在Mongodb里面存在另一种集群,就是分片技术,可以满足MongoDB数据量大量增长的需求。本文记录相关内容。
背景 {#背景}
当MongoDB存储海量的数据时,一台机器可能不足以存储数据,也可能不足以提供可接受的读写吞吐量。这时,我们就可以通过在多台机器上分割数据,使得数据库系统能存储和处理更多的数据。
为什么使用分片 {#为什么使用分片}
高数据量和吞吐量的数据库应用会对单机的性能造成较大压力, 大的查询量会将单机的CPU耗尽, 大的数据量对单机的存储压力较大, 最终会耗尽系统的内存而将压力转移到磁盘IO上。
为了解决这些问题, 有两个基本的方法: 垂直扩展和水平扩展。
垂直扩展:增加更多的CPU和存储资源来扩展容量。水平扩展:将数据集分布在多个服务器上。MongoDB的分片就是水平扩展的体现。
分片设计思想
分片为应对高吞吐量与大数据量提供了方法。使用分片减少了每个分片需要处理的请求数,因此,通过水平扩展,集群可以提高自己的存储容量和吞吐量。举例来说,当插入一条数据时,应用只需要访问存储这条数据的分片.
分片目的
- 读/写能力提升
- 存储容量扩容
- 高可用性
- 复制所有的写入操作到主节点
- 延迟的敏感数据会在主节点查询
- 单个副本集限制在12个节点
- 当请求量巨大时会出现内存不足。
- 本地磁盘不足
- 垂直扩展价格昂贵
MongoDB分片 {#MongoDB分片}
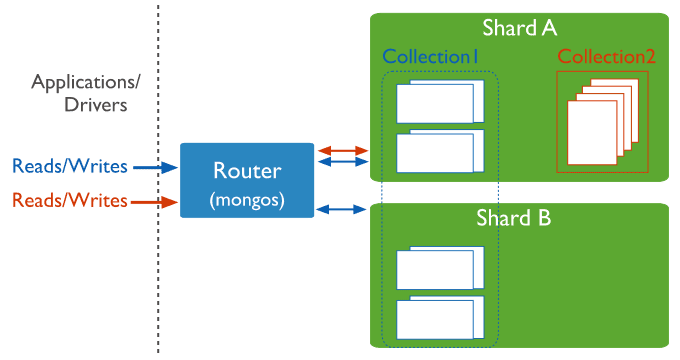
下图展示了在MongoDB中使用分片集群结构分布:
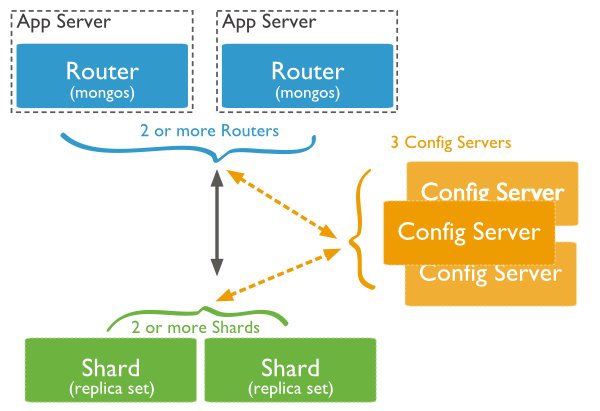
上图中主要有如下所述三个主要组件:
-
Shard:
即分片,真正的数据存储位置,以chunk为单位存数据;每个分片可以部署为一个复制集。实际生产环境中一个shard server角色可由几台机器组个一个replica set承担,防止主机单点故障。
-
Config Server:
mongod实例,存储了整个 ClusterMetadata,其中包括 chunk信息。
-
Query Routers:
前端路由,客户端由此接入,且让整个集群看上去像单一数据库,前端应用可以透明使用。
mongos提供的是客户端application与MongoDB分片集群的路由功能,这里分片集群包含了分片的collection和非分片的collection。如下展示了通过路由访问分片的collection和非分片的collection:
分片数据存储:Chunk {#分片数据存储:Chunk}
Chunk是什么 {#Chunk是什么}
在一个shard server内部,MongoDB还是会把数据分为chunks,每个chunk代表这个shard server内部一部分数据。chunk的产生,会有以下两个用途:
