Stable Diffusion 已经发展到可以生成以假乱真图像的程度,无论是 AI 作画还是照片生成都已经可以生成得很精细,本文记录使用过程。
简介 {#简介}
网上最近突然多了很多好看的图,后来发觉八成是 AI 图像的优质化和平民化导致的了,自己是没有那个实力和时间以及设备训练模型了,跟风本地跑一跑玩一玩~
这里先介绍两个网站,对于有能力探寻更深入的人会有所帮助:
Hugging Face 上有很多数据集可以用来做训练,也可以基于其他人共享的数据集进行训练,比自己找数据要方便很多,也有 auto train 功能,可以使用他们付费的服务进行训练。也可以创建 space 来快速给一个训练好的模型生成 API 接口,方便以服务的形式开放给他人使用或者让自己的其他服务调用。有了这些功能深度学习工程师便可以更专注于深度学习本身,而不用特别关注训练数据的来源或者如何部署机器进行训练、回测以及接口化。
CivitAI 主要是模型分享以及社区,用户会在其他人的模型下面回复通过这个模型生成的样本,以及生成时的参数和 seed,方便我们调试其他人模型时可以参考已有的输出进行快速尝试,不然可能会一直觉得自己生成的不够好。
本文记录在 Windows 11 下安装、配置、运行 Stable-diffusion 的流程
过程中经常需要访问境外的网站,需要科学上网。
- 实现过程:
- 安装 UI 环境
- 下载模型
- 运行 UI
- 根据需求生成图像
UI 安装 {#UI-安装}
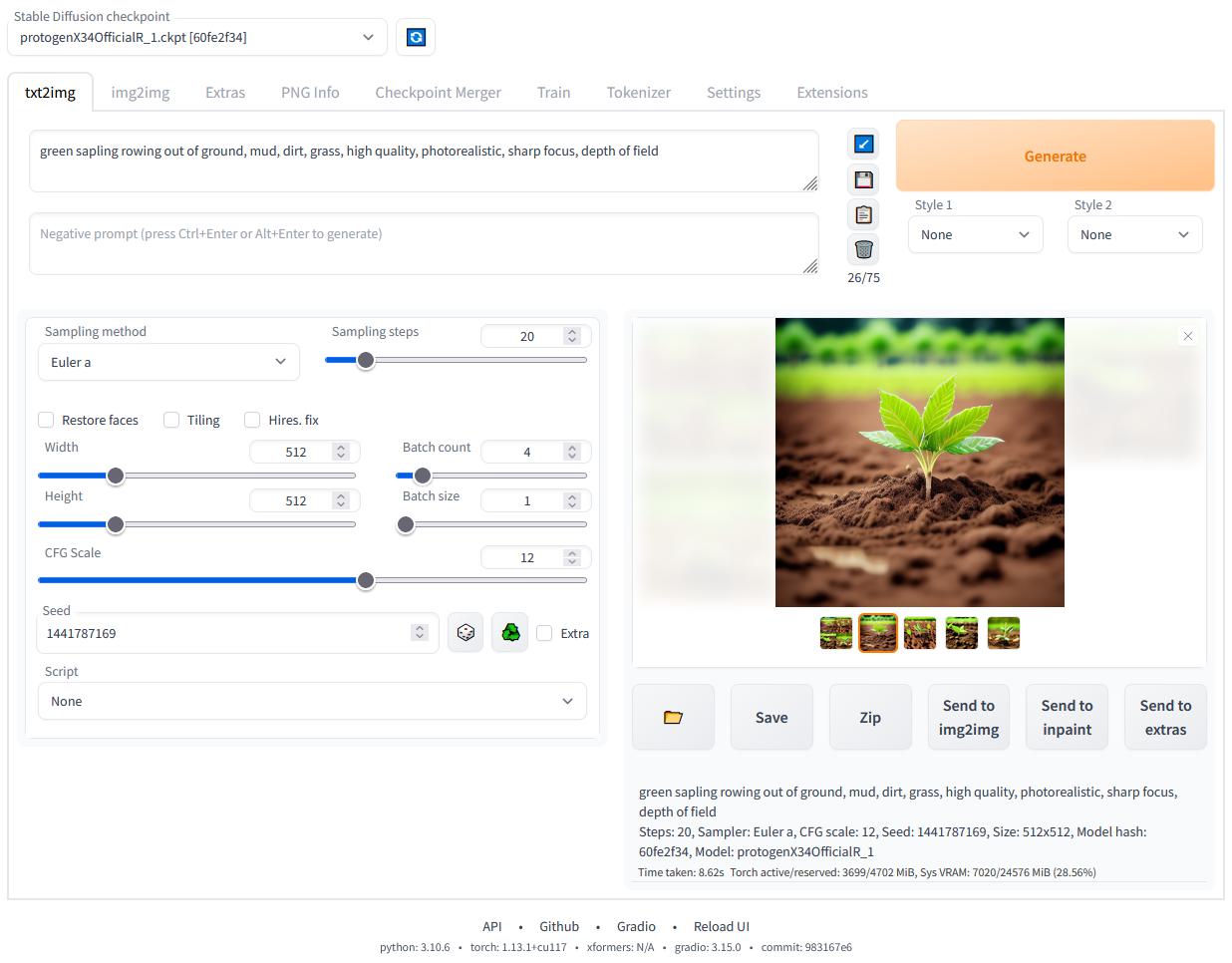
