# (一)概述 {#一-概述}
如果说垃圾收集算法是内存回收的理论,那么垃圾收集器就是内存回收的具体实现。
垃圾收集器目前存在的有很多,但是依旧没有哪个收集器是万能的存在,我们只能选择一个最适合应用的收集器。
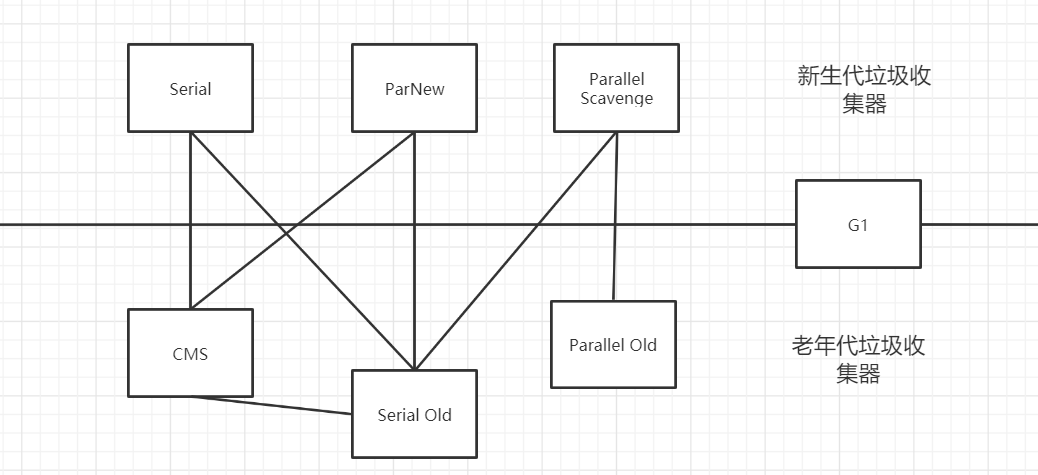
下面会介绍目前主流Java虚拟机中所采用的七种垃圾收集器: Serial、parNew、ParallelScavenge、SerialOld、ParallelOld、CMS、G1 上述垃圾收集器有些适用于新生代,有些适用于老年代,有些在新生代和老年代都适应。如下图所示,连线表示可以配合使用。
# (二)Serial {#二-serial}
Serial是一个单线程的收集器,Serial的特点是它在进行垃圾收集时,必须"Stop the World",意思就是当这个垃圾收集器开始工作时,必须停止其他所有的工作线程。听起来似乎很不靠谱,但是对于限定单个CPU的场景下,这种方式简单而高效。对于简单的桌面应用,分配给虚拟机的内存不会很大,对于一两百兆的新生代,Serial的垃圾收集时间可以控制在一百毫秒以内,对于用户来说基本上是无影响的。
Serial收集器在新生代使用复制算法。
# (三)ParNew {#三-parnew}
ParNew垃圾收集器是Serial的多线程版本,使用多条线程进行垃圾收集。除此之外,和Serial基本相同,ParNew在多线程收集垃圾时依旧需要**"Stop the World"**。ParNew可以使用-XX:ParallelGCThreads参数来限制垃圾收集的线程数量。
ParNew收集器在新生代使用复制算法
# (四)Parallel Scavenge {#四-parallel-scavenge}
Parallel Scavenge也是新生代收集器,也同样是多线程的收集器,但是和ParNew不同,Parallel Scavenge收集器关注的是一个可控制的吞吐量(Throughput)。所谓吞吐量指的是CPU用于运行代码的时间和CPU总消耗的时间比例。
吞吐量=运行代码的时间 /(运行代码的时间+垃圾收集时间)
理论上吞吐量越高,用户就越不能感受到停顿时间。
Parallel Scavenge提供了两个参数用来控制吞吐量: -XX:MaxGCPauseMillis和**-XX:GCTimeRatio**
-XX:MaxGCPauseMillis 设置内存回收花费时间最高毫秒值,但是不要一味地认为只要把值设置很小,垃圾回收就更快了。这个停顿时间是以牺牲吞吐量和新生代空间换来的。
-XX:GCTimeRatio表示垃圾收集时间占总时间的比例,(1~100),也就是吞吐量的倒数。默认这个值是99,就是允许最大百分之1的垃圾手机时间(1/(1+99))。
还有一个参数**-XX:+UseAdaptiveSizePolicy**,打开这个参数后,就不需要自己设置新生代大小、晋升老年代对象年龄等参数,因此Parallel Scavenge收集器也被叫做吞吐量优先垃圾收集器。
Parallel Scavenge采用复制算法。
# (五)Serial Old {#五-serial-old}
一听名字就知道这是Serial收集器的老年代版本,是单线程收集器,采用标记-整理算法,其余的和新Serial基本相同。
# (六)Parallel Old {#六-parallel-old}
Parallel Scavenge收集器的老年版本,多线程收集器,采用标记-整理算法,也是吞吐量优先。
# (七)CMS收集器 {#七-cms收集器}
CMS(Concurrent Mark Sweep)收集器是一种以获取最短回收停顿时间为目标 的收集器。CMS是基于标记-清除算法的老年代垃圾回收器,CMS是目前应用最广泛的老年代垃圾回收器,它进行垃圾回收分为以下四步:
1、初始标记:标记GC Roots可以直接关联到的对象,速度很快(stop the world)
2、并发标记:根搜索算法的过程
3、重新标记:为了修正并发标记期间,因程序运行导致标记产生变动的对象。(stop the world)
4、并发清除:清除垃圾
这个过程中耗时最长的是并发标记和并发清除的过程,但是并不会stop the world,而初始标识和重新标记的速度都很快,即使stop the world也不会占用太多时间。
它的优点就是并发收集、并发清除、低停顿。
