本文讨论 Python 中的不同序列类型。 Python 标准库用 C 实现了丰富的序列类型,可以按照包含对象类型和是否可修改进行分类。
包含对象类型 {#包含对象类型}
将 python 内置序列类型按照包含对象类型来分类,可以将其分为容器序列 和扁平序列。
- 容器序列存放的是它们所包含的任意类型的对象的引用,而扁平序列里存放的是值而不是引用。
- 扁平序列其实是一段连续的内存空间。由此可见扁平序列其实更加紧凑,但是它里面只能存放诸如字符、字节和数值这种基础类型。
容器序列 {#容器序列}
容器序列能存放不同类型的数据。
- 包括
list, tuple, collections.deque
list {#list}
内置类型,列表
| 序号 | 方法 | 含义 | |----|----------------------------------------------|-----------------------------------| | 1 | list.append(obj) | 在列表末尾添加新的对象 | | 2 | list. count (obj) | 统计某个元素在列表中出现的次数 | | 3 | list.extend(seq) | 在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表) | | 4 | list.index(obj) | 从列表中找出某个值第一个匹配项的索引位置 | | 5 | list.insert(index, obj) | 将对象插入列表 | | 6 | list.pop([index=-1]) | 移除列表中的一个元素(默认最后一个元素),并且返回该元素的值 | | 7 | list.remove(obj) | 移除列表中某个值的第一个匹配项 | | 8 | list.reverse() | 反向列表中元素 | | 9 | list.sort(cmp=None, key=None, reverse=False) | 对原列表进行排序 |
tuple {#tuple}
元组,表示不可修改的列表
- 元组中只包含一个元素时,需要在元素后面添加逗号来消除歧义
- 访问方法和列表相同,不可以修改,但可以组合元组
- 内置函数
| 函数 | 含义 | |------------|------------| | len(tuple) | 计算元组元素个数 | | max(tuple) | 返回元组中元素最大值 | | min(tuple) | 返回元组中元素最小值 | | tuple(seq) | 将列表转换为元组 |
collections.deque {#collections-deque}
collections 中的 deque 是双端队列,和 list 的用法整体上基本差不多,不过deque有一些特殊的用法是list没有的:
| 序号 | 方法 | 含义 | |----|----------------------|---------------------| | 1 | appendleft(x) | 头部添加元素 | | 2 | extendleft(iterable) | 头部添加多个元素 | | 3 | popleft() | 头部返回并删除 | | 4 | rotate(n=1) | 旋转 | | 5 | maxlen | 最大空间,如果是无边界的,返回None |
deque 性能优于 list。
扁平序列 {#扁平序列}
扁平序列只能容纳一种类型。
- 包含
str、bytes、bytearray、memoryview和array.array
str {#str}
- 字符串中字符大小写的变换
| 方法 | 含义 | |----------------|-------------------------| | S.lower() | 小写 | | S.upper() | 大写 | | S.swapcase() | 大小写互换 | | S.capitalize() | 首字母大写 | | S.title() | 只有首字母大写,其余为小写,模块中没有这个方法 |
- 字符串在输出时的对齐
