OpenAI最近推出了Sora, 这是一个开创性的文本到视频模型, 代表了视频生成技术的一个重大飞跃。Sora能够将简短的文本描述转换成详细的、高清的视频片段, 这些片段最长可达一分钟。所提出的Sora推进了AI技术, 并在视频制作中提供了新的创造潜能。
**这个框架, 它由以下组成部分组成。** 1. **Video VQ-VAE**. 2. **Denoising Diffusion Transformer**. 3. **Condition Encoder**. 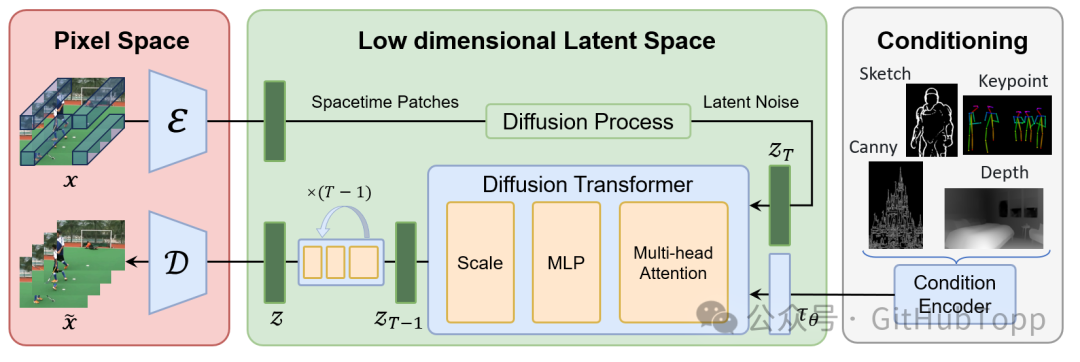 *框架图*
实现细节 ---- ### (1)可变长宽比 我们参考FIT实施了一种动态掩码策略, 以并行批量训练的同时保持灵活的长宽比。具体来说, 我们将高分辨率视频在保持长宽比的同时下采样至最长边为256像素, 然后在右侧和底部用零填充至一致的256x256分辨率。这样便于videovae以批量编码视频, 以及便于扩散模型使用注意力掩码对批量潜变量进行去噪。 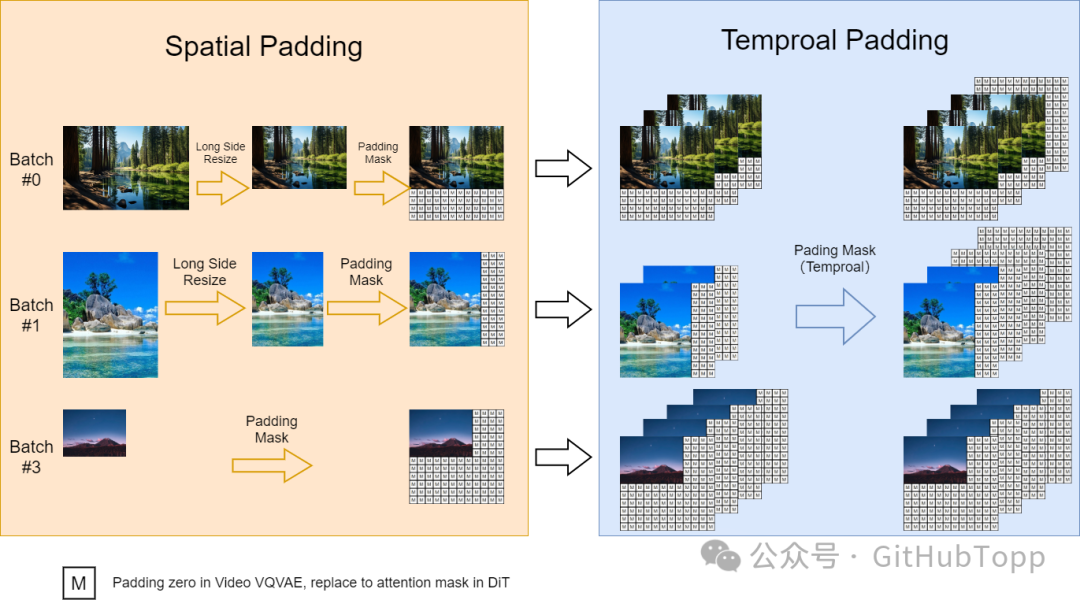 *动态训练策略* ### (2) 可变分辨率 在推理过程中, 尽管我们在固定的256x256分辨率上进行训练, 但我们使用位置插值可以实现可变分辨率采样。我们将可变分辨率噪声潜变量的位置索引从\[0, seq_length-1\]下调到\[0, 255\],以使其与预训练范围对齐。这种调整使得基于注意力的扩散模型能够处理更高分辨率的序列。 ### (3) 可变时长 我们使用VideoGPT中的Video VQ-VAE, 将视频压缩至潜在空间, 并且支持变时长生成。同时, 我们扩展空间位置插值至时空维度, 实现对变时长视频的处理。
10s视频重建(256x)
18s视频重建(196x)
团队 --- * 林彬: 北京大学 * 袁盛海: 北京大学 * 唐振宇: 北京大学 * 张俊武: 北京大学 * 程鑫华: 北京大学 * 陈柳汉: 北京大学 * 叶阳: 北京大学 * 朱斌: 北京大学 * 葛云阳: 北京大学 * 周星: 兔展AI * 董少灵: 兔展AI * 史业民: 兔展AI顾问 * 田永鸿: 北京大学 * 袁粒: 北京大学
**文本到视频模型的技术难点**主要包括以下两个方面: 1. 捕捉文本和图像之间的复杂关系:文本描述的内容可能包括物体、场景、动作和情感等多种信息,而图像则可能呈现出多种不同的形态和特征。因此,如何有效地捕捉和理解文本与图像之间的复杂关系,是实现文本到视频转换的关键。 2. 生成高质量的图像和视频:文本到视频转换的另一个技术难点是如何生成高质量的图像和视频。这需要处理大量的数据,并进行复杂的计算,同时还需要对图像的细节、光照和颜色等方面进行精确控制,以便能够生成逼真的图像和视频。 为了解决这些技术难点,研究人员通常需要使用深度学习技术,如卷积神经网络(CNN)和循环神经网络(RNN)等,来捕捉文本和图像之间的复杂关系,并生成高质量的图像和视频。同时,还需要使用大量的训练数据来训练模型,以便让模型能够更好地理解文本和图像之间的关系,并生成更加逼真的图像和视频。 