如今,AI绘画技术的发展已经迈出了令人瞩目的一步。普通用户只需输入文本,就能生成具有独特风格和想象力的图像。最近有一项最新研究似乎又取得了突破性进展,使得AI在图像处理方面超过了传统抠图技术,并引起广泛关注和讨论。

这项名为LayerDiffusion的技术由ControlNet作者Lvmin Zhang发布。在介绍这项技术之前,我们先来简单介绍一下这位作者背后的故事。他之前创作的Stable Diffusion为AI绘画提供了关键突破。虽然普通人可以通过输入简单文本输出高质量图片,但随着样本增多,问题也逐渐显露出来。尽管模型很强大,但生成的图片往往无法完全受用户控制,需要使用大量限定词才能生成可用图片。
ControlNet解决了这个问题,在输入时直接提供构图、姿势等深度信息。它消除了频繁尝试并基于运气选择合适关键词的麻烦,并解决了手指等特定关键点的问题。这位在AI绘画领域做出巨大贡献的作者是如何发展的,我们将有机会向大家介绍。

回到LayerDiffusion,该项目和ControlNet一样,解决了实际应用中常见的问题:生成4通道RGBA图像,效果不亚于商业抠图。除了单个透明图像外,它还能生成多层图片,分离元素与背景。这对于作图或抠图人员来说是理想工具。

LayerDiffusion利用大型预训练潜在扩散模型(latent diffusion model)创建透明图像。这项技术不仅可以生成单个透明图片,还能生成多层透明图层。尽管LayerDiffusion项目已经开源并可在Forge上使用,并通过测试证明其功能强大------不仅支持直接生成透明图片元素,还可以与环境融合生成透明内容。据网络调查显示,在相同条件下(如先生成再处理),相比临时解决方案,人们更喜欢直接产生的透明内容。

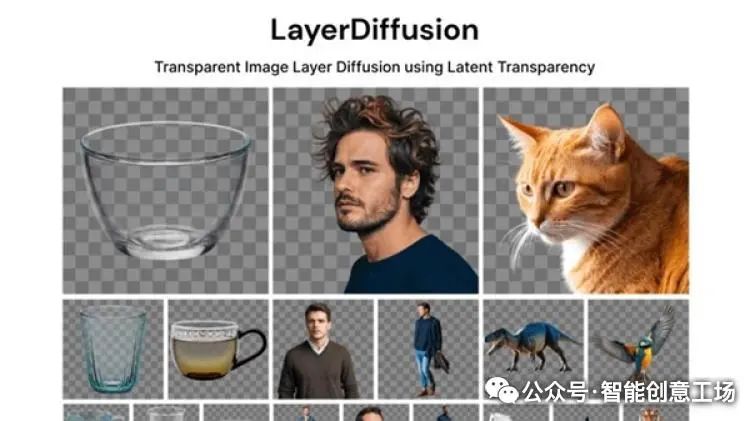

传统抠图技术通常基于颜色、纹理等特征进行分割,在处理半透明效果或复杂边缘时存在清晰度差、细节丢失等问题。而LayerDiffusion技术通过深度学习模型精细分析图像,识别出不同层次的物体和背景,并将它们分别绘制在不同图层上。这种分图层技术不仅提高了图像处理效率,还保留更多细节和信息,使得处理后的图片更真实自然。
虽然该技术目前仍处于研究和商业化阶段,并已开源部分代码,但已经引起大量关注和讨论。人们对AI在图像处理领域的潜力充满好奇和期待,并希望看到更多类似创新技术的问世,以进一步提升图像处理水平和效率。 
除了在图像处理领域应用外,该技术还可扩展到动画制作、游戏开发、虚拟现实等其他领域。例如,在动画制作中,利用AI绘画技术可以更快速精确地绘制角色与背景,提高制作效率与质量;在游戏开发中,则可以借助AI绘画技术实现逼真精致的场景与角色设计,提升游戏体验。
**如何使用LayerDiffusion**
图像生成和基本图层功能现已运行,但透明img2img尚未完成(大约一周内完成)。