| 方法 | 含义 | |-------------------------------|-----------------------------------------| | S.ljust(width,[fillchar]) | 输出width个字符,S左对齐,不足部分用fillchar填充,默认的为空格。 | | S.rjust(width,[fillchar]) | 右对齐 | | S.center(width, [fillchar]) | 中间对齐 | | S.zfill(width) | 把S变成width长,并在右对齐,不足部分用0补足 |
- 字符串中的搜索和替换
| 方法 | 含义 | |--------------------------------------|---------------------------------------------------------------------------| | S.find(substr, [start, [end]]) | 返回S中出现substr的第一个字母的标号,如果S中没有substr则返回-1。start和end作用就相当于在S[start:end]中搜索 | | S.index(substr, [start, [end]]) | 与find()相同,只是在S中没有substr时,会返回一个运行时错误 | | S.rfind(substr, [start, [end]]) | 返回S中最后出现的substr的第一个字母的标号,如果S中没有substr则返回-1,也就是说从右边算起的第一次出现的substr的首字母标号 | | S.rindex(substr, [start, [end]]) | 从右边起进行 index 操作 | | S.count(substr, [start, [end]]) | 计算substr在S中出现的次数 | | S.replace(oldstr, newstr, [count]) | 把S中的oldstar替换为newstr,count为替换次数。这是替换的通用形式,还有一些函数进行特殊字符的替换 | | S.strip([chars]) | 把S中前后chars中有的字符全部去掉,可以理解为把S前后chars替换为None | | S.lstrip([chars]) | 把S中最前和chars重复的字符全部去掉 | | S.rstrip([chars]) | 把S中最后和chars重复的字符全部去掉 | | S.expandtabs([tabsize]) | 把S中的tab字符替换为空格,每个tab替换为tabsize个空格,默认是8个 |
- 字符串的分割和组合
| 方法 | 含义 | |---------------------------------|----------------------------------------------------| | S.split([sep, [maxsplit]]) | 以sep为分隔符,把S分成一个list。maxsplit表示分割的次数。默认的分割符为空白字符 | | S.rsplit([sep, [maxsplit]]) | 从右边进行的分割操作 | | S.splitlines([keepends]) | 把S按照行分割符分为一个list,keepends是一个bool值,如果为真每行后而会保留行分割符。 | | S.join(seq) | 把seq代表的序列──字符串序列,用S连接起来 |
- 字符串的mapping
| 方法 | 含义 | |------------------------------------|-------------------------------------------------------------------------------------------------------------------------------------------------| | String.maketrans(from, to) | 返回一个256个字符组成的翻译表,其中from中的字符被一一对应地转换成to,所以from和to必须是等长的。 | | S.translate(table[,deletechars]) | 使用上面的函数产后的翻译表,把S进行翻译,并把deletechars中有的字符删掉。需要注意的是,如果S为unicode字符串,那么就不支持deletechars参数,可以使用把某个字符翻译为None的方式实现相同的功能。此外还可以使用codecs模块的功能来创建更加功能强大的翻译表。 |