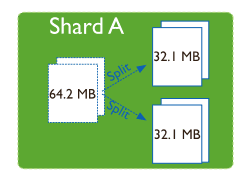
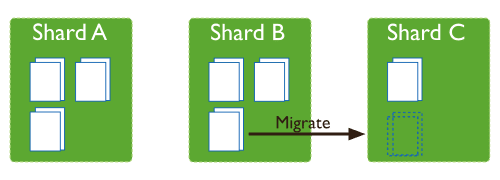
Splitting:当一个chunk的大小超过配置中的chunk size时,MongoDB的后台进程会把这个chunk切分成更小的chunk,从而避免chunk过大的情况Balancing:在MongoDB中,balancer是一个后台进程,负责chunk的迁移,从而均衡各个shard server的负载,系统初始1个chunk,chunk size默认值64M,生产库上选择适合业务的chunk size是最好的。MongoDB会自动拆分和迁移chunks。
分片集群的数据分布(shard节点)
- 使用chunk来存储数据
- 进群搭建完成之后,默认开启一个chunk,大小是64M,
- 存储需求超过64M,chunk会进行分裂,如果单位时间存储需求很大,设置更大的chunk
- chunk会被自动均衡迁移。
chunksize的选择 {#chunksize的选择}
适合业务的chunksize是最好的。
chunk的分裂和迁移非常消耗IO资源;chunk分裂的时机:在插入和更新,读数据不会分裂。
chunksize的选择:
小的chunksize:数据均衡是迁移速度快,数据分布更均匀。数据分裂频繁,路由节点消耗更多资源。大的chunksize:数据分裂少。数据块移动集中消耗IO资源。通常100-200M
chunk分裂及迁移 {#chunk分裂及迁移}
随着数据的增长,其中的数据大小超过了配置的chunk size,默认是64M,则这个chunk就会分裂成两个。数据的增长会让chunk分裂得越来越多。
这时候,各个shard 上的chunk数量就会不平衡。这时候,mongos中的一个组件balancer 就会执行自动平衡。把chunk从chunk数量最多的shard节点挪动到数量最少的节点。
chunkSize 对分裂及迁移的影响
- MongoDB 默认的 chunkSize 为64MB,如无特殊需求,建议保持默认值;chunkSize 会直接影响到 chunk 分裂、迁移的行为。
- chunkSize 越小,chunk 分裂及迁移越多,数据分布越均衡;反之,chunkSize 越大,chunk 分裂及迁移会更少,但可能导致数据分布不均。
- chunkSize 太小,容易出现
jumbo chunk(即shardKey 的某个取值出现频率很高,这些文档只能放到一个 chunk 里,无法再分裂)而无法迁移;chunkSize 越大,则可能出现 chunk 内文档数太多(chunk 内文档数不能超过 250000 )而无法迁移。 - chunk 自动分裂只会在数据写入时触发,所以如果将 chunkSize 改小,系统需要一定的时间来将 chunk 分裂到指定的大小。