该代码库是高度动态的,可能在下个月发生很大变化。如果您来自专业内容创作工作室,需要严格重现之前的所有结果,您可以考虑在每次更新时备份文件。 在你开始之前
因为很多人可能好奇**LayerDiffusion**过程中的潜在预览是什么样子,所以我录制了一个视频,以便您在下载模型和扩展之前可以看到它: 可以看到,原生透明漫射可以处理透明玻璃、半透明发光效果等,这是简单的背景去除方法无法实现的。原生透明漫射还为您提供了详细的毛皮、头发、胡须以及像骨骼一样的详细结构。 **适用绘画模型:** 请注意,当前发布的所有型号均适用于 SDXL。如果需要,SD1.5 的型号可能会在稍后提供。 请注意,在此扩展中,所有模型下载/选择都是全自动的。事实上,大多数用户可以跳过此部分。
已发布以下模型:
1. layer_xl_transparent_attn.safetensors这是一个 256 级 LoRA,可将 SDXL 变成透明图像生成器。它将模型的潜在分布更改为可以通过特殊 VAE 管道解码的"透明潜在空间"。 2. layer_xl_transparent_conv.safetensors这是将 SDXL 变成透明图像生成器的替代模型。该安全张量文件包含所有转换层的偏移量(实际上,所有不是任何关注层的 q、k、v 的层)。这些偏移可以合并到任何 XL 模型中,以将潜在分布更改为透明图像。因为我们排除了任何 q,k,v 层的偏移训练,所以对 SDXL 的即时理解应该被完美保留。然而,在实践中,我发现这layer_xl_transparent_attn.safetensors会带来更好的结果。layer_xl_transparent_conv.safetensors对于一些需要特别提示理解的特殊用例,这仍然包括在内。此外,该模型可能会对基础模型产生强烈的风格影响。 3. layer_xl_fg2ble.safetensors这是一个安全张量文件,包含将 SDXL 转换为图层生成模型的偏移量,该模型以前景为条件,并生成混合合成。 4. layer_xl_fgble2bg.safetensors这是一个安全张量文件,包含将 SDXL 转换为图层生成模型的偏移量,该模型以前景和混合合成为条件,并生成背景。 5. layer_xl_bg2ble.safetensors这是一个安全张量文件,包含将 SDXL 转换为图层生成模型的偏移量,该模型以背景为条件,并生成混合合成。 6. layer_xl_bgble2fg.safetensors这是一个安全张量文件,包含将 SDXL 转换为图层生成模型的偏移量,该模型以背景和混合合成为条件,并生成前景。 7. vae_transparent_encoder.safetensors这是一个图像编码器,用于从像素空间中提取潜在偏移。可以将偏移添加到潜像中以帮助透明度的扩散。请注意,在本文中,我们使用了一个相对较重的模型,其参数数量与 SD VAE 完全相同。发布的模型重量更轻,需要更少的 vram,并且不会影响我的测试结果质量。 8. vae_transparent_decoder.safetensors这是一个图像解码器,以 SD VAE 输出和潜在图像作为输入,并输出真实的 PNG 图像。该模型架构也比纸质版本更轻量,以减少 VRAM 需求。我已确保减少的参数不会影响结果质量。