- 编码和解码
| 方法 | 含义 | |-----------------------------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------| | S.encode([encoding,[errors]]) | 其中encoding可以有多种值,比如gb2312 gbk gb18030 bz2 zlib big5 bzse64等都支持。errors默认值为"strict",意思是UnicodeError。可能的值还有'ignore', 'replace', 'xmlcharrefreplace', 'backslashreplace' 和所有的通过codecs.register_error注册的值。 | | S.decode([encoding,[errors]]) | 按照指定方式进行解码。 |
- 字符串的测试函数
| 方法 | 含义 | |---------------------------------------|--------------------| | S.startwith(prefix[,start[,end]]) | 是否以prefix开头 | | S.endwith(suffix[,start[,end]]) | 以suffix结尾 | | S.isalnum() | 是否全是字母和数字,并至少有一个字符 | | S.isalpha() | 是否全是字母,并至少有一个字符 | | S.isdigit() | 是否全是数字,并至少有一个字符 | | S.isspace() | 是否全是空白字符,并至少有一个字符 | | S.islower() | S中的字母是否全是小写 | | S.isupper() | S中的字母是否便是大写 | | S.istitle() | S是否是首字母大写的 |
- 字符串类型转换函数,这几个函数只在string模块中有
| 方法 | 含义 | |-------------------------|----------------------------------------------------------------------| | string.atoi(s[,base]) | base默认为10,如果为0,那么s就可以是012或0x23这种形式的字符串,如果是16那么s就只能是0x23或0X12这种形式的字符串 | | string.atol(s[,base]) | 转成long | | string.atof(s[,base]) | 转成float |
注意: 字符串对象是不可改变的,也就是说在python创建一个字符串后,你不能把这个字符中的某一部分改变。任何上面的函数改变了字符串后,都会返回一个新的字符串,原字串并没有变。
bytes {#bytes}
bytes 类型,由多个字节组成,以字节为单位进行操作,网上有人称之为"字节串"。
- 字节串(bytes)和字符串(string)的对比:
- 字符串由若干个字符组成,以字符为单位进行操作;字节串由若干个字节组成,以字节为单位进行操作。
- 字节串和字符串除了操作的数据单元不同之外,它们支持的所有方法都基本相同。
- 字节串和字符串都是不可变序列,不能随意增加和删除数据。
- bytes 只负责以字节序列的形式(二进制形式)来存储数据,至于这些数据到底表示什么内容(字符串、数字、图片、音频等),完全由程序的解析方式决定。如果采用合适的字符编码方式(字符集),字节串可以恢复成字符串;反之亦然,字符串也可以转换成字节串。
| 用法 | 含义 | |-------------------------------------------|---------------------------------------| | b1 = bytes() | 创建一个空的bytes | | b2 = b'hello' | 通过b前缀指定hello是bytes类型的值 | | b3 = bytes('我爱Python编程',encoding='utf-8') | 调用bytes方法将字符串转成bytes对象 | | b4 = "学习Python很有趣".encode('utf-8') | 利用字符串的encode()方法编码成bytes,默认使用utf-8字符集 | | st = b4.decode('utf-8') | 将bytes 对象解码成字符串,默认使用UTF-8进行解码 |
