# (一)Set接口的特点 {#一-set接口的特点}
A collection that contains no duplicate elements. More formally, sets contain no pair of elements e1 and e2 such that e1.equals(e2), and at most one null element. As implied by its name
Set接口是Collection的子接口,通过上面这段官方文档对Set的介绍可以看出Set的两个特点:
- 无序(插入和取出的顺序不一致)
- 不可重复(所有元素只能出现一次,因此null也只能有一个)
Set的所有方法均来自Collection,没有自己的特有方法。HashSet和TreeSet是Set接口最常用的实现类。
# (二)HashSet的底层结构 {#二-hashset的底层结构}
首先还是先来看看官方文档对HashSet的介绍:
This class implements the Set interface, backed by a hash table (actually a HashMap instance). It makes no guarantees as to the iteration order of the set; in particular, it does not guarantee that the order will remain constant over time. This class permits the null element.
总结一下:HashSet继承Set接口,底层是一个哈希表,但是实际上是HashMap(这点可以从源码中看出来)。它是无序的(插入和取出的顺序不一致),它允许空节点。
我们先看一下源码:
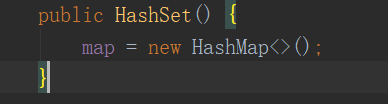
HashSet在构造方法中构造了一个HashMap,因此对源码的解读会放到HashMap中,现在主要说一下HashSet的底层实现结构。
# 2.1 HashSet为什么是不重复和无序的 {#_2-1-hashset为什么是不重复和无序的}
这个问题其实知道Hash表如何构造就很容易理解。
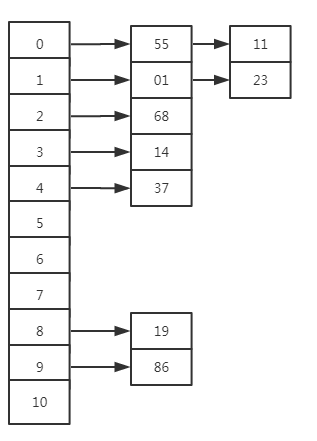
- 当有一个元素要进入hash表时,先获取该元素的哈希值,再通过一系列运算得到一个索引。(每个元素都能计算出一个索引值,但索引值并非是有序的,因此最终得到一个无序的哈希表。)
- 当该索引处没有元素,则直接插入
- 若该索引处有元素,则需要逐个通过equals判断,如果依旧不相等,则将元素以链表的形式添加在该索引的后面。如果相等,则覆盖原来的元素,实现不重复。
哈希表的链地址法如图所示:
# (三)HashSet的底层实现 {#三-hashset的底层实现}
为了更加清除的了解HashSet底层实现,我们通过代码来演示一下,按照以往的思路,我们先创建一个简单的类:
public class Book {
private String name;
private float price;
public Book(String name, float price){
this.name=name;
this.price=price;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public float getPrice() {
return price;
}
public void setPrice(float price) {
this.price = price;
}
@Override
public String toString() {
return "Book{" +
"name='" + name + '\'' +
", price=" + price +
'}';
}
}
然后再实现HashSet,在这里我故意让两个元素重复
public class HashSettest1 {
public static void main(String[] args) {
HashSet hashSet=new HashSet();
hashSet.add(new Book("aa",20));
hashSet.add(new Book("bb",10));
hashSet.add(new Book("bb",10));
System.out.println(hashSet);
}
}
但是结果却并没有把我们认为的重复元素(名称和价格相等就算重复)给去重

我们前面讲过,HashSet会先计算一个元素的哈希值,然后通过得到的索引用equals和已存在元素进行比较。但是在Book类中没有重写hashcode和equals方法,相当于它并不是按照我们的想法(名称和价格相等就算重复)去判断是否重复,而是根据这个对象计算了一个哈希值。
因此在Book中重写一个HashCode方法和equals方法,这两个方法编译器可以直接生成,为了让大家能理解我自己手写一个简单的HashCode方法和equals方法
@Override
public int hashCode() {
return name.hashCode()+(int)price;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (getClass() != o.getClass()) return false;
Book book = (Book) o;
return price==book.price &&
name.equals(book.name);
}
我通过名称和价格生成一个hashcode去生成哈希值,equals只有当名称和价格都相等时才算相等。
但是我现在手写的这个hashcode方式存在一个问题,即使name的hash值和price不同,但是加起来是有可能相同的,虽然后续还有equals方法可以防止hashcode的误差,但是增加了计算负担。
idea自动生成的两个方法如下:
@Override
public int hashCode() {
return Objects.hash(name, price);
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Book book = (Book) o;
return Float.compare(book.price, price) == 0 &&
Objects.equals(name, book.name);