(3月4日更新)以下型号即将发布:
1. 联合前景-背景生成模型。SDXL 模型的速度会慢 3 倍,并且需要 3.5 倍以上的 VRAM,但会在一次传递中同时生成前景和背景。(SD1.5型号也将发布,SD1.5型号速度非常快并且没有太大性能问题。) 2. 一步前景条件背景模型。SDXL 模型的速度会慢 2 倍,并且需要 2.5 倍以上的 VRAM,但会在一次传递中生成更清晰的背景(与已发布的两步模型相比)。(SD1.5型号也将发布,SD1.5型号速度非常快并且没有太大性能问题。) 3. 一步背景条件前景模型。SDXL 模型的速度会慢 2 倍,并且需要 2.5 倍以上的 VRAM,但会在一次传递中生成更清晰的前景(与已发布的两步模型相比)。(SD1.5型号也将发布,SD1.5型号速度非常快并且没有太大性能问题。) 4. SD1.5型号。
以下型号可能很快就会发布(如有需要):
1. 可以一起生成前景和背景的模型(使用类似于 AnimateDiff 的注意力共享)。我之所以搁置这个模型,是因为以下原因:(1)其他发布的模型已经可以实现所有功能,而这个模型没有带来更多的功能。(2) 该模型的推理速度比其他模型慢 3 倍,并且需要比其他已发布模型多 4 倍的 VRAM,如果有必要,我正在努力减少该模型的 VRAM。(3) 这个模型将涉及更多的超参数,如果需要,我将在发布之前研究推理/训练的最佳实践。在我们完成最终的 VRAM 优化后,该模型确认将很快发布,具有联合层生成和一步 bg/fg 条件 2. 当前的背景条件前景模型可能有点太轻量级了。我可能会发布一个更重的、具有更多参数和不同行为的版本(另请参阅稍后的讨论)。 3. 由于扩散器训练和 k-扩散推理之间的差异,我可以观察到一些神秘的问题,例如有时 DPM++ 会产生伪影,但 Euler A 会修复它。我正在研究它,可能会提供一些修改后的模型,可以更好地与所有 A1111 采样器配合。
完整性检查 ===== 我们强烈建议您进行健全性检查并获得完全相同的结果(这样,如果出现任何问题,我们就会知道问题是否出在我们这边)。
使用的两个模型是:
1. https://civitai.com/models/133005?modelVersionId=198530 Juggernaut XL V6(注意用的是V6,不是v7或v8或V9)
2. https://civitai.com/models/261336?modelVersionId=295158 anima_pencil-XL 1.0.0 (注意使用的是1.0.0,而不是 1.5.0 )
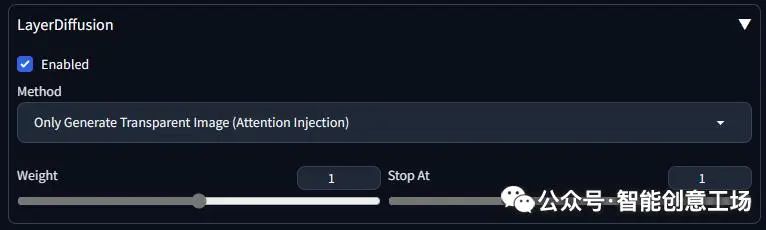
我们将首先测试透明图像的生成。将您的扩展设置为:

一个苹果,高品质
