* 杨立昆团队提出图像世界模型:在视觉表征学习中学习和利用世界模型 * 具身智能新突破:将现实世界中的仿人控制视为下一个 token 预测 * 微软新研究:迈向整体智能的 Agent AI * Google DeepMind:让机器人学会动作语言 * Meta、StabilityAI 新研究:用强化学习增强大模型推理 * 华为文生图大模型:仅 0.6B,生成 4K 分辨率图像 * 天大提出 SheetAgent:通过大模型进行电子表格推理和操作 * Design2Code:我们离前端工程自动化还有多远? * StableDrag:为基于点的图像编辑提供稳定的拖动功能 * MovieLLM:利用人工智能生成的电影增强对长视频的理解 * AtomoVideo:高保真图像视频生成器 * ChatDiet:个性化食品推荐 AI 聊天机器人 * EyeGPT:大模型驱动的眼科助手 * 在神经科学领域,大模型超越了人类专家 * 7B语言模型,已具备强大的数学能力
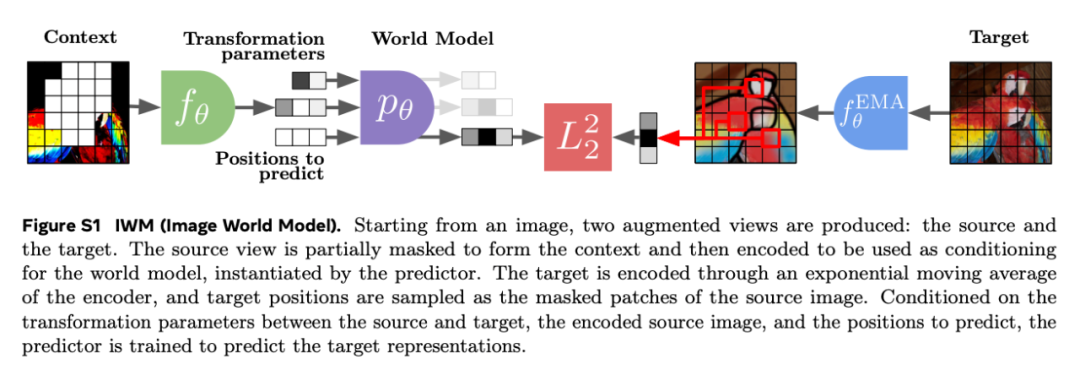
**1.杨立昆团队提出图像世界模型:在视觉表征学习中学习和利用世界模型** 联合嵌入预测架构(JEPA)通过利用世界模型进行学习,被认为是一种很有前途的自监督方法,但以往仅限于预测输入中的缺失部分。 在这项研究中,深度学习三巨头之一、图灵奖获得者、Meta 首席科学家 Yann LeCun(杨立昆)及其团队,探索了如何将 JEPA 预测任务泛化到更广泛的破坏类型上,并提出了图像世界模型(IWM),这是一种超越遮蔽图像建模的方法,可以学习预测潜在空间中全局光度变换的影响。
他们研究了学习性能良好的图像世界模型的秘诀,并证明它依赖于三个关键方面:条件、预测难度和能力。该研究还证明,通过微调可以调整 IWM 学习到的预测性世界模型,从而解决不同的任务;微调后的 IWM 世界模型与之前的自监督方法性能相当,甚至更胜一筹。
最后,他们还展示了利用 IWM 学习可以控制所学表征的抽象程度,学习不变表征(如对比方法)或等变表征(如遮蔽图像建模)。
论文链接: https://arxiv.org/abs/2403.00504