我们安装 stable-diffusion-webui ,进入链接,clone 仓库到本地。
按照 Automatic Installation on Windows 一节的要求配置环境
Automatic Installation on Windows {#Automatic-Installation-on-Windows}
记录我的过程,供参考:
安装 Anaconda {#安装-Anaconda}
下载、安装了 2023.03 版本的 Anaconda
接下来运行
webui-user.bat文件,我在过程中遇到很多问题,没有问题的同志可以跳过这一节
安装 CUDA 11.7 {#安装-CUDA-11-7}
下载链接:https://developer.nvidia.com/cuda-11-7-0-download-archive
torch {#torch}
安装 torch 1.13.1+cu117,torchvision 0.14.1+cu117
webui-user.bat 会自动安装,如果安装太慢可以手动安装
webui-user.bat {#webui-user-bat}
修改这个文件,配置 VENV_DIR 为 Anaconda 路径,例如:
webui.bat {#webui-bat}
将 set PYTHON="%VENV_DIR%\Scripts\Python.exe 修改为:
这样就将 Python 环境配置为刚刚安装的 Anaconda 了
gfpgan {#gfpgan}
安装 gfpgan 时失败: RuntimeError: Couldn't install gfpgan
原因八成是网络的问题,解决方法是直接到 github下载 GFPGAN 代码到本地,并进行本地安装。
如果遇到其他 github 上的模块无法安装也可以用同样的方法。
CLIP {#CLIP}
安装 CLIP 仓库链接
stable-diffusion-stability-ai {#stable-diffusion-stability-ai}
仓库地址: https://github.com/Stability-AI/stablediffusion
注意 :克隆仓库时需要命名为 stable-diffusion-stability-ai
k-diffusion {#k-diffusion}
仓库地址:https://github.com/crowsonkb/k-diffusion
CodeFormer {#CodeFormer}
仓库地址:https://github.com/sczhou/CodeFormer
open_clip {#open-clip}
仓库链接:https://gitcode.net/mirrors/mlfoundations/open_clip?utm_source=csdn_github_accelerator
安装 xformers {#安装-xformers}
需要安装 xformers
ChilloutMix & LoRA {#ChilloutMix-LoRA}
这样 Web-UI 需要的环境配置好了,需要下载模型
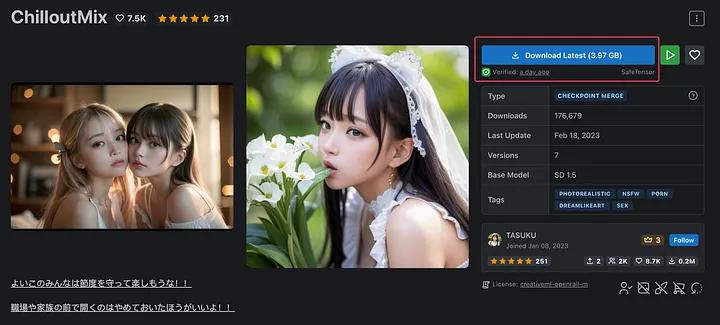