负面提示:不好、丑陋
步骤:20,采样器:DPM++ 2M SDE Karras,CFG规模:5,种子:12345,大小:1024x1024,模型哈希:1fe6c7ec54,模型:juggernautXL_version6Rundiffusion,layerdiffusion_enabled:True,layerdiffusion_method:仅生成透明图像(注意力注入),layerdiffusion_weight:1、layerdiffusion_ending_step:1、layerdiffusion_fg_image:False、layerdiffusion_bg_image:False、layerdiffusion_blend_image:False、layerdiffusion_resize_mode:裁剪和调整大小,版本:f0.0.17v1.8.0rc-latest-269-gef35383b
确保你得到这个苹果
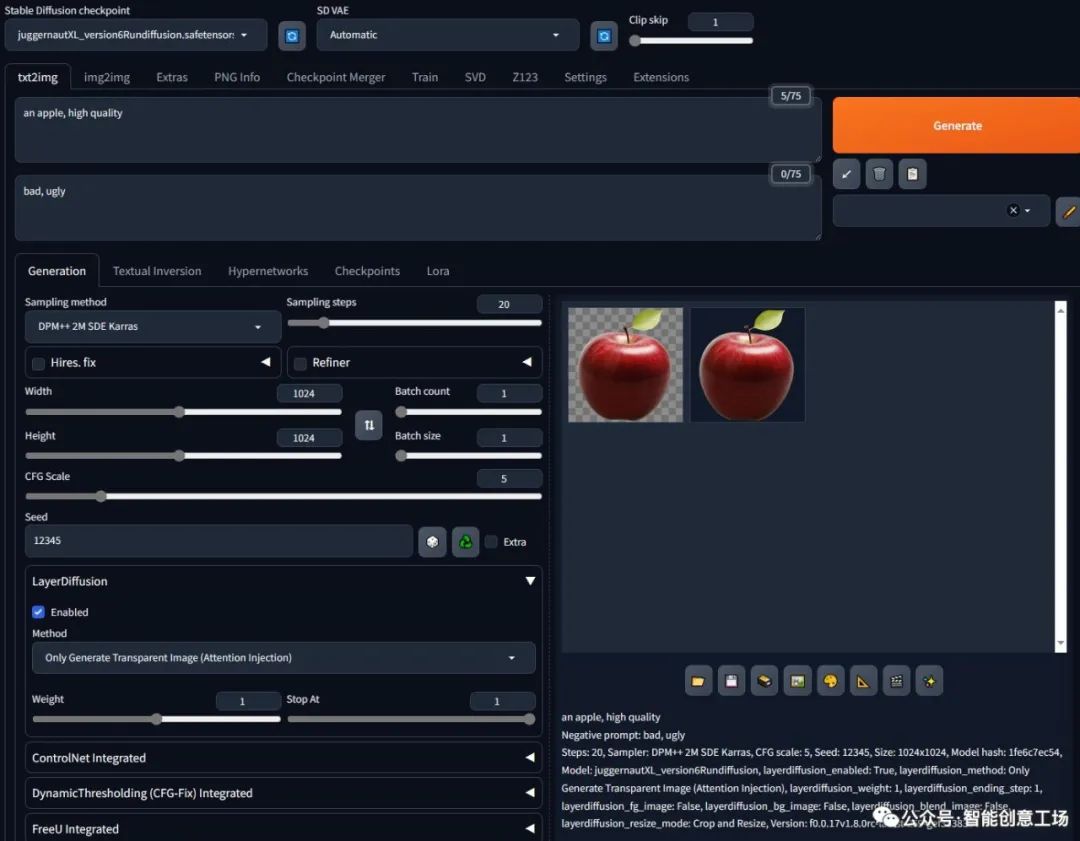


女人,凌乱的头发,高品质
负面提示:不好、丑陋
步骤:20,采样器:DPM++ 2M SDE Karras,CFG规模:5,种子:12345,大小:1024x1024,模型哈希:1fe6c7ec54,模型:juggernautXL_version6Rundiffusion,layerdiffusion_enabled:True,layerdiffusion_method:仅生成透明图像(注意力注入),layerdiffusion_weight:1、layerdiffusion_ending_step:1、layerdiffusion_fg_image:False、layerdiffusion_bg_image:False、layerdiffusion_blend_image:False、layerdiffusion_resize_mode:裁剪和调整大小,版本:f0.0.17v1.8.0rc-latest-269-gef35383b
确保你得到的女人头发像这样乱
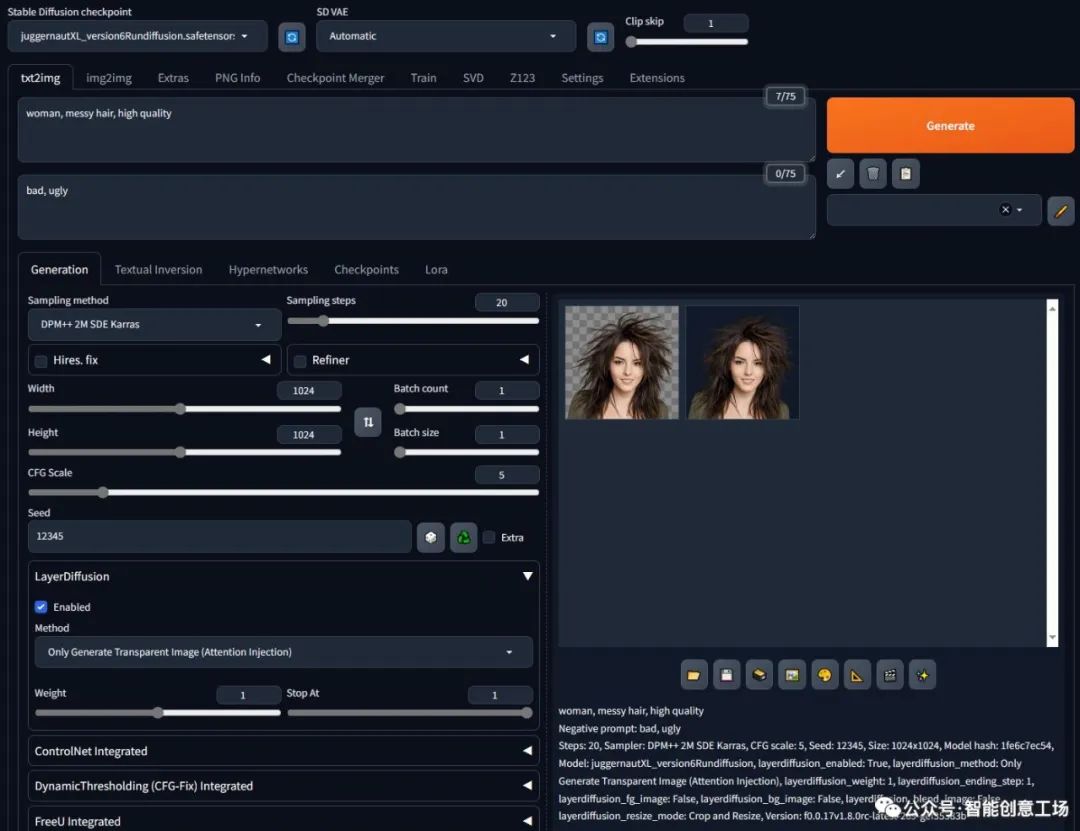

玻璃杯,高品质
负面提示:不好、丑陋
步骤:20,采样器:DPM++ 2M SDE Karras,CFG规模:5,种子:12345,大小:1024x1024,模型哈希:1fe6c7ec54,模型:juggernautXL_version6Rundiffusion,layerdiffusion_enabled:True,layerdiffusion_method:仅生成透明图像(注意力注入),layerdiffusion_weight:1、layerdiffusion_ending_step:1、layerdiffusion_fg_image:False、layerdiffusion_bg_image:False、layerdiffusion_blend_image:False、layerdiffusion_resize_mode:裁剪和调整大小,版本:f0.0.17v1.8.0rc-latest-269-gef35383b