**2.具身智能新突破:将现实世界中的仿人控制视为下一个 token 预测**
类似于语言中的下一个单词(word)预测,来自加州大学伯克利分校的研究团队将现实世界中的仿人控制视为下一个 token 预测问题。结果表明,该模型能让一个全尺寸的仿人机器人在旧金山自由行走。这些发现为通过传感器运动轨迹生成建模来学习具有挑战性的真实世界控制任务提供了一条前景广阔的道路。
论文链接: https://arxiv.org/abs/2402.19469
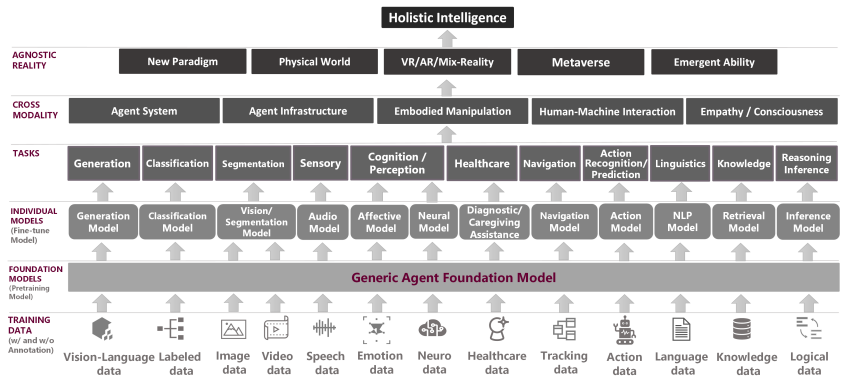
**3.微软新研究:迈向整体智能的 Agent AI**
来自微软的研究团队及其合作者强调开发 AI 智能体(Agent AI)------一种将大型基础模型整合到智能体行动中的具身系统。AI 智能体这一新兴领域横跨现有的各种体现式和基于智能体的多模态交互,包括机器人、游戏和医疗保健系统等。研究团队提出了一种新颖的大型行动模型------Agent Foundation Model 来实现具身智能行为。
论文链接: https://arxiv.org/abs/2403.00833
**4.Google DeepMind:让机器人学会动作语言**
来自 Google DeepMind 和斯坦福的研究团队提出教机器人学习动作语言,用更精细的短语来描述低级动作。作为任务和动作之间的中间步骤,预测这些语言动作迫使策略学习看似不同的任务中低级动作的共享结构。以语言动作为条件的策略可以很容易地在执行过程中通过人类指定的语言动作进行修正。这为灵活的策略提供了新的范例,使其能够从人类对语言的干预中学习。
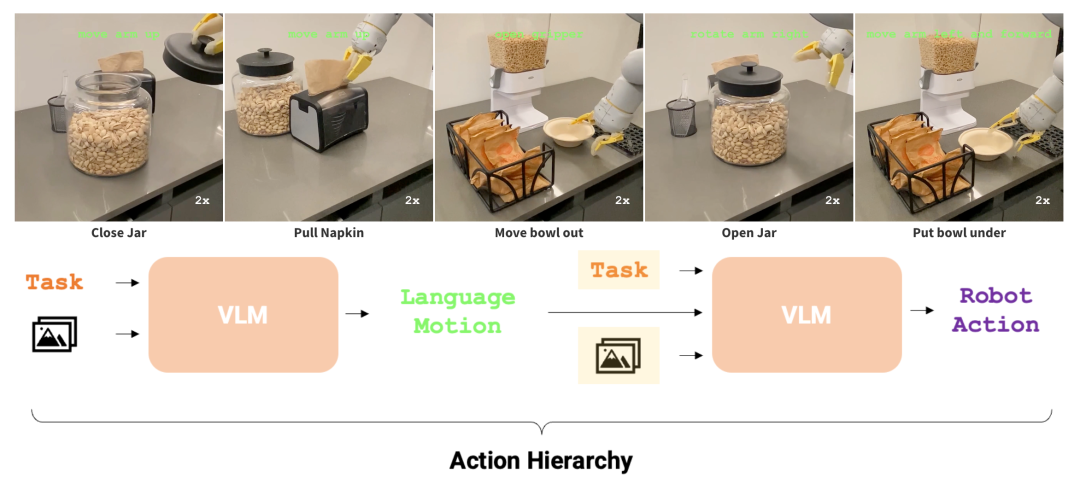
论文链接: https://arxiv.org/abs/2403.01823
**5.Meta、StabilityAI 新研究:用强化学习增强大模型推理**
来自Meta、佐治亚理工学院、StabilityAI 和加州大学伯克利分校的研究团队探索了多种从反馈中学习的算法,如Expert Iteration、Proximal Policy Optimization(PPO)、Return-Conditioned RL等在提高 LLM 推理能力方面的表现。研究发现:在 RL 训练过程中,模型无法在 SFT 模型已经产生的解决方案之外进行更多探索。该项研究讨论了这一发现对 RLHF 的影响以及 RL 未来在 LLM 微调中的作用。 论文链接: https://arxiv.org/abs/2403.04642
