GetAllocatableCPUs(s).Union(reusableCPUs)
// If there are aligned CPUs in numaAffinity, attempt to take those first.
result := cpuset.NewCPUSet()
if numaAffinity != nil {
alignedCPUs := cpuset.NewCPUSet()
for _, numaNodeID := range numaAffinity.GetBits() {
alignedCPUs = alignedCPUs.Union(allocatableCPUs.Intersection(p.topology.CPUDetails.CPUsInNUMANodes(numaNodeID)))
}
numAlignedToAlloc := alignedCPUs.Size()
if numCPUs < numAlignedToAlloc {
numAlignedToAlloc = numCPUs
}
alignedCPUs, err := p.takeByTopology(alignedCPUs, numAlignedToAlloc)
if err != nil {
return cpuset.NewCPUSet(), err
}
result = result.Union(alignedCPUs)
}
// Get any remaining CPUs from what's leftover after attempting to grab aligned ones.
remainingCPUs, err := p.takeByTopology(allocatableCPUs.Difference(result), numCPUs-result.Size())
if err != nil {
return cpuset.NewCPUSet(), err
}
result = result.Union(remainingCPUs)
// Remove allocated CPUs from the shared CPUSet.
s.SetDefaultCPUSet(s.GetDefaultCPUSet().Difference(result))
klog.InfoS("AllocateCPUs", "result", result)
return result, nil
}
删除 pod 过程
当这些通过 CPU Managers 分配 CPUs 的 Container 要删除时,CPU Manager 工作流大致如下:
- Kuberuntime 会调用 CPU Manager 去按静态策略中定义分发处理。
- CPU Manager 将容器分配的 Cpu Set 重新归还到 Shared Pool 中。
- Kuberuntime 调用容器运行时移除该容器。
- CPU Manager 会异步进行协调循环,为使用共享池中的 Cpus 容器更新 CPU 集合。
参考代码:pkg/kubelet/cm/cpumanager/cpu_manager.go
func (m *manager) RemoveContainer(containerID string) error {
m.Lock()
defer m.Unlock()
err := m.policyRemoveContainerByID(containerID)
if err != nil {
klog.ErrorS(err, "RemoveContainer error")
return err
}
return nil
}
参考代码:pkg/kubelet/cm/cpumanager/policy_static.go
func (p *staticPolicy) RemoveContainer(s state.State, podUID string, containerName string) error {
klog.InfoS("Static policy: RemoveContainer", "podUID", podUID, "containerName", containerName)
if toRelease, ok := s.GetCPUSet(podUID, containerName); ok {
s.Delete(podUID, containerName)
// Mutate the shared pool, adding released cpus.
s.SetDefaultCPUSet(s.GetDefaultCPUSet().Union(toRelease))
}
return nil
}
处理方法
知道了异常的原因和以及具体原因,解决办法也非常好弄就两步:
- 删除原有 cpu_manager_state 文件
- 重启 kubelet





