Preface {#preface}
本文中使用的 JDK 版本是JDK 11.0.2。
Java 异常体系 {#java-异常体系}
Java 在设计之初就提供了相对完善的异常处理机制,大大降低了编写和维护可靠程序的门槛。
异常处理机制主要回答了三个问题
- What:异常类型回答了什么被抛出;
- Where:异常堆栈跟踪回答了在哪抛出;
- Why:异常信息回答了为什么被抛出。
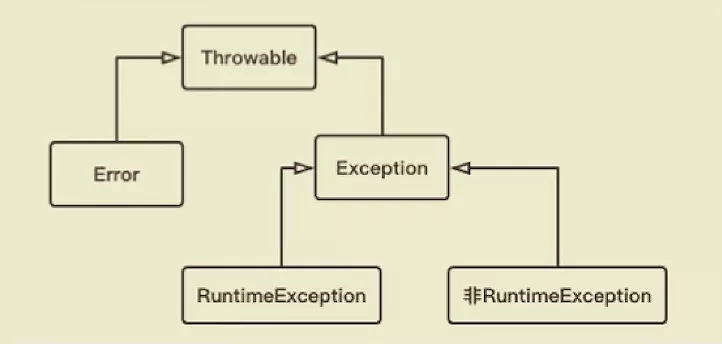
从概念角度解析 Java 的异常处理机制
-
Error:程序无法处理的系统错误,编译器不做检查;
一般指与 JVM 相关的问题,如:系统崩溃、虚拟机错误、内存空间不足、方法调用栈溢出等。
这类错误导致的应用程序中断仅靠程序本身无法恢复和预防。 -
Exception:程序可以处理的异常,捕获后可能恢复运行。
应该尽可能的去处理,使程序恢复运行,不能随意终止异常。
-
总结:前者是程序无法处理的错误,后者是可以处理的异常。
异常体系
RuntimeException:不可预知的,程序应当自行避免,如:NullPointException;- 非
RuntimeException:可预知的,从编译器校验的异常,如:IOException。
从责任角度看:
Error属于 JVM 需要负担的责任;RuntimeException是程序应该负担的责任;CheckedException可检查异常是 Java 编译器应该负担的责任。
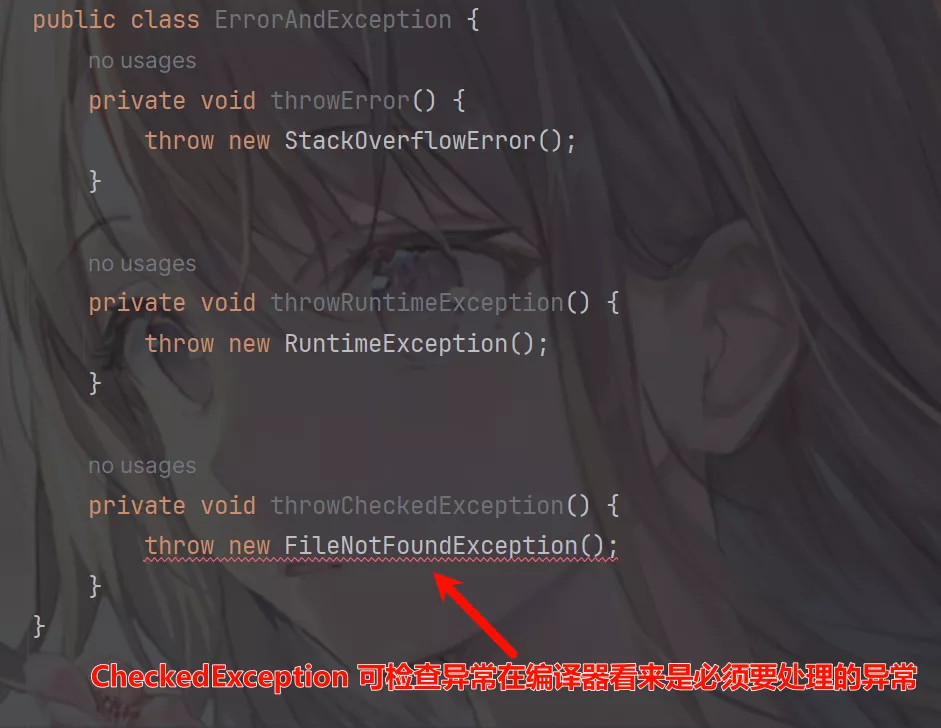
public class ErrorAndException {
private void throwError() {
throw new StackOverflowError();
}
private void throwRuntimeException() {
throw new RuntimeException();
}
private void throwCheckedException() throws FileNotFoundException {
// 根据实际业务逻辑使用 try catch 处理异常或向上抛出异常
throw new FileNotFoundException();
}
public static void main(String[] args) throws FileNotFoundException {
ErrorAndException eae = new ErrorAndException();
// 一旦异常被抛出,后面的代码就不会再被执行了,从输出结果看只抛出了 StackOverflowError 后就停止运行了
eae.throwError();
eae.throwRuntimeException();
eae.throwCheckedException();
}
/*
输出:
Exception in thread "main" java.lang.StackOverflowError
at cool.ldw.javabasic.throwable.ErrorAndException.throwError(ErrorAndException.java:7)
at cool.ldw.javabasic.throwable.ErrorAndException.main(ErrorAndException.java:22)
*/
}
常见的 RuntimeException:
NullPointerException:空指针引用异常;ClassCastException:类型强制转换异常;IllegalArgumentException:传递非法参数异常;IndexOutOfBoundsException:下标越界异常;NumberFormatException:数字格式异常;
常见的非 RuntimeException:
ClassNotFoundException:找不到指定class的异常;IOException:IO操作异常。
常见的 Error:
-
NoClassDefFoundError:找不到class定义的异常的;成因:
- 类依赖 class 或者 jar 不存在;
- 类文件存在,但是存在不同的域中;
- 大小写问题,
javac编译的时候是无视大小写的,很有可能编译出来的 class 文件就与想要的不一样。
-
StackOverflowError:深递归导致栈被耗尽而抛出的异常; -
OutOfMemoryError:内存溢出异常。
Java 异常处理机制 {#java-异常处理机制}
处理步骤大致如下:
-
抛出异常:创建异常对象,交由运行时系统处理;
当一个方法运行错误引异常时,会创建异常对象并交由运行时系统,异常对象包含了异常类型和异常出时的程序状态等信息。运行时系统负责寻找出现异常的代码并处理。
-
捕获异常:寻找合适的异常处理器处理异常,否则终止运行。
在方法抛出异常后运行时系统将转为寻找合适的异常处理器处理异常,潜在的异常处理器是异常发生时依次存留在 调用栈 中方法的集合。
当异常处理器所能处理的异常类型与抛出的异常类型相符时即为合适的异常处理器。
运行时系统从发生异常的方法开始依次回查 调用栈 中的方法,直至找到含有异常处理器的方法并执行。
当运行时系统遍历了调用栈都没找到合适的异常处理器,则运行时系统终止,Java 程序终止。
举个例子:
public class ExceptionHandleMechanism {
public static int doWork() {
try {
int i = 10 / 0; // 会抛出异常
System.out.println("i = " + i);
} catch (ArithmeticException e) { // 捕获异常
// 捕获 ArithmeticException
System.out.println("ArithmeticException: " + e);
return 0;
} catch (Exception e) { // 捕获异常
// 捕获 Exception
System.out.println("Exception: " + e);
return 1;
} finally {
System.out.println("Finally");
return 2;
}
}
public static void main(String[] args) {
System.out.println("执行后的值为:" + doWork());
System.out.println("Mission Complete");
}
/* 输出:
ArithmeticException: java.lang.ArithmeticException: / by zero
Finally
执行后的值为:2
Mission Complete
*/
}
异常发生后,运行时系统负责寻找合适的异常处理器来处理,这里便找到了专门处理算术类异常ArithmeticException的catch代码块;并且从输出结果看finally中的代码先于return执行。
最多只会匹配一个catch块,并且是按照顺序进行匹配的。
异常的处理原则:
- 具体明确:抛出的异常应能通过异常类名和 message 准确说明异常的类型和产生异常的原因;
- 提早抛出:应尽可能早的发现并抛出异常,便于精确定位问题;
- 延迟捕获:异常的捕获和处理应尽可能延迟,让掌握更多信息的作用域来处理异常。
高效主流的异常处理框架
在用户看来,应用系统发生的所有异常都是应用系统内部的异常。
- 设计一个通用的继承自
RuntimeException的异常来统一处理; - 其余异常都统一转译为上述异常
AppException; - 在catch之后,抛出上述异常的子类,并提供足以定位的信息;
- 由前端接收
AppException做统一处理。
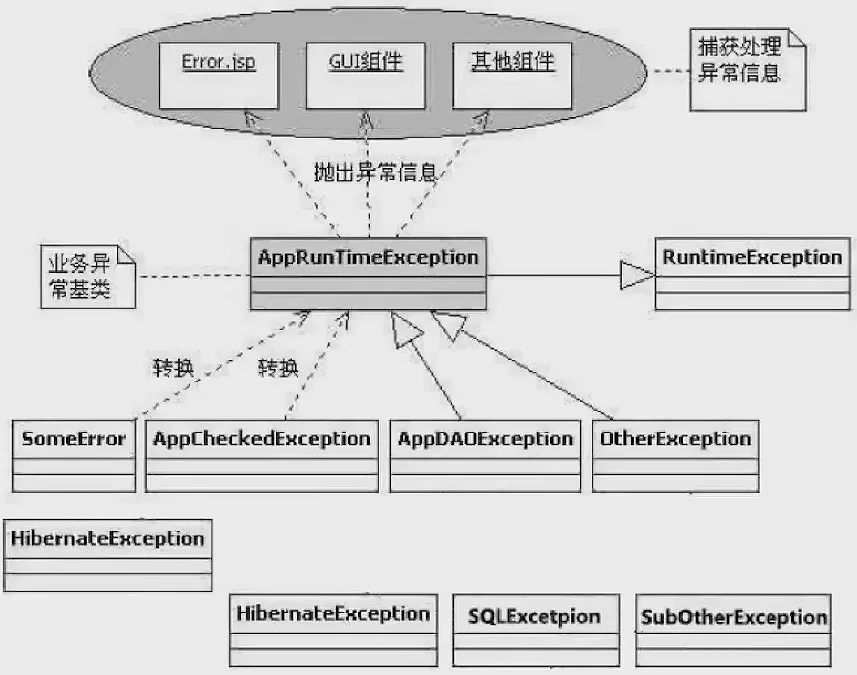
Java异常处理消耗性能的地方
try-catch块影响 JVM 的优化;- 异常对象实例需要保存栈快照等信息,开销较大。
举个例子:
public class ExceptionPerformance {
public static void testException(String[] array) {
try {
System.out.println(array[0]);
} catch (NullPointerException e) {
System.out.println("array cannot be null");
}
}
public static void testIf(String[] array) {
if (array != null){
System.out.println(array[0]);
} else {
System.out.println("array cannot be null");
}
}
public static void main(String[] args) {
// 纳秒
long start = System.nanoTime();
// testException(null);
testIf(null);