确保你拿到这个杯子
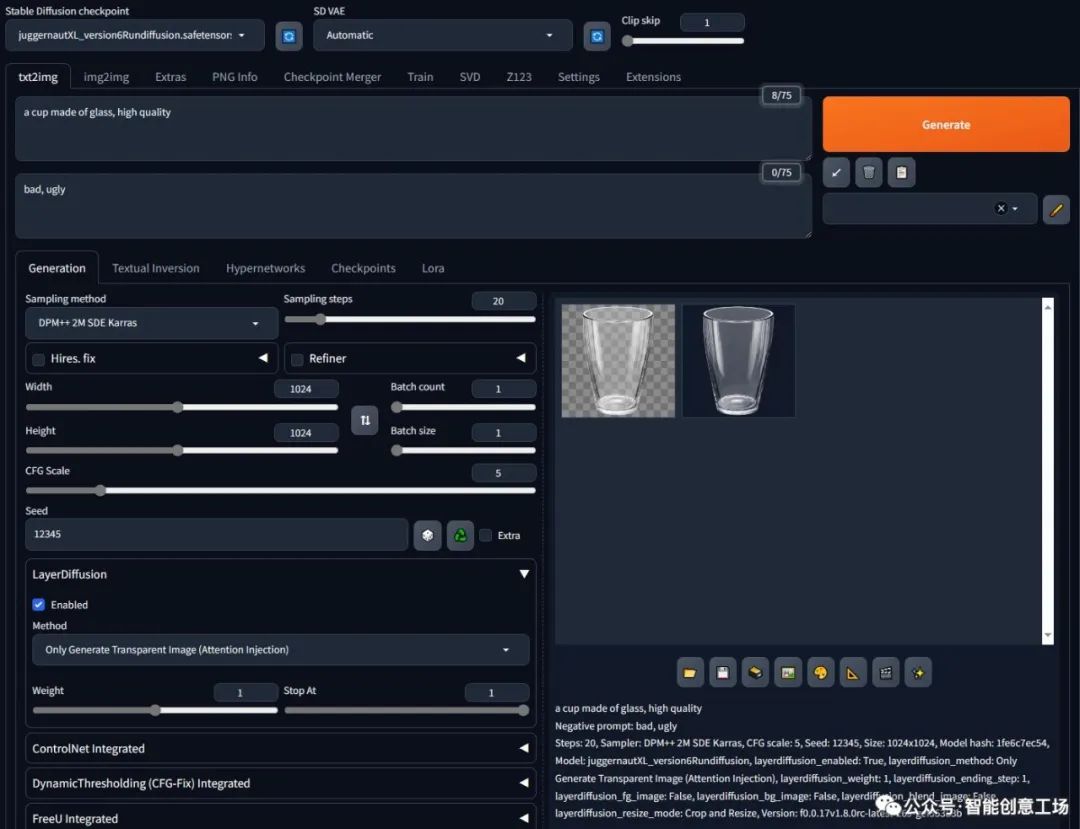

发光效果,魔法书,高品质
负面提示:不好、丑陋
步骤:20,采样器:DPM++ 2M SDE Karras,CFG规模:7,种子:12345,大小:1024x1024,模型哈希:1fe6c7ec54,模型:juggernautXL_version6Rundiffusion,layerdiffusion_enabled:True,layerdiffusion_method:仅生成透明图像(注意力注入),layerdiffusion_weight:1、layerdiffusion_ending_step:1、layerdiffusion_fg_image:True、layerdiffusion_bg_image:False、layerdiffusion_blend_image:True、layerdiffusion_resize_mode:裁剪和调整大小,版本:f0.0.17v1.8.0rc-latest-269-gef35383b
确保您收到这本发光的书
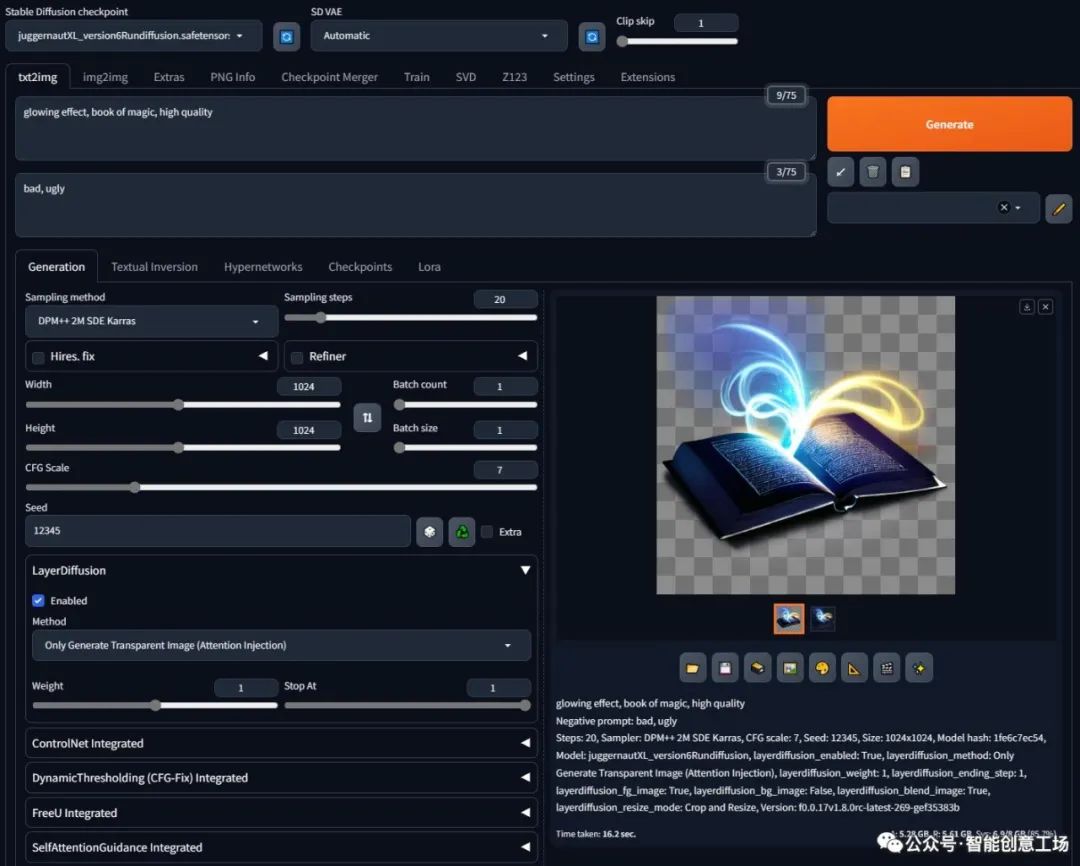

好的,然后让我们继续看更长一点的提示: (此提示来自https://civitai.com/images/3160575)
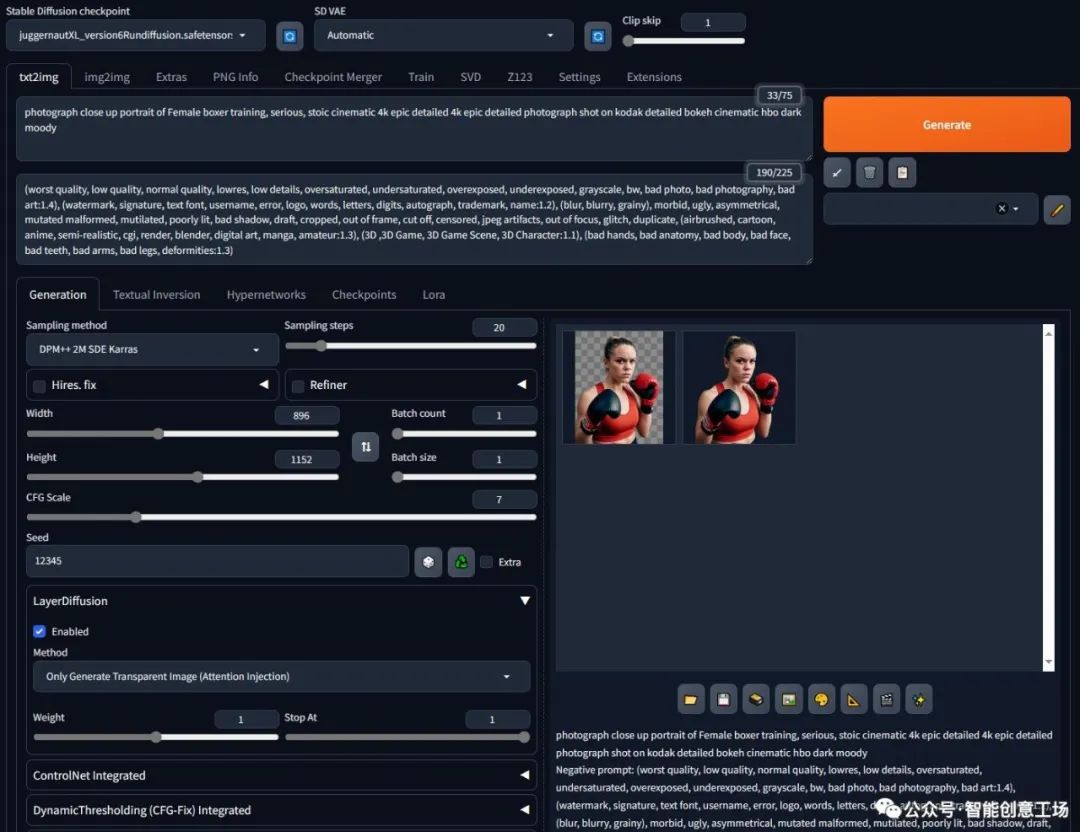
照片特写女拳击手训练肖像,严肃,坚忍电影 4k 史诗详细 4k 史诗详细照片在柯达拍摄详细散景电影 hbo 黑暗穆迪
负提示:(最差质量、低质量、普通质量、低分辨率、低细节、过饱和、欠饱和、曝光过度、曝光不足、灰度、黑白、糟糕的照片、糟糕的摄影、糟糕的艺术:1.4)、(水印、签名、文本字体、用户名、错误、徽标、单词、字母、数字、亲笔签名、商标、名称:1.2)、(模糊、模糊、粒状)、病态、丑陋、不对称、变异畸形、残缺、光线不足、阴影不良、草稿、裁剪、出框、切断、审查、jpeg 伪像、失焦、故障、重复、(喷绘、卡通、动漫、半写实、cgi、渲染、搅拌机、数字艺术、漫画、业余爱好者:1.3)、(3D、 3D游戏,3D游戏场景,3D角色:1.1),(坏手,坏解剖,坏身体,坏脸,坏牙齿,坏胳膊,坏腿,畸形:1.3)
步骤:20,采样器:DPM++ 2M SDE Karras,CFG规模:7,种子:12345,大小:896x1152,模型哈希:1fe6c7ec54,模型:juggernautXL_version6Rundiffusion,layerdiffusion_enabled:True,layerdiffusion_method:仅生成透明图像(注意力注入),layerdiffusion_weight:1、layerdiffusion_ending_step:1、layerdiffusion_fg_image:False、layerdiffusion_bg_image:False、layerdiffusion_blend_image:False、layerdiffusion_resize_mode:裁剪和调整大小,版本:f0.0.17v1.8.0rc-latest-269-gef35383b