**6.华为文生图大模型:****仅0.6B**,** 生成4K分辨率图像**
来自华为诺亚方舟实验室、大连理工大学、香港大学和香港科技大学的研究团队提出了一个能够直接生成 4K 分辨率图像的 Diffusion Transformer(DiT)模型------PixArt-Σ,它与其前身 PixArt-α 相比有了长足的进步,图像的保真度明显提高,并能够更好地与文本提示保持一致。
PixArt-Σ 实现了卓越的图像质量和用户提示功能,同时模型大小(0.6B 参数)明显小于现有的文本到图像扩散模型,如 SDXL(2.6B 参数)和 SD Cascade(5.1B 参数)。此外,PixArt-Σ 能够生成 4K 图像,支持制作高分辨率海报和壁纸,可有效促进电影和游戏等行业高质量视觉内容的生产。
 
论文链接: https://arxiv.org/abs/2403.04692
**7.天大提出 SheetAgent:通过大模型进行电子表格推理和操作**
为了缩小与现实世界需求的差距,天津大学团队提出了一个具有长视距和多类别任务的基准------SheetRM,其推理操作依赖于现实生活中的挑战。为了减轻上述挑战,研究团队进一步提出了一个利用 LLM 功能的新型自主智能体------SheetAgent。
SheetAgent 由 Planner、Informer 和 Retriever三个协作模块组成,通过迭代任务推理和反思,SheetAgent 既能实现高级推理,又能准确操作电子表格,而无需人工交互。
论文链接: https://arxiv.org/abs/2403.03636
**8.Design2Code:我们离前端工程自动化还有多远?**
多模态大型语言模型(MLLMs)可以直接将可视化设计转换为代码实现,开创了前端开发的新模式。来自微软、Google DeepMind、斯坦福和佐治亚理工学院的研究团队将其形式化为一个 Design2Code 任务,并进行了全面的基准测试。
评估表明,在 49% 的情况下,标注者认为 GPT-4V 生成的网页可以在视觉外观和内容方面取代原始参考网页;而令人惊讶的是,在 64% 的情况下,GPT-4V 生成的网页被认为比原始参考网页更好。
