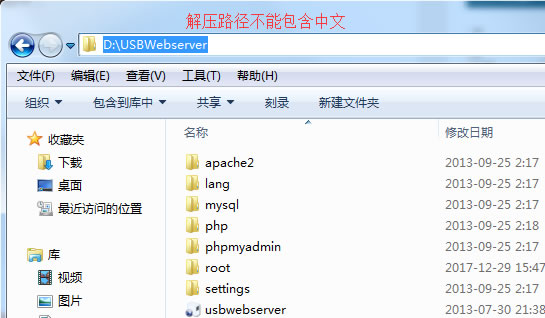
K-means 算法中,如何去度量聚类结果的优劣?以及 K 值究竟如何设定更加合适呢?下面我们通过几个方面来介绍下:
-
误差平方和(SSE )和 "肘" 方法
-
轮廓系数法(Silhouette Coefficient,SC)
-
CH 系数(Calinski Harabasz Index)
-
误差平方和(SSE )和 "肘" 方法 {#title-0} =================================
假设:我们现在有 3 个簇,累加每个簇的所属样本减去其质心的平方和,即为该聚类结果的误差平方和。
 图-1
图-1
- 考虑簇内的内聚程度
- k 表示质心的个数
- p 表示某个簇内的样本
- m 表示质心点
- SSE 的值越大说明聚类效果越不好
SSE 越小越好。我们通过 KMeans 对象的 inertia_ 属性来获得 SSE 误差平方和 值。
如何通过 SSE 来选择 K 值呢?
- 对于n个点的数据集,迭代计算 k from 1 to n,每次聚类完成后计算 SSE
- SSE 是会逐渐变小的,因为每个点都是它所在的簇中心本身。
- SSE 变化过程中会出现一个拐点,下降率突然变缓时即认为是最佳 n_clusters 值。
在决定什么时候停止训练时,肘方法同样有效,数据通常有更多的噪音,在增加分类无法带来更多回报时,我们停止增加类别。
示例代码如下:
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
if name == "main":
# 1. 创建数据集
X, y = make_blobs(n_samples=500,
n_features=2,
cluster_std=[0.3, 0.4, 0.6],
centers=[(-2, -2), (2, 2), (0, 0)],
random_state=2)
# 2. 计算不同 K 值对应的 SSE
sse = []
ks = range(1, 50)
# 开始逐步迭代
for k in ks:
# 初始化迭代器一次的 KMeans
my_kmeans = KMeans(n_clusters=k, max_iter=50, random_state=0)
my_kmeans.fit(X)
sse.append(my_kmeans.inertia_)
3. 绘制误差平方和变化曲线
plt.figure(figsize=(10, 5), dpi=80)
plt.title("误差平方和变化曲线")
plt.xticks(range(1, 50, 2), labels=range(1, 50, 2))
plt.plot(ks, sse)
plt.scatter(ks[::2], sse[::2])
plt.grid()
plt.show()
程序输出结果:
 图-3
图-3
在上图中,k = 3 时,误差平方和下降开始平缓,这是 "肘" 方法选择 K 值。
- 轮廓系数法(Silhouette Coefficient,SC) {#title-1} ==============================================
轮廓系数(Silhouette Coefficient),是聚类效果好坏的一种评价方式。最早由 Peter J. Rousseeuw 在 1986 提出。它结合内聚度和分离度两种因素。可以用来在相同原始数据的基础上用来评价不同算法、或者算法不同运行方式对聚类结果所产生的影响。
假设我们使用 K-means,将待分类数据分为了 k 个簇 ,对于簇中的每个向量,分别计算它们的轮廓系数。对于其中的一个样本 i 来说:
 图-4
图-4
a(i) = average(i向量到所有它属于的簇中其它点的距离)
b(i) = min (i向量到与它相邻最近的簇内的所有点的平均距离)
将所有样本点的轮廓系数求平均,就是该聚类结果 SC 轮廓系数,其范围为:[-1, 1],SC 系数越大越好。
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
if name == "main":
# 1. 创建数据集
X, y = make_blobs(n_samples=500,
n_features=2,
cluster_std=[0.3, 0.4, 0.6],
centers=[(-2, -2), (2, 2), (0, 0)],
random_state=2)
# 2. 计算不同 K 值对应的 SC 系数
sc = []
ks = range(2, 50)
for k in ks:
# 初始化迭代器一次的 KMeans
my_kmeans = KMeans(n_clusters=k, max_iter=50, random_state=0)
result = my_kmeans.fit_predict(X)
sc.append(silhouette_score(X, result))
3. 绘制误差平方和变化曲线
plt.figure(figsize=(10, 5), dpi=80)
plt.title("SC 变化曲线")
plt.xticks(range(2, 50, 2), labels=range(2, 50, 2))
plt.plot(ks, sc)
plt.scatter(ks[::2], sc[::2])
plt.grid()
plt.show()
程序输出结果为:
 图-5
图-5
- CH 系数(Calinski Harabasz Index) {#title-2} ============================================
CH 系数也同样考虑的是簇内紧凑,簇与簇之间距离越大越好,并同时考虑用尽可能少的簇将数据集聚类。
 图-6
图-6
该公式表示的含义是什么呢?
 图-7
图-7
【图-7】中 cpi 表示簇的质心,计算每个簇内的样本点到质心的距离的平方,我们希望该值越小越好。
 图-8
图-8
【图-8】中的 X 表示所有样本点的中心点,计算每个簇的质心到中心点的距离的平方,其中,每个距离的平方的权重则是每个簇的样本数量,我们希望该值越大越好。
SSB/SSW 表示希望SSW 尽量的小,SSB 尽量的大。
(m-k)/(k-1) 中的 k 表示簇的数量,表示用尽可能少的簇聚类更多的样本,当 k 大的时,我们发现 (m-k)/(k-1) 就会变小。
所以,我们说 CH 系数是综合考量了簇的个数、簇的紧凑型、簇之间的分离程度。
CH 系数越大越好,其表示用尽量少的类别聚类尽量多的样本,同时获得较好的聚类效果。
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
from sklearn.metrics import calinski_harabasz_score
if name == "main":
# 1. 创建数据集
X, y = make_blobs(n_samples=500,
n_features=2,
cluster_std=[0.3, 0.4, 0.6],
centers=[(-2, -2), (2, 2), (0, 0)],
random_state=2)
# 2. 计算不同 K 值对应的 SC 系数
ch = []
ks = range(2, 50)
for k in ks:
# 初始化迭代器一次的 KMeans
my_kmeans = KMeans(n_clusters=k, max_iter=50, random_state=0)
result = my_kmeans.fit_predict(X)
ch.append(calinski_harabasz_score(X, result))
3. 绘制误差平方和变化曲线
plt.figure(figsize=(10, 5), dpi=80)
plt.title("CH 变化曲线")
plt.xticks(range(2, 50, 2), labels=range(2, 50, 2))
plt.plot(ks, ch)
plt.scatter(ks[::2], ch[::2])
plt.grid()
plt.show()
程序输出结果为:

本篇文章主要介绍了聚类效果的评估方法:SSE、SC、CH,及其计算方法。至此,本篇文章结束