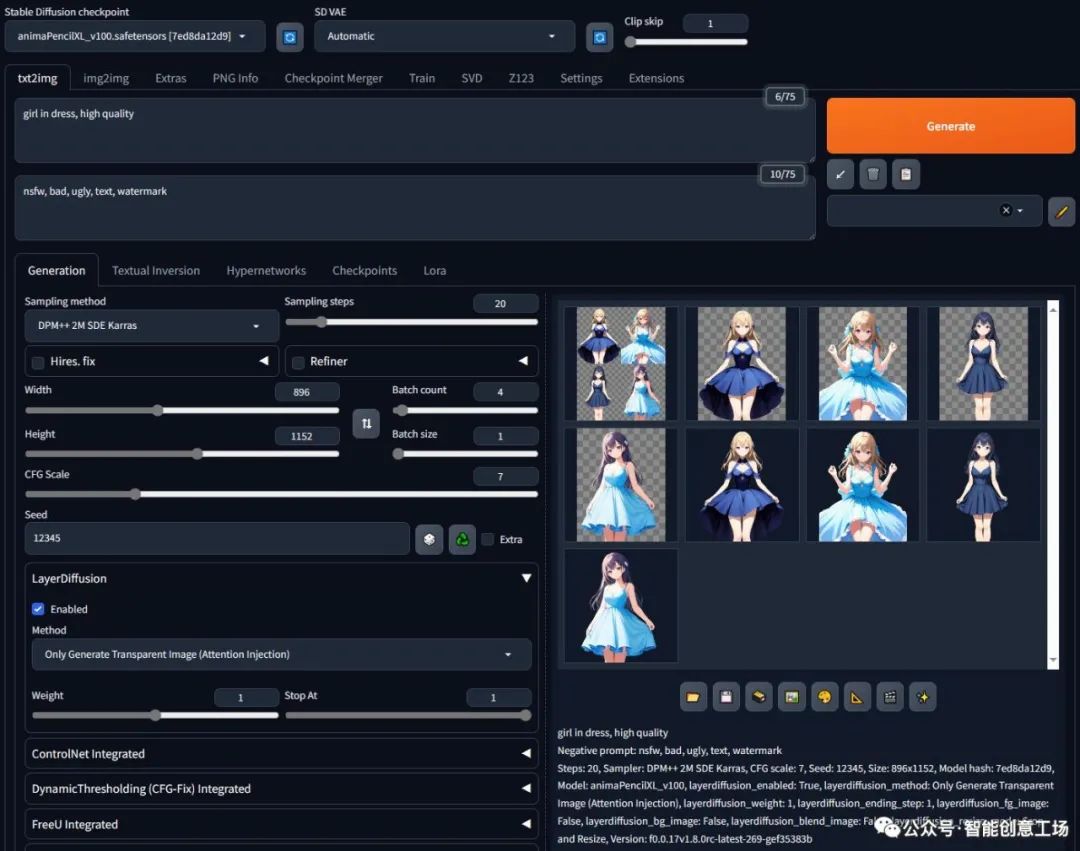
动漫模型测试:
穿裙子的女孩,高品质
负面提示:nsfw、坏、丑、文字、水印
步骤:20,采样器:DPM++ 2M SDE Karras,CFG规模:7,种子:12345,大小:896x1152,模型哈希:7ed8da12d9,模型:animaPencilXL_v100,layerdiffusion_enabled:True,layerdiffusion_method:仅生成透明图像(注意力注入),layerdiffusion_weight:1、layerdiffusion_ending_step:1、layerdiffusion_fg_image:False、layerdiffusion_bg_image:False、layerdiffusion_blend_image:False、layerdiffusion_resize_mode:裁剪和调整大小,版本:f0.0.17v1.8.0rc-latest-269-gef35383b
(我不太擅长用AnimagineXL格式编写提示,也许你可以用更好的提示得到更好的结果)
### 背景图片
首先下载这个图片: 
然后设置界面
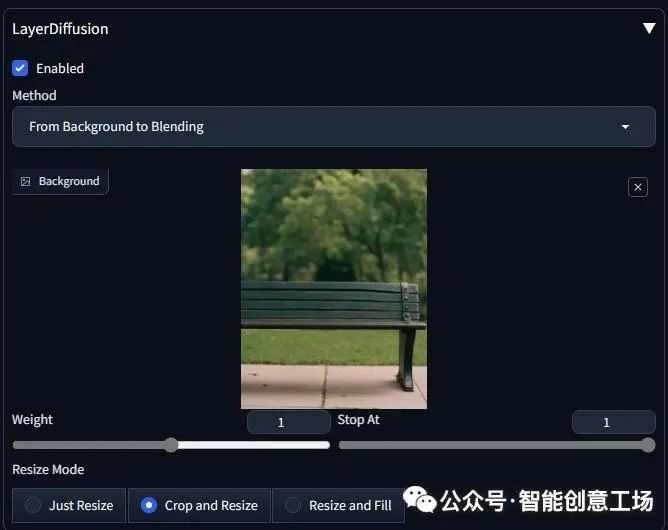
然后设置参数
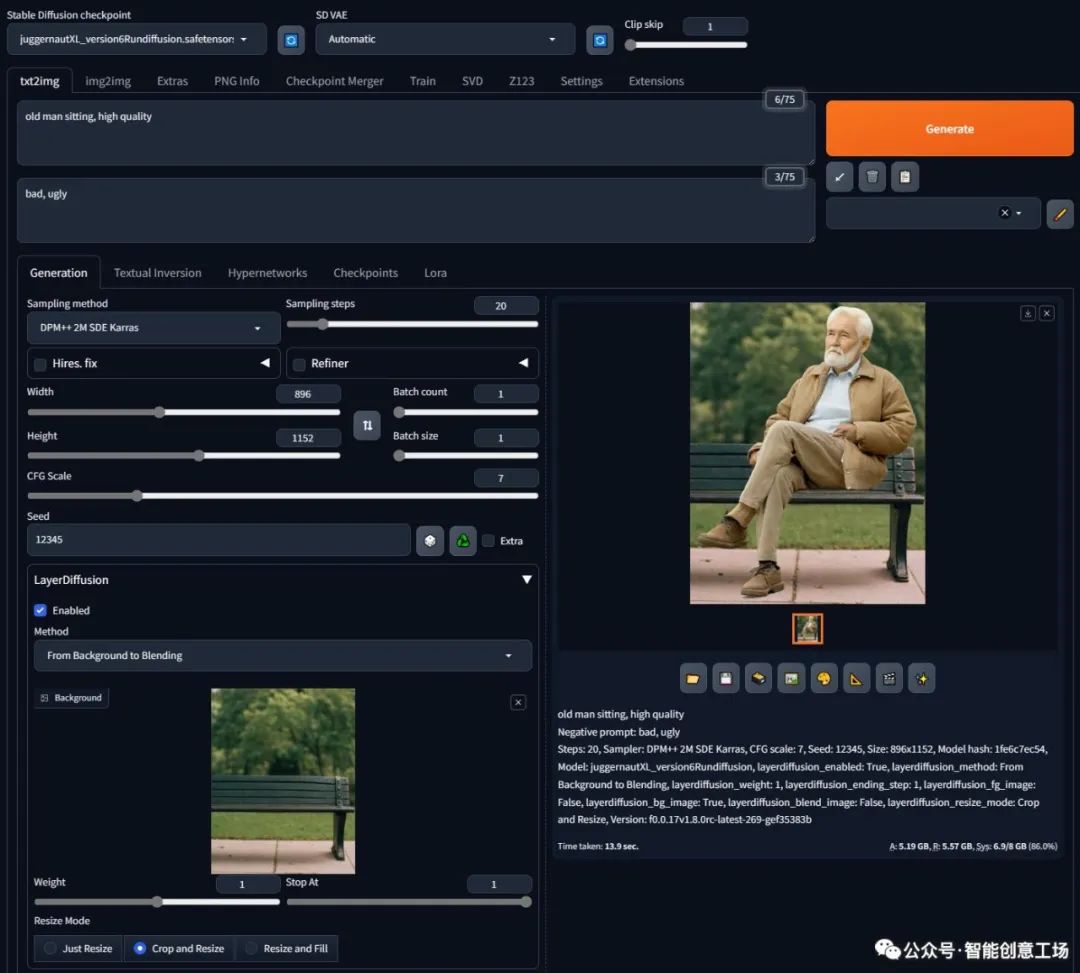
老人坐着,高品质
负面提示:不好、丑陋
步骤:20,采样器:DPM++ 2M SDE Karras,CFG 规模:7,种子:12345,大小:896x1152,模型哈希:1fe6c7ec54,模型:juggernautXL_version6Rundiffusion,layerdiffusion_enabled:True,layerdiffusion_method:从背景到混合,layerdiffusion_weight:1,layerdiffusion_ending_step:1、layerdiffusion_fg_image:False、layerdiffusion_bg_image:True、layerdiffusion_blend_image:False、layerdiffusion_resize_mode:裁剪和调整大小,版本:f0.0.17v1.8.0rc-latest-269-gef35383b
然后设置界面(您首先更改模式,然后将图像从结果拖到界面)
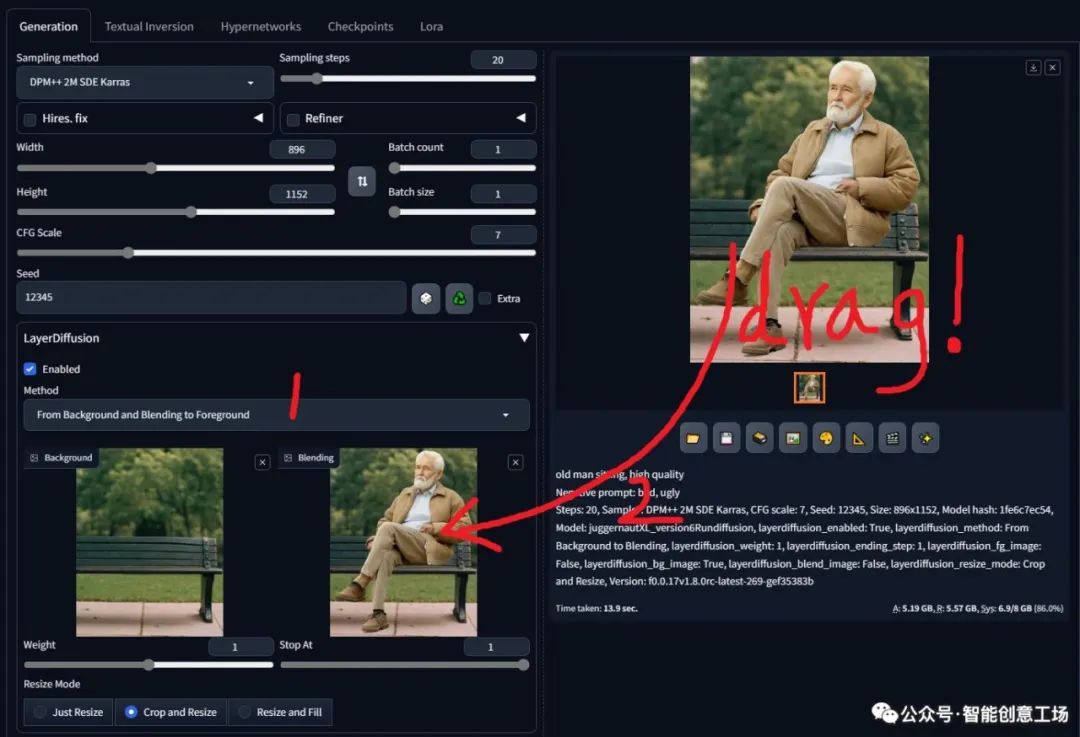