}
进入hashcode源码后可以看到,对于计算出的值它又乘了一个31,避免哈希值一致但是实际不一致的情况
public static int hashCode(Object a[]) {
if (a == null)
return 0;
int result = 1;
for (Object element : a)
result = 31 * result + (element == null ? 0 : element.hashCode());
return result;
}
为什么选择31作为这个因子,《Effective Java》作了这样的解释:
之所以使用 31, 是因为他是一个奇素数。如果乘数是偶数,并且乘法溢出的话,信息就会丢失,因为与2相乘等价于移位运算(低位补0)。使用素数的好处并不很明显,但是习惯上使用素数来计算散列结果。 31 有个很好的性能,即用移位和减法来代替乘法,可以得到更好的性能: 31 * i == (i << 5)- i, 现代的 VM 可以自动完成这种优化。这个公式可以很简单的推导出来。
简而言之,使用 31 最主要的还是为了性能。
# (四)TreeSet的结构和运行原理 {#四-treeset的结构和运行原理}
首先还是来看看官方文档对TreeSet的介绍:
A NavigableSet implementation based on a TreeMap. The elements are ordered using their natural ordering, or by a Comparator provided at set creation time, depending on which constructor is used.
TreeSet底层结构是基于TreeMap的,这一点和HashSet类似。
# 4.1 TreeSet的特点 {#_4-1-treeset的特点}
- 不允许重复(不允许有null值)
- 可以实现对元素的排序(自然排序、定制排序)
- 自然排序:添加的元素实现Comparable接口,实现里面的compareTo方法
- 定制排序:创建TreeMap对象时,传入一个Comparator接口,并实现里面的compare方法
- 底层是一个TreeMap,TreeMap底层是一个红黑树结构,可以实现对元素的排序
# 4.2 TreeSet的实际操作 {#_4-2-treeset的实际操作}
还是新建一个最普通的Book类:
public class Book {
private String name;
private float price;
public Book(String name, float price){
this.name=name;
this.price=price;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public float getPrice() {
return price;
}
public void setPrice(float price) {
this.price = price;
}
@Override
public String toString() {
return "Book{" +
"name='" + name + '\'' +
", price=" + price +
'}';
}
}
然后新建一个类去使用TreeSet:
public class TreeSetTest {
public static void main(String[] args) {
TreeSet treeSet=new TreeSet();
treeSet.add(new Book("a",10));
treeSet.add(new Book("b",5));
treeSet.add(new Book("c",20));
System.out.println(treeSet);
}
}
但是结果是报错的,报错的原因是Book类没有继承Comparable接口

解决办法一(自然排序):在Book类中继承Comparable接口,重写compareTo方法:
public class Book implements Comparable{
......
@Override
public int compareTo(Object o) {
Book book= (Book) o;
return Float.compare(this.price,book.price);
}
}
解决办法二(定制排序):在建TreeMap对象时,传入一个Comparator接口,并实现里面的compare方法。
public class TreeSetTest {
public static void main(String[] args) {
TreeSet treeSet=new TreeSet(new Comparator() {
@Override
public int compare(Object o1, Object o2) {
Book book1= (Book) o1;
Book book2= (Book) o2;
return Float.compare(book1.getPrice(),book2.getPrice());
}
});
treeSet.add(new Book("a",10));
treeSet.add(new Book("b",5));
treeSet.add(new Book("c",20));
System.out.println(treeSet);
}
}
# 4.3 TreeSet去重的方法 {#_4-3-treeset去重的方法}
前面讲到hashSet去重的方法是hashcode和equals方法判断相同则覆盖,TreeSet是通过compareTo方法的返回值来判断是否相同,如果返回值为0则认定是重复元素。
# (五)总结 {#五-总结}
最后来总结一些HashSet和TreeSet的区别:
- TreeSet 是二叉树(红黑树)实现的,Treeset中的数据是自动排好序的,不允许放入null值。
- HashSet 是哈希表实现的,HashSet中的数据是无序的,可以放入null,但只能放入一个null,两者中的值都不能重复。
- HashSet要求放入的对象实现HashCode()和equals()方法,TreeSet要求放入的对象继承Comparable接口并实现compareTo方法或者在建TreeMap对象时,传入一个Comparator接口,并实现里面的compare方法。