-
同时 bytes 兼容 str 的大部分方法 ,只不过 bytes方法,输入的是bytes输出的也是bytes
例如:
b'abcdef'.replace(b'f',b'k')
bytearray {#bytearray}
- 表示可变的字节数组
- 定义对象:
| 用法 | 含义 | |----------------------------------------------------|-----------------------------------------------------| | bytearray() | 定义一个空的bytearray | | bytearray(int) | 定义一个指定长度的bytearray的字节数组,默认被\x00填充 | | bytearray(iterable_of_ints) | 根据[0,255]的int组成的可迭代对象创建bytearray | | bytearray(string,encoding[,errors])-->bytearray | 根据string类型创建bytearray,和string.encode()类似,不过返回的是可变对象 | | bytearray(bytes_or_buffe) | 从一个字节序列或者buffer复制出一个新的可变bytearray对象 |
- 操作:
| 函数 | 含义 | |--------------------------|---------------------------| | append(int) | 尾部追加一个元素 | | insert(index,int) | 在指定索引位置插入元素 | | extend(iterable_of_ints) | 将一个可迭代的整数结婚追加到当前bytearray | | pop(index = -1) | 从指定索引上移除元素,默认从尾部移除 | | remove(value) | 找到第一个value移除,找不到抛异常 | | clear() | 清空bytearray | | reverse() | 翻转bytearray,就地修改 |
Memoryview {#Memoryview}
bytes, bytearray 和 memoryview 表示的是在连续内存中保存的字节序列。
memoryview 的意义 {#memoryview-的意义}
-
bytes 和 bytearray 本质上依然是序列,与 list 或者 string 类似,也支持切片操作。
-
Python 中的切片会创建一个完整的副本,比如 list[:5] 会创建一个新的 list 对象,包含了前 5 项数值。如果我们现在从一个文件中读取了一些数据,经过处理认为只需要将这些数据的前 10 字节保存起来,经典的做法是将 data[:10] 切片写入文件。
-
然而切片的副本是完全可以避免的,这就可以借助 memoryview 获得更高效的实现:
- 下面是用切片和视图切片在内存中的差异:
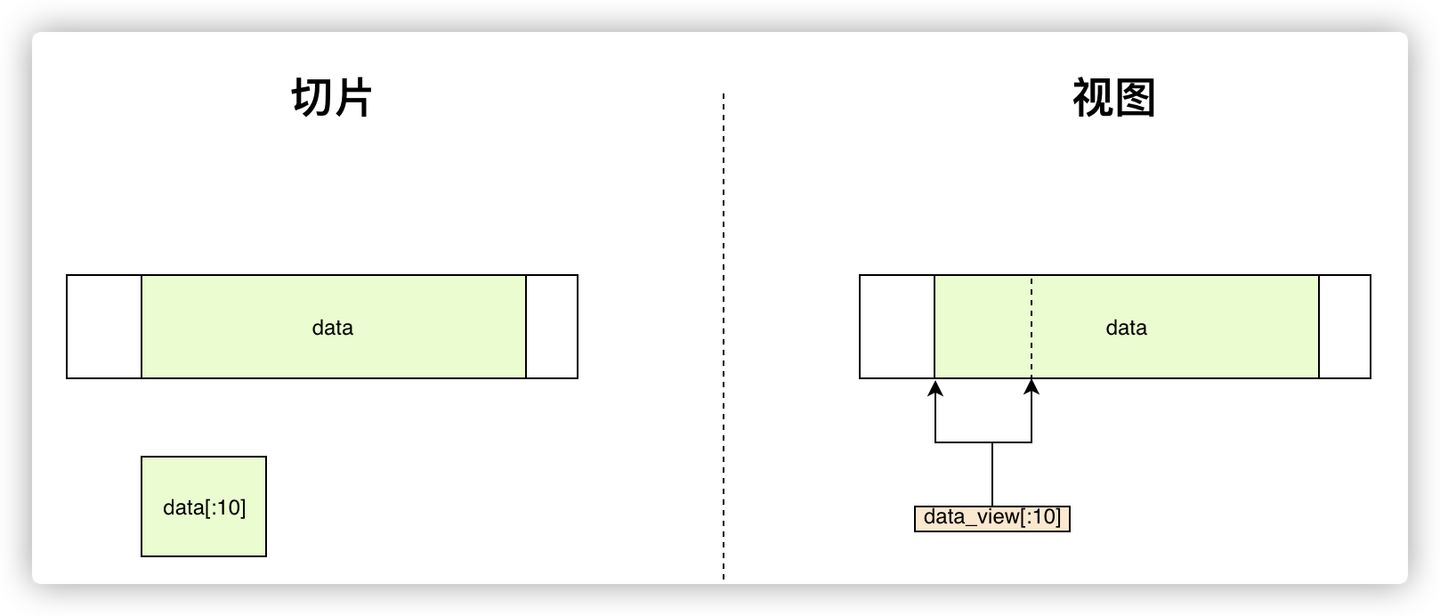
- 基本用法
| 用法 | 含义 | |---------------------|---------------| | v = memoryview(obj) | 创建内存视图对象 | | v[1] | 索引字节中的数据 | | v[1:5] | 内存切片 | | v[1:5].tobytes() | 内存数据转换为 bytes |
array.array {#array-array}
array 模块是 python 中实现的一种高效的数组存储类型,它和list相似,但是所有的数组成员必须是同一种类型。在创建数组的时侯, 就确定了数组的类型。
- array 支持的初始化类型
| Type code | C Type | Python Type | Minimum size in bytes |
|-----------|----------------|-------------------|-----------------------|
| 'c' | char | character | 1 |
| 'b' | signed char | int | 1 |
| 'B' | unsigned char | int | 1 |