然后将采样器更改为 Euler A 或 UniPC 或其他不是 dpm 的采样器(这可能是因为扩散器训练脚本和 webui 的 k-diffusion 之间存在一些差异。我仍在研究这一点,并且可能会修改我的训练脚本和模型很快,这一步将被删除。)
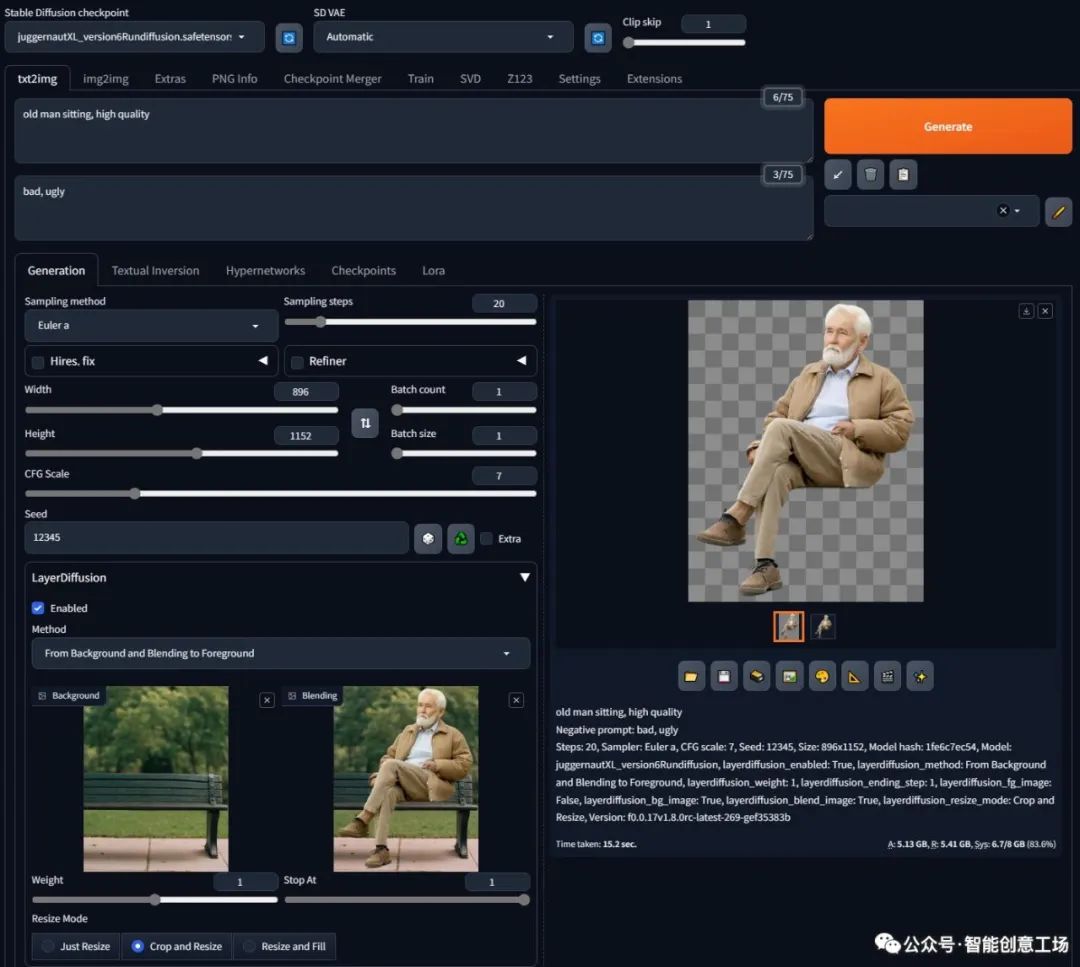
常问问题:
*好的。但是怎样才能得到这样的背景图片呢?*
您可以使用前景条件来获得这样的背景。我们将在下一节中描述它。
或者,您可以使用旧的修复技术对任何图像执行前景去除,以获得这样的背景。
*等待。为什么要分两步生成呢?我可以一次性生成它吗?*
两个步骤可以实现更灵活的编辑。如果有必要,我们将很快发布一步模型,但该模型大 2 倍,需要 4 倍大的 VRAM,并且我们仍在努力减少该模型的计算需求。(但在我的测试中,大多数情况下当前的解决方案都比该模型更好。)
另外你可以看到当前的模型大约是 680MB,特别是我认为它有点太轻量级了,很快就会发布一个相对较重的模型,以实现潜在的更强的结构理解(但这仍在实验中)。
前景条件 ====
首先我们生成一只狗 一只狗坐着,高品质 负面提示:不好、丑陋
步骤:20,采样器:DPM++ 2M SDE Karras,CFG规模:7,种子:12345,大小:896x1152,模型哈希:1fe6c7ec54,模型:juggernautXL_version6Rundiffusion,layerdiffusion_enabled:True,layerdiffusion_method:仅生成透明图像(注意力注入),layerdiffusion_weight:1、layerdiffusion_ending_step:1、layerdiffusion_fg_image:True、layerdiffusion_bg_image:False、layerdiffusion_blend_image:False、layerdiffusion_resize_mode:裁剪和调整大小,版本:f0.0.17v1.8.0rc-latest-269-gef35383b
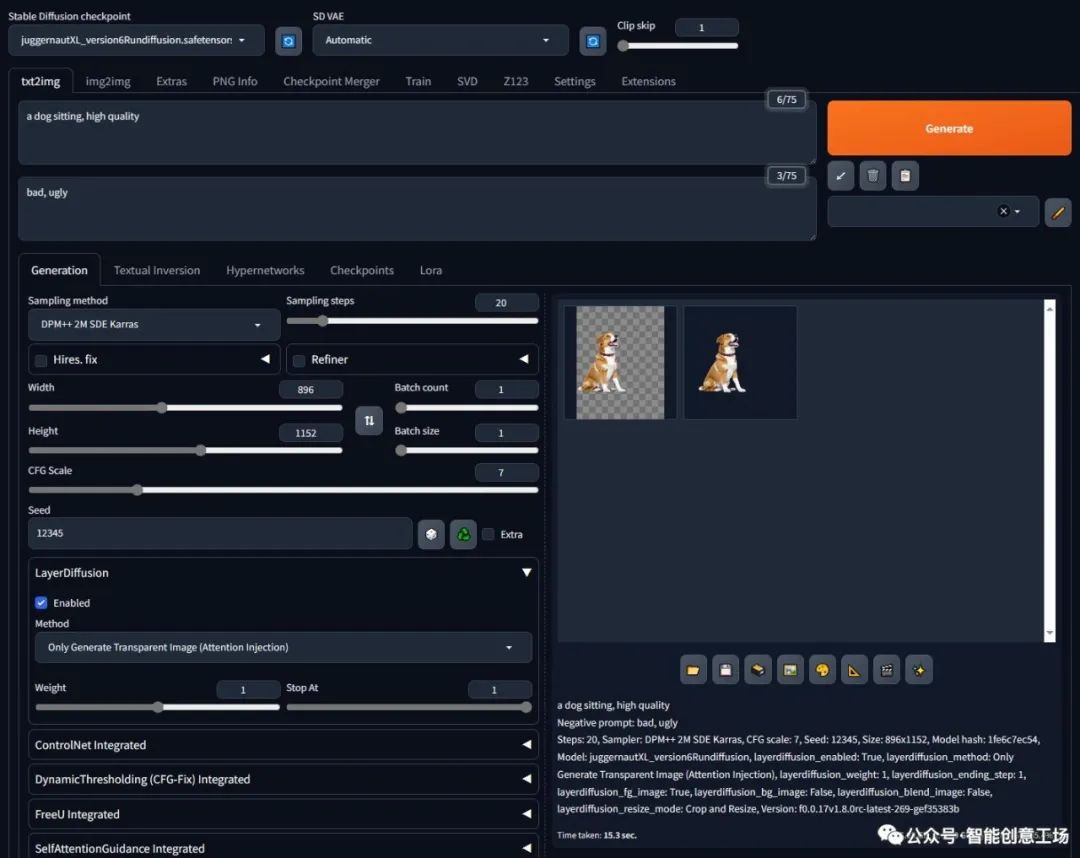

然后更改为`From Foreground to Blending`并将透明图像拖动到前景输入。
请注意,您拖动的是真正的透明图像,而不是具有棋盘背景的可视化效果。确保你看到这个
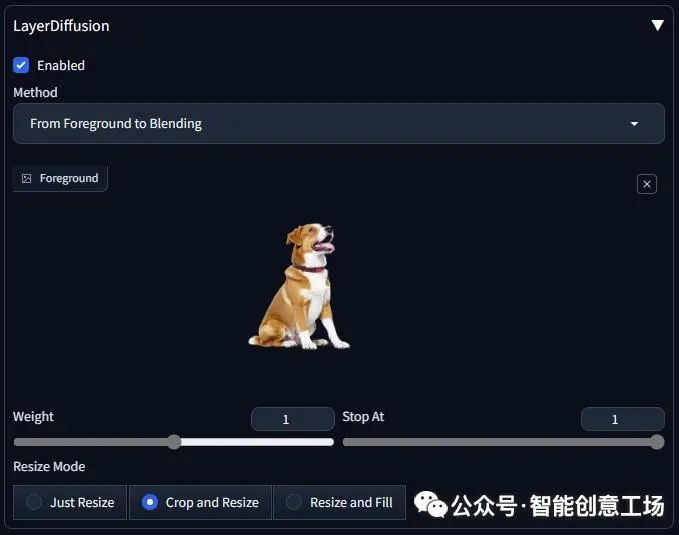
然后这样做
一只狗坐在房间里,高品质
负面提示:不好、丑陋