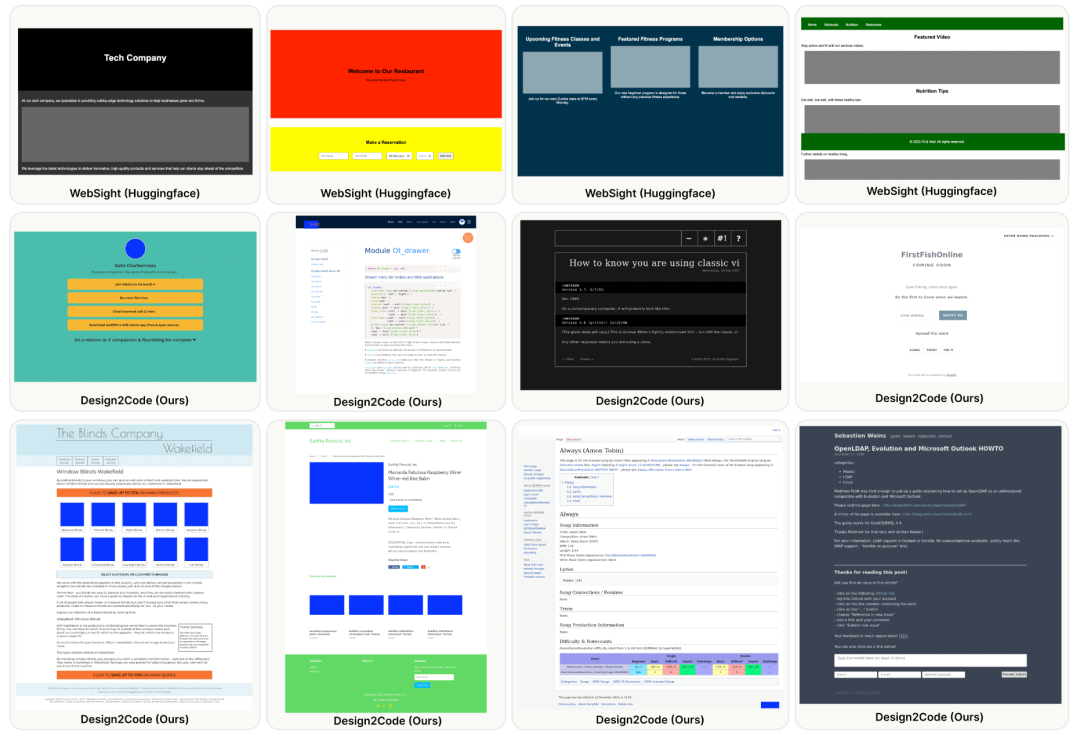
论文链接: https://arxiv.org/abs/2403.03163
**9.StableDrag:为基于点的图像编辑提供稳定的拖动功能**
来自南京大学和腾讯的研究团队建立了一个稳定而精确的基于拖动的编辑框架------StableDrag,它包含一个确定性点跟踪方法和一种基于置信度的运动监督潜在增强策略,前者允许我们精确定位更新的控制点,从而提高长距离操作的稳定性,而后者负责保证在所有操作步骤中优化后的潜在变量尽可能高质量。
论文链接: https://arxiv.org/abs/2403.04437
**10.MovieLLM:利用人工智能生成的电影增强对长视频的理解**
来自复旦大学和腾讯的研究团队提出了一个为长视频创建合成的高质量数据的新框架------MovieLLM。该框架利用 GPT-4 和文生图模型的强大功能,生成详细的脚本和相应的视觉效果。
MovieLLM 以其灵活性和可扩展性脱颖而出,成为传统数据收集方法的优越替代方案。实验证明,MovieLLM 生成的数据显著提高了多模态模型在理解复杂视频叙事方面的性能,克服了现有数据集在稀缺性和偏差方面的局限性。
论文链接: https://arxiv.org/abs/2403.01422
**11.AtomoVideo:高保真图像视频生成器**
阿里巴巴团队提出了一种高保真图像视频生成框架 AtomoVideo,它基于多粒度图像注入实现了生成的视频与给定图像的更高保真度。得益于高质量的数据集和训练策略,AtomoVideo 在保持出色的时间一致性和稳定性的同时,实现了更高的运动强度。这一架构可灵活扩展到视频帧预测任务,通过迭代生成实现长序列预测。
此外,由于采用了适配器训练的设计,AtomoVideo 可以很好地与现有的个性化模型和可控模块相结合。
论文链接: https://arxiv.org/abs/2403.01800
**12.ChatDiet:个性化食品推荐 AI 聊天机器人**
加州大学尔湾分校研究团队提出了一个由 LLM 驱动的新型框架------ChatDiet,它专为个性化营养导向食物推荐聊天机器人而设计。ChatDiet 整合了个人和群体模型,并辅以一个协调器( orchestrator)来可无缝检索和处理相关信息。能够根据个人用户的偏好动态提供个性化和可解释的食物推荐。