| 'u' | Py_UNICODE | Unicode character | 2 (see note) |
| 'h' | signed short | int | 2 |
| 'H' | unsigned short | int | 2 |
| 'i' | signed int | int | 2 |
| 'I' | unsigned int | long | 2 |
| 'l' | signed long | int | 4 |
| 'L' | unsigned long | long | 4 |
| 'f' | float | float | 4 |
| 'd' | double | float | 8 |
- 支持方法
| 方法 | 含义 | |------------------------------------|--------------------------------------------------| | arr = array.array('i',[0,1,1,3]) | 建立有符号整型数组 | | arr.itemsize | 项目个数(和 len 数量不同) | | arr.append(5) | 追加元素 | | arr.buffer_info() | 获取数组在存储器中的地址、元素的个数,以元组形式(地址、长度)返回 | | arr.count(3) | 3 在数组中出现的次 | | arr.extend(_list) | n将可迭代对象的元素序列附加到数据的末尾,合并两个序列(数据需要类型相同) | | arr.fromlist(list) | 对象⽅法:将列表中的元素追加到数组后⾯,相当于for x in list:a.append(x) | | arr.index(x) | 对象⽅法:返回数组中x的最⼩下标 | | arr.insert(1,0) | 在下表1(负值表⽰倒数)之前插⼊值0 | | arr.pop(4) | 删除索引为4的值并返回 | | arr.remove(5) | 删除出现第一个5 | | arr.reverse() | 数组顺序反转 | | arr.tolist() | 数组转换为列表 |
是否可变 {#是否可变}
- 将Python 中内置序列按照能否修改也可以分为两类
可变序列 MutableSequence {#可变序列-MutableSequence}
-
表示可以修改序列中元素的内容而不需要额外创建新的对象
-
主要包含以下序列:
- list
- bytearray
- array.array
- collections.deque
- memoryview
不可变序列 Sequence {#不可变序列-Sequence}
- 表示序列中内容初始化后不可被在内存中原地修改
- 修改都是以创建新对象的形式完成的
- 主要包含:
- tuple
- str
- bytes
可变与不可变的关系 {#可变与不可变的关系}
- 二者的差异
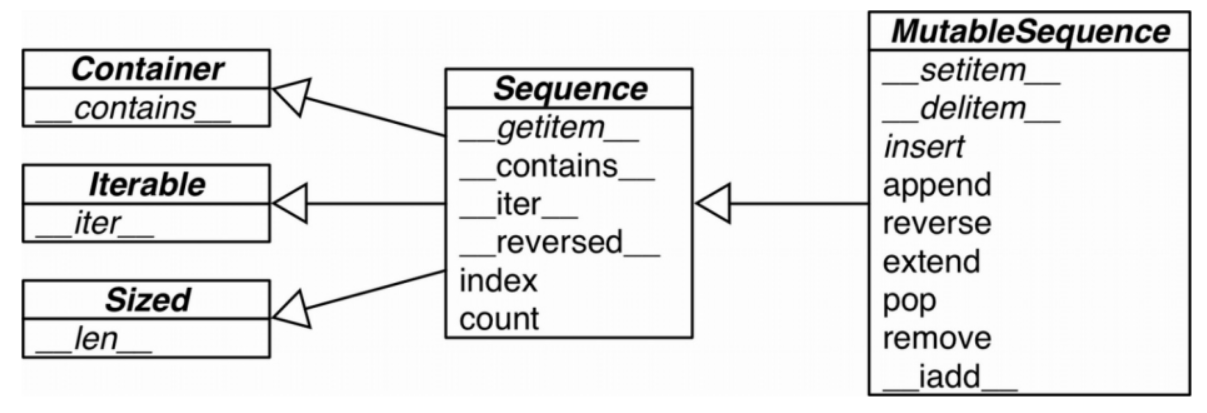
- 这个 UML 类图列举了 collections.abc 中的几个类(超类在左边,箭头从子类指向超类,斜体名称代表抽象类和抽象方法)
- 虽然内置的序列类型并不是直接从 Sequence 和 MutableSequence 这两个抽象基类(Abstract Base Class,ABC)继承而来的,但是了解这些基类可以帮助我们总结出那些完整的序列类型包含了哪些功能。
参考资料 {#参考资料}
- 流畅的Python(2017年人民邮电出版社出版)
- https://zhuanlan.zhihu.com/p/358852737
- https://blog.csdn.net/weixin_42136837/article/details/113647627
- http://c.biancheng.net/view/2175.html
- https://blog.csdn.net/u013008795/article/details/88945733
- https://zhuanlan.zhihu.com/p/336285305
- https://wenku.baidu.com/view/44ed8c1ddd80d4d8d15abe23482fb4daa58d1d8d.html