虽然文本到视频模型的技术难点较多,但随着深度学习技术的不断发展和优化,相信未来会有更多的突破和创新,使得文本到视频转换变得更加容易和高效。
**文本到视频模型的技术路径**主要包括以下几种:
1. 基于生成对抗网络(GAN)的方法:GAN 是一种生成式模型,通过训练两个神经网络(生成器和判别器)来进行数据生成和判别。在文本到视频转换中,可以使用 GAN 来生成与文本描述相符的视频。具体来说,生成器根据文本描述生成视频,而判别器则用于判断生成的视频是否真实。通过不断训练和优化,生成器可以生成更加逼真的视频。 2. 基于编码器-解码器的方法:编码器-解码器是一种常用的序列到序列模型,可以用于文本到视频的转换。在编码器中,将文本描述转换为特征向量,然后在解码器中,将这些特征向量转换为视频帧。这种方法通常需要大量的训练数据,并且需要对模型进行精细的调整,以便生成高质量的视频。 3. 基于时空扩散U-Net的方法:时空扩散U-Net 是一种时空卷积神经网络,可以同时处理时间和空间维度上的信息。在文本到视频转换中,可以使用时空扩散U-Net 来生成与文本描述相符的视频。该方法可以在单次推理中生成整个视频的所有时间段,从而增强生成视频的动作连贯性和时间一致性。 4. 基于多模态的方法:多模态方法是指利用多种模态的数据(如文本、图像、音频等)来进行视频生成。在文本到视频转换中,可以使用多模态方法来结合文本描述和其他模态的数据(如静态图像或音频),以生成更加丰富的视频内容。 需要注意的是,以上技术路径并不是相互独立的,而是可以相互结合和融合,以实现更加高效和准确的文本到视频转换。同时,随着技术的不断发展和优化,相信未来会有更多的技术路径涌现,推动文本到视频转换技术的不断发展和进步。
**普通IT工程师关注最前沿的人工智能技术有多个原因:** 1. 职业发展:随着人工智能技术的广泛应用,掌握这些技术可以为IT工程师的职业发展带来巨大的优势。无论是在求职、晋升还是转岗等方面,具备人工智能技能的人才通常更受欢迎。了解前沿技术有助于工程师在职业生涯中保持竞争力。 2. 提高效率:人工智能技术可以帮助工程师自动化处理大量数据和复杂任务,从而提高工作效率。例如,利用机器学习算法进行自动化测试、使用自然语言处理技术进行智能问答等,都可以帮助工程师更快速地完成任务。 3. 创新和竞争力:人工智能技术是创新的重要源泉。掌握这些技术可以帮助工程师和企业保持竞争力,开发出更具创新性的产品和服务。同时,了解前沿技术也有助于工程师在创新过程中保持敏锐的洞察力。 4. 拓展业务领域:人工智能技术可以应用于多个领域,如金融、医疗、教育等。了解前沿技术有助于工程师拓展业务领域,为企业创造更多的商业价值。 5. 个人兴趣和好奇心:对于一些对科技和创新充满热情的IT工程师来说,关注最前沿的人工智能技术也是一种享受。通过学习和实践,他们可以更好地理解这个领域的最新动态和发展趋势,满足自己的好奇心和求知欲。 总之,关注最前沿的人工智能技术对普通IT工程师来说是非常有益的。这不仅可以为他们的职业发展带来优势,还可以帮助他们提高工作效率、保持竞争力、拓展业务领域,并满足个人兴趣和好奇心。