- chunk 只会分裂,不会合并,所以即使将 chunkSize 改大,现有的 chunk 数量不会减少,但 chunk 大小会随着写入不断增长,直到达到目标大小。
分片依据和分片算法 {#分片依据和分片算法}
MongoDB 中Collection的数据是根据什么进行分片的呢?这就是我们要介绍的分片键(Shard key) ;那么又是采用过了什么算法进行分片的呢?这就是紧接着要介绍的范围分片(range sharding)**和**哈希分片(Hash Sharding)。
分片键(Shard key) {#分片键(Shard-key)}
分片键就是在集合中选一个字段或者组合字段,用该键的值作为数据拆分的依据。
分片键必须是一个索引,通过sh.shardCollection加会自动创建索引(前提是此集合不存在的情况下)。一个自增的分片键对写入和数据均匀分布就不是很好,因为自增的片键总会在一个分片上写入,后续达到某个阀值可能会写到别的分片。但是按照片键查询会非常高效。
注意:
-
分片键是不可变。
-
分片键必须有索引。
-
分片键大小限制512bytes。
-
分片键用于路由查询。
-
MongoDB不接受已进行collection级分片的collection上插入无分片
-
键的文档(也不支持空值插入)
-
一旦你对一个集合分片,那么其分片键就不可再改变;也就是说,你不可以对这个集合再重新选择另一个不一样的分片键。
分片键格式 {#分片键格式}
为了将一个集合分片,你必须在 sh.shardCollection() 方法中指定目标集合和分片键:
namespace参数由字符串<database>.<collection>组成,该字符串指定目标集合的完整命名空间。 key参数由包含一个字段和该字段的索引遍历方向的文档组成。
注意:
- 如果需要进行分片的目标集合是空集合,可以不创建索引直接进行下一步的分片设置,该操作会自动创建索引。
- 如果需要进行分片的目标集合是非空集合,则需要先创建索引key。
哈希分片(Hash Sharding) {#哈希分片(Hash-Sharding}
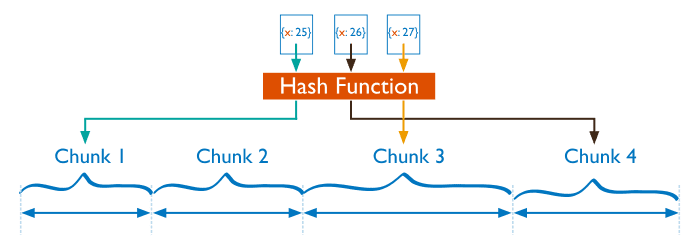
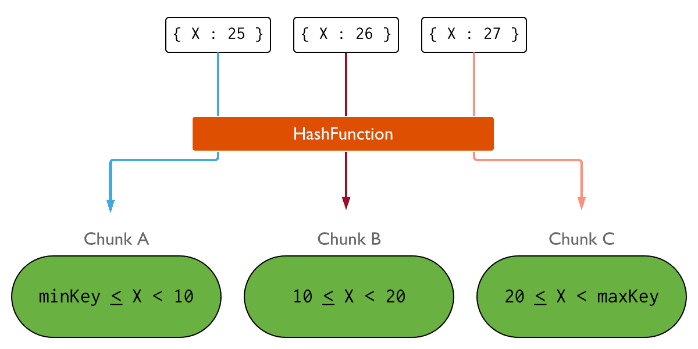
分片过程中利用哈希索引作为分片,基于哈希片键最大的好处就是保证数据在各个节点分布基本均匀。
对于基于哈希的分片,MongoDB计算一个字段的哈希值,并用这个哈希值来创建数据块。在使用基于哈希分片的系统中,拥有相近分片键的文档很可能不会存储在同一个数据块中,因此数据的分离性更好一些。
范围分片(range sharding) {#范围分片(range-sharding)}