按照大佬的教程,选用 https://civitai.com/models/6424/chilloutmix 模型作为基础模型,模型大小 3.97GB
下载完成后放在 models/Stable-diffusion/ 文件夹下,文件名为 chilloutmix_NiPrunedFp32Fix.safetensors
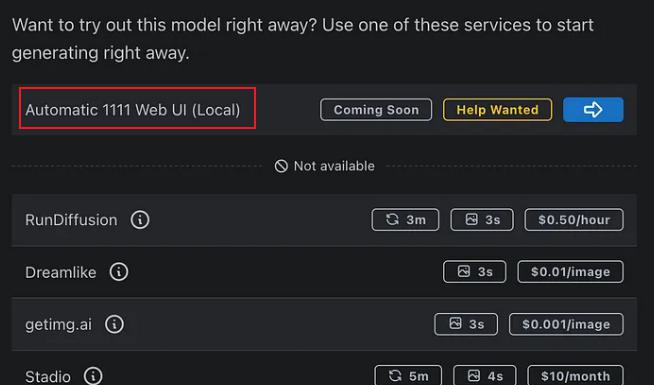
其余的可以在 CivitAI 访问下载,注意需要选择 Automatic 1111 Web UI (Local) 可用的:
可以选择一个自己顺眼的 LORA 训练模型。LoRA(Low-Rank Adaptation of Large Language Models)粗略地讲就是利用少量的图像来对 AI 进行额外学习训练,并在一定程度上控制结果。
流程上也比较简单,就是基于 ChilloutMix 的训练结果和你自己准备的数据集来进行二次训练,目的是最终输出的内容既具有原始 ChilloutMix 的能力,又更倾向你提供的数据的特征。
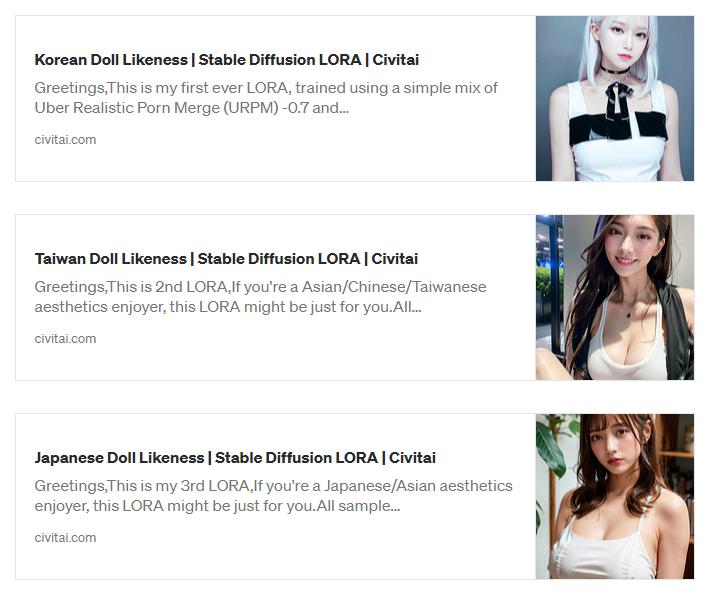
下载的模型也一并放进 models/Stable-diffusion/ 文件夹下
生成图像 {#生成图像}
运行 webui-user.bat 文件,如果出现 Running on local URL: http://127.0.0.1:7860 表示本地服务器启动成功
访问 http://127.0.0.1:7860/,选择模型,输入关键词可以体验生成图像啦 ~
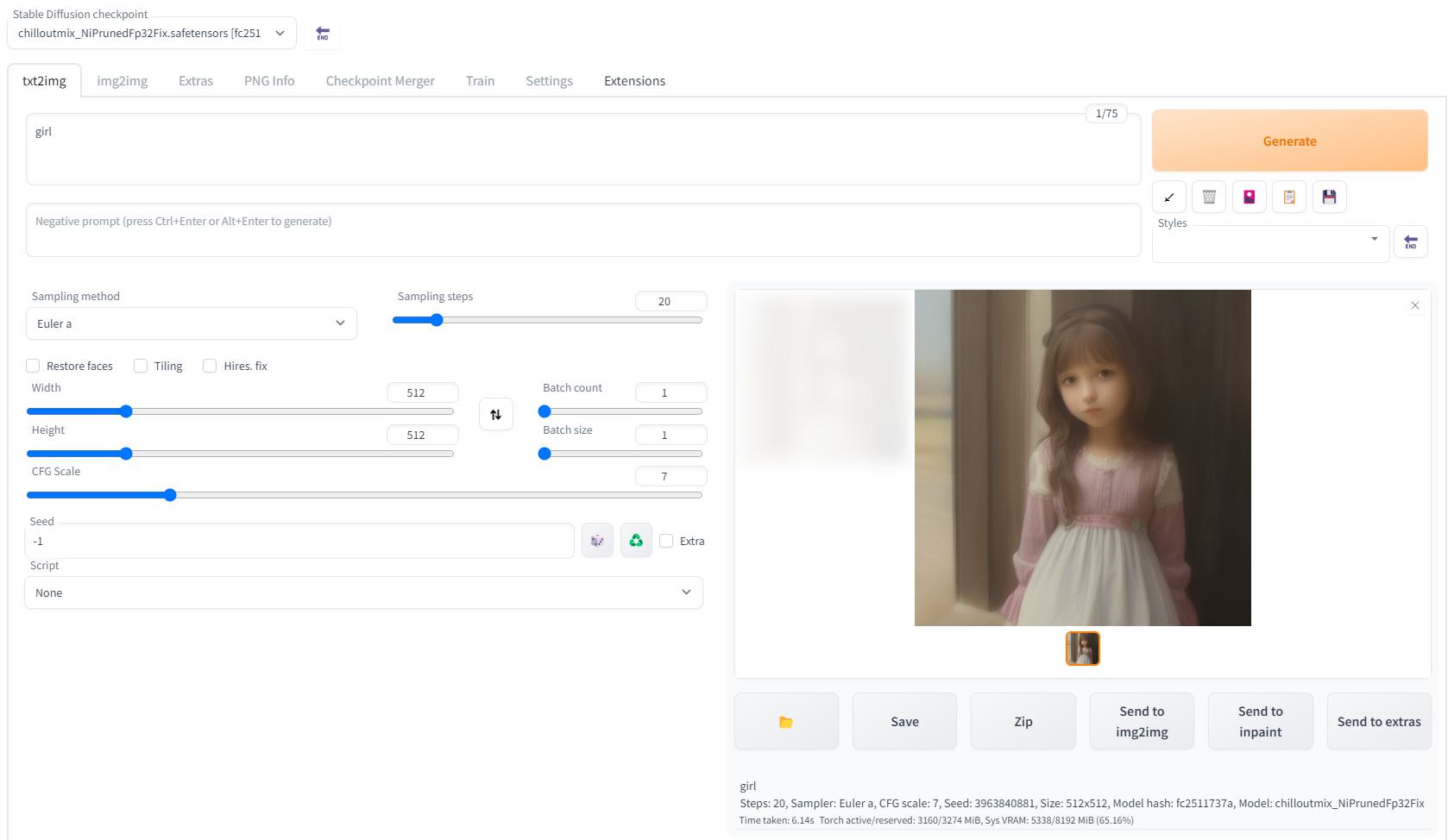