步骤:20,采样器:DPM++ 2M SDE Karras,CFG 规模:7,种子:12345,大小:896x1152,模型哈希:1fe6c7ec54,模型:juggernautXL_version6Rundiffusion,layerdiffusion_enabled:True,layerdiffusion_method:从前景到混合,layerdiffusion_weight:1,layerdiffusion_ending_step:1、layerdiffusion_fg_image:True、layerdiffusion_bg_image:False、layerdiffusion_blend_image:False、layerdiffusion_resize_mode:裁剪和调整大小,版本:f0.0.17v1.8.0rc-latest-269-gef35383b
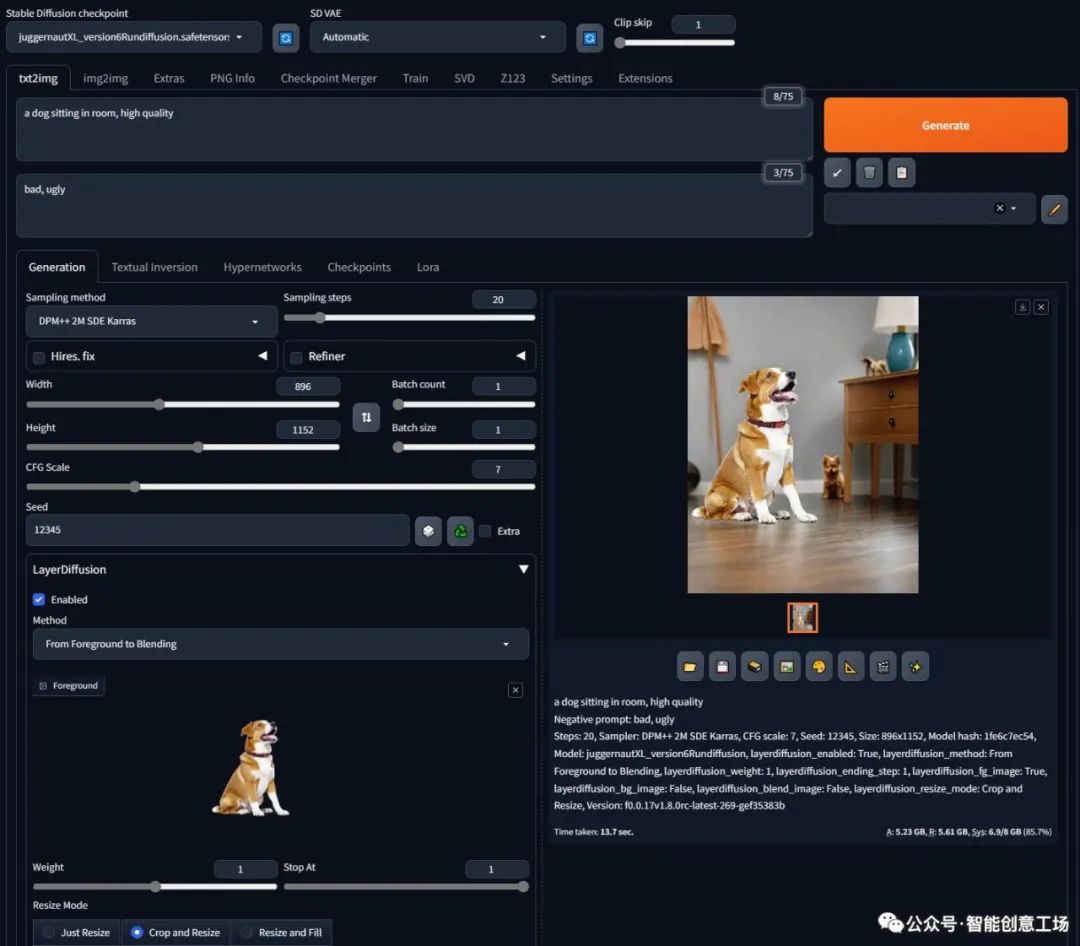
然后改变模式,拖动你的图像,这样
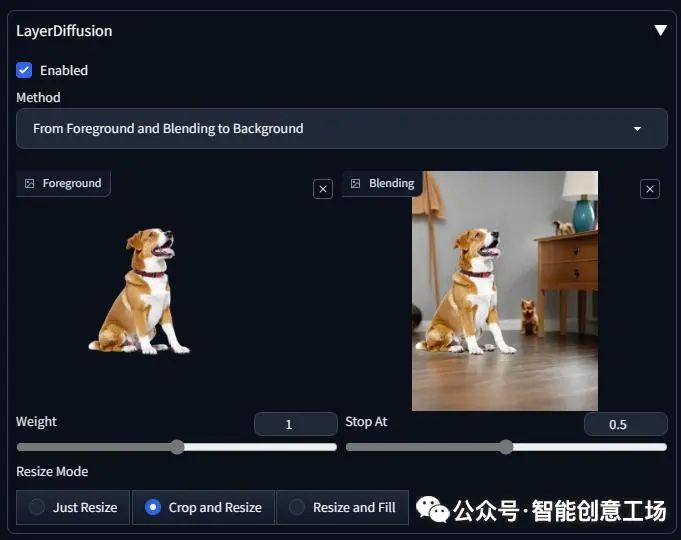
(请注意,这里我将 stop 设置为 0.5 以获得更好的结果,因为我不需要 bg 完全相同)
然后将采样器更改为 Euler A 或 UniPC 或其他不是 dpm 的采样器(这可能是因为扩散器训练脚本和 webui 的 k-diffusion 之间存在一些差异。我仍在研究这一点,并且可能会修改我的训练脚本和模型很快,这一步将被删除。)
然后这样做
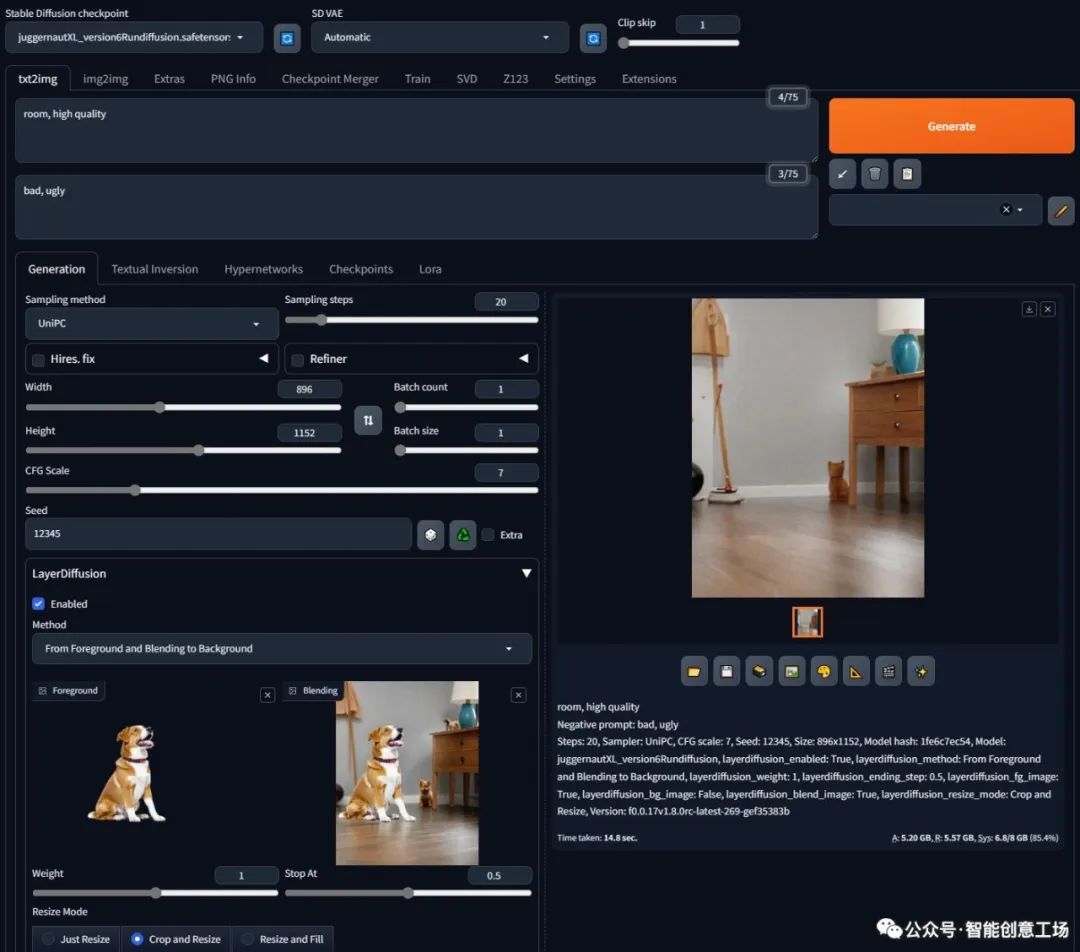
房间,高品质
负面提示:不好、丑陋
步骤:20,采样器:UniPC,CFG 规模:7,种子:12345,大小:896x1152,模型哈希:1fe6c7ec54,模型:juggernautXL_version6Rundiffusion,layerdiffusion_enabled:True,layerdiffusion_method:从前景并混合到背景,layerdiffusion_weight:1,layerdiffusion_ending_step:0.5 ,layerdiffusion_fg_image:True,layerdiffusion_bg_image:False,layerdiffusion_blend_image:True,layerdiffusion_resize_mode:裁剪和调整大小,版本:f0.0.17v1.8.0rc-latest-269-gef35383b
如果你感兴趣,请前往作者官网了解更多信息,并不要忘记下载Stable Diffusion亲自体验。当然,这对硬件配置要求较高,没有一块性能强悍的显卡怎么行!全新影驰GeForce RTX 40 SUPER系列GPU在AI工作负载方面表现出色。与RTX 3080 Ti相比,在生成视频方面速度提高了1.5倍,在生成图像方面速度提高了1.7倍。作为PC上体验AI最佳的显卡系列,专用AI Tensor Core可提供高达836 AI TOPS,为游戏、创作和日常工作等领域带来革命性的AI性能。
开源地址:
**https://github.com/layerdiffusion/sd-forge-layerdiffuse**
**https://github.com/layerdiffusion/LayerDiffuse**