将单个Collection的数据分散存储在多个shard上,用户可以指定根据集合内文档的某个字段即shard key来进行范围分片(range sharding)。
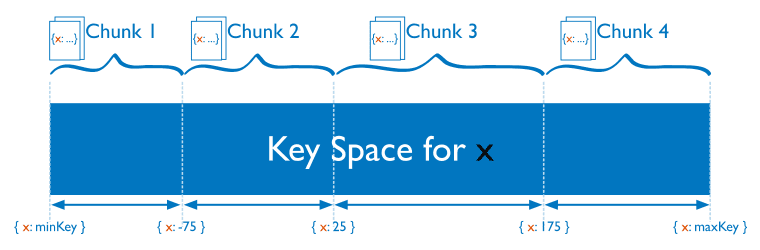
对于基于范围的分片,MongoDB按照片键的范围把数据分成不同部分:
哈希和范围的结合 {#哈希和范围的结合}
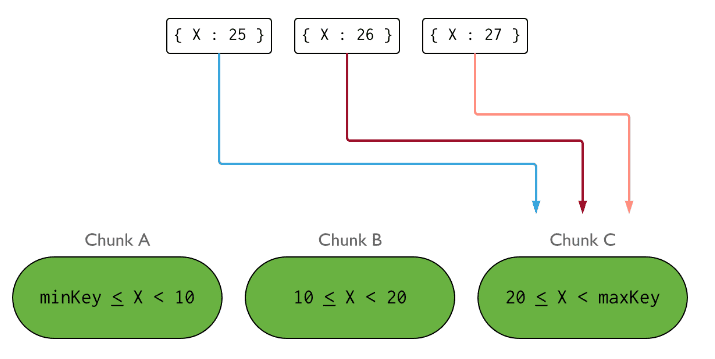
如下是基于X索引字段进行范围分片,但是随着X的增长,大于20的数据全部进入了Chunk C, 这导致了数据的不均衡。
这时对X索引字段建哈希索引:
按区域:Zone {#按区域:Zone}
在分片群集中可以基于分片键划分数据的区域(zone)在新窗口打开, 你可以将每个区域(zone)与集群中的一个或多个分片关联。
应用区域(zone)的一些常见部署模式如下:
- 将指定的数据放在指定的分片上。
- 确保最相关的数据驻留在地理上最靠近应用程序服务器的分片上。
- 根据分片硬件的硬件/性能将数据路由到分片。
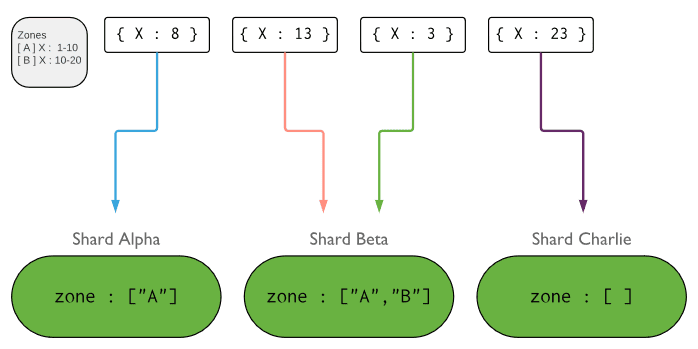
下图说明了具有三个分片和两个区域的分片集群。 A区域代表下边界为1且上限为10的范围。B区域代表下边界为10且上限为20的范围。分片Alpha和Beta具有A区域。 分片Beta也具有B区。分片Charlie没有与之关联的区域。 群集处于稳定状态。
分片实例 {#分片实例}
分片结构端口分布如下:
步骤一:启动Shard Server
步骤二: 启动Config Server
**注意:**这里我们完全可以像启动普通mongodb服务一样启动,不需要添加---shardsvr和configsvr参数。因为这两个参数的作用就是改变启动端口的,所以我们自行指定了端口就可以。
步骤三: 启动Route Process
mongos启动参数中,chunkSize这一项是用来指定chunk的大小的,单位是MB,默认大小为200MB.
步骤四: 配置Sharding
接下来,我们使用MongoDB Shell登录到mongos,添加Shard节点
步骤五: 程序代码内无需太大更改,直接按照连接普通的mongo数据库那样,将数据库连接接入接口40000
参考资料 {#参考资料}
- https://www.runoob.com/mongodb/mongodb-sharding.html
- https://pdai.tech/md/db/nosql-mongo/mongo-z-sharding.html
文章链接:
https://www.zywvvd.com/notes/coding/dataset/mongodb-slice/mongodb-slice/