此处 Prompt 代表你想要生成的元素,而 Negative prompt 代表你想要避免出现的元素,选择提示词是一门很神奇的学问,对生成图像的质量至关重要。
咒语 {#咒语}
分享一组提示词做测试:
随机种子 -1 表示随机随机种子,八成生成的是不同的小姐姐,质量差不多就可以了
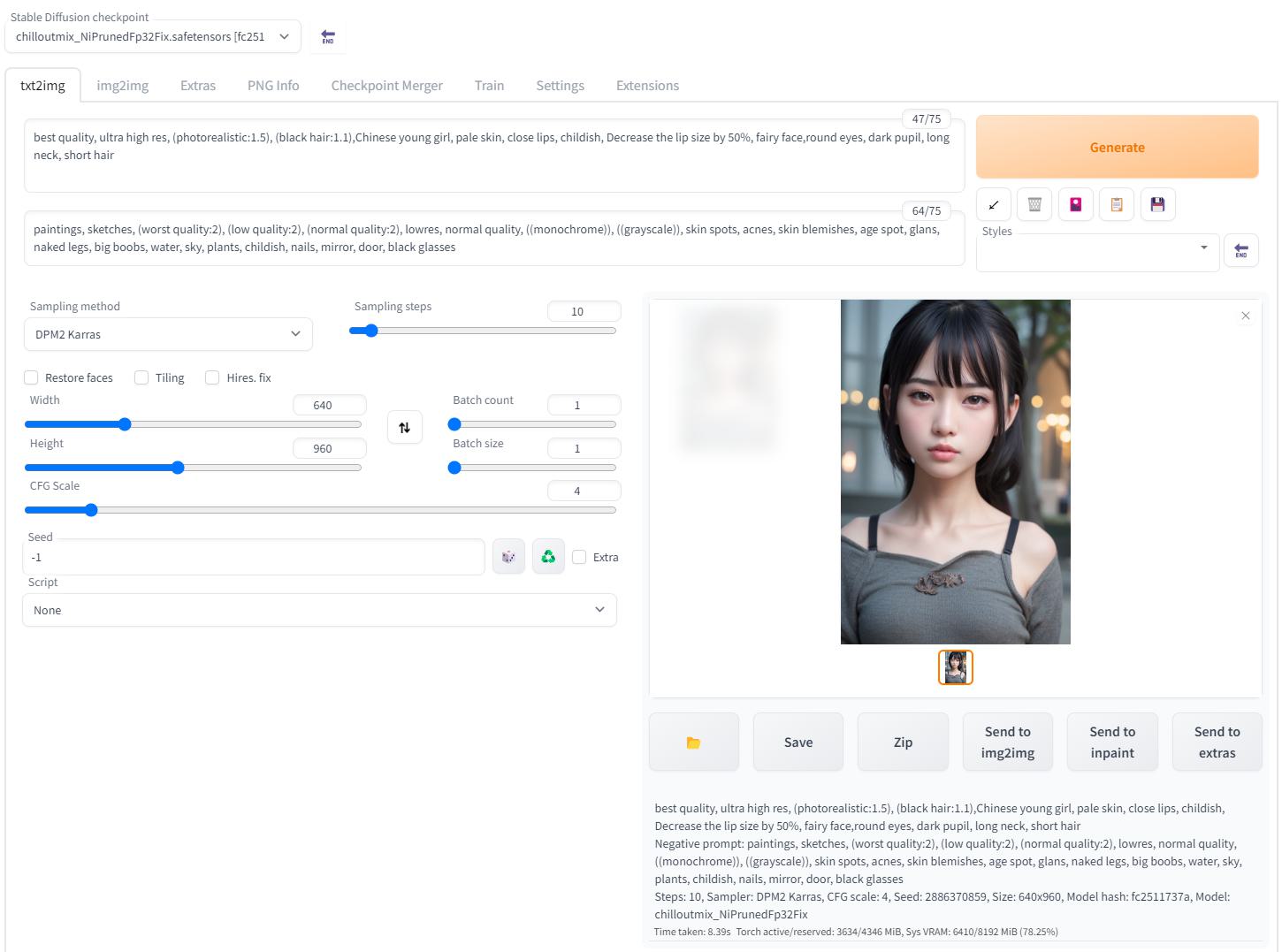
小姐姐:

参考资料 {#参考资料}
- https://medium.com/@croath/低成本体验生成-ai-小姐姐照片-85ffa7c13cd7
- https://zhuanlan.zhihu.com/p/612676189
- stable-diffusion-webui
- https://blog.csdn.net/weixin_40735291/article/details/129153398
- https://github.com/TencentARC/GFPGAN
- https://gitcode.net/mirrors/mlfoundations/open_clip?utm_source=csdn_github_accelerator
- https://github.com/sczhou/CodeFormer
- https://github.com/Stability-AI/stablediffusion
- https://github.com/crowsonkb/k-diffusion
- https://github.com/openai/CLIP
- https://civitai.com/