System.out.println("cost " + (System.nanoTime() - start));
}
/* testException(null) 输出:
array cannot be null
cost 270600
*/
/* testIf(null) 输出:
array cannot be null
cost 205900
*/
}
Java 集合框架 {#java-集合框架}
工作中消失而面试却长存的算法与数据结构是因为优秀的算法和数据结构被封装到了 Java 的集合框架之中。
数据结构考点:
- 数组和链表的区别;
- 链表的操作,如反转,链表环路检测,双向链表,循环链表相关操作;
- 队列,栈的应用;
- 二叉树的遍历方式及其递归和非递归的实现;
- 红黑树的旋转。
算法考点:
- 内部排序:如递归排序、交换排序(冒泡、快排)、选择排序、插入排序;
- 外部排序:应掌握如何利用有限的内存配合海量的外部存储来处理超大的数据集,写不出来也要有相关的思路。
考点扩展:
- 哪些排序是不稳定的,稳定意味着什么?
- 不同数据集,各种排序最好或最差的情况?
- 如何优化算法?
以上是数据结构和算法考点的简单梳理,我们还是回过头来重点关注 Java 集合本身。
集合作为容器可以存储多个元素,由于数据结构的不同 Java 提供了多种集合类,将集合类中的共性功能不断向上抽取,最终形成了集合体系结构。
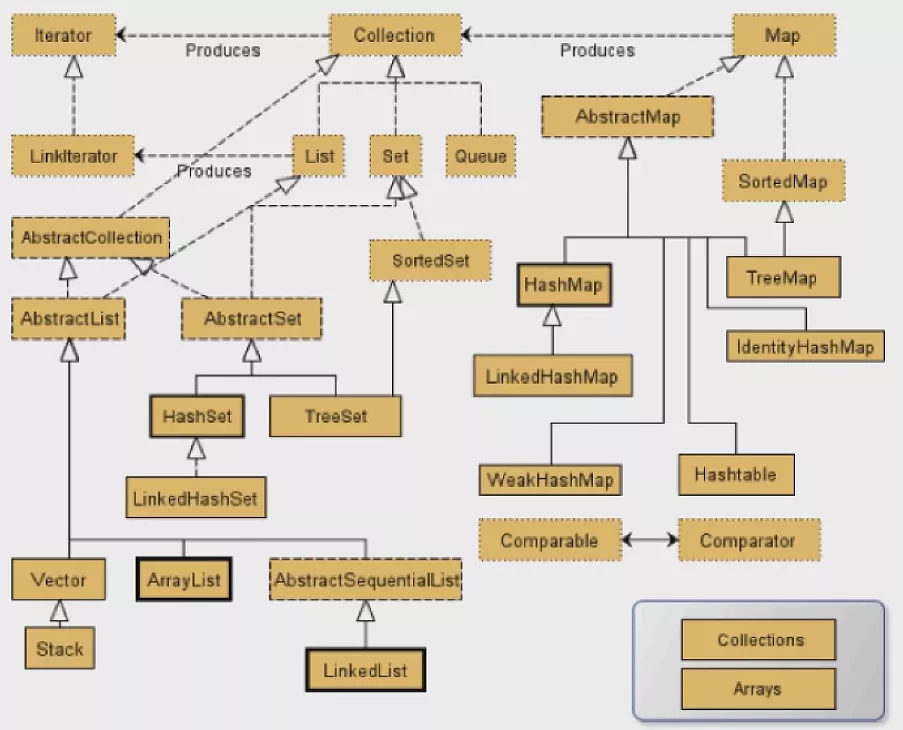
List 和 Set 的区别:

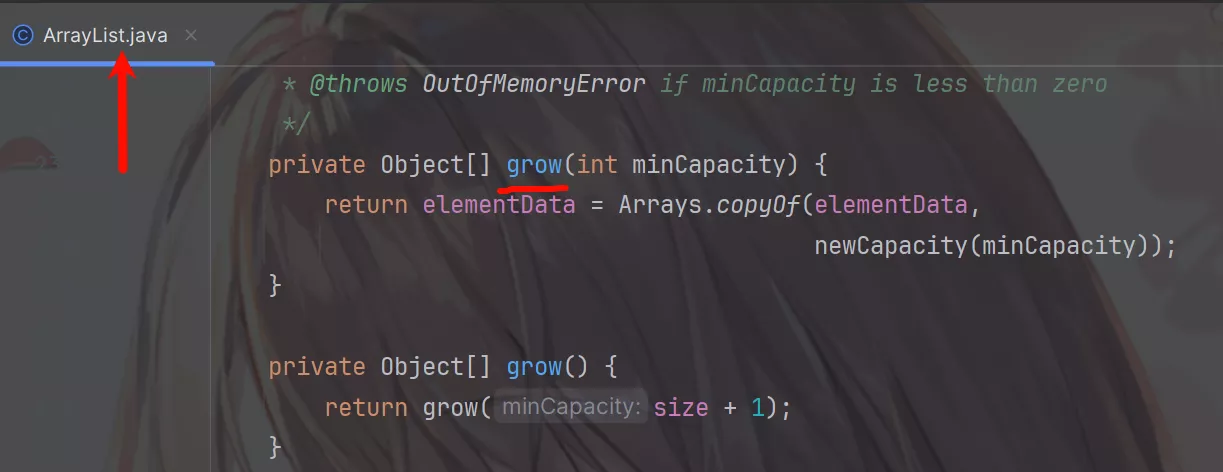
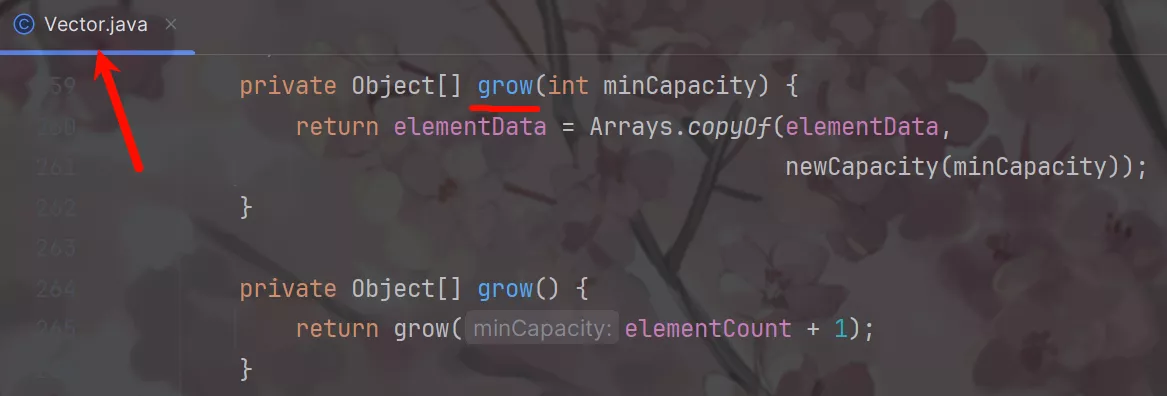
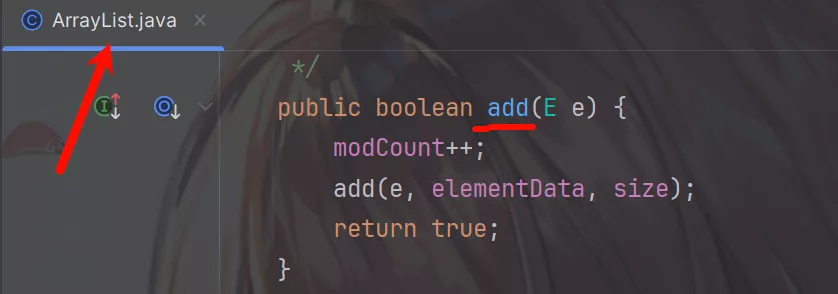
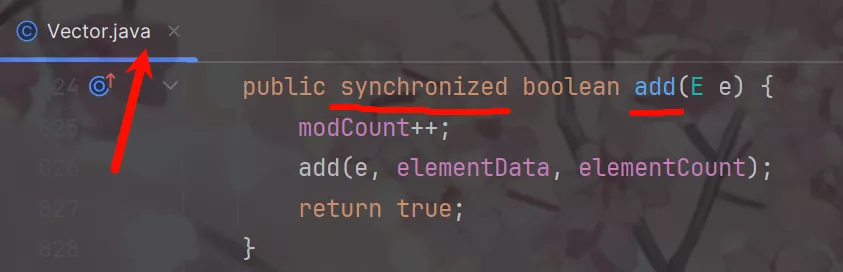
来看看List实现类ArrayList、Vector、LinkedList的源码。
ArrayList和Vector是由数组来实现的。


它们通过grow()方法实现动态扩容,就是创建一个新的容量更大的数组并将原来的数据复制到新创建的数组中,最后覆盖原先的数组。
ArrayList是线程不安全的,其方法既没有用到锁也没有用到CAS相关技术;
而Vector对外提供的public方法几乎都加上了锁,所以它是线程安全的由于加上了synchronized关键字,这些方法只能串行执行,不适用高并发和对性能要求的高的场景;但是它保证了性能安全又不适用于高并发场景现如今Vector已经很少使用了。
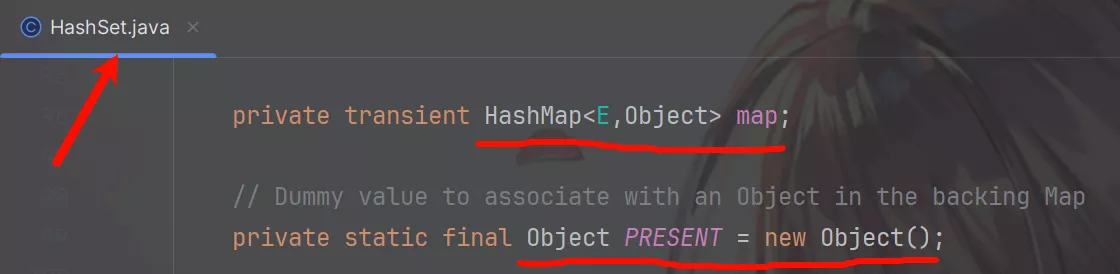
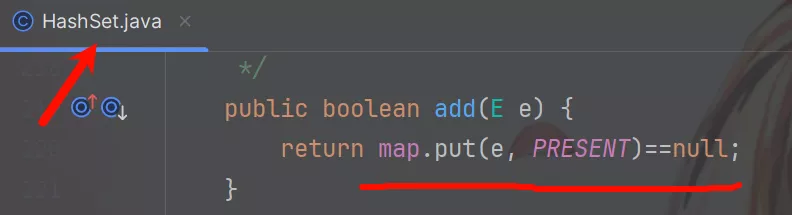
看完List再来看看Set的实现类HashSet和TreeSet。
HashSet底层由HashMap实现;调用add()方法时将参数作为map的键存储从而实现去重保证元素的唯一性。
TreehSet核心是排序 。底层由NavigableMap实现,调用add()方法时也是将参数作为map的键存储保证元素的唯一性。
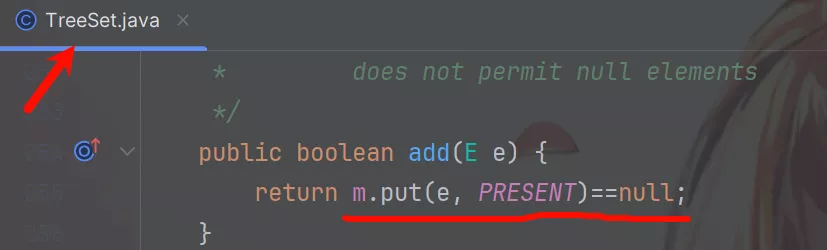
而NavigableMap是一个接口,实际使用的是其实现类TreeMap。
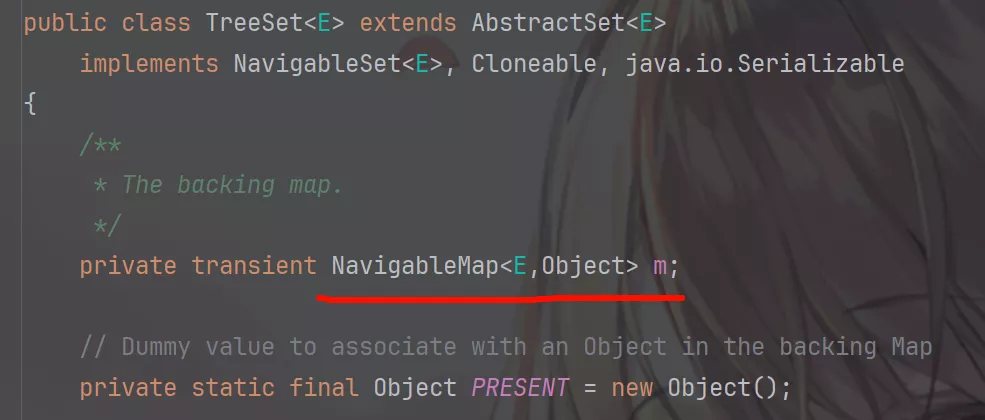
TreeMap通过getEntry()方法排序元素并返回Entry对象。
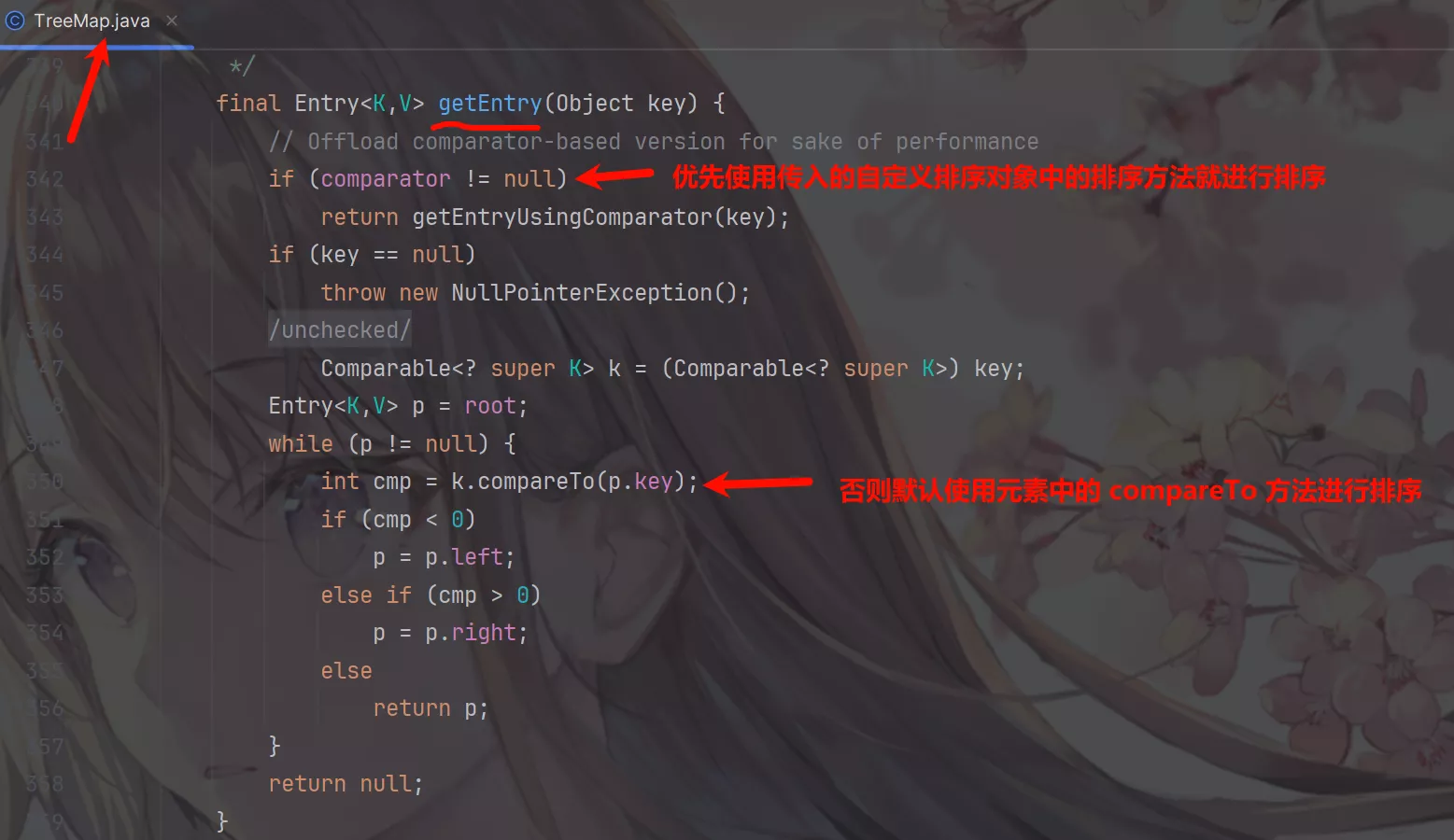
来看一个使用默认排序的例子:
Customer实现了Comparable接口并重写了compareTo()方法,还必须重写equals()和hashCode()方法。
为了保证正确的排序需要compareTo()和equals()方法按照相同的规则判断两个对象是否相同。即调用equals()方法返回true时,compareTo()方法也要返回 0。
public class Customer implements Comparable{
private String name;
private int age;
public Customer(String name, int age) {
this.age = age;
this.name = name;
}
public int getAge() {
return age;
}
public String getName() {
return name;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (!(obj instanceof Customer))
return false;
final Customer other = (Customer) obj;
if (this.name.equals(other.getName()) && this.age == other.getAge())
return true;
else
return false;
}
@Override
public int compareTo(Object o) {
Customer other = (Customer) o;
// 先按照name属性排序
if (this.name.compareTo(other.getName()) > 0)
return 1;
if (this.name.compareTo(other.getName()) < 0)
return -1;
// 在按照age属性排序
if (this.age > other.getAge())
return 1;
if (this.age < other.getAge())
return -1;
return 0;
}
@Override
public int hashCode() {
int result;
result = (name == null ? 0 : name.hashCode());
result = 29 * result + age;
return result;
}
public static void main(String[] args) {
Set<Customer> set = new TreeSet<>();
Customer customer1 = new Customer("Tom", 16);
Customer customer2 = new Customer("Tom", 15);
set.add(customer1);
set.add(customer2);
for(Customer c : set){
System.out.println(c.name + " " + c.age);
}
}
/* 输出:
Tom 15
Tom 16
*/
}
再看使用自定义排序的例子:
public class CustomerComparator implements Comparator<Customer> {
/**
* 只针对 name 进行排序
*/
@Override
public int compare(Customer c1, Customer c2) {
if (c1.getName().compareTo(c2.getName()) > 0) return -1;
if (c1.getName().compareTo(c2.getName()) < 0) return 1;
return 0;
}
public static void main(String args[]) {
Set<Customer> set = new TreeSet<Customer>(new CustomerComparator());
Customer customer1 = new Customer("Tom", 5);
Customer customer2 = new Customer("Tom", 9);
Customer customer3 = new Customer("Tom", 2);
set.add(customer1);
set.add(customer2);
set.add(customer3);
Iterator<Customer> it = set.iterator();
while (it.hasNext()) {
Customer customer = it.next();
System.out.println(customer.getName() + " " + customer.getAge());
}
}
/* 输出:
Tom 5
*/
}
由于传入的元素中name属性都相同都为Tom,调用compare方法返回的都是 0,表示是相同的,而TreeSet又不支持存储重复的值,因此最后输出TreeSet中只包含一个元素。
HashMap {#hashmap}
HashMap是Map的实现类用来保存具有映射关系的实现类,key使用Set实现不可重复,value使用Collection实现可重复。
HashTable扩展自Dictionary,结构上与HashMap明显不同;HashMap是Map的正统,对顺序没有要求的场景下HashMap就是最好的选择。
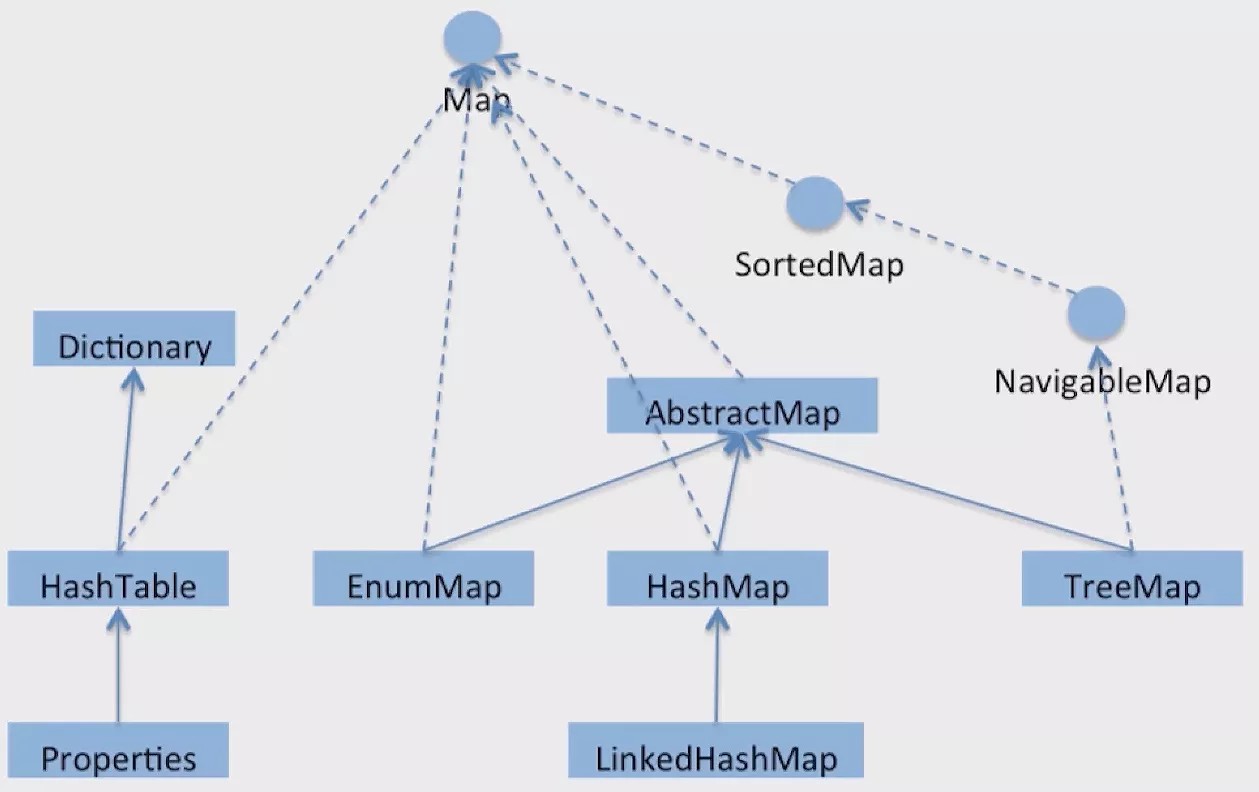
HashMap在 Java 8 以前使用数组 + 链表 的方式实现,结合了数组查询速度快和链表的增删快的特点;且HashMap的操作是非synchrinized的,所以它的效率也很高。
在没有赋初始值时其数组长度默认为 16,每个数组元素存储的都是链表的头节点,用取模
hash(key.hashCode())%len的操作(实际源码中是位运算效率更高)计算新添加的元素所要存放的数组位置。
在极端情况下,新添加的值通过哈希散列运算(即上面的位运算)总是得到同一个值,这会导致某个数组元素后面的链表会很长,查询的性能会恶化成O(n)。
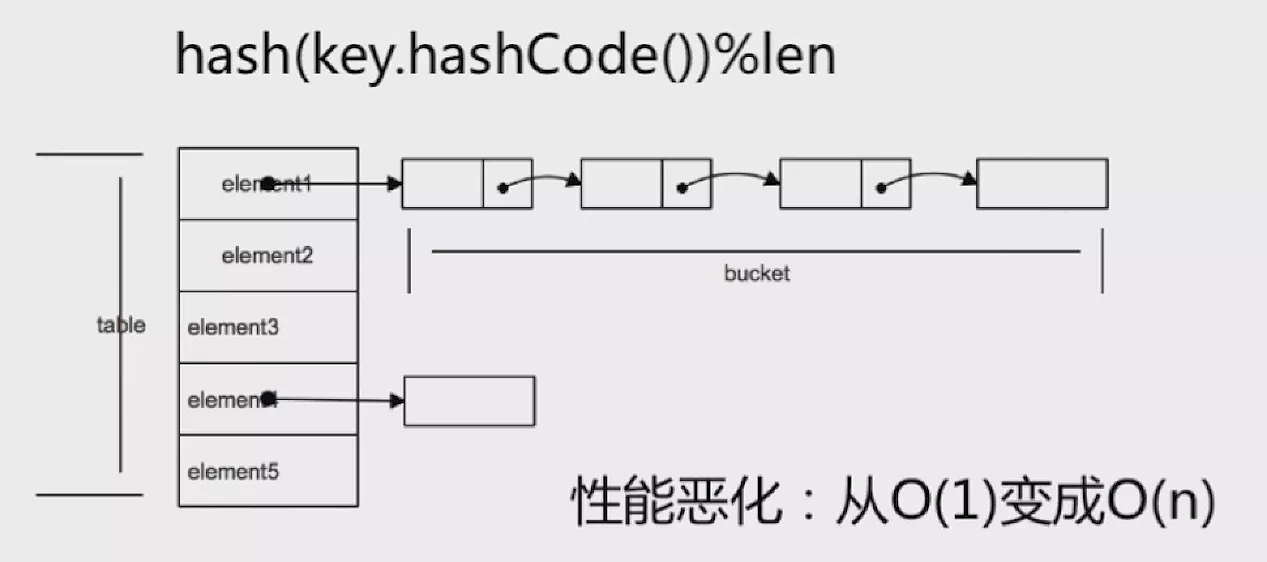
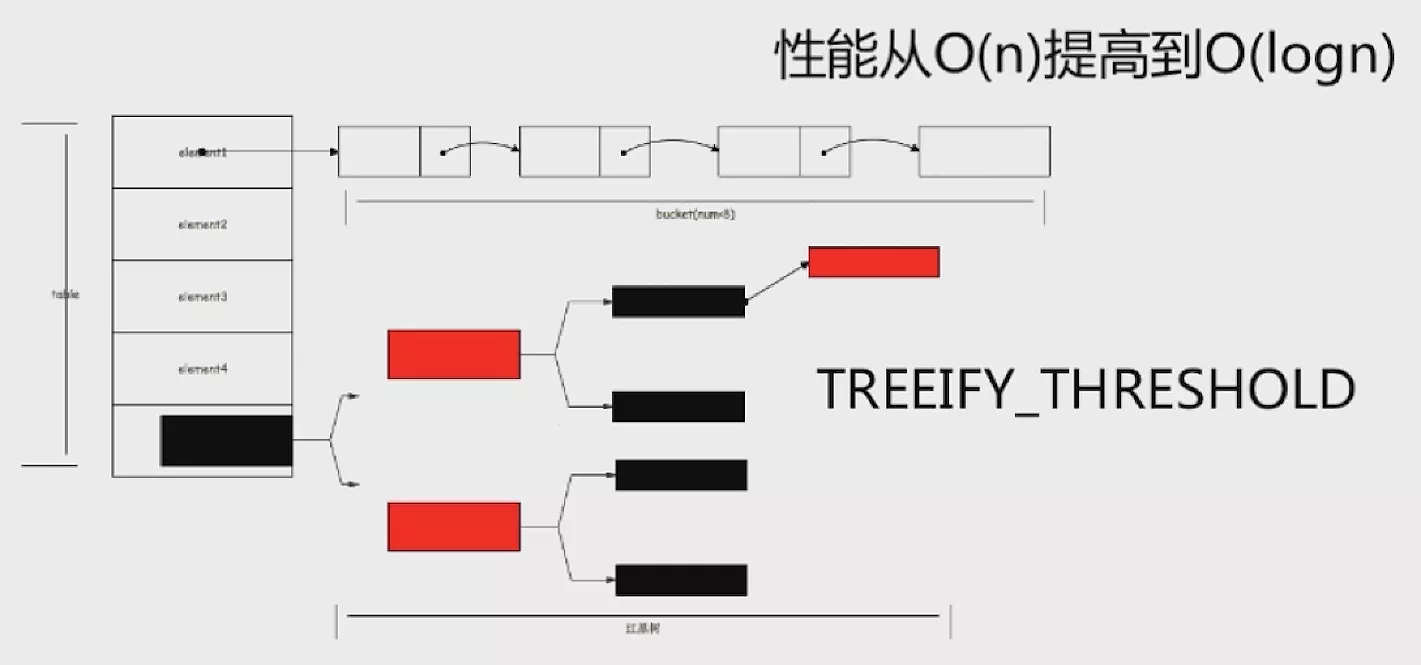
为了优化极端情况下的性能恶化,在 Java 8 及之后的版本中,HashMap改为了使用数组 + 链表 + 红黑树 的方式实现。使用常量TREEIFY_THRESHOLD判断链表是否需要转换为红黑树,将极端情况下的性能优化成了O(logn)。
接下来就从源码部分来分析HashMap:
HashMap是由Node<K, V>[]组成的符合结构。
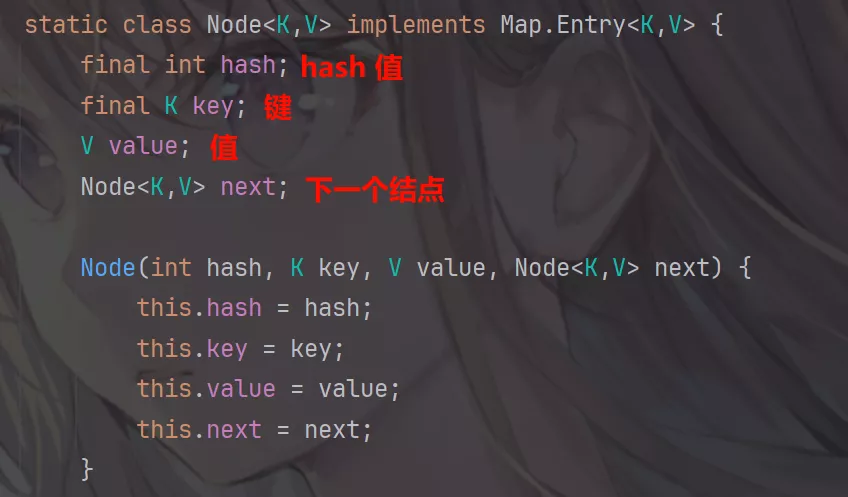
数组table被分为一个个bucket(桶),通过哈希值计算元素在桶中的位置,哈希值相同的键值对用链表存储;如果链表的长度超过TREEIFY_THRESHOLD的值(默认为 8)就换转化为红黑树,如果长度低于UNTREEIFY_THRESHOLD的值又会将红黑树转换为链表以保证更高的性能。

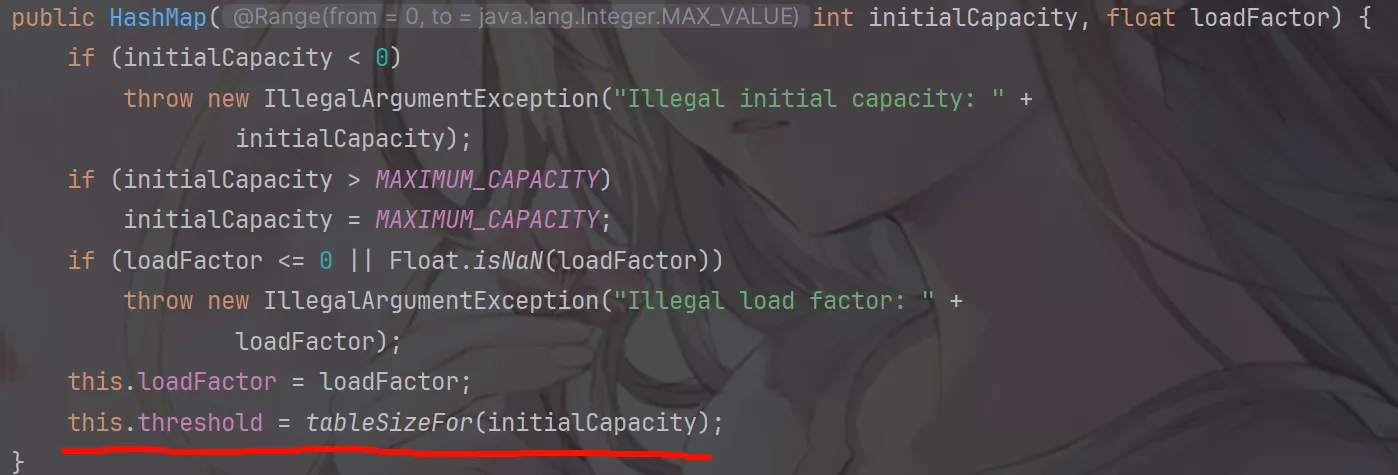
在HashMap初始化的时候,即构造函数中并没有初始化table数组,仅仅是将相关的成员变量赋予了值。
按照LazyLoad原则,在首次使用时才初始化table数组。
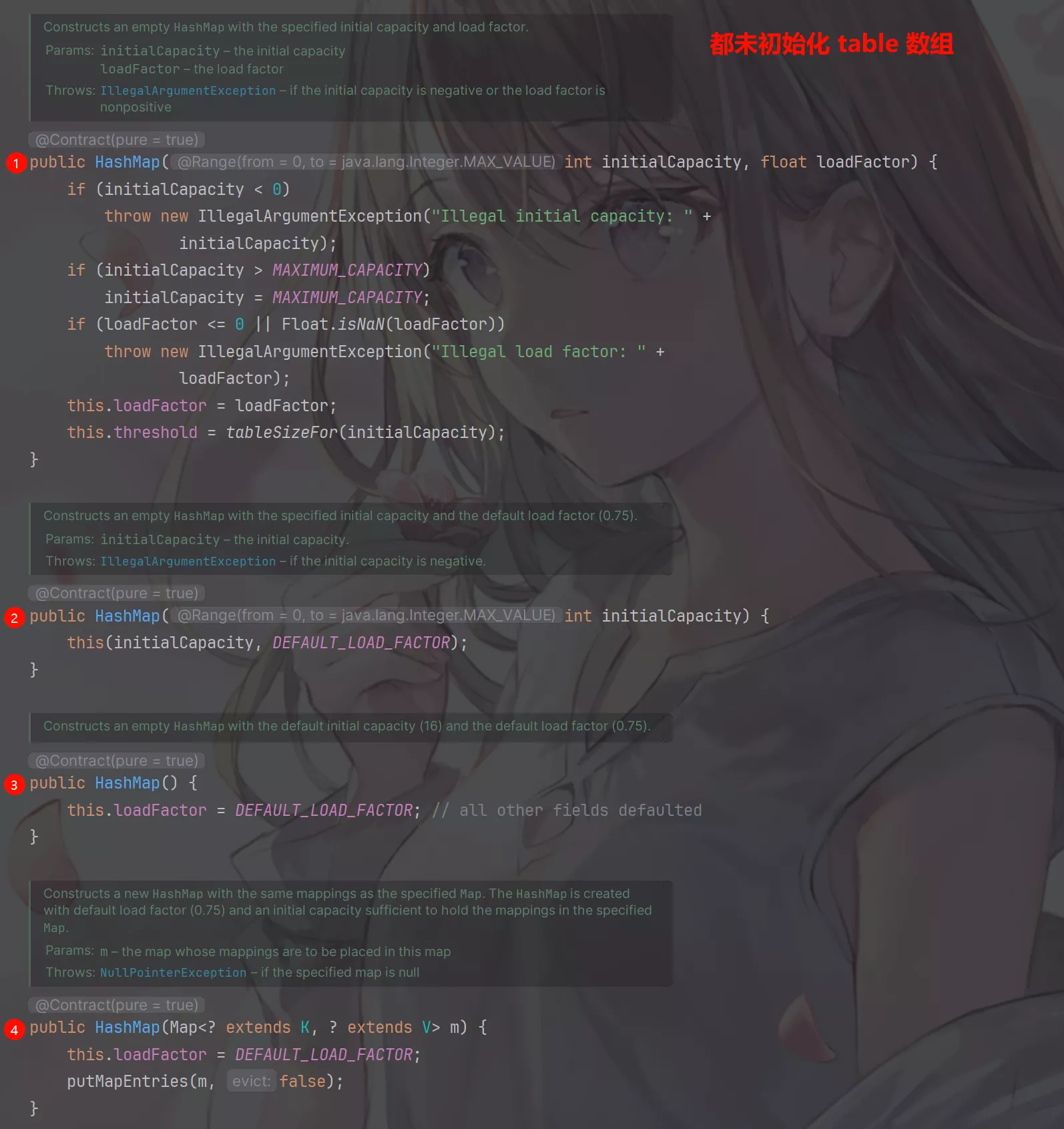
put()方法实现。

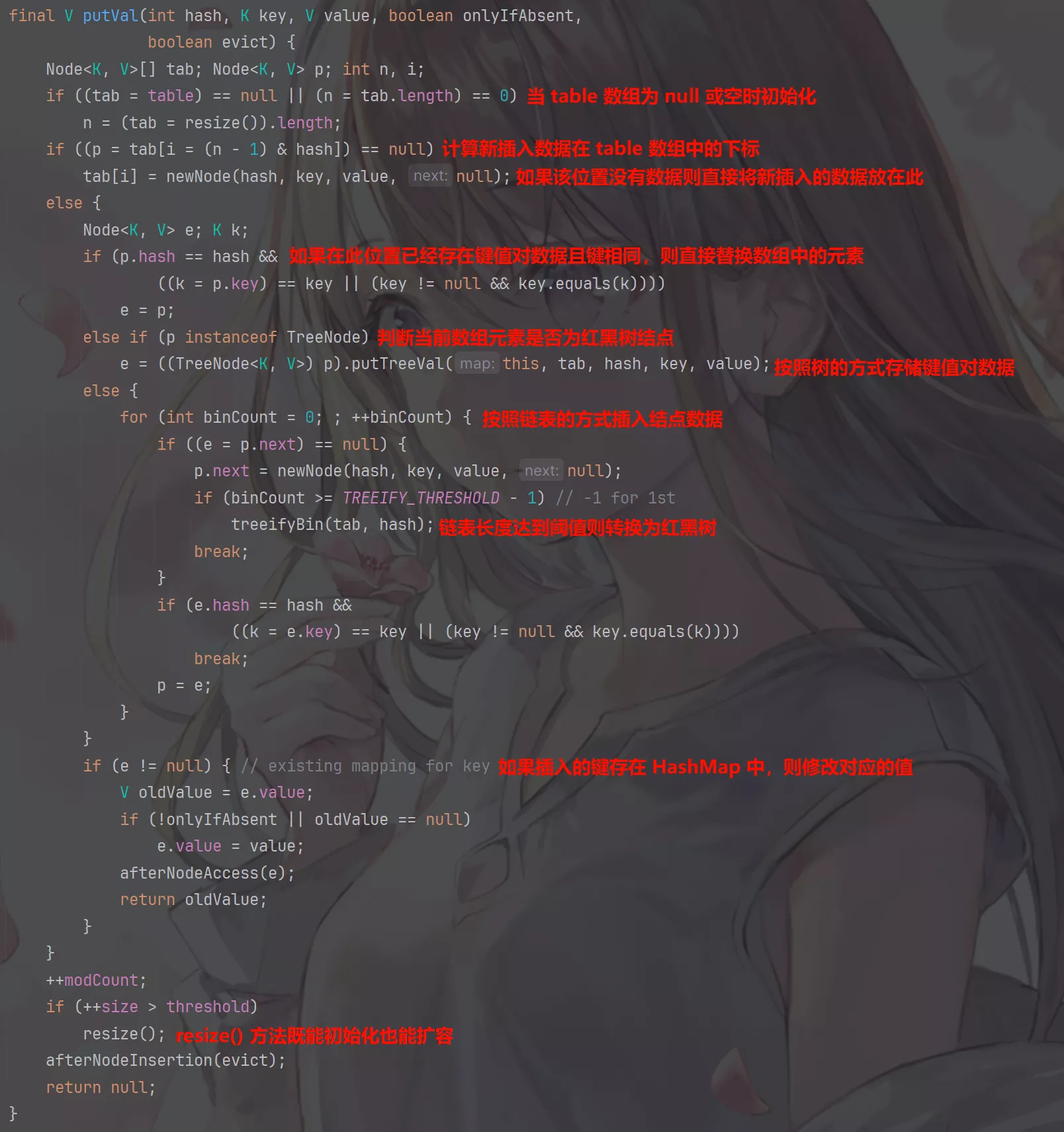
put()方法逻辑:
-
若
HashMap未被初始化,则进行初始化操作; -
对
Key求Hash值,依据Hash值计算下标; -
若未发生碰撞,则直接放入桶中;
-
若发生碰撞,则以链表的方式链接到后面;
-
若链表长度超过阀值,且
HashMap元素超过最低树化容量,则将链表转成红黑树;// 桶的容量 static final int TREEIFY_THRESHOLD = 8; // 最低树化容量 static final int MIN_TREEIFY_CAPACITY = 64;当前桶的容量超过
TREEIFY_THRESHOLD且整个HashMap中的元素超过MIN_TREEIFY_CAPACITY就会将链表转为红黑树。如果桶的容量超过TREEIFY_THRESHOLD但是元素未超过MIN_TREEIFY_CAPACITY则只会发生resize()扩容操作。 -
若节点已经存在,则用新值替换旧值;
-
若桶满了(默认容量 16 * 扩容因子 0.75),就需要
resize()(扩容 2 倍后重排)。
get()方法实现。
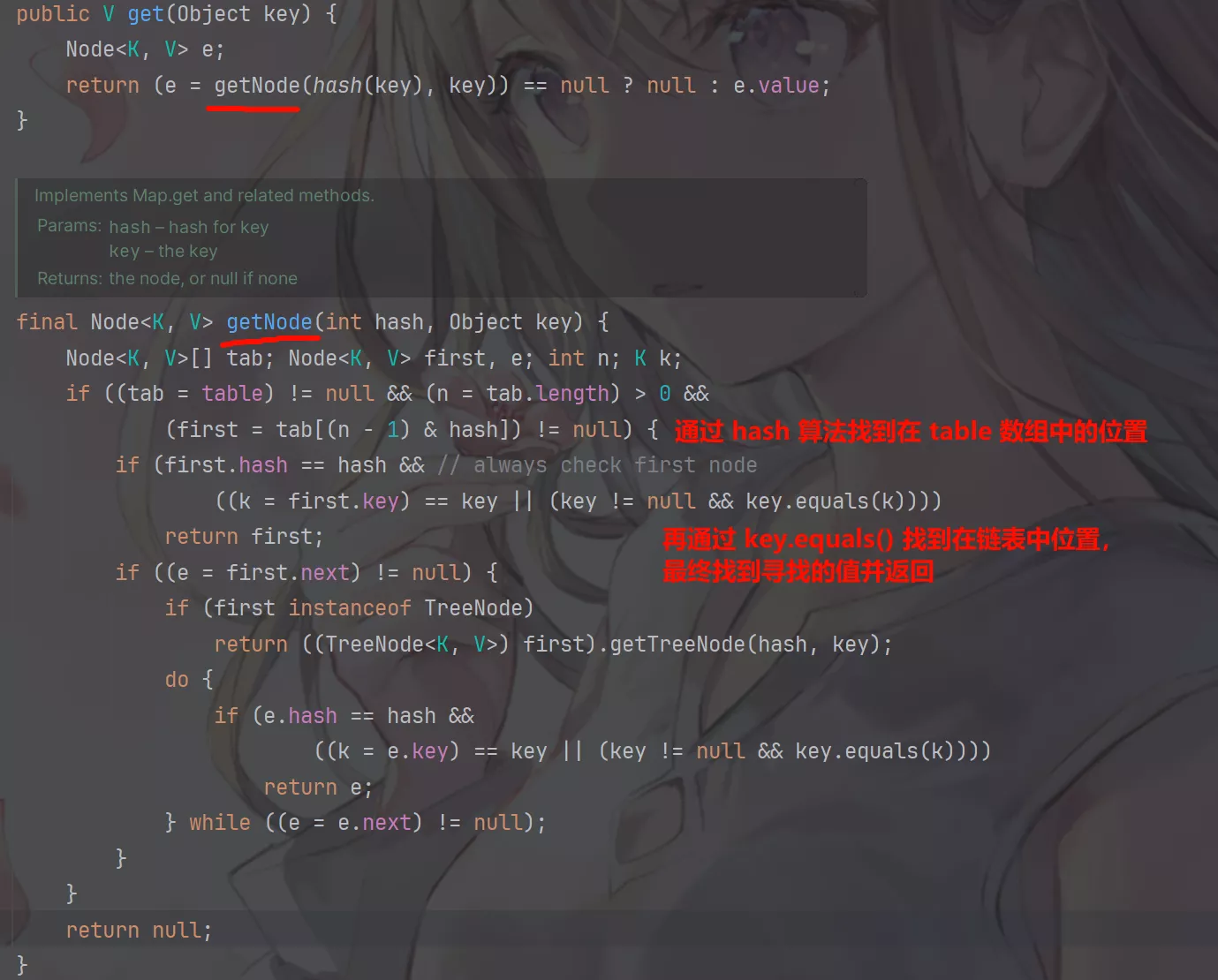
如何有效减少碰撞:
-
扰动函数:促使元素位置分布均匀,减少碰撞机率;
-
使用
final对象,并采用合适的eguals()和hashCode()方法。不可变性使得能够缓存不同键的
hashCode,提高获取速度。使用
String,Integer作为键就是非常好的选择。String是final的且重写了eguals()和hashCode()方法
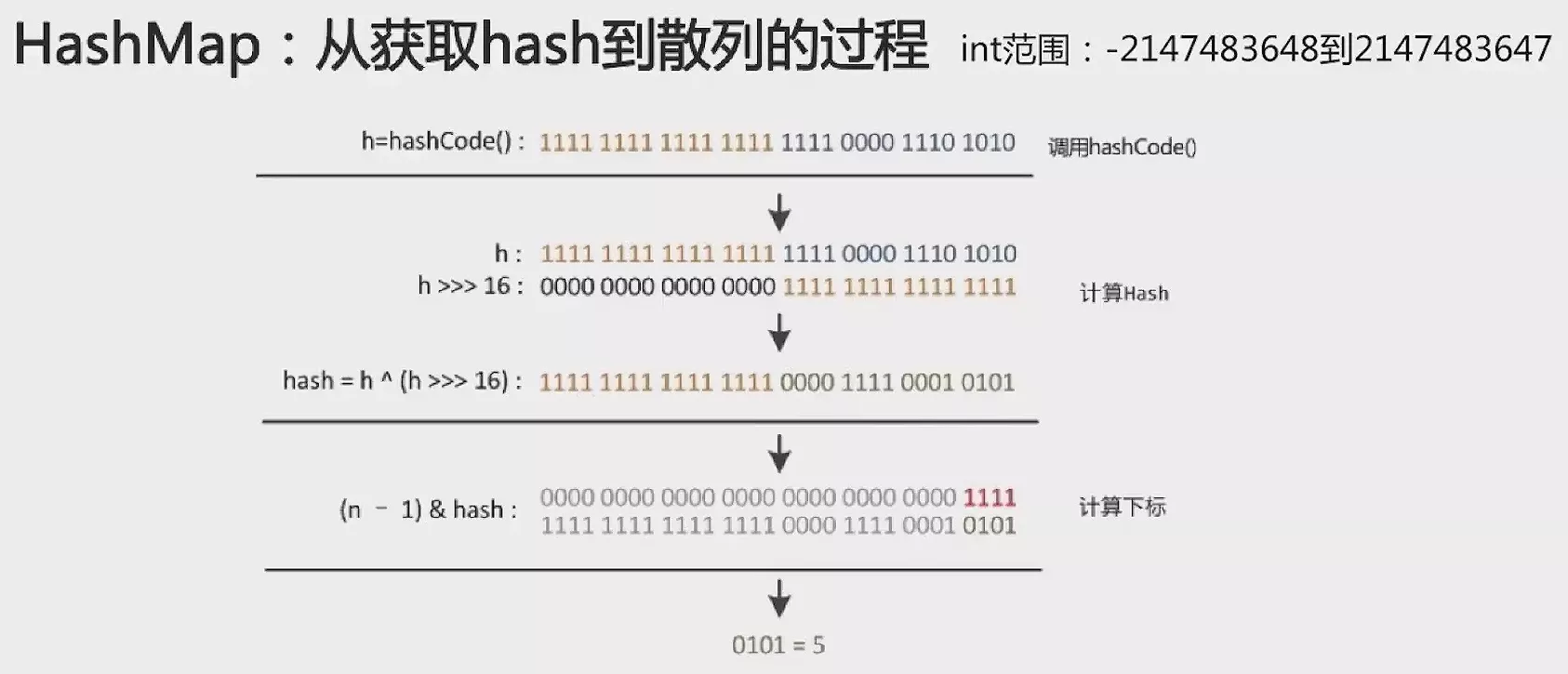
在HashMap中计算hash的方式为:先获取key的hashCode与其高 16 位移动到低 16 位(即右移 16 位)值做异或运算。

key的hashCode值为int,范围在-2147483648 ~ 2147483647有 40 亿的映射空间,内存是放不下这么大长度的数组的,所以直接拿key的hashCode来用是不现实的,所以将key的hashCode右移 16 位再做异或操作。
这样做是为了混合原始hash值的高位和地低位,加大低位的随机性,而且混合后的低位参杂了高位的特征,这样高位的信息也变相的保存了下来。在table数组长度较小时也能保证高低位都参与到运算中,也不会有太大的开销。
后面再计算元素在table中的下标时只需使用(n - 1) & hash,类似于取模操作,只是用位与运算更高效。
能用位于替换取模操作的原因是
table数组的长度总是2^n次方。
HashMap有个可以穿初始化容量的构造函数,但并不是传入的值是多少就会初始化多少个数量,它需要被换算成2^n次方。
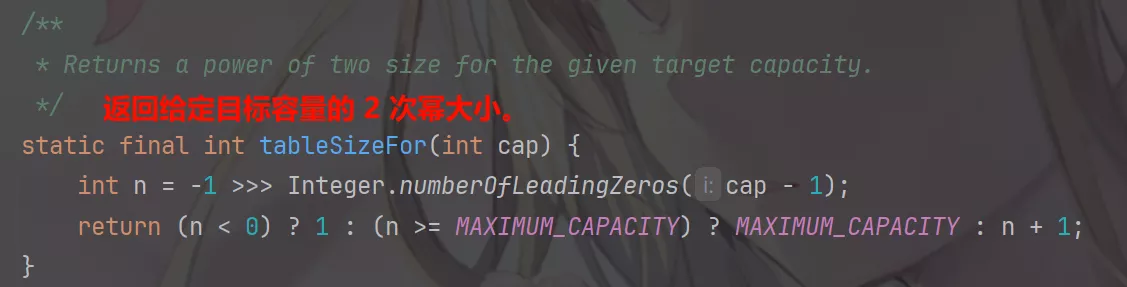
当HashMap的table数组被填满了75%时,会调用resize()方法进行扩容。
HashMap默认负载因子值为0.75,即75%。一般不要更改此值,因为它符合通用的情况。

resize()方法会创建原先table数组 2 倍容量的新数组替换原先的table数组,并将原来的元素放入到新的table数组中,这个过程叫做rehashing。
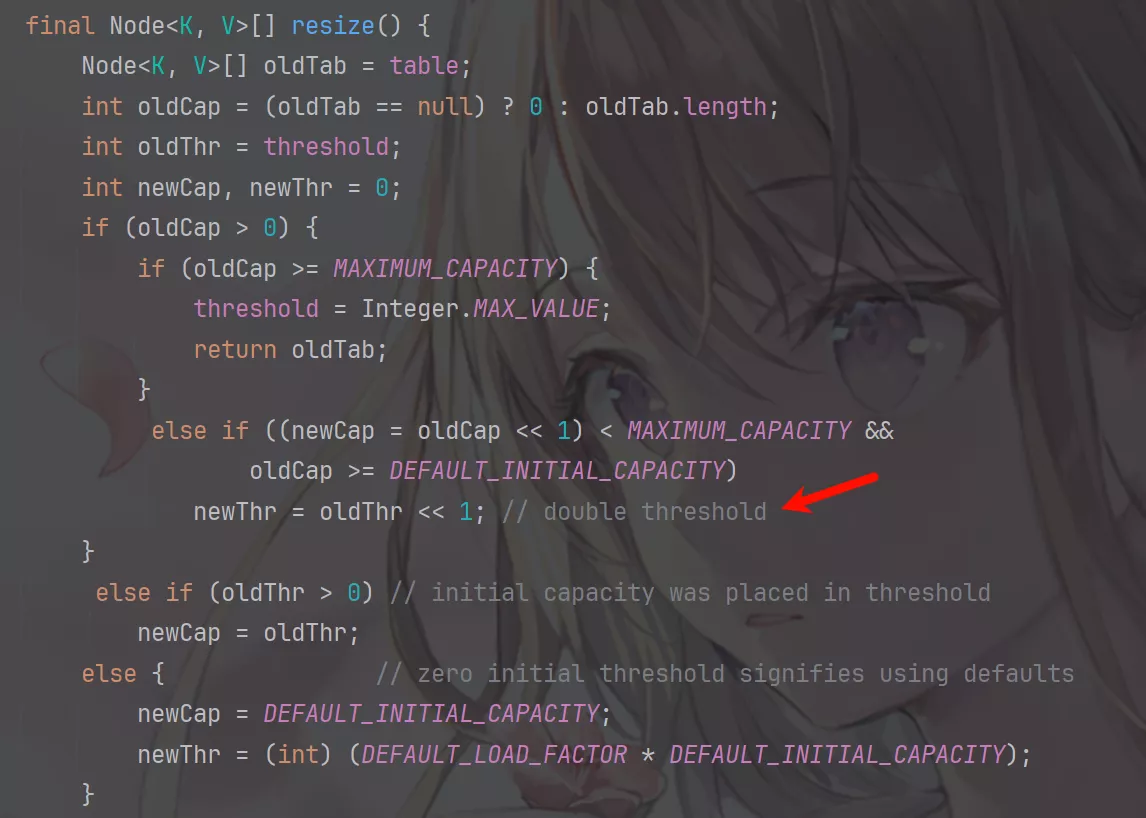
扩容的问题:
- 多线程环境下,调整大小会存在条件竞争,容易造成死锁;
rehashing(原HashMap中的值移动到新HashMap中)是一个比较耗时的过程。
HashMap 知识点回顾
- 成员变量:数据结构,树化國值;
- 构造函数:延迟创建;
put和get的流程;- 哈希算法,扩容,性能。
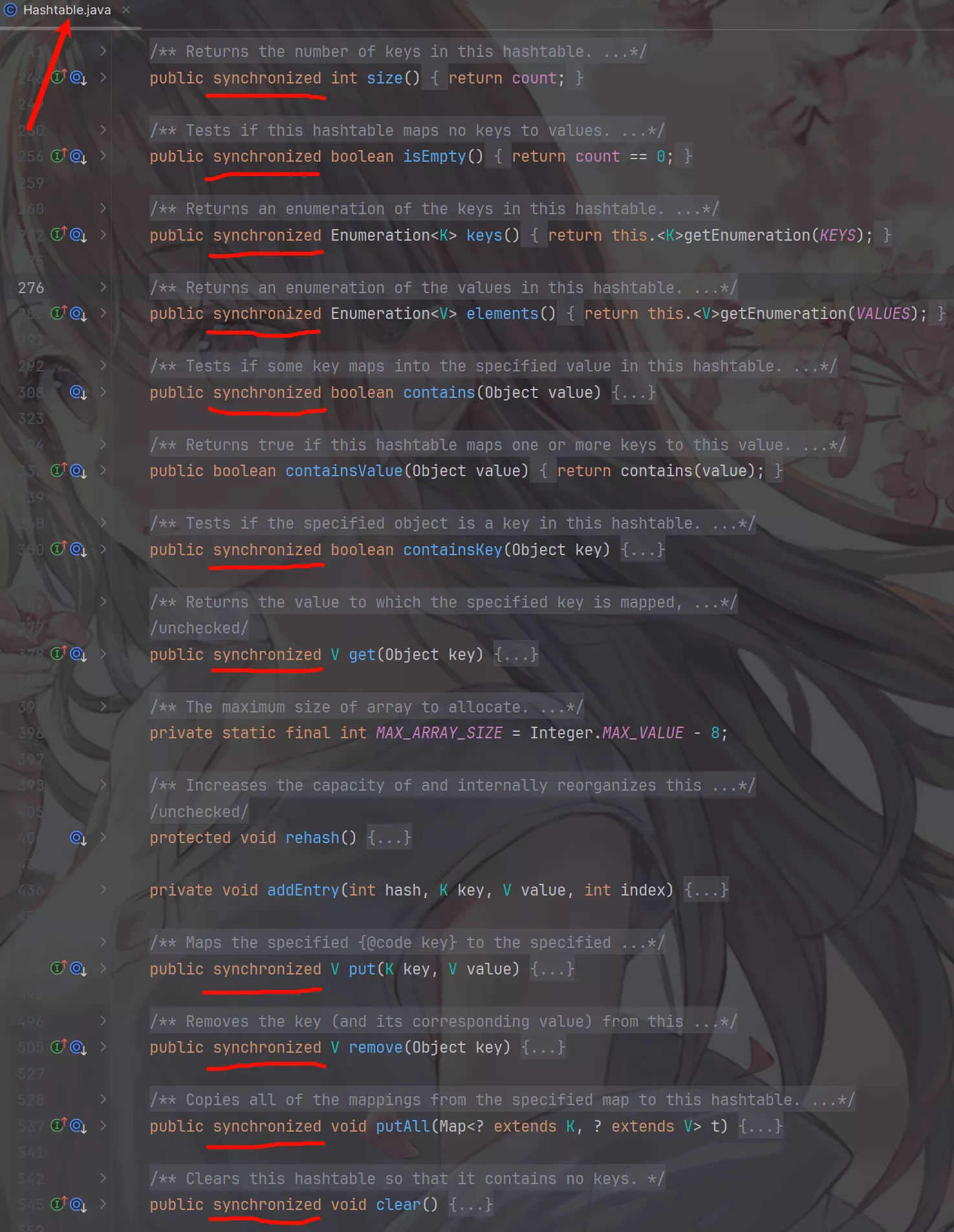
HashTable {#hashtable}
- 早期Java类库提供的哈希表的实现线程安全;
- 涉及到修改
Hashtable的方法,使用synchronized修饰; - 串行化的方式运行,性能较差,已经很少使用。
ConcurrentHashMap {#concurrenthashmap}
HashMap并不是线程安全的,但如果想要其线程安全可以使用以下的方法将HashMap对象包装成线程安全的synchronizedMap实例。
public class SafeHashMapDemo {
public static void main(String[] args) {
Map hashMap = new HashMap();
Map safeHashMap = Collections.synchronizedMap(hashMap);
safeHashMap.put("aa","1");
safeHashMap.put("bb","2");
System.out.println(safeHashMap.get("bb"));
}
}
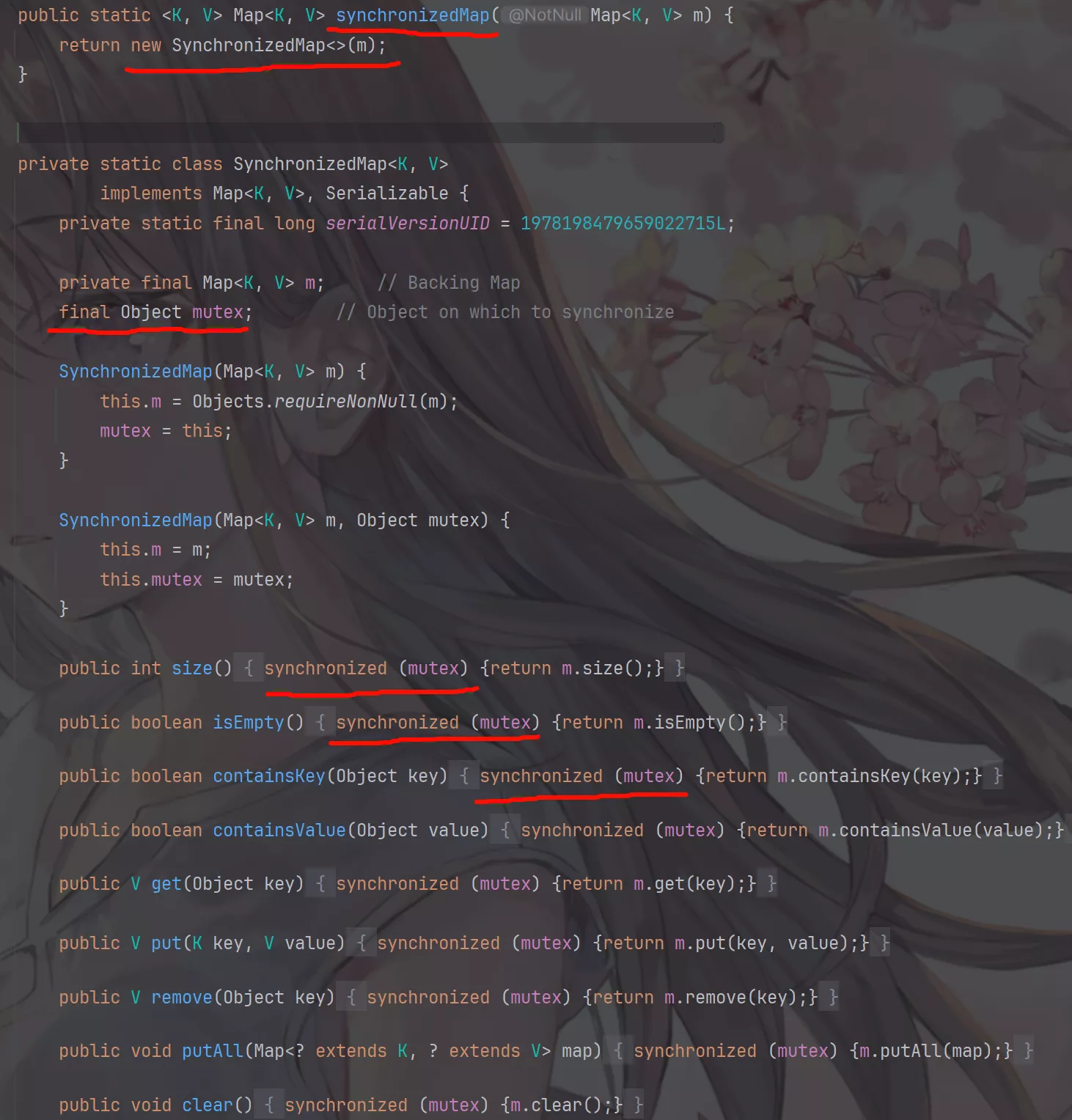
它实现的原理是使用mutex作为锁对象,使用synchronized关键字修饰public方法。
和Hashtable的实现原理几乎一样,不同的是Hashtable锁的是this,而synchronizedMap锁的是mutex对象,所以synchronizedMap效率也很低。
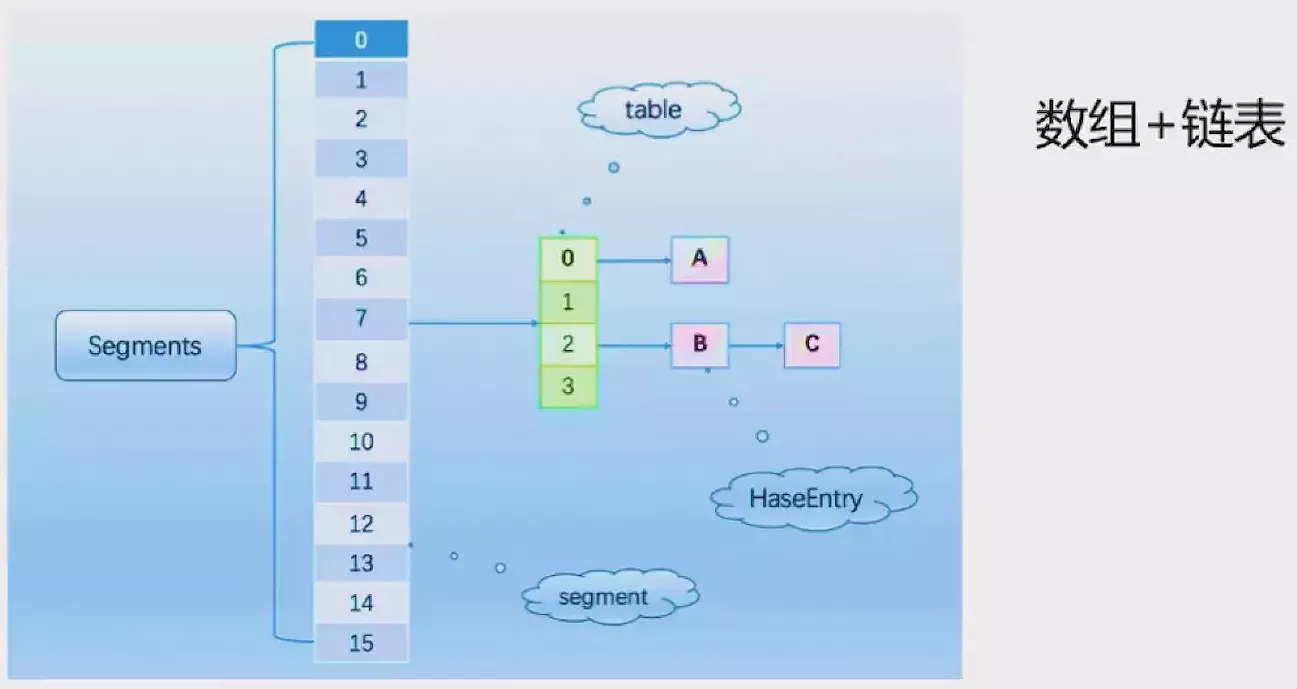
为了改进HashTable效率低下的痛点ConcurrentHashMap应运而生。
早期的ConcurrentHashMap:通过分段锁Segment来实现。
通过锁细粒度化,将整锁拆解成多个锁给每一段数据都配一把锁,当一个线程占用某把锁(即Segment)访问其中的数据时不影响位于其余Segment中的数据被其它线程访问。默认会分配 16 个Segment,所以理论上的比HashTable的效率提升了 16 倍。
当前的ConcurrentHashMap:CAS + synchronized使锁更细化。
synchronized只所动当前链表或红黑树的首结点,只要hash不冲突就不会有线程竞争,效率得到的进一步的提升。
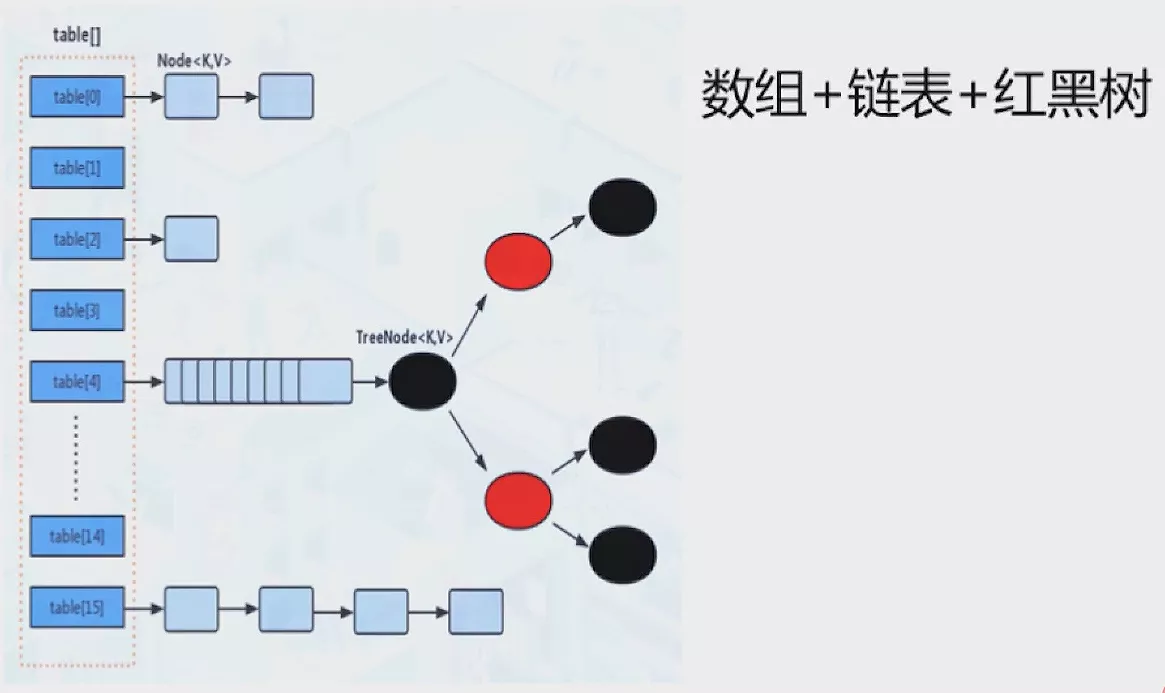
ConcurrentHashMap出自 JUC 包,有非常多的地方与HashMap类似,比如有:TREEIFY_THRESHOLD、UNTREEIFY_THRESHOLD、LOAD_FACTOR。
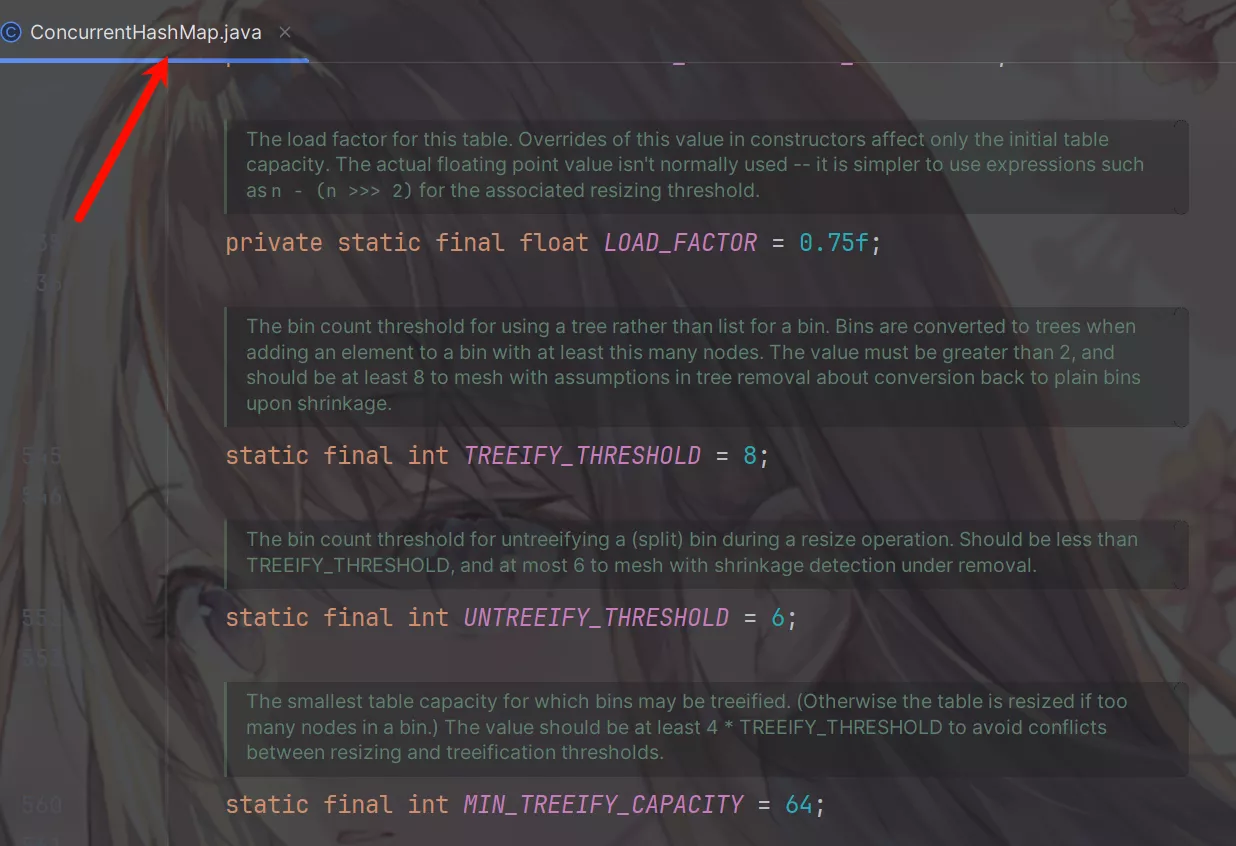
除此之外还有很多特有的成员变量,比较重要的有sizeCtl。是Hash表初始化或扩容时的控制位标识量。
- 负数代表正在初始化或扩容操作。
-1表示正在初始化。-n表示有n个线程正在进行扩容操作。
- 0 和 正数表示
Hash表还未被初始化,此时这个数值表示初始化或下一次扩容的大小。
因为有volatile关键字修饰,sizeCtl是多线程可见的,对它的修改别的线程能立刻感知到。

put()方法的源码:
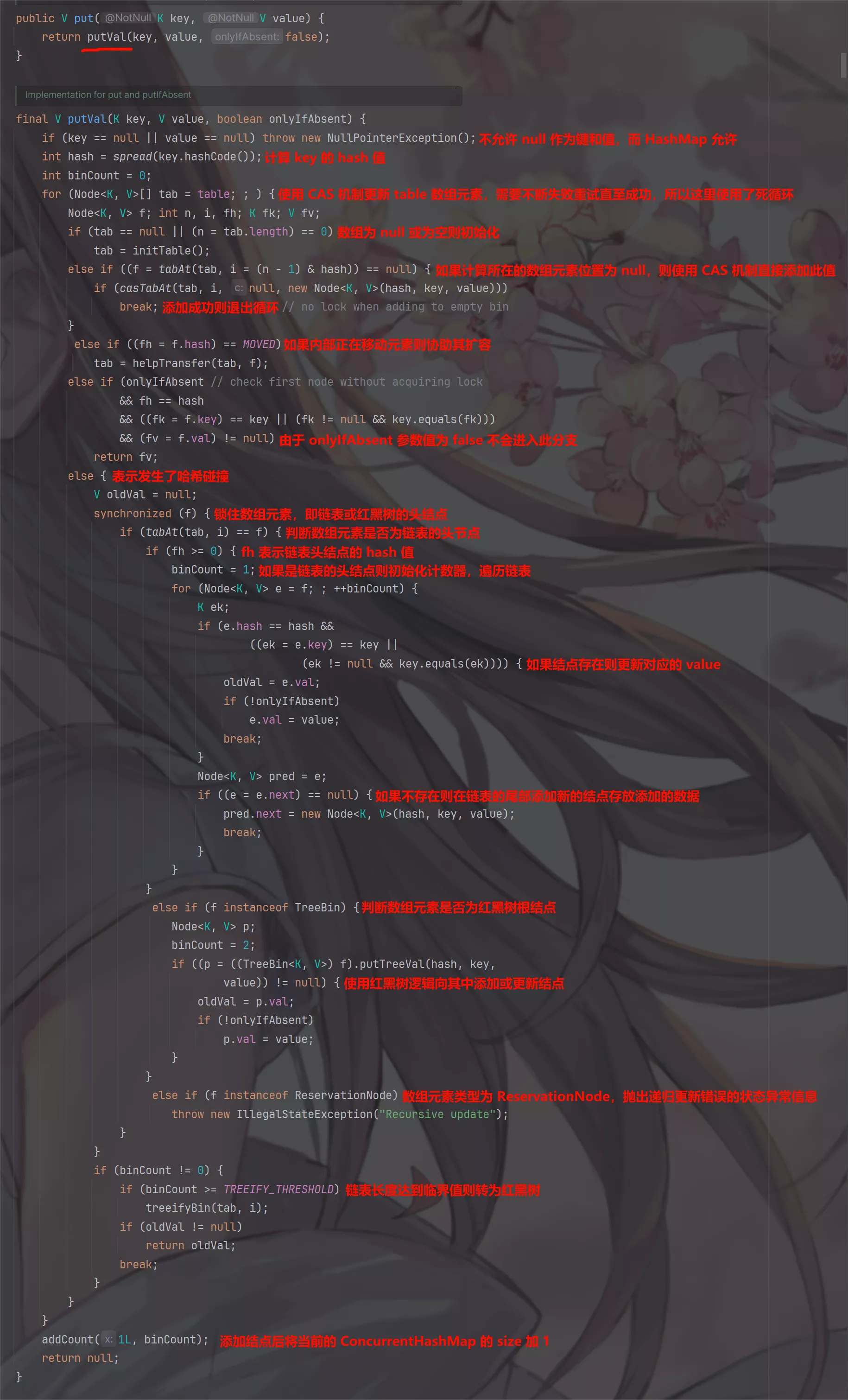
ReservationNode是保留结点,是一个占位符不会保存实际数据,正常情况下不会出现。只有当
computeIfAbsent()或compute()方法被调用时才有可能出现ReservationNode情况。这两个方法可以构建本地缓存,降低程序的计算量,因为有缓存所以
put()中要判断是否为保留结点。
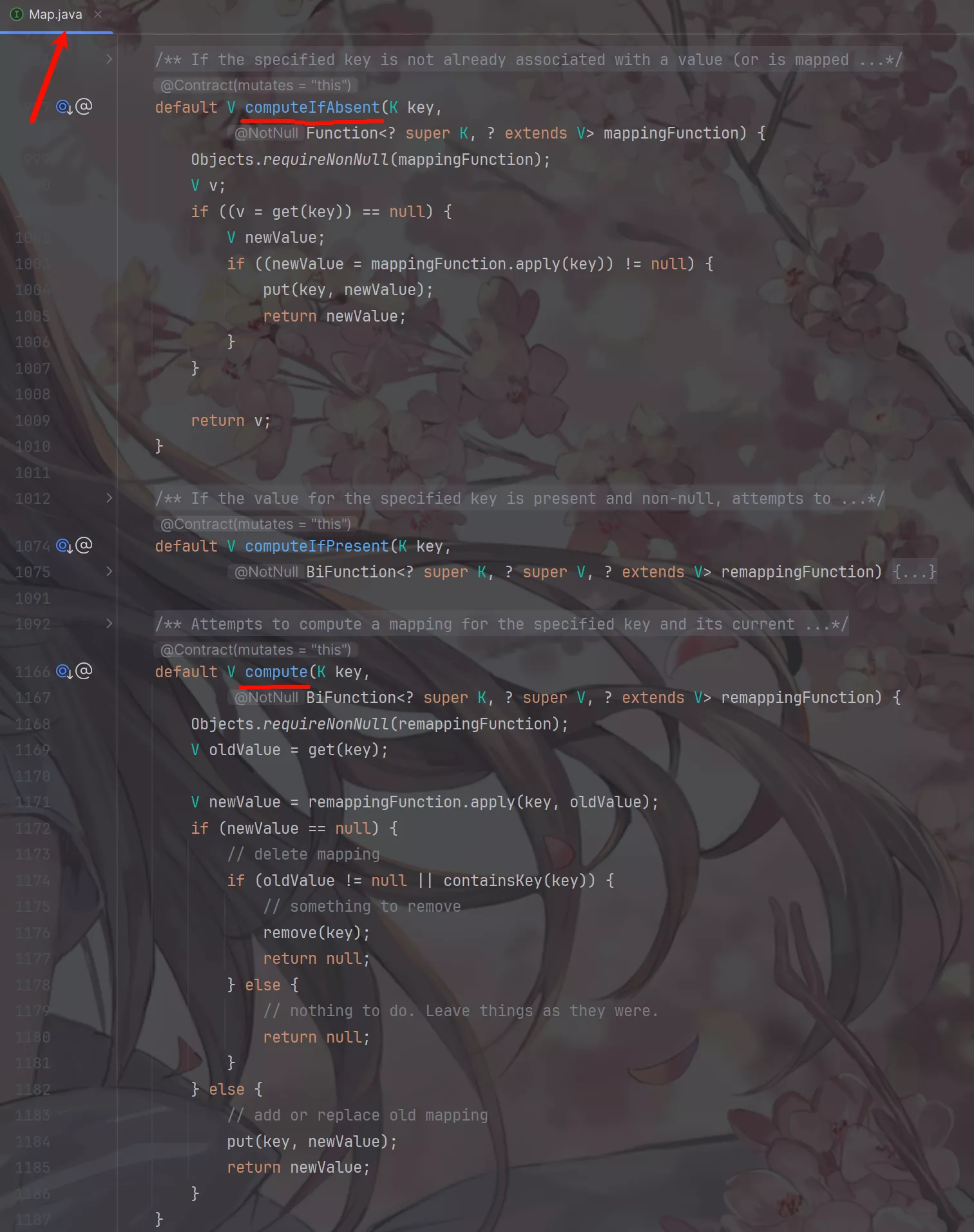
put()方法的逻辑:
-
判断
Node[]数组是否初始化,没有则进行初始化操作; -
通过
hash定位数组的索引坐标,是否有Node结点,如果没有则使用CAS进行添加(链表的头结点),添加失败则进入下次循环; -
检查到内部正在扩容,就帮助它一块扩容。
-
如果
f != null,则使用synchronized锁住f元素(链表 / 红黑二叉树的头元素);-
如果是
Node(链表结构)则执行链表的添加操作; -
如果是
TreeNode(树型结构)则执行树添加操作。
-
-
判断链表长度已经达到临界值 8,当然这个 8 是默认值,大家也可以去做调整,当结点数超过这个值就需要把链表转换为树结构。
总结:比起Segment,锁拆得更细。
- 首先使用无锁操作 CAS 插入头节点,失败则循环重试;
- 若头节点已存在,则尝试获取头节点的同步锁,再进行操作。
需要注意的点:
size()方法和mappingCount()方法的异同,两者计算是否准确?- 多线程环境下如何进行扩容?
HashMap、HashTable、ConcurrentHashMap 区别 {#hashmaphashtableconcurrenthashmap-区别}
HashMap线程不安全,数组 + 链表 + 红黑树;Hashtable线程安全,锁住整个对象,数组 + 链表;ConccurentHashMap线程安全,CAS + 同步锁,数组 + 链表 + 红黑树;HashMap的 key、value 均可为null,而其他的两个类不支持。
J.U.C 包知识点梳理 {#juc-包知识点梳理}
java.util.concurrent:提供了并发编程的解决方案。有两大核心:
CAS是java.util.concurrent.atomic包的基础;AQS是java.util.concurrent.locks包以及一些常用类比如Semophore,ReentrantLock等类的基础。
J.U.C包的分类
- 线程执行器
executor; - 锁
locks; - 原子变量类
atomic; - 并发工具类
tools; - 并发集合
collections;
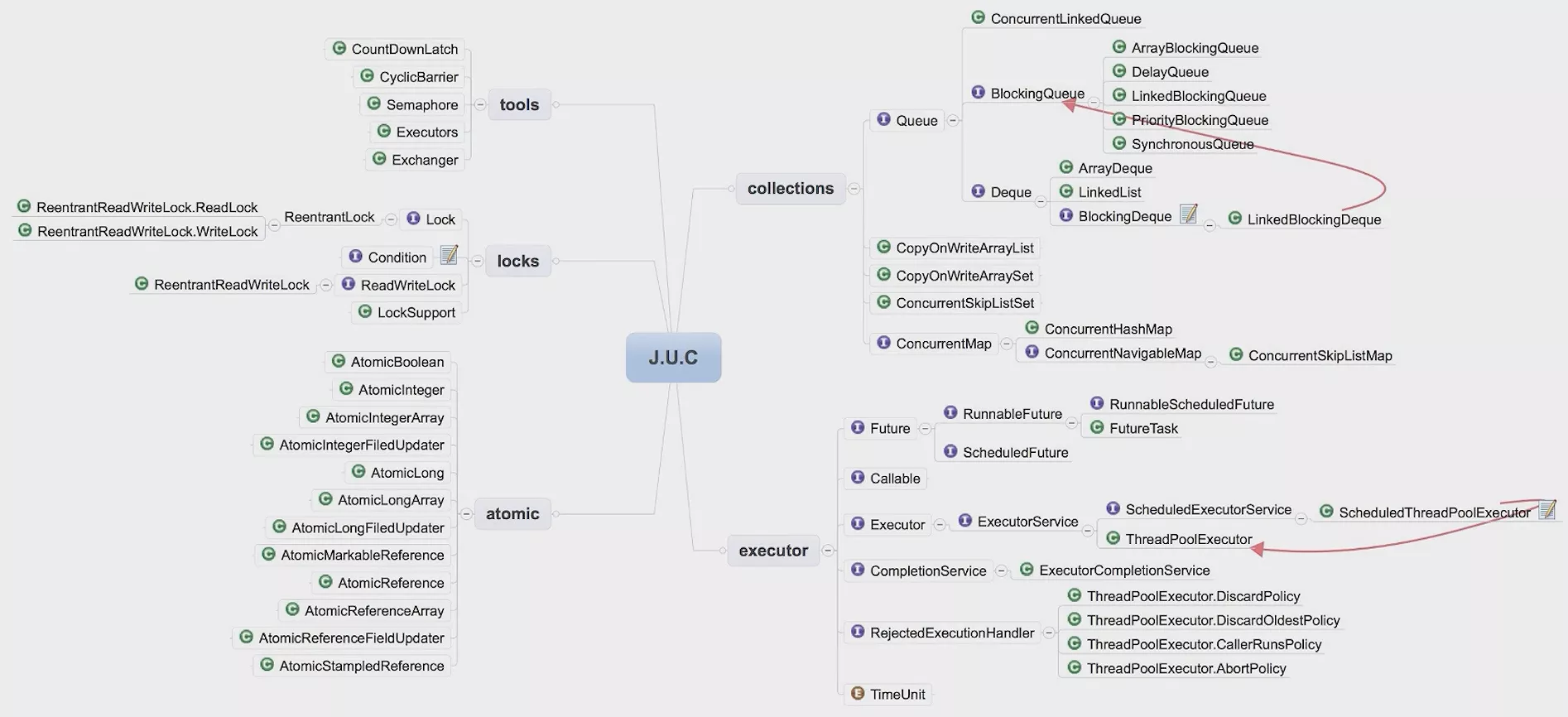
线程执行器executor是任务的执行和调度框架,在tools下有个Executors类用来创建ExecutorService、ScheduledExecutorService、ThreadFactory、Callable等对象。
在 Java 5 之前协调共享变量的访问时能够使用的方法只有synchronized和volatile,之后便出现了 J.U.C 中的locks,locks中引入了显式锁,可以更加细粒度的控制线程间的共享资源。其中Condition是由Lock对象创建的,一个Lock对象可以创建多个Condition对象,Condition对象主要用于将线程的等待和唤醒,即将wait(),notify()和notifyAll()方法对象化。Lock和Condition都是基于 AQS 实现的,而 AQS 的底层是通过调用LockSupport.park() 方法实现线程的阻塞和唤醒。ReentrantReadWhiteLock可重入读写锁,表示没有线程进行写操作时允许多个线程同时进行读操作,若有线程在进行写操作,其它线程的读和写操作只能等待,在读多于写的情况下比排它锁ReentrantLock拥有更好的并发性和吞吐量。
原子变量类atomic,表示具有原子操作特征的类,操作一旦开始就不能被中断。atomic包方便我们在多线程环境下无锁的进行原子操作。atomic包下有 12 个类,4 中更新方式,分别是:
- 原子更新基本类型;
- AtomicBoolean
- AtomicInteger
- AtomicLong
- 原子更新数组;
- AtomicIntegerArray
- AtomicLongArray
- 原子更新引用;
- AtomicMarkableReference
- AtomicReference
- AtomicStampledReference
- 原子更新字段。
- AtomicIntegerFieldUpdater
- AtomicLongFieldUpdater
- AtomicReferenceFieldUpdater
- AtomicStampledReference
atomic使用 CAS 方式更新字段,当某个线程执行atomic方法时不会被其它线程打断,其它线程就像自旋锁那样一致等待到atomic方法执行完毕,再由 JVM 从等待池中选取一个线程来执行。在软件层面上是非阻塞的,底层是借助 CPU 的原子指令来实现的。
在面对多线程中累加操作的问题中可以适当使用atomic变量来解决。
并发工具类:
- 闭锁
CountDownLatch; - 栅栏
CyclicBarrier; - 信号量
Semaphore; - 交换器
Exchanger。
以上 4 个同步器都是为了协助线程间的同步。
CountDownLatch(闭锁):让让主线程等待一组事件发生后继续执行。
事件指的是CountDownLatch里的countDown()方法。
子线程线程调用countDown()方法之后还会继续执,它只是告诉下主线程我这里 ok 了。
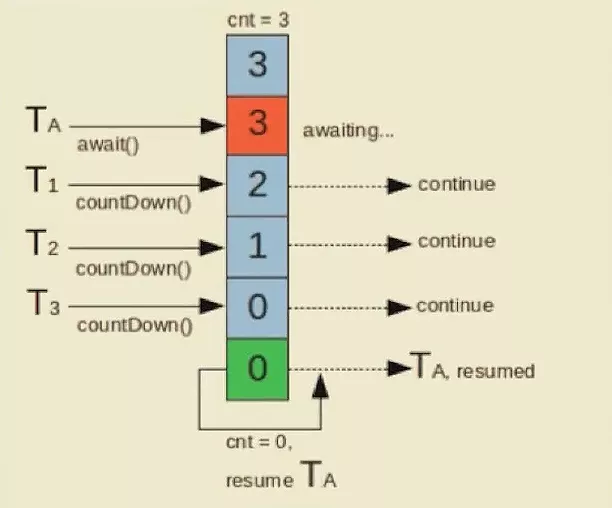
如上图,调用CountDownLatch.await()方法后主线就进入等待状态,CountDownLatch中有个类似计数的变量cnt,表示事件的个数,每当子线程调用countDown()方法后计数器cnt就会-1,直到所有的子线程都调用了countDown()方法计数器cnt为 0 后,主线程才能恢复继续执行。
CountDownLatch的使用方法请看下面的例子:
public class CountDownLatchDemo {
public static void main(String[] args) throws InterruptedException {
new CountDownLatchDemo().go();
}
private void go() throws InterruptedException {
CountDownLatch countDownLatch = new CountDownLatch(3);
// 依次创建3个线程,并启动
new Thread(new Task(countDownLatch), "Thread1").start();
Thread.sleep(1000);
new Thread(new Task(countDownLatch), "Thread2").start();
Thread.sleep(1000);
new Thread(new Task(countDownLatch), "Thread3").start();
countDownLatch.await();
System.out.println("所有线程已到达,主线程开始执行" + System.currentTimeMillis());
}
class Task implements Runnable {
private CountDownLatch countDownLatch;
public Task(CountDownLatch countDownLatch) {
this.countDownLatch = countDownLatch;
}
@Override
public void run() {
System.out.println("线程" + Thread.currentThread().getName() + "已经到达" + System.currentTimeMillis());
countDownLatch.countDown();
}
}
/* 输出:
线程Thread1已经到达1710167235051
线程Thread2已经到达1710167236059
线程Thread3已经到达1710167237072
所有线程已到达,主线程开始执行1710167237073
*/
}
CyclicBarrier(栅栏):阻塞当前线程,等待其他线程。
- 等待其它线程,且会阻塞自己当前线程,所有线程必须同时到达栅栏位置后,才能继续执行;
- 所有线程到达栅栏处,可以触发执行另外一个预先设置的线程。
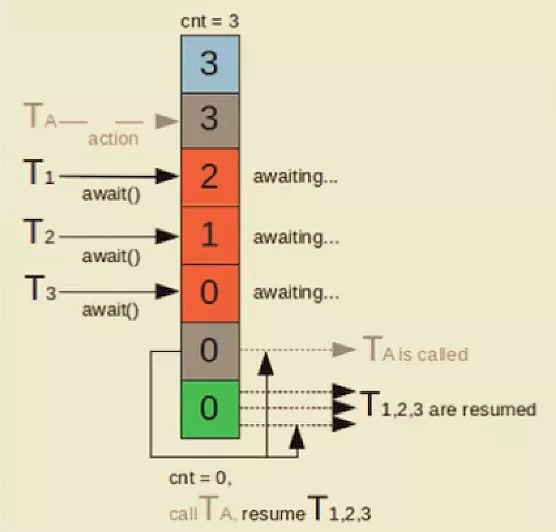
如上图,CyclicBarrier与上面的CountDownLatch一样内部也有一个计数变量cnt,子线程每调用一次await()方法计数器就会-1,若此时计数器不为 0 就会阻塞当前子线程。当前线程TA会等到其三个子线程T1、T2、T3都到达栅栏处,即cnt为 0 时一起执行。
CyclicBarrier的使用方法请看下面的例子:
public class CyclicBarrierDemo {
public static void main(String[] args) throws InterruptedException {
new CyclicBarrierDemo().go();
}
private void go() throws InterruptedException {
// 初始化栅栏的参与者数为3
CyclicBarrier cyclicBarrier = new CyclicBarrier(3);
// 依次创建3个线程,并启动
new Thread(new Task(cyclicBarrier), "Thread1").start();
Thread.sleep(1000);
new Thread(new Task(cyclicBarrier), "Thread2").start();
Thread.sleep(1000);
new Thread(new Task(cyclicBarrier), "Thread3").start();
}
class Task implements Runnable {
private CyclicBarrier cyclicBarrier;
public Task(CyclicBarrier cyclicBarrier) {
this.cyclicBarrier = cyclicBarrier;
}
@Override
public void run() {
System.out.println("线程" + Thread.currentThread().getName() + "已经到达" + System.currentTimeMillis());
try {
cyclicBarrier.await();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (BrokenBarrierException e) {
e.printStackTrace();
}
System.out.println("线程" + Thread.currentThread().getName() + "开始处理" + System.currentTimeMillis());
}
}
/* 输出:
线程Thread1已经到达1710167875453
线程Thread2已经到达1710167876465
线程Thread3已经到达1710167877471
线程Thread1开始处理1710167877472
线程Thread3开始处理1710167877472
线程Thread2开始处理1710167877472
*/
}
Semaphore(信号量):控制某个资源可被同时访问的线程个数。
初始化时设置可同时访问的线程个数,子线程调用acquire()方法申请许可,使用完毕后调用release()方法释放许可。
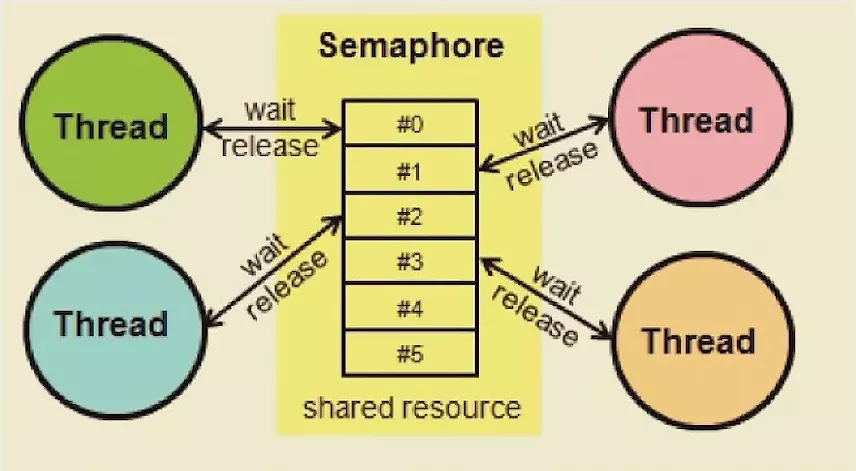
Semaphore的使用方法请看下面的例子:
public class SemaphoreDemo {
public static void main(String[] args) {
// 线程池
ExecutorService exec = Executors.newCachedThreadPool();
// 只能5个线程同时访问
final Semaphore semp = new Semaphore(5);
// 模拟20个客户端访问
for (int index = 0; index < 20; index++) {
final int NO = index;
Runnable run = new Runnable() {
public void run() {
try {
// 获取许可
semp.acquire();
System.out.println("Accessing: " + NO);
Thread.sleep((long) (Math.random() * 10000));
// 访问完后,释放
semp.release();
} catch (InterruptedException e) {
}
}
};
exec.execute(run);
}
// 退出线程池
exec.shutdown();
}
/* 输出:
Accessing: 0
Accessing: 2
Accessing: 3
Accessing: 4
Accessing: 1
Accessing: 5
Accessing: 8
Accessing: 6
Accessing: 9
Accessing: 7
Accessing: 10
Accessing: 11
Accessing: 12
Accessing: 13
Accessing: 14
Accessing: 15
Accessing: 16
Accessing: 17
Accessing: 18
Accessing: 19
*/
}
Exchanger(交换器):两个线程到达同步点后,相互交换数据。
提供一个同步点,在同步点两个线程可以交换数据。一个线程先达到同步点就会阻塞等待另一个线程也到达同步点后才会被唤醒交换数据。线程方法中调用Exchanger.exchange()方法的地方就是同步点。注意只能用于两个线程交换数据。
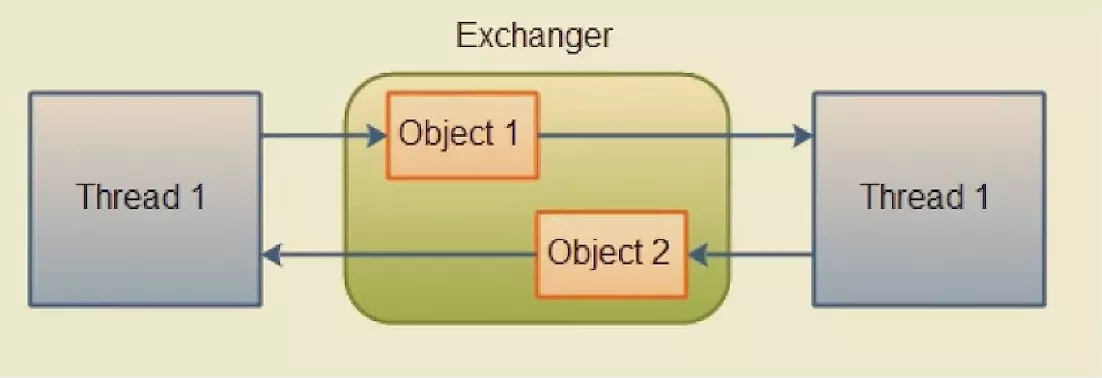
Exchanger的使用方法请看下面的例子:
public class ExchangerDemo {
private static Exchanger<String> exchanger = new Exchanger();
public static void main(String[] args) {
//代表男生和女生
ExecutorService service = Executors.newFixedThreadPool(2);
service.execute(() -> {
try {
//男生对女生说的话
String girl = exchanger.exchange("我其实暗恋你很久了......");
System.out.println("女生说:" + girl);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
service.execute(() -> {
try {
System.out.println("女生慢慢的从教室里走出来......");
TimeUnit.SECONDS.sleep(3);
//男生对女生说的话
String boy = exchanger.exchange("我很喜欢你......");
System.out.println("男生说:" + boy);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}
/* 输出:
女生慢慢的从教室里走出来......
女生说:我很喜欢你......
男生说:我其实暗恋你很久了......
*/
}
讲完并发工具类后,还剩最后一部分并发集合collections。
BlockingQueue:提供可阻塞的入队和出队操作。
主要用于生产者-消费者模式,在多线程场景时生产者线程在队列尾部添加元素,而消费者线程则在队列头部消费元素,通过这种方式能够达到将任务的生产和消费进行隔离的目的。
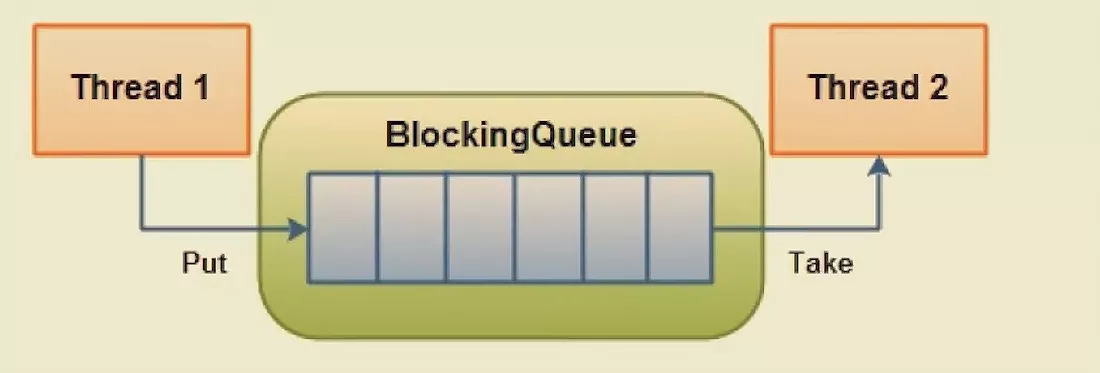
BlockingQueue接口中的典型方法:
// 尝试向队尾添加元素,添加成功返回 true,失败抛出 IllegalStateException 异常;
boolean add(E e);
// 尝试向队尾添加元素,添加成功返回 true,失败返回 false;
boolean offer(E e);
// 尝试向队尾添加元素,如果队列满了则阻塞直到成功添加为止;
void put(E e) throws InterruptedException;
// 尝试向队尾添加元素,如果队列满了则阻塞直到成功添加为止,并可指定超时时间,超时未成功添加则抛出 InterruptedException 异常
boolean offer(E e, long timeout, TimeUnit unit)
throws InterruptedException;
// 尝试从队头取出元素,如果队列为空则阻塞直到成功去除元素为止,对应 put() 方法;
E take() throws InterruptedException;
// 尝试从队头取出元素,如果队列为空则阻塞直到成功去除元素为止,并可指定超时时间,超时未成功取到元素则抛出 InterruptedException 异常,对应 offer() 方法;
E poll(long timeout, TimeUnit unit)
throws InterruptedException;
// 获取当前队列剩余容量
int remainingCapacity();
// 从队列中移除指定对象
boolean remove(Object o);
// 判断队列中是否存在指定对象
boolean contains(Object o);
// 将队列中的元素转移到指定的集合中
int drainTo(Collection<? super E> c);
它的实现类有(重点前 3 个):
-
ArrayBlockingQueue:一个由数组结构组成的有界阻塞队列; -
LinkedBlockingQueue:一个由链表结构组成的有界/无界阻塞队列; -
PriorityBlockingQueue:一个支持优先级排序的无界阻塞队列,不是先进先出; -
DealyQueue:一个使用优先级队列实现的无界阻塞队列;队列中的元素必须实现
Dealy接口,只有在指定的延迟期满后才能从队列中获取到此元素。 -
SynchronousQueue:一个不存储元素的阻塞队列;仅允许容纳一个元素。
-
LinkedTransferQueue:一个由链表结构组成的无界阻塞队列;是
SynchronousQueue和LinkedBlockingQueue的合体,性能比LinkedBlockingQueue更高,因为它是无锁操作,比SynchronousQueue能存储更多的元素。 -
LinkedBlockingDeque:一个由链表结构组成的双向阻塞队列。
Java 的 IO 机制 {#java-的-io-机制}
Java 的 IO 机制经过多年的完善在实践中证明了构建高扩展性应用的能力。其实现方式基于不同的抽象模型可分为多种。
BIO、NIO、AIO 有什么区别?
Block-IO(BIO)阻塞 IO 是java.io和部分java.net包下的类,例如java.net包下的Socket、ServerSocket、Http、URLConnection,因为网络通信同样属于 IO 行为。
传统 IO 基于字节流和字符流进行操作,为我们提供很方便的功能,比如基于字节流的InputStream和OutputStream,基于字符流的Reader和Writer。
当使用
InputStream、OutputStream、Reader和Writer时,主要区别和用法如下:InputStream(输入流) {#inputstream输入流}
用途:处理字节数据的输入流。
常见用法:
- 从文件、网络连接或其他数据源读取字节。
- 读取图像、音频、视频等二进制数据。
常见类:
FileInputStream:从文件中读取字节流。ByteArrayInputStream:从字节数组中读取字节。示例用法:
InputStream input = new FileInputStream("file.txt"); int data = input.read(); while (data != -1) { // 处理读取的字节数据 data = input.read(); } input.close();OutputStream(输出流) {#outputstream输出流}
用途:处理字节数据的输出流。
常见用法:
- 将字节数据写入文件、网络连接或其他数据目标。
- 写入图像、音频、视频等二进制数据。
常见类:
FileOutputStream:将字节写入文件。ByteArrayOutputStream:将字节写入字节数组。示例用法:
OutputStream output = new FileOutputStream("output.txt"); output.write("Hello, World!".getBytes()); output.close();Reader(读取器) {#reader读取器}
用途:处理字符数据的输入流。
常见用法:
- 从文件、网络连接或其他数据源读取字符。
- 读取文本文件中的内容。
常见类:
FileReader:从文件中读取字符流。StringReader:从字符串中读取字符。示例用法:
Reader reader = new FileReader("file.txt"); int data = reader.read(); while (data != -1) { // 处理读取的字符数据 data = reader.read(); } reader.close();Writer(写入器) {#writer写入器}
用途:处理字符数据的输出流。
常见用法:
- 将字符数据写入文件、网络连接或其他数据目标。
- 写入文本数据到文件。
常见类:
FileWriter:将字符写入文件。StringWriter:将字符写入字符串。示例用法:
Writer writer = new FileWriter("output.txt"); writer.write("Hello, World!"); writer.close();区别总结 {#区别总结}
- 数据类型 :
InputStream和OutputStream处理字节数据。Reader和Writer处理字符数据。- 适用性 :
- 使用字节流处理二进制数据(如图像、音频)。
- 使用字符流处理文本数据,可以更好地处理字符编码。
- 类别 :
- 字节流(
InputStream和OutputStream)更适合处理所有类型的数据。- 字符流(
Reader和Writer)更适合处理文本数据,因为它们能够正确处理字符编码。这些是基本的区别和用法,具体情况会根据需求和数据类型有所变化。
BIO基于流模型实现,采用同步阻塞的交互方式,在读写操作完成之前线程会一直被阻塞,按照线性顺序串行执行。
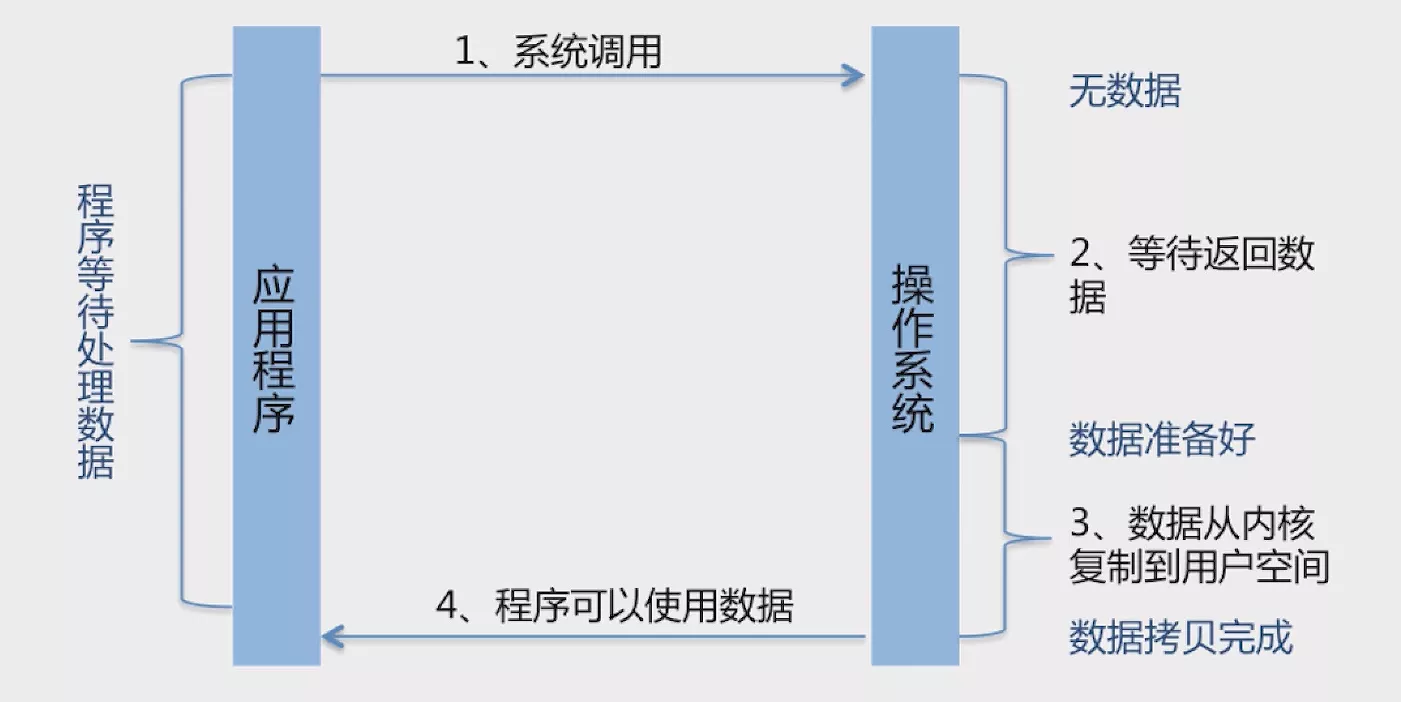
特点是:在 IO 执行的 2 个阶段都被阻塞住了。
优点是:代码简单,直观。
缺点是:IO 效率和扩展性不好。
NonBlock-IO (NIO)非阻塞 IO,提供了Channels、Buffers、Selectors等新的抽象,可以构建多路复用、同步非阻塞的 IO 操作,提供了更接近操作系统底层的高性能操作方式。
与BIO明显的不同是NIO在发起系统调用的请求后并没有被阻塞,而是反复检查数据是否已被准备好,把原来大块不能用的阻塞时间分成了许多小的阻塞,即检查数据是否已准备好时会发生小的阻塞,类似于轮询机制。
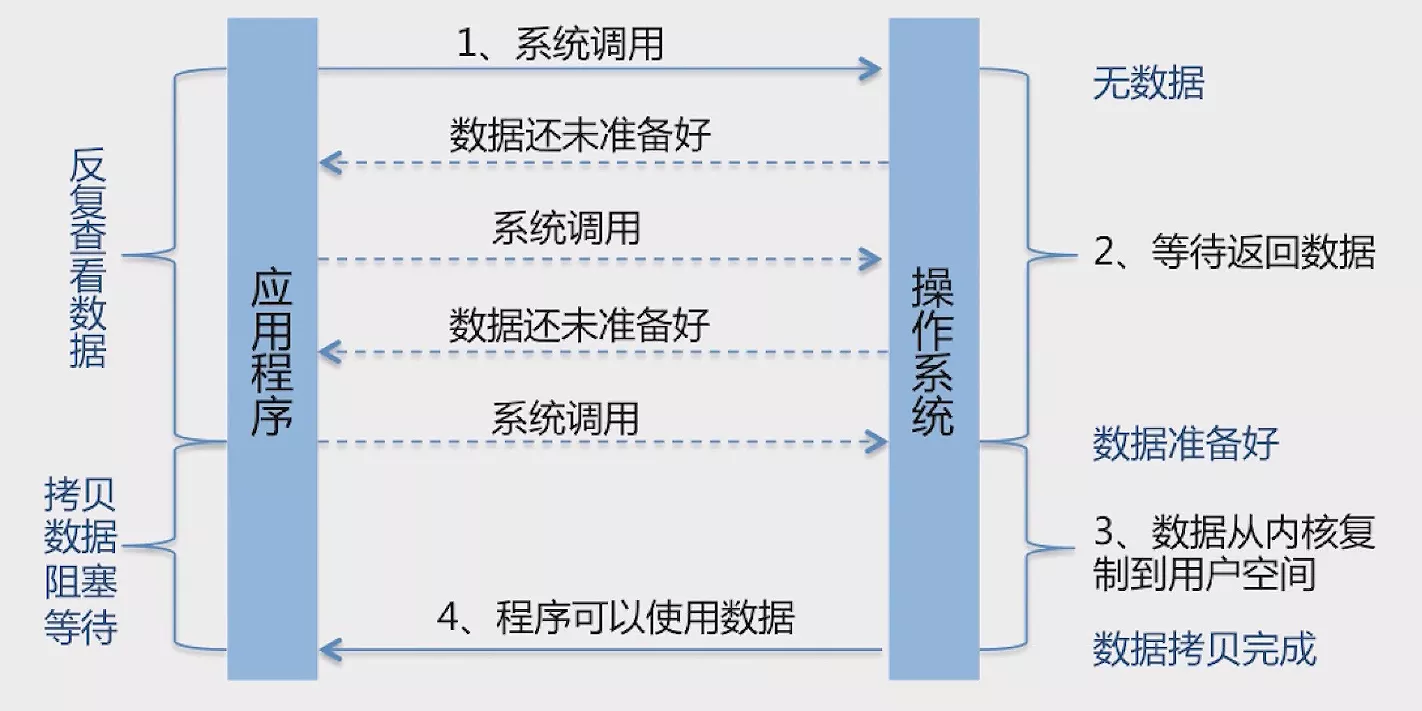
特点是:程序需要不断的询问内核是否已准备好,第一个返回查看数据的阶段是非阻塞的,第二个拷贝数据阶段是阻塞的。
NIO的核心:
- Channels
- Buffers
- Selectors
基本上NIO中的 IO 操作都从一个Channel开始。Channel类似于流,数据可以从Channel读到Buffer中,也可以从Buffer写到Channel中。
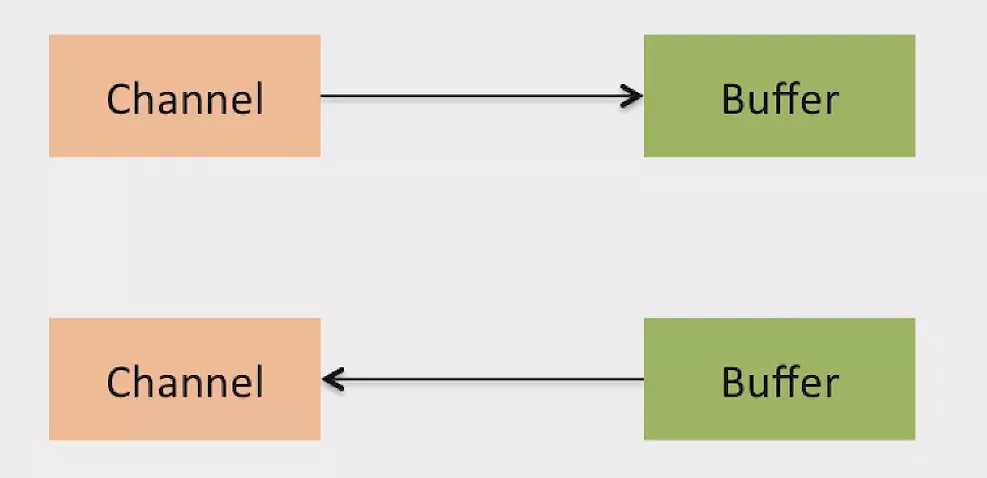
NIO-Channels 类型:
-
FileChannel
它拥有以下两个方法:
transferTo():把FileChannel中的数据拷贝到另外一个Channel;transferFrom():把另外一个Channel中的数据拷贝到FileChannel。
常用于高效的网络数据传输和大文件拷贝,在操作系统的支持下通过该方法传输数据无需将数据从内核态拷贝到用户态,再从用户态拷贝到目标的内核态,避免了 2 次用户态和内核态间的上下文切换,即"零拷贝",效率较高。
-
DatagramChannel
-
SocketChannel
-
ServerSocketChannel
这些类型覆盖了 TCP,UDP 网络 IO 和文件 IO。
NIO-Buffers 类型:
- ByteBuffer
- CharBuffer
- DoubleBuffer
- FloatBuffer
- IntBuffer
- LongBuffer
- ShortBuffer
- MappedByteBuffer
这些 Buffer 包含了能通过 IO 发送的基本数据类型,MappedByteBuffer主要用于表示内存映射文件。
NIO-Selector
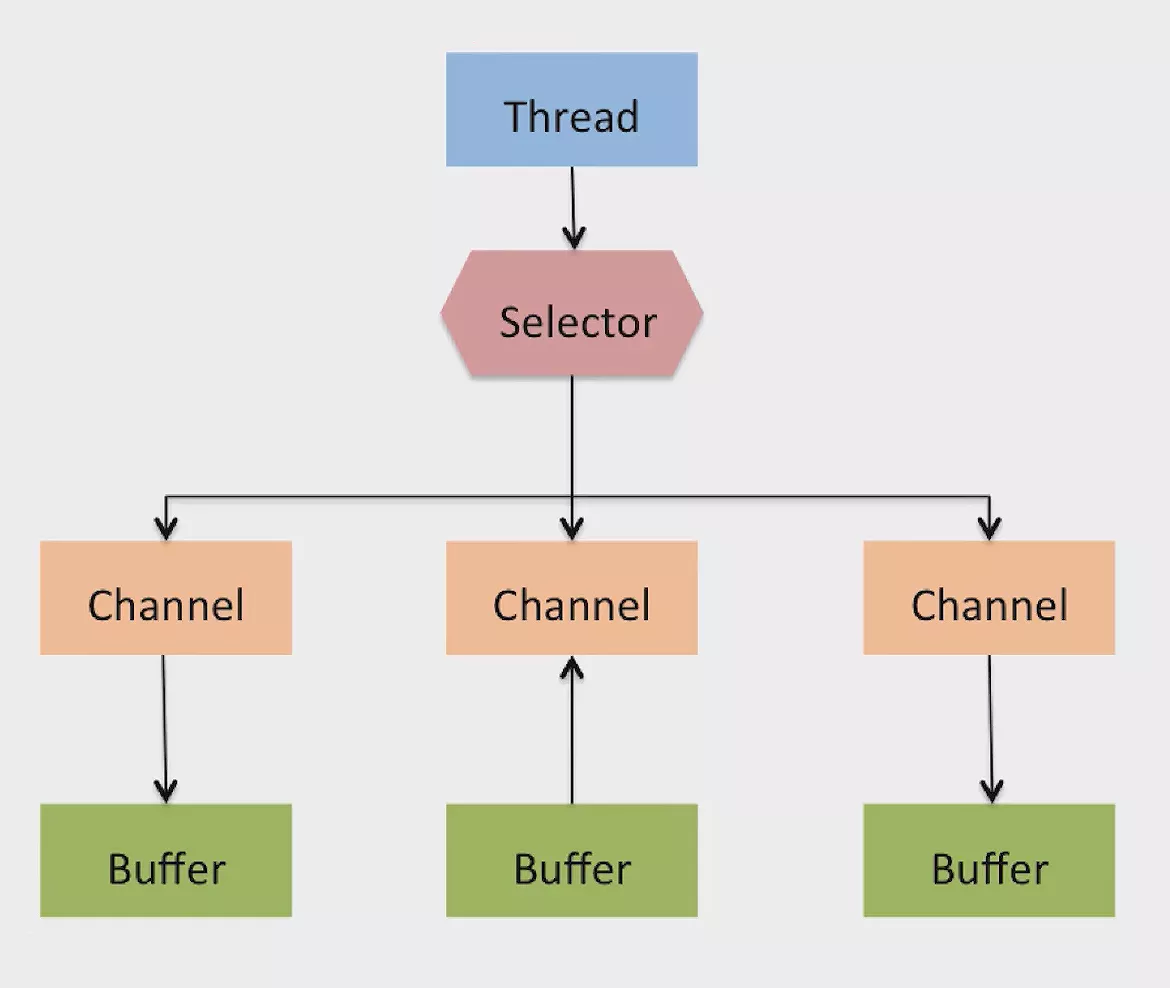
Selector允许单线程处理多个Channel。
若应用打开了多个连接,即通道,但每个连接的流量都很低,使用Selector就会很方便。
使用Selector需要先向其注册Channel,然后调用select()方法。此方法会一直阻塞直到某个注册的通道Channel有事件就绪,一旦此方法返回,线程就可以处理这些事件,事件可以是有新的连接创建,Buffer中有内容可以被读取等。
下图表示的是单个线程使用一个Selector操作三个Channel的情形。
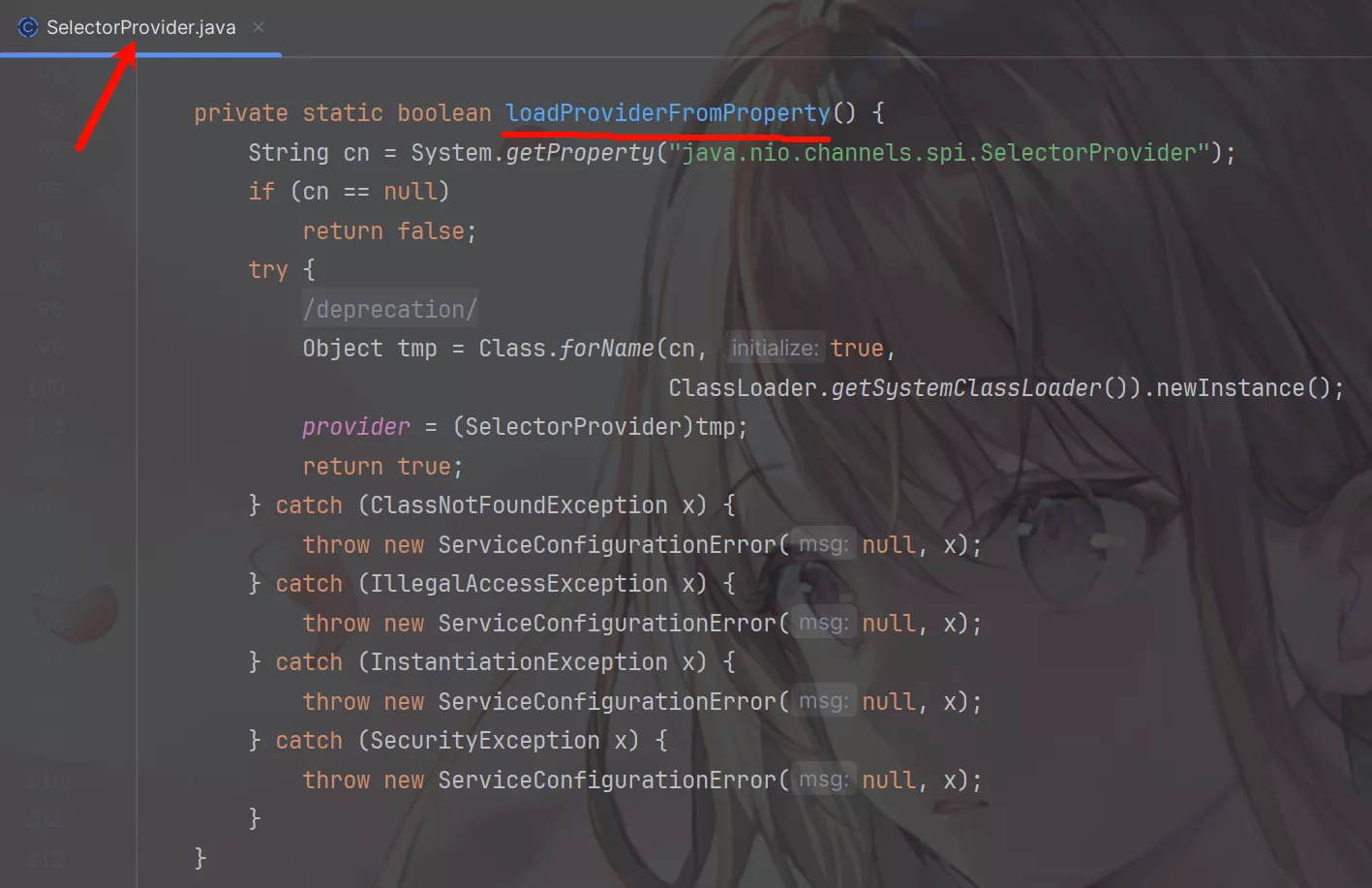
在其源码中可以发现Selector是由SelectorProvider创建。
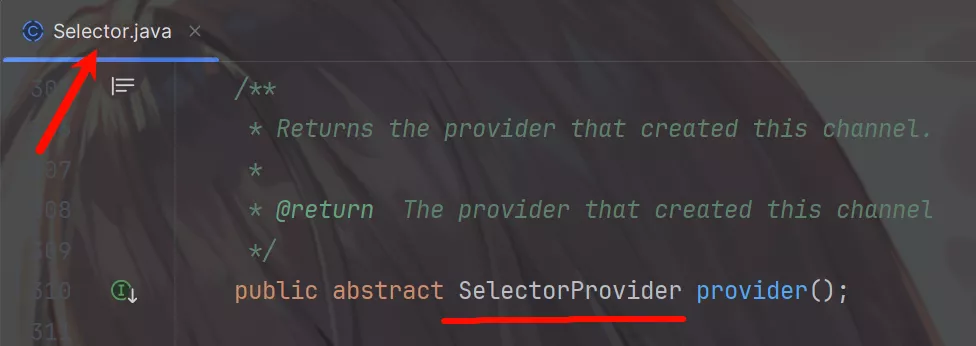
在SelectorProvider.provider()方法中加载SelectorProvider对象。
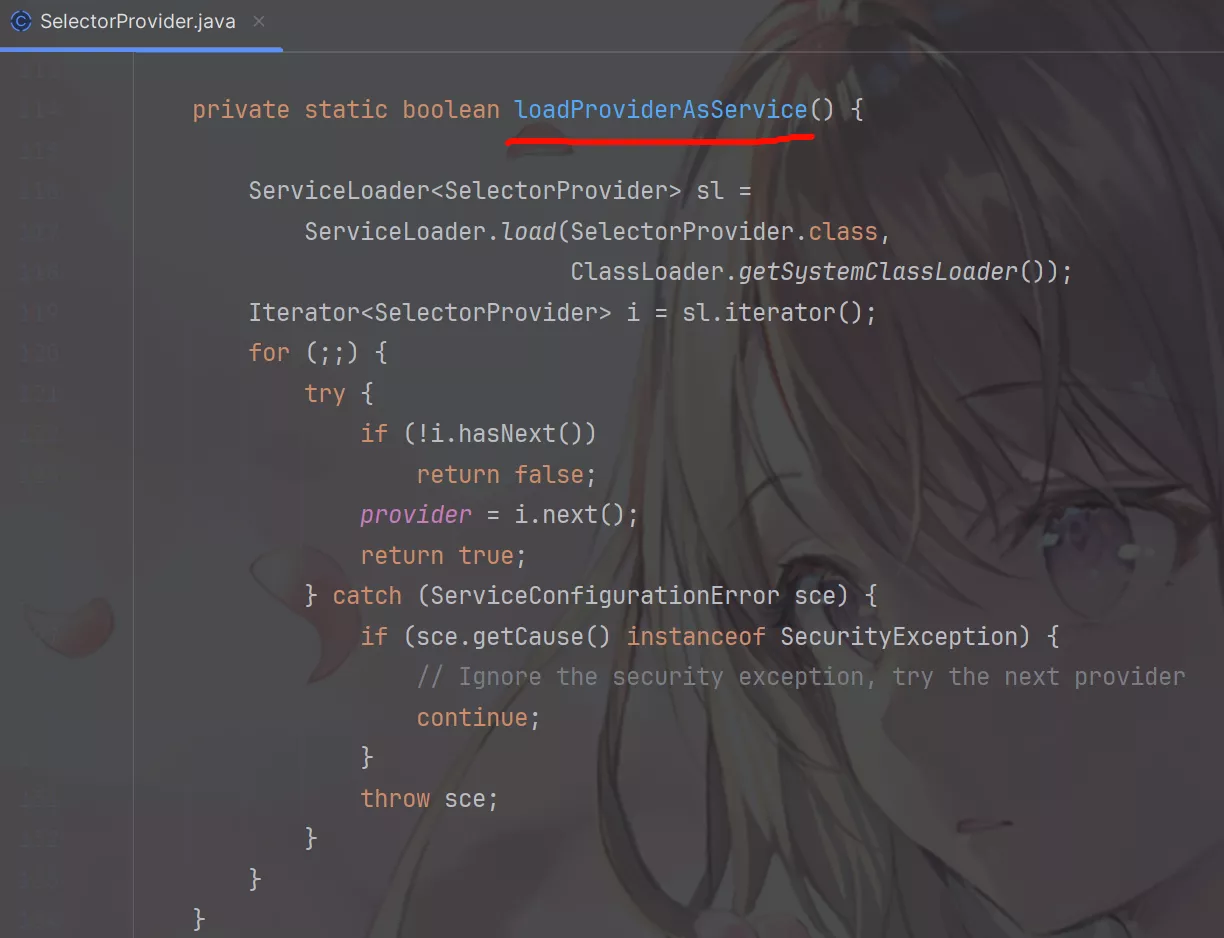
它首先通过loadProviderFromProperty()方法尝试寻找相关的文件去做Selector实现类的加载,如果加载不到再去执行loadProviderAsService()方法再次尝试加载,如果还是加载不到就会使用DefaultSelectorProvider.create()创建SelectorProvider实现类实例。
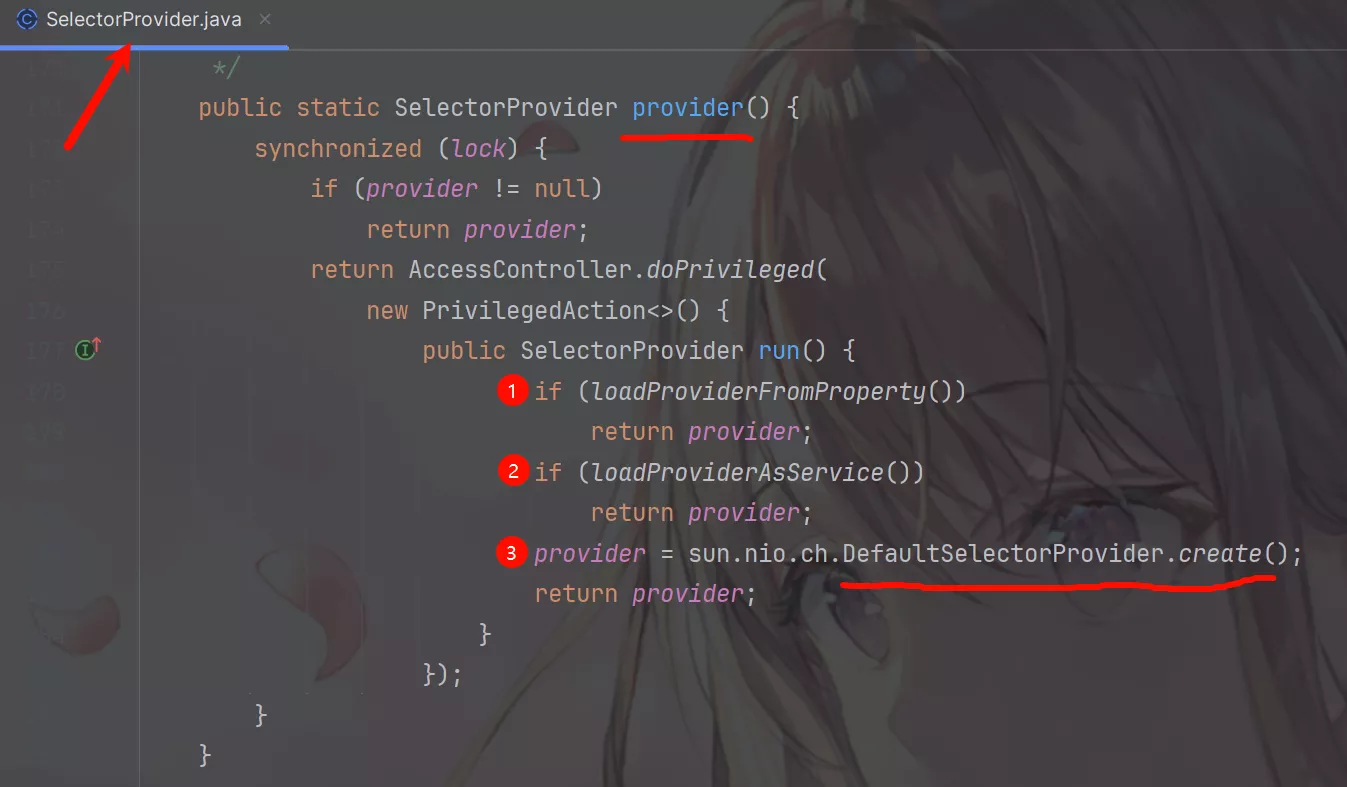
DefaultSelectorProvider.create()最终调用的是 JDK 底层的源码,而 JDK 底层源码根据操作系统的不同也不同。
查看 OpenJDK8 DefaultSelectorProvider.java 实现源码

从create()方法的底层源码能看出它会根据不同的操作系统创建不同的Provider,也就是说NIO的底层使用了操作系统的多路复用。
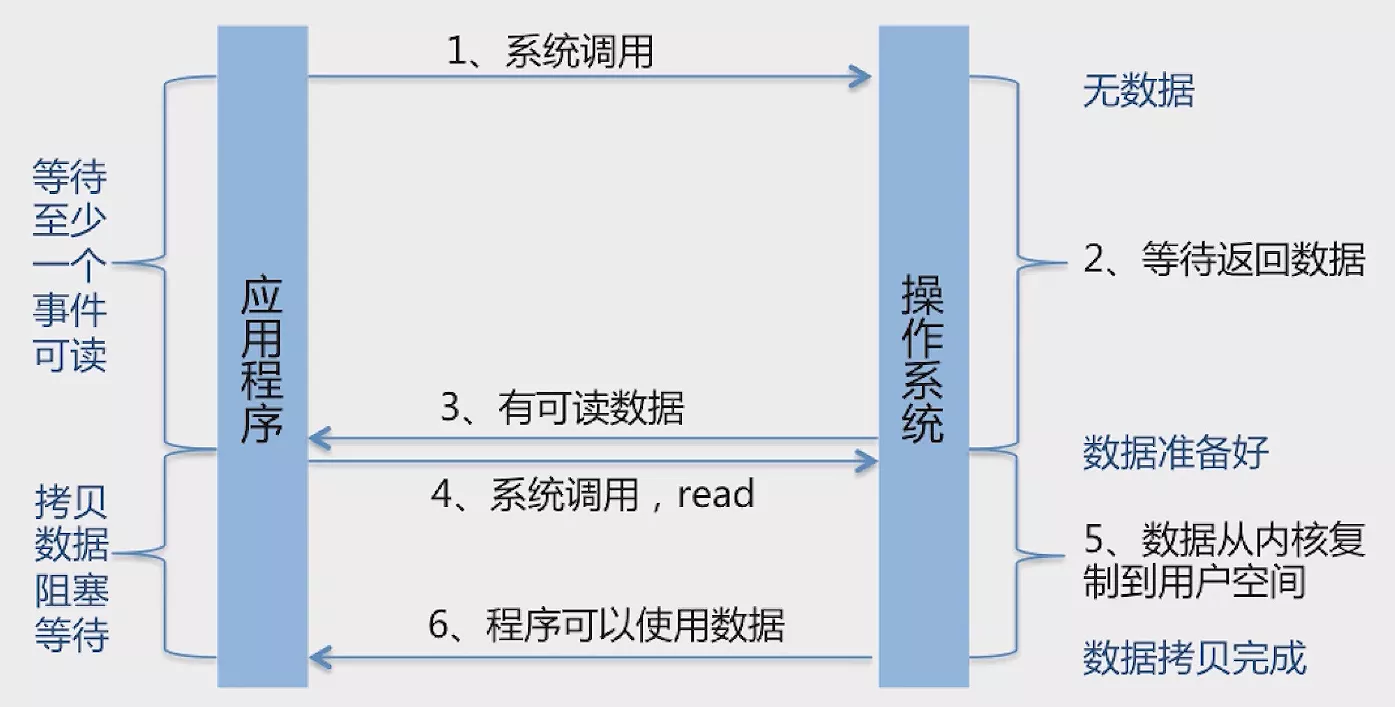
IO多路复用:调用系统级别的 select \ poll \ epoll。
使单线程可以处理多个网络 IO,其中由系统监控 IO 状态,由Selector通过轮询监控多个 IO 请求,当有一个Socket数据准备好后就可以返回了。
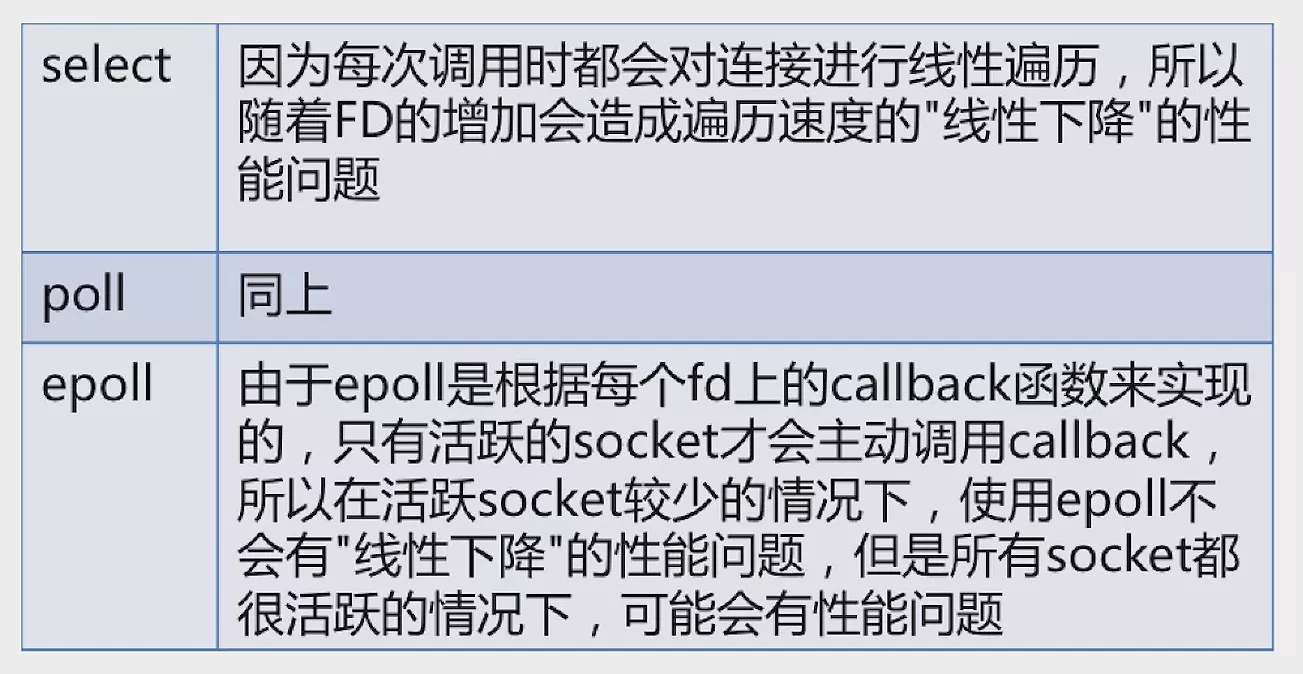
select、poll、epoll的区别:
-
区别一:支持一个进程所能打开的最大连接数。

-
区别二:FD 剧增后带来的 IO 效率问题。
-
区别三:消息传递方式。

Asynchronous IO (AIO):基于事件和回调机制。
在 Java 7 中NIO得到了进一步的改进,引入了异步非阻塞的方式,得到了AIO,是NIO 2.0版版本。
应用发起系统调用后直接返回不会阻塞住,当处理完成时操作系统就会通知响应线程进行后续处理。
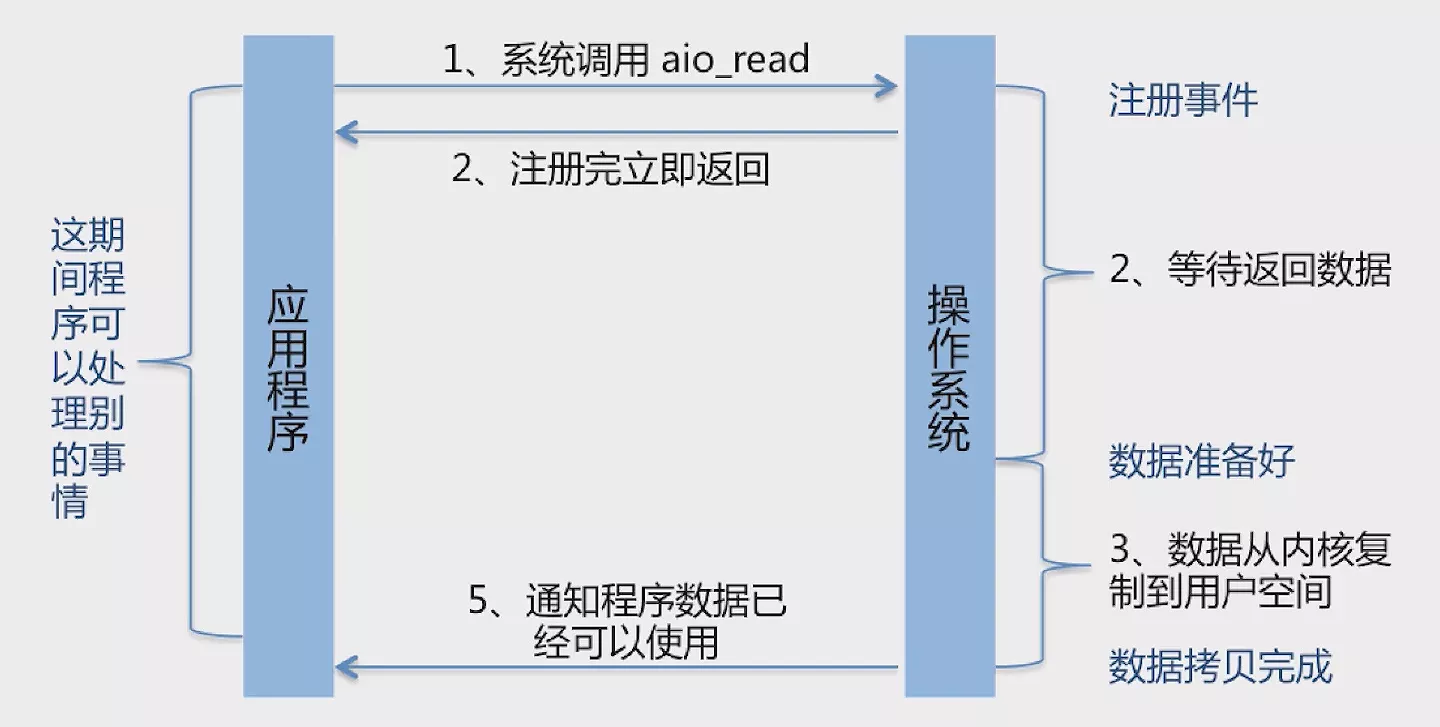
AIO如何进一步加工处理结果:
- 基于回调:实现
CompletionHandle接口,调用时触发回调函数; - 返回
Future:通过isDone()查看是否准备好,通过get()等待返回数据。
为了进一步加深对BIO、NIO、AIO的理解,下面通过这三种方式分别实现同一个功能,感受它们之间的区别。
要实现的功能是:实现一个server服务器等待客户端连接,若接收到了客户端连接则将客户端传递过来的数据原封不动的响应回去。
先来看BIO的实现。
public class BIOPlainEchoServer {
/**
* 简单的 Socket 服务器
*/
public void serve(int port) throws IOException {
// 将 ServerSocket 绑定到指定的端口里
final ServerSocket socket = new ServerSocket(port);
while (true) {
// 阻塞直到收到新的客户端连接
final Socket clientSocket = socket.accept();
System.out.println("Accepted connection from " + clientSocket);
// 接收到客户端连接后,创建一个子线程去处理客户端的请求
new Thread(new Runnable() {
@Override
public void run() {
try (BufferedReader reader = new BufferedReader(new InputStreamReader(clientSocket.getInputStream()))) {
PrintWriter writer = new PrintWriter(clientSocket.getOutputStream(), true);
// 从客户端读取数据并原封不动回写回去
while (true) {
writer.println(reader.readLine());
writer.flush();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}).start();
}
}
/**
* 使用线程池避免频繁创建和销毁线程
*/
public void improvedServe(int port) throws IOException {
// 将 ServerSocket 绑定到指定的端口里
final ServerSocket socket = new ServerSocket(port);
// 创建一个线程池
ExecutorService executorService = Executors.newFixedThreadPool(6);
while (true) {
// 阻塞直到收到新的客户端连接
final Socket clientSocket = socket.accept();
System.out.println("Accepted connection from " + clientSocket);
// 接收到客户端连接后,将请求提交给线程池去执行
executorService.execute(() -> {
try (BufferedReader reader = new BufferedReader(new InputStreamReader(clientSocket.getInputStream()))) {
PrintWriter writer = new PrintWriter(clientSocket.getOutputStream(), true);
//从客户端读取数据并原封不动回写回去
while (true) {
writer.println(reader.readLine());
writer.flush();
}
} catch (IOException e) {
e.printStackTrace();
}
});
}
}
}
但是如果请求很多,即便使用了线程池后,还会可能出现很多请求得不到响应的情况,此时应该想到使用多路复用来优化。
再来看多路复用机制的NIO实现。
public class NIOPlainEchoServer {
public void serve(int port) throws IOException {
System.out.println("Listening for connections on port " + port);
// 创建 Channel
ServerSocketChannel serverChannel = ServerSocketChannel.open();
// 从 Channel 中获取 ServerSocket 实例
ServerSocket ss = serverChannel.socket();
InetSocketAddress address = new InetSocketAddress(port);
// 将 ServerSocket 绑定到指定的端口里
ss.bind(address);
// 将 serverChannel 设置为 非阻塞 状态,因为阻塞状态下不允许注册操作,会抛出 IllegalBlockingModeException 异常,即下面的 serverChannel.register() 方法
serverChannel.configureBlocking(false);
// 创建 Selector 作为类似调度员的角色
Selector selector = Selector.open();
// 将 channel 注册到 Selector 里,并说明让 Selector 关注的点,这里是关注建立连接这个事件,即 SelectionKey.OP_ACCEPT
serverChannel.register(selector, SelectionKey.OP_ACCEPT);
while (true) {
try {
// 阻塞等待就绪的 Channel,即阻塞等待建立连接事件和下方注册的读写事件的发生,一直轮询直到事件就绪,类似自旋
selector.select();
} catch (IOException ex) {
ex.printStackTrace();
// 代码省略的部分是结合业务,正确处理异常的逻辑
break;
}
// 获取到 Selector 里所有就绪的 SelectedKey 实例,每将一个 channel 注册到 selector 就会产生一个 SelectedKey
Set<SelectionKey> readyKeys = selector.selectedKeys();
Iterator<SelectionKey> iterator = readyKeys.iterator();
// 遍历 SelectedKey
while (iterator.hasNext()) {
SelectionKey key = iterator.next();
// 将就绪的 SelectedKey 从 Selector 中移除,因为马上就要去处理它,防止重复执行
iterator.remove();
try {
// 若 SelectedKey 处于 Acceptable 状态,即建立连接状态
if (key.isAcceptable()) {
ServerSocketChannel server = (ServerSocketChannel) key.channel();
// 接受客户端的连接
SocketChannel client = server.accept();
System.out.println("Accepted connection from " + client);
client.configureBlocking(false);
// 向 selector 注册刚刚接收客户端连接的 SocketChannel 实例,主要关注读写,并传入一个 ByteBuffer 实例供读写缓存
client.register(selector, SelectionKey.OP_WRITE | SelectionKey.OP_READ, ByteBuffer.allocate(100));
}
// 若 SelectedKey 处于可读状态
if (key.isReadable()) {
SocketChannel client = (SocketChannel) key.channel();
ByteBuffer output = (ByteBuffer) key.attachment();
// 从 channel 里读取数据存入到 ByteBuffer 里面
client.read(output);
}
//若 SelectedKey 处于可写状态
if (key.isWritable()) {
SocketChannel client = (SocketChannel) key.channel();
ByteBuffer output = (ByteBuffer) key.attachment();
// 反转 ByteBuffer 的位置和限制,切换缓冲区从写模式到读模式,准备读取之前写入的数据
output.flip();
// 将 ByteBuffer 里的数据写入到 channel 里
client.write(output);
// 清除已经读取过的数据
output.compact();
}
} catch (IOException ex) {
key.cancel();
try {
key.channel().close();
} catch (IOException cex) {
}
}
}
}
}
}
它比BIO高效的原因是利用了单线程轮询事件机制,通过高效的定位就绪的Channel事件的类型做出相应的处理,仅仅在selector.select()阶段是阻塞的,可有效避免大量客户端连接时频繁切换线程带来的问题,应用的扩展能力有了非常大的提高。
最后来看AIO的实现。
AIO与NIO不同,读写操作均为异步,只需调用read()或write()方法即可。
对于读操作,当有流可读时操作系统会将可读取的流传入到read()方法的缓冲区并通知应用程序。
对于写操作,当操作系统将write()方法传递的流写入完毕时通知应用程序。
即read()或write()方法均为异步,完成后会主动调用回调函数。
public class AIOPlainEchoServer {
public void serve(int port) throws IOException {
System.out.println("Listening for connections on port " + port);
// 创建 Channel,对应 NIO 中的 ServerSocketChannel
final AsynchronousServerSocketChannel serverChannel = AsynchronousServerSocketChannel.open();
InetSocketAddress address = new InetSocketAddress(port);
// 将 ServerSocket 绑定到指定的端口里
serverChannel.bind(address);
final CountDownLatch latch = new CountDownLatch(1);
// 与 NIO 不同的是这里不需要 selector.select() 阻塞等待,直接使用 serverChannel.accept() 接收请求
// 开始接收新的客户端请求. 一旦一个客户端请求被接收, CompletionHandler 就会被调用
serverChannel.accept(null, new CompletionHandler<AsynchronousSocketChannel, Object>() {
@Override
public void completed(final AsynchronousSocketChannel channel, Object attachment) {
// AsynchronousSocketChannel 对应于 NIO 中客户端的 SocketChannel
// 一旦完成处理,再次接收新的客户端请求
serverChannel.accept(null, this);
ByteBuffer buffer = ByteBuffer.allocate(100);
// 在 channel 里植入一个读操作 EchoCompletionHandler,一旦 buffer 有数据写入,EchoCompletionHandler 便会被唤醒
channel.read(buffer, buffer, new EchoCompletionHandler(channel));
}
@Override
public void failed(Throwable throwable, Object attachment) {
try {
// 若遇到异常,关闭 channel
serverChannel.close();
} catch (IOException e) {
// ignore on close
} finally {
latch.countDown();
}
}
});
try {
latch.await();
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
private final class EchoCompletionHandler implements CompletionHandler<Integer, ByteBuffer> {
private final AsynchronousSocketChannel channel;
EchoCompletionHandler(AsynchronousSocketChannel channel) {
this.channel = channel;
}
@Override
public void completed(Integer result, ByteBuffer buffer) {
buffer.flip();
// 在 channel 里植入一个读操作 CompletionHandler,一旦 channel 有数据写入,CompletionHandler 便会被唤醒
channel.write(buffer, buffer, new CompletionHandler<Integer, ByteBuffer>() {
@Override
public void completed(Integer result, ByteBuffer buffer) {
if (buffer.hasRemaining()) {
// 如果 buffer 里还有内容,则再次触发写入操作将 buffer 里的内容写入 channel
channel.write(buffer, buffer, this);
} else {
// 清除已经读取过的数据
buffer.compact();
// 如果 channel 里还有内容需要写入到 buffer 里,则再次触发写入操作将 channel 里的内容写入 buffer
channel.read(buffer, buffer, EchoCompletionHandler.this);
}
}
@Override
public void failed(Throwable exc, ByteBuffer attachment) {
try {
channel.close();
} catch (IOException e) {
// ignore on close
}
}
});
}
@Override
public void failed(Throwable exc, ByteBuffer attachment) {
try {
channel.close();
} catch (IOException e) {
// ignore on close
}
}
}
}
AIO业务逻辑的关键在于指定CompletionHandler,EchoCompletionHandler回调接口,在accept()、read()、write()等关键节点通过事件机制来调用。
BIO、NIO、AIO对比:
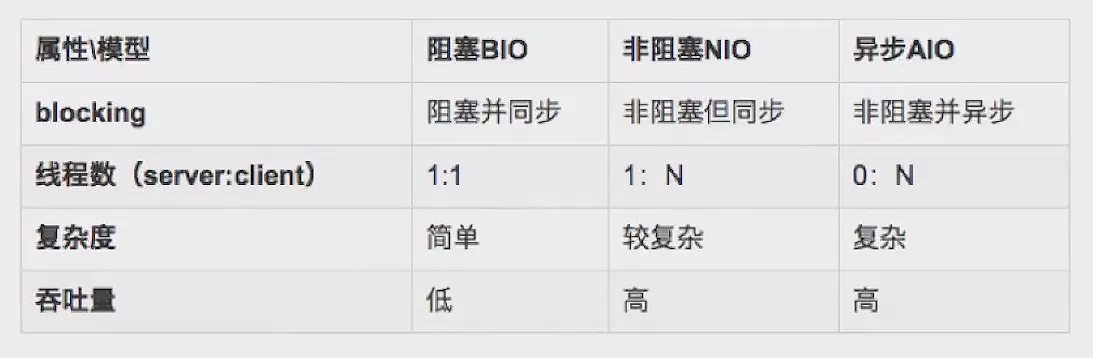
BIO适合连接数少且固定的架构,编码简单,直观;NIO适合连接数量多但连接较短的架构,如聊天服务器,编码较复杂;AIO适合连接数量多且连接较长的架构,如相册服务器,能充分调用操作系统参与并发操作,编码复杂。
参考资料 {#参考资料}
- 剑指Java面试-Offer直通车-慕课网实战 (imooc.com)
- ChatGPT 3.5