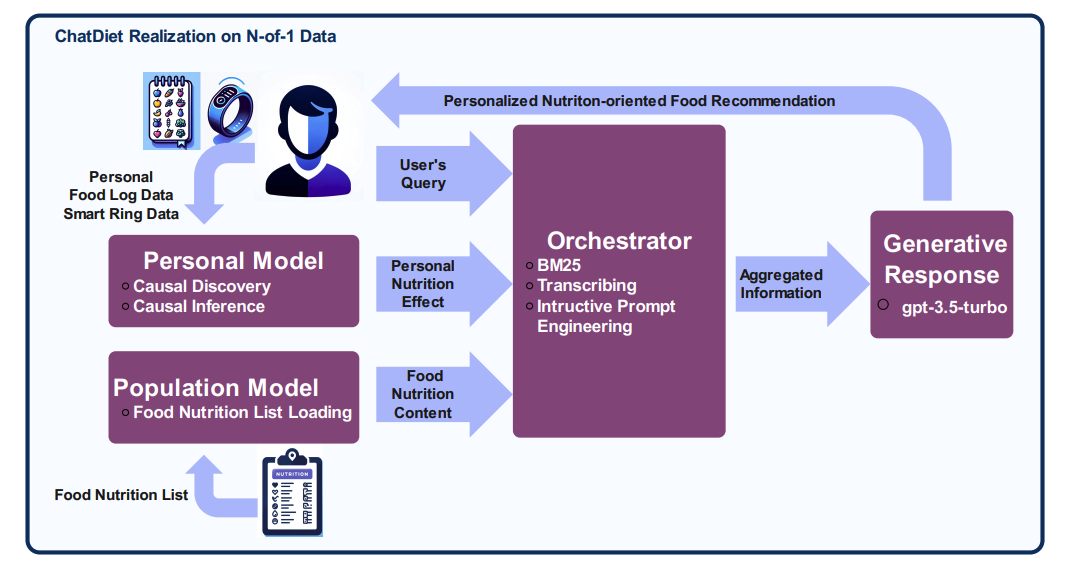
论文链接: https://arxiv.org/abs/2403.00781
**13.EyeGPT:大模型驱动的眼科助手**
来自香港理工大学、Centre for Eye and Vision Research (CEVR)、中山大学、上海交通大学和眼科临床医学中心的研究团队提出了专为眼科设计的专业 LLM------EyeGPT,它采用了角色扮演、微调和检索增强生成三种优化策略。通过评估不同 EyeGPT 变体的性能确定了最有效的变体,它在可理解性、可信度和移情能力方面与人类眼科医生的水平相当(all Ps\>0.05)。
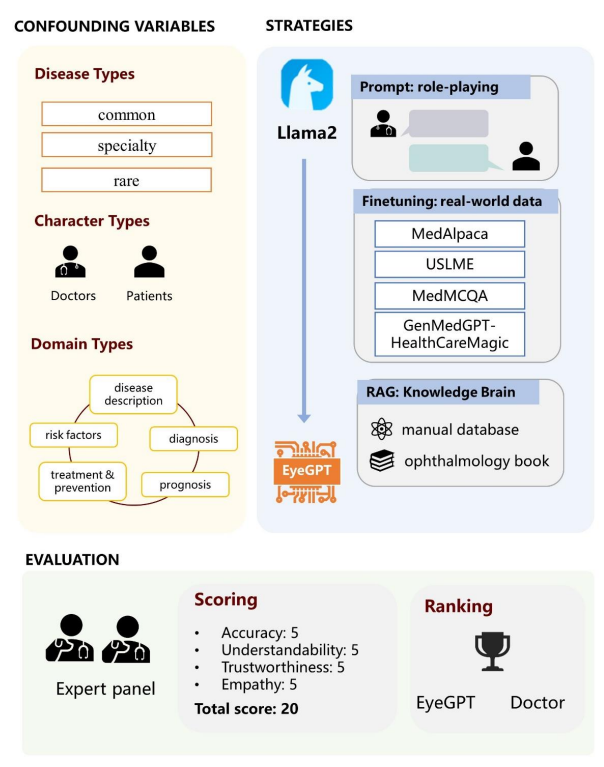 图:研究概述。
论文链接: https://arxiv.org/abs/2403.00840
**14.在神经科学领域,大模型超越了人类专家**
来自伦敦大学学院的研究团队及其合作者创建了一个预测神经科学结果的前瞻性基准------BrainBench。研究发现,LLMs 在预测实验结果方面超过了专家。BrainGPT 是根据神经科学文献调整的 LLM,它的表现更好。与人类专家一样,当 LLMs 对自己的预测充满信心时,他们更有可能预测正确。该项研究并不局限于神经科学,也可以应用于其他知识密集型领域。
论文链接: https://arxiv.org/abs/2403.03230
**15.7B语言模型,已具备强大的数学能力**
此前人们认为,普通语言模型只有在规模非常大或需要大量数学相关预训练的情况下才会展现出数学能力。来自微软亚洲研究院、西安交通大学、中国科学技术大学和清华大学的研究团队发现,采用普通预训练的 LLaMA-2 7B 模型已经表现出很强的数学能力。只需扩大 SFT 数据的规模,就能显著提高生成正确答案的可靠性。
这种直接的方法在 LLaMA-2 7B 模型在 GSM8K 和 MATH 上分别达到了 82.6% 和 40.6% 的准确率,比以前的模型分别高出 14.2% 和 20.8%。
论文链接: https://arxiv.org/abs/2403.04706
**|点击关注我 ? 记得标星|**