但是它有三个显著的缺点:
1、对CPU资源十分敏感,因为并发标记和并发清除都是和程序同时运行,因此会占用CPU导致应用程序变慢。
2、无法处理浮动垃圾,浮动垃圾就是在并发清除过程中新生成的垃圾,这部分垃圾CMS无法在本次被清理,可能出现Concurrent Mode Failed报错,因此需要预留一定的内存空间,无法等到老年代快被占满时再清除。默认情况下,CMS在老年代使用了68%后就会被激活。可以设置-XX:CMSInitiatingOccupancyFraction设置这个值。
3、产生空间碎片,由于采用的是标记-清除算法,那就无法避免会产生空间碎片的问题,这会给分配大对象带来困难。
# (八)G1 {#八-g1}
上面的垃圾回收器基本上都是按新生代和老年代去区分,但是G1不一样
堆结构
G1的堆结构就是把一整块内存区域划分为多个固定大小的块,JVM一般把堆划分为2000个region,然后每个region从1M到32M不等。
内存的分配
所有的region会被划分为Eden、Survivor、Old和Humongous,其中对Eden、Survivor和Old的理解用其他垃圾回收器去理解,这里多了一种类型Humongous,这个类型主要用来存储比标准块大百分之50或者更大的对象。
G1中的YGC
第一次YGC时,Eden块中存活的对象会被转移到一个或多个survivor块中,存活时间达到阈值,这些对象就会晋升到老年代。年轻代 GC 通过多线程并行进行。
此时会有一次 stop the world暂停,会计算出 Eden大小和 survivor 大小,用于下次young GC。统计信息会被保存下来,用于辅助计算size。比如暂停时间之类的指标也会纳入考虑。
一旦发生一次新生代回收,整个新生代都会被回收(根据对暂停时间的预测值,新生代的大小可能会动态改变)
G1中的老年代垃圾收集
老年代回收不会回收全部老年代空间,只会选择一部分收益最高的 Region,回收时一般会搭便车------把待回收的老年代 Region 和所有的新生代 Region 放在一起进行回收,这个过程一般被称为 Mixed GC
G1中的老年代垃圾收集和CMS收集器很相似
1、初始标记:附加在正常的YGC过程中,标记所有的根。(stop the world)
2、扫描根区域:扫描Survivor Regions中指向老年代的被初始标记标记的引用及引用的对象,这个阶段是并发执行的,但是在年轻代GC发生之前必须完成。(stop the world)
3、并发标记:在整个堆中查找活着的元素,此阶段可被YGC打断
4、再次标记:类似CMS的重新标记,处理并发标记阶段产生的新的对象引用,这阶段使用了SATB(snapshot-at-the-beginning)算法,该算法比CMS中所采用的快很多。(stop the world)
5、清理阶段:G1 GC 会识别完全空闲的区域和可供进行混合垃圾回收的区域进行清理。(stop the world)
你可以发现,有四个阶段都需要stop the world,为了降低stop the world的时间,G1使用了RSet(Remembered Set)来记录不同代之间的引用关系。
RSet
RSet记录了"谁引用了我",RSet记录了以下两种引用:
1、老年代 Region 间的引用
2、老年代 Region 到新生代 Region 的引用,Young GC 时直接将这种引用加入 GC Roots。
RSet的工作原理是这样的,进行 Young GC 时,选择新生代所在的 Region 作为 GC Roots,这些 Region 中的 RSet 记录了老年代->新生代的的跨代引用(「谁引用了我」),从而可以避免了扫描整个老年代 。进行 Mixed GC 时,「老年代->老年代」之间的引用,可以通过待回收 Region 中的 RSet 记录获得,「新生代->老年代」之间的引用通过扫描全部的新生代获得(前面提到过 Mixed GC 会搭 Young GC 的便车),也不需要扫描全部老年代。总之,引入 RSet 后,GC 的堆扫描范围大大减少了。
# (九)总结 {#九-总结}
上面这七种垃圾收集器中最优秀的非G1莫属,但是它还不够好,第一个原因是RSet会占用一定的内存,第二个原因是stop the world时间太长了。目前有两款更新的垃圾回收器:ZGC/C4 垃圾回收器 、Shenandoah 垃圾回收器,有兴趣的小伙伴可以去了解下。