? 研究背景 ------- 在图像生成领域,扩散模型已经取得了巨大成功。 然而,现有的视频生成技术往往无法捕捉到人类表情的全部细节。 EMO的出现,正是为了解决这一挑战,它不仅能够生成令人信服的说话视频,还能制作出风格多样的唱歌视频。 ? 原理探究 ------- 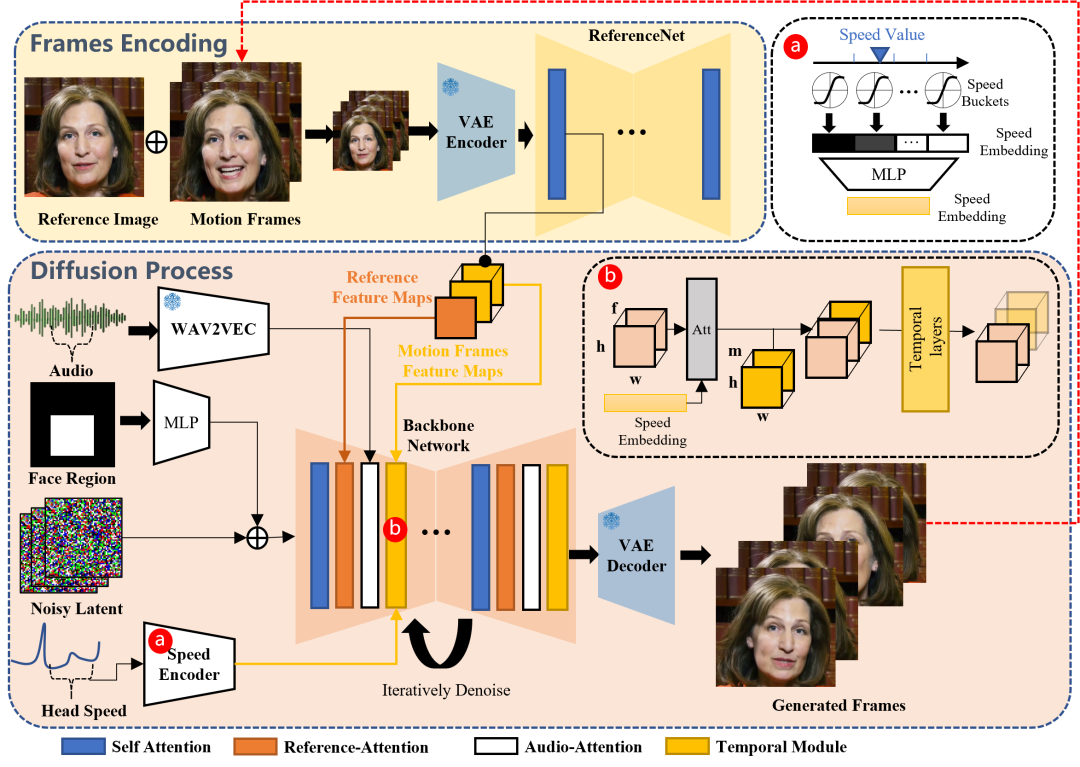 **EMO(Emote Portrait Alive)技术:** 是一种音频驱动的人像视频生成框架,它能够根据单一参考图像和声音输入生成具有丰富表情和自然头部运动的动画视频。 以下是EMO技术实现原理的详细阐述:**1. 音频到视频的直接合成:** * EMO采用直接音频到视频的合成方法,这意味着它不需要依赖于中间的3D模型或面部标记。 * 这种方法通过捕捉音频信号中的信息,直接生成与之相匹配的面部表情和头部运动。**2. Stable Diffusion(SD)基础框架:** * EMO基于Stable Diffusion(SD),这是一个广泛使用的文本到图像(T2I)模型。 * SD通过自编码器变分自编码器(VAE)将原始图像特征分布映射到潜在空间,并在推理过程中去除噪声以重建图像。
**3. 网络管道:** * Backbone Network:这是EMO的核心部分,它接收多帧噪声潜在输入,并在每个时间步骤尝试将其去噪为连续的视频帧。Backbone Network包含时间模块,以保持生成帧之间的连续性。 * Audio Layers:音频层负责处理输入音频序列,提取特征并将其与潜在代码进行交叉注意力操作,以驱动生成角色的运动。 * ReferenceNet:与Backbone Network结构相同,用于从输入图像中提取详细特征。ReferenceNet和Backbone Network在某些层上的特征图可能相似,这有助于Backbone Network整合ReferenceNet提取的特征。 * Temporal Modules:时间模块通过自注意力层在帧内的特征之间进行操作,以捕捉视频的动态内容。这些模块在Backbone Network的每个分辨率层中插入,以保持帧之间的一致性和连贯性。 * Face Locator and Speed Layers:面部定位器和速度层用于提供弱控制信号,以确保生成角色的运动一致性和稳定性。面部定位器通过编码面部边界框区域来控制角色面部的生成位置,而速度层则通过调整头部运动速度来保持运动的连贯性。
**4. 训练策略:** * EMO的训练分为三个阶段:图像预训练、视频训练和速度层集成。在图像预训练阶段,Backbone Network和ReferenceNet从单帧输入中学习。 * 在视频训练阶段,引入时间模块和音频层,处理连续帧。在速度层集成阶段,只训练时间模块和速度层,以避免音频层的训练影响音频对角色运动的驱动能力。 1. **5. 数据集构建:** * 为了训练EMO,研究者构建了一个包含超过250小时视频和超过1500万张图像的庞大且多样化的音视频数据集。 * 这个数据集涵盖了多种语言和内容,如演讲、电影电视片段和歌唱表演,确保模型能够捕捉到广泛的人类表情和声音风格。
**6. 实验结果:** * EMO在HDTF数据集上的实验结果表明,它在多个评价指标上超越了现有的最先进技术,如FID、SyncNet、F-SIM和FVD。 * 此外,用户研究和定性评估也证实了EMO在生成自然和表现力强的视频方面的能力。**EMO技术的实现原理结合了先进的扩散模型、精心设计的网络结构和大规模数据集,使得它能够在没有显式控制信号的情况下,生成高度真实和表现力丰富的视频内容。** ? 未来展望 ------- 虽然EMO在生成过程中可能需要更多的时间,且在控制信号方面还有待完善,但它的潜力无疑是巨大的。 想象一下,未来我们可以用EMO来创建个性化的虚拟助手、在线教育的互动视频,甚至是电影和游戏中的动态角色。 EMO的出现,无疑将为数字娱乐和人机交互带来革命性的变革。 ? 立即体验 ------- 想要亲自体验EMO的神奇魅力吗?点击下方视频链接,让我们一起探索这个由AI驱